
OpenVLA-OFT论文研读与复现 笔记
论文总结
随着 Vision‑Language‑Action (VLA) 模型在 2023‑24 年迅速崛起,研究者发现它们在新机器人平台上常出现 推理延迟高(自回归解码) 和 适配效率低 两大短板。斯坦福团队以自家 7 B 预训练模型 OpenVLA‑7B 为基座,在 Fine‑Tuning Vision‑Language‑Action Models: Optimizing Speed and Success(RSS 2025)中系统剖析微调策略并提出 OpenVLA‑OFT。(arXiv, Robotics: Science and Systems)
项目地址: https://openvla-oft.github.io
改进内容
作者沿 三条轴线——① 动作解码方式,② 动作表示,③ 学习目标——做消融,最终提出 OFT 配方:
- 并行解码 一次性输出所有动作维度;
- 动作块 (Action Chunking) 一次预测多步(模拟 8 步 / 实机 25 步),减少推理调用;
- 连续动作 + L1 回归 取代离散分类或扩散头,训练稳定、硬件友好。
微调仅增设轻量动作头与可选 FiLM 调制层,视觉‑语言主干权重保持冻结。代码与检查点已开源。(GitHub)
架构图
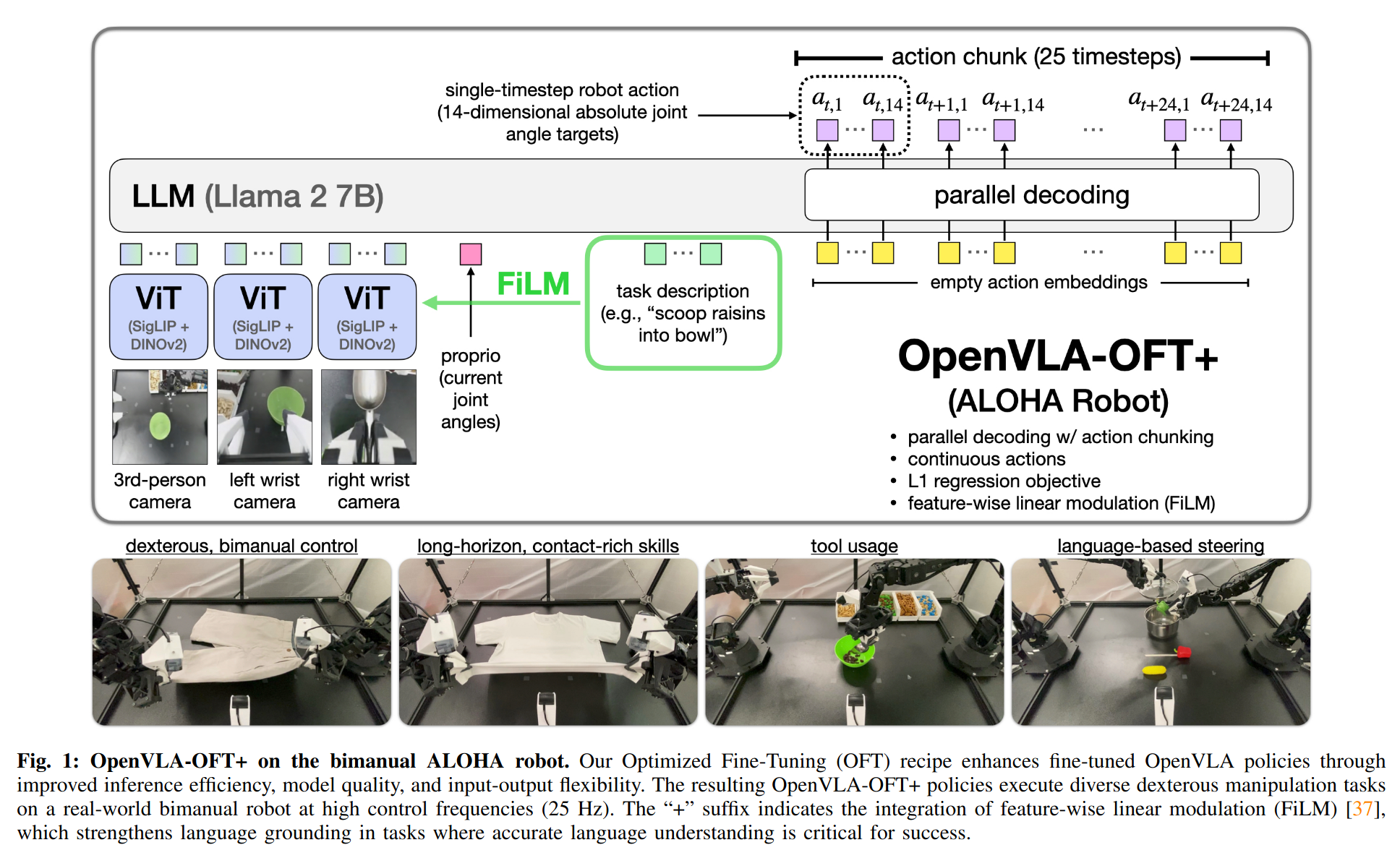
方法成效
- LIBERO 四套仿真任务:平均成功率由 76.5 % → 97.1 %,动作生成频率提升 26 ×;
- ALOHA 双臂真实机器人:在四项灵巧操作上较 Diffusion Policy、ACT 等基线高 ~15 个百分点。(arXiv)
一句话总结:OpenVLA‑OFT 通过“并行 + 块状 + 连续 L1”三招,把同一预训练 VLA 模型在新场景中调得又快又准,为后续机器人研究提供了高效可复用的微调蓝本。
复现
先看复现效果
由于成本原因,本人只基于LIBERO仿真环境复现,训练20K Steps。效果如下,左侧是第三人称视角(3rd_person_img)右侧是腕部视角(wrist_img):

20 K‑step OpenVLA‑OFT (1 policy for all 4 suites) (每个任务 5 次评测)
| 模型 / 任务套件 | LIBERO‑10† | LIBERO‑Spatial | LIBERO‑Object | LIBERO‑Goal | 平均 |
|---|---|---|---|---|---|
| Diffusion Policy(从零训练) | 50.5 | 78.3 | 92.5 | 68.3 | 72.4 |
