xpath相关用法及技巧
-
lxml下载
-
xpath基本用法
-
xpath插件
Xpath及XML路径语言,它是一门在XML文档查找信息的语言。
首先需要解决lxml的安装问题,在Windows下我们可以尝试使用pip install lxml 下载,如果没有任何报错的,恭喜安装成功,下面可以进行骚操作了;如果出现报错,出现的提示出现libxml2库等信息,可以采用wheel安装。
wheel的安装方法:推荐去 http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml下载对应的lxml文件,切换到下载文件的目录下,进入cmd,pip install {文件名}.wheel进行安装。
二:xpath的使用方法
介绍一下xpath的常用规则:
| 表达式 | 描述 | 示例 | 结果 |
|---|---|---|---|
| nodename | 选取此节点的所有子节点 | xbhog | 选取xbhog下所有的子节点 |
| / | 如果是在最前面,代表从根节点选取。否则选择某节点下的某个节点 | /xbhog | 选取根元素下所有的xbhog节点 |
| // | 从全局节点中选择节点,随便在哪个位置 | //xbhog | 从全局节点中找到所有的xbhog节点 |
| @ | 选取某个节点的属性 | //xbhog[@price] | 选择所有拥有price属性的xbhog节点 |
| . | 当前节点 | ./a | 选取当前节点下的a标签 |
| 路径表达式 | 描述 |
|---|---|
| /bookstore/book[1] | 选取bookstore下的第一个子元素 |
| /bookstore/book[last()] | 选取bookstore下的倒数第二个book元素。 |
| bookstore/book[position()<3] | 选取bookstore下前面两个子元素。 |
| //book[@price] | 选取拥有price属性的book元素 |
| //book[@price=10] | 选取所有属性price等于10的book元素 |
这些基本规则基本上满足日常需求了,如果还有其他问题,百度是个好东西你值得拥有。
下面举个例子实战一下:
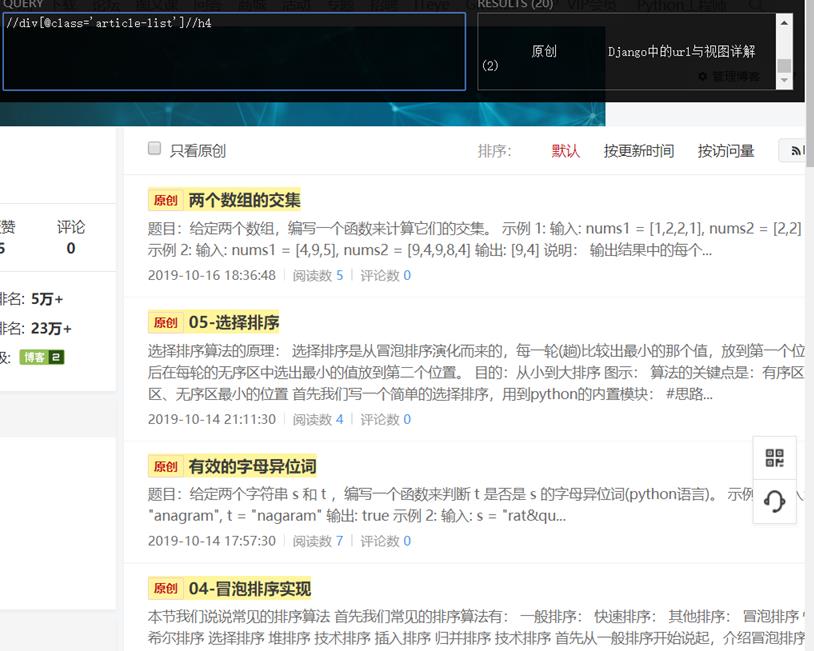
下面是我博客的内容,我们需要做的就是爬取这一页的标题内容:[两个数组的交集.......],想一下!

