壁纸提取
简单说下这次练手的小东西想法:在暑假的时候,看见自己的电脑壁纸有点。。。。,LOW,所以想着做一个WIN下的壁纸切换小程序。这次只是图片提取部分,话不多说来看看代码。
第一步:查看网页源代码(F12/右击审查元素),查看每个组图间、组图下的图片之间的关系。
可以看到该缩略图多对应的有href下的组图链接,以及自己本身的的链接,后缀为JPG,或者鼠标放上去可以看到相关的图片。
点进组图,再查看每个图片的URL结构。如下:


可以看到URL结构与组图相似,点击下一页,URL自动变化(URL后5个参数发生变化),没办法找到相关的规律,可能我比较菜。。。。
找到NetWork下的网页源代码,这个是没有任何渲染源代码,
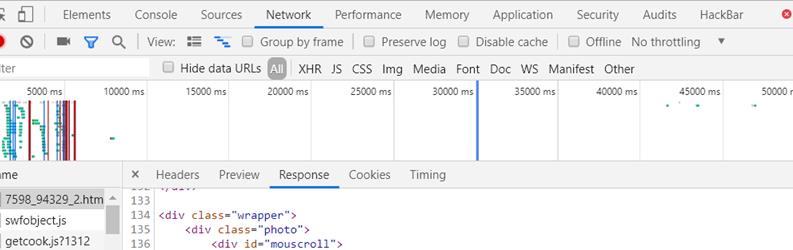
我们找到这个:

发现规律了吗?有思路的可以试试。
然后我们写的代码如下:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # author:albert time:2019/7/8 4 import requests 5 from lxml import etree 6 from random import randint 7 8 9 a = [] 10 11 # 每个组图的url 12 def This_Mosaic_Url(): 13 req = requests.get('http://desk.zol.com.cn/1920x1200/').text 14 html = etree.HTML(req) 15 url = html.xpath("//div//li[@class='photo-list-padding']//a/@href") 16 for i in url: 17 url_list = 'http://desk.zol.com.cn' + i 18 a.append(url_list) 19 20 def list_randan(): 21 it= iter(a) 22 # print(next(it)) 23 return next(it) 24 25 # 每个组图下的所有图片 26 def img_picture(): 27 # 第一个url===>"http://desk.zol.com.cn/bizhi/7590_94212_2.html" 28 list = [a[0]] 29 30 while True: 31 url_1 = 'http://desk.zol.com.cn' 32 req = requests.get(list[-1],timeout=3).text 33 html = etree.HTML(req) 34 35 url_detail = ''.join(html.xpath("//div[@class='photo-next prev-next']//a/@href")) 36 if url_detail == 'javascript:;': 37 try: 38 for i in range(15): 39 href = list_randan() 40 list.append(href) 41 except: 42 pass 43 else: 44 url = url_1 + url_detail 45 list.append(url) 46 47 print(len(list)) 48 for x in list: 49 print(x) 50 51 if __name__ == '__main__': 52 This_Mosaic_Url() 53 img_picture()
以上实现的思路,如果有什么疑问欢迎在下面留言!
初学者
分享及成功,你的报应就是我,记得关注,留言!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号