| OpenVLA(Vanilla 微调) | 53.7 | 84.7 | 88.4 | 79.2 | 76.5 |
| OpenVLA‑OFT(官方,完整 50‑150 K step) | 97.7 | 98.0 | 96.1 | 95.3 | 96.8 |
| 复现 OFT(Train 20 K step,Eval 5 次/任务) | 70.0 | 98.0 | 100.0 | 94.0 | 90.5 |
简要说明: 保持 OFT 配方(并行解码 + 动作块 + 连续 L1 回归)的前提下,仅用 20 K step (单张4090D 48G耗时3-4天),对四个 LIBERO 套件做了快速评测(--num_trials_per_task 5),结果显示平均成功率 90.5 %,比未经微调的 OpenVLA‑7B 基线(≈76 %)大幅提升;其中 Spatial 和 Object 套件已接近官方完整评测的水平,说明核心策略已生效。LIBERO‑10 略低,后续可继续训练到 50 K step 应该可以进一步收敛。整体验证了 OFT 在小数据、短训练下显著加速且保持高成功率的优势。
环境安装
克隆仓库
git clone git@gitee.com:xbit/openvla-oft.git
cd openvla-oft
主体流程按照官方README.md,参考SETUP.md和LIBERO.md,有些库版本问题,建议先修改如下:
pyproject.toml中库版本

指定numpy版本,确保与tensorflow兼容

安装依赖库
建议先在 https://huggingface.co/settings/keys 页面Add SSH Key,确保git clone能拉取LIBERO中LFS训练数据。
# 1. 创建并激活 Conda 环境 openvla-oft
conda create -y -n openvla-oft python=3.10
source "$(conda info --base)/etc/profile.d/conda.sh"
conda activate openvla-oft
# 2. 安装 PyTorch 2.2.0 / cu121(三个官方 wheel 已自带 CUDA 12.1)
python -m pip install --upgrade pip
python -m pip install \
torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 \
--index-url https://download.pytorch.org/whl/cu121
# 3. 可编辑方式安装当前 openvla-oft 源码
pip install -e .