我们先打开开发者模式,找到标题所在的网页源代码:

我们从最里面一步一步往外推,<a> --> <h4> --> <div class="article-item-box csdn-tracking-statistics"> --><div class="article-list">
<div class="article-list"> 是 <h4> 标签的父节点
<div class="article-list"> 是 <a> 标签的孙节点
<h4> 是 <a> 标签的父节点
所以我们可以参照上面的常用规则写出://div[@class='article-list']//h4表达式,我们看到下图中的标题都已经选中了,这就证明我们写的表达式正确。
三:插件介绍
有人会发现我图片中出现黑色的框,这是谷歌的一个插件(xpath helper), 在chrome浏览器安装好xpath helper插件后(科学访问,人人有责), 点击 Ctrl + Shift + X 激活 XPath Helper 的控制台,然后您可以在 Query 文本框中输入相应 XPath 进行调试了,提取的结果将被显示在旁边的 Result 文本框中,可以实时检测自己的表达式是否正确。

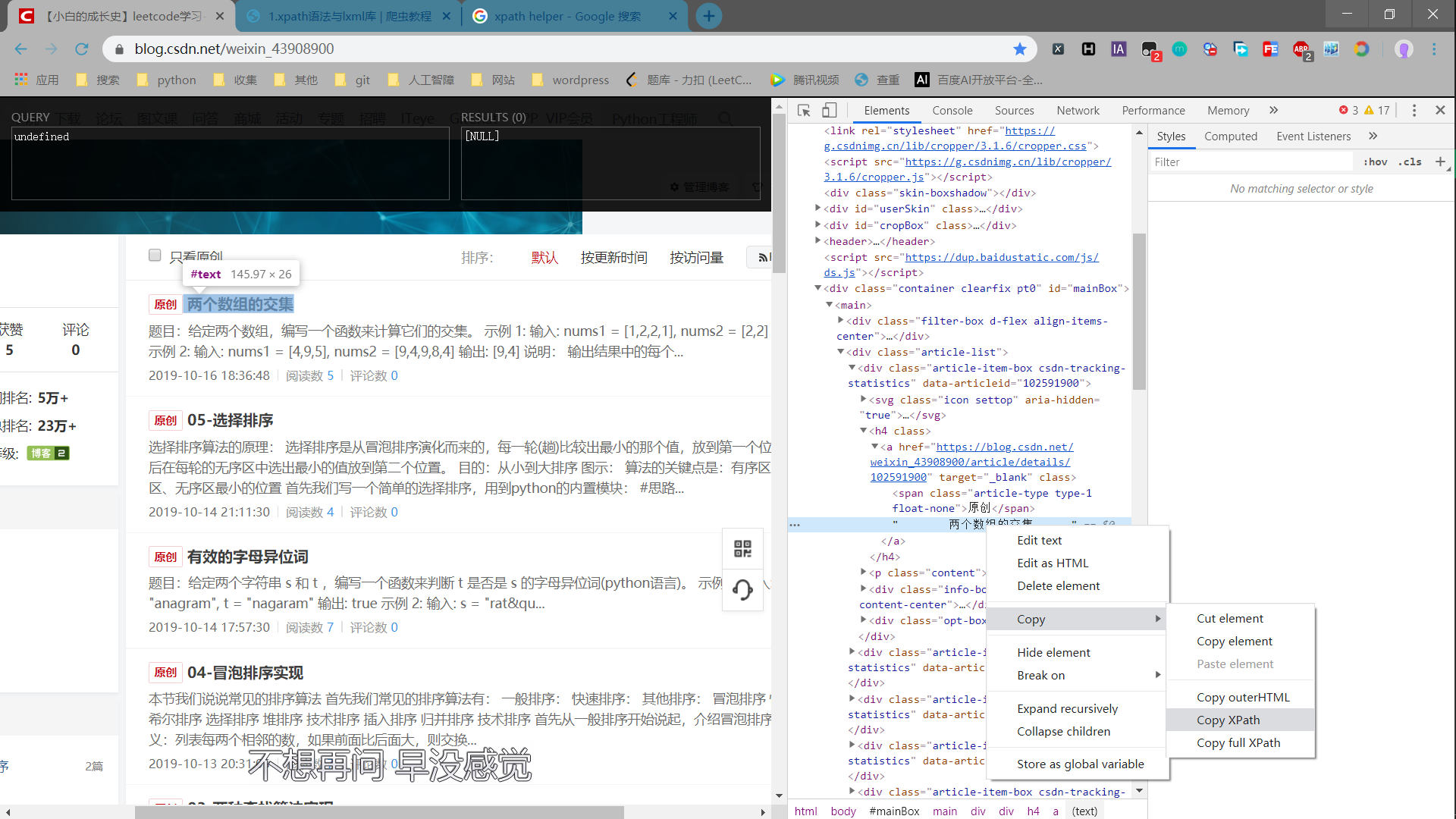
最后有个小补充,如果你不想写xpath语法,你还可以F12,选中你想要的信息右击,copy--copy xpath,缺点是没有手写的简洁,copy的比较繁琐,不利于阅读。
爬虫系列----未完待续.......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号