
网络评论方面级观点挖掘方法研究综述(软件学报)
网络评论方面级观点挖掘方法研究综述(软件学报)
1、方面提取
-
2.1 显式方面提取
显式方面提取的方法按照学习方式不同可以分为有监督学习的方法、无监督学习的方法与半监督学习的方法.- 2.1.1 带监督学习方法
- 有监督的统计模型
1、隐马尔可夫模型(hidden Markov model,简称 HMM)
采用一种编入词汇的 HMM 模型来提取显式方面.该模型能够识别方面及其对应观点内容,同时能够判断观点极性.该方法首先建立由不同词汇及其对应词性组成的词集,以此来对评论文本的方面及观点内容进行人工标注;然后,将标注完毕的数据送入 HMM 进行训练.
2、条件随机场模型(conditional random field,简称 CRF)等。
基本思想是,通过依赖于少数变量的局部函数的乘积来表示一个依赖大量随机变量的概率分布.由于方面的抽取过程可视作一个序列标注问题,因此可采用 CRF 中的线性链结构来解决此问题。 - 主题模型
1、pLSA(probabilistic latent semantic analysis)
2、LDA(latent Dirichlet allocation)
主要思想是:在文档与单词间建立“主题”这一桥梁,通 常的主题模型为无监督模型。
- 有监督的统计模型
- 2.1.2 无监督学习方法
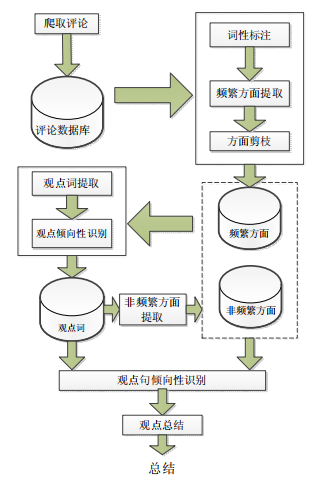
- 该方法首先将电子产品评论数据进行词性标注(part-of-speech tagging,简称 POS),并使用以 Apriori 算法为基础的关联规则挖掘方法找出频繁出现的名词及名词短语作为候选方面;然后,将错误的词语通过剪枝算法将其进行过滤,最终形成方面集合,方法流程图如图所示:
![]()
- 该方法首先将电子产品评论数据进行词性标注(part-of-speech tagging,简称 POS),并使用以 Apriori 算法为基础的关联规则挖掘方法找出频繁出现的名词及名词短语作为候选方面;然后,将错误的词语通过剪枝算法将其进行过滤,最终形成方面集合,方法流程图如图所示:
- 2.1.3 半监督学习方法
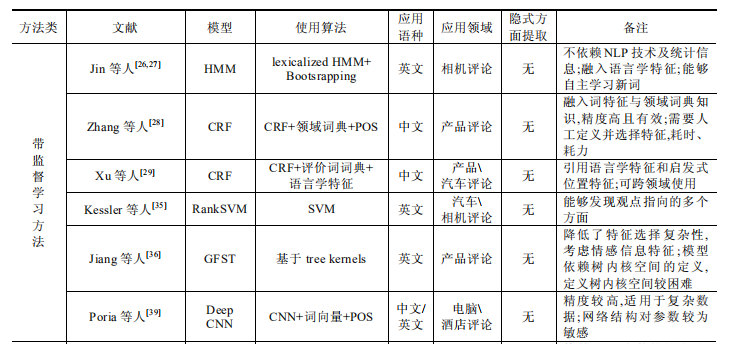
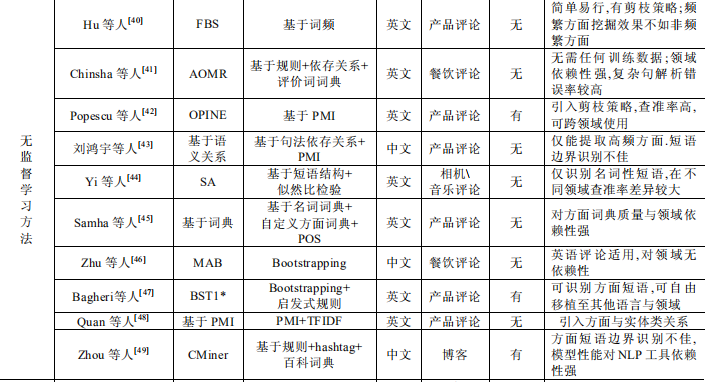
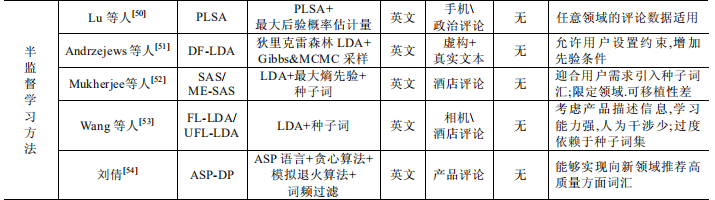
半监督方法能够利用局部标注来完成显式方面的全局挖掘,但对数据领域有着较强的依赖,能够自主挖掘显式方面,大量减少人工干涉同时提高结果的精准度仍是显式方面提取方法的目标. - 显式方面提取方法对比
![]()
![]()
![]()
- 2.1.1 带监督学习方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号