# 4. 安装编译工具并构建 flash-attn 2.5.5
pip install packaging ninja
pip install flash-attn==2.5.5 --no-build-isolation
# 5. 验证 Torch / CUDA / flash-attn 是否就绪
python - <<'PY'
import torch, importlib.metadata
print(f"Torch : {torch.__version__} (CUDA {torch.version.cuda})")
print("flash-attn:", importlib.metadata.version("flash_attn"))
print("GPU :", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "N/A")
PY
# 6. 安装libero
git clone https://github.com/Lifelong-Robot-Learning/LIBERO.git
pip install -e LIBERO
pip install -r experiments/robot/libero/libero_requirements.txt # From openvla-oft base dir
# 拉取用于微调训练的LIBERO数据(约20G),耗时较长。
# 要先在https://huggingface.co/settings/keys页面Add SSH Key,确保git clone能拉取LFS
git clone git@hf.co:datasets/openvla/modified_libero_rlds
# Done!现在可直接运行 OpenVLA-OFT 的训练或评估脚本
Eval
直接按照官方LIBERO.md中的命令运行即可,它会自动下再对应模型参数ckpt。命令示例:
python experiments/robot/libero/run_libero_eval.py \
--pretrained_checkpoint moojink/openvla-7b-oft-finetuned-libero-spatial \
--task_suite_name libero_spatial
Train(finetune)
简单训练,按照官方命令没问题:
torchrun --standalone --nnodes 1 --nproc-per-node X vla-scripts/finetune.py ......
训练完后用相同的脚本eval,只不过pretrained_checkpoint要用自己的模型参数,示例如下:
python experiments/robot/libero/run_libero_eval.py \
--pretrained_checkpoint runs/openvla-7b+libero_4_task_suites_no_noops+b64+lr-0.0005+lora-r32+dropout-0.0--image_aug--parallel_dec--8_acts_chunk--continuous_acts--L1_regression--3rd_person_img--wrist_img--proprio_state--20000_chkpt/ \
--task_suite_name libero_goal --num_trials_per_task 5
需要注意的细节:
- 官方显卡是8张显卡训练,每张batch size = 8,如果显卡不够,或显存较小,需要改参数训练。以单显卡4090 48G为例,要减少batch size,并设置grad_accumulation_steps,以便每个Step总的batch size为64(与论文一致)。
torchrun --standalone --nnodes 1 --nproc-per-node 1 vla-scripts/finetune.py \
--vla_path runs/openvla-7b+libero_4_task_suites_no_noops+b64+lr-0.0005+lora-r32+dropout-0.0--image_aug--parallel_dec--8_acts_chunk--continuous_acts--L1_regression--3rd_person_img--wrist_img--proprio_state--15000_chkpt \
...... \
--batch_size 4 \
--grad_accumulation_steps 16 \
--learning_rate 5e-4 \
......
- 论文中提到
# Merge LoRA weights into base model and save resulting model checkpoint
# Note: Can be very slow on some devices; if so, we recommend merging offline
if cfg.use_lora and cfg.merge_lora_during_training:
我也遇到了它导致的问题了,因为内存不足,导致失败(而非太慢),建议内存≤64G的电脑将merge_lora_during_training设置为False,如下:
torchrun --standalone --nnodes 1 --nproc-per-node 1 vla-scripts/finetune.py \
...... \
--merge_lora_during_training False \
......
- 如果训练过程中异常中断,假设要恢复15000的ckpt用于继续训练或Eval,命令如下:
# 1. 将LoRA参数融合进openvla-7b,如果finetune阶段merge_lora_during_training设置为True,跳过此步
python vla-scripts/merge_lora_weights_and_save.py \
--base_checkpoint openvla/openvla-7b \
--lora_finetuned_checkpoint_dir runs/openvla-7b+libero_4_task_suites_no_noops+b64+lr-0.0005+lora-r32+dropout-0.0--image_aug--parallel_dec--8_acts_chunk--continuous_acts--L1_regression--3rd_person_img--wrist_img--proprio_state--15000_chkpt/
# 2. 继续训练,关注下面参数,其他参数不变,注意vla_path参数为继续训练的起点。
torchrun --standalone --nnodes 1 --nproc-per-node 1 vla-scripts/finetune.py \
--vla_path runs/openvla-7b+libero_4_task_suites_no_noops+b64+lr-0.0005+lora-r32+dropout-0.0--image_aug--parallel_dec--8_acts_chunk--continuous_acts--L1_regression--3rd_person_img--wrist_img--proprio_state--15000_chkpt \
...... \
--resume True \
--resume_step 15000\
......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号