

软件工程寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践S班 |
|---|---|
| 这个作业要求在哪里 | 点这你就知道了 |
| 这个作业的目标 | <阅读《构建之法》提出问题,编写程序,学会使用github管理代码> |
| 其他参考文献 | 腾讯C++规范参考 |
part1:阅读《构建之法》并提问
Q1.构建之法8.3获取用户需求中,提到“A/B测试”以及其弱点,但我认为判断A/B测试是否做过头很难,当你意识到
做过头时候,用户都跑光了。(比如我玩的梦幻西游,就因为全新的建模导致一群人弃坑)所以选择性的拿老用户当
“小白鼠”会不会更合适?(比如美团试探性的增加老用户的配送费)
Q2.构建之法8.7的WBS(分治)中提到做好WBS的要点中,认为“要从结果出发,而不是团队的活动” 的意思是,两者
是优先级先后关系吗?如果是这样我认为,其实团队的活动也很重要,因为整个工程肯定得交流的好,分工合理才能
井井有条否则做出来也是残次品。后期维护沟通也麻烦。
Q3.构建之法16.3.4中提出产品的生命周期各个阶段,通过“动量”“加速度”来判断,产品到底属于成熟期,还是衰弱
期,但一般来说衰弱期再往后留下的都是老用户,如果是游戏,他们往往会舍不得离开,如果此时导入新鲜血液,刺
激消费,或许某些情况下,会比文章中提到的“以低成本维护产品”会好呢?亦或者像很多国产游戏一样是在快关服的
时候宰一刀老玩家跑路。
Q4构建之法16.1.3中提出创新之人,如何让别人接受自己的创新中提到“目前大众习惯,已有系统是否兼容”。这句话
的意思我感觉自我矛,。这样子只能算是改进,而不是创新不是吗?
Q5.在构建之法NABC框架模式中有人提到的“D”推广,指出Delivery是在前人实践后意识到Delivery的重要性,那这个
D是跟开发人员 完全无关的吧,在我的认知中推广似乎和技术层面没什么太大的关系吧.所以书中只是提及一下子,并没
有什么太深刻的意思是吗?
附加题: “关于goto语句的争论“”
软件工程热门以来,就有一个一直很火被历代程序员交流的话题——"goto语句"。1974年,D·E·克努斯对于GOTO语句争论
作了全面公正的评述,其基本观点是:不加限制地使用GOTO语句,特别是使用往回跳的GOTO语句,会使程序结构难于理解
,在这种情形,应尽量避免使用GOTO语句。goto语句一直都是讨论的热点,其实我还是觉得,存在即合理,既然goto被人
诟病这么多年仍然没被彻底的摈弃,说明还是有一定的用武之地,就比如跳出很多层的循环,如果不用goto就得额外多设
置很多的判断条件,循环的代码的可读性上就会大大下降,也不便于维护。所以虽然我不怎么用,也会尽量避免,但我还
是觉得goto语句正如D·E·克努斯的意见应该尽量避免,而不是完全不用。
part2:WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(h) | 实际耗时(h) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 25h | 43h |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 2h | 1h |
| • Design Spec | • 生成设计文档 | 0.5h | 0.5h |
| • Design Review | • 设计复审 | 0.3h | 0.5h |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 0.2h | 0.5h |
| • Design | • 具体设计 | 5h | 8h |
| • Coding | • 具体编码 | 5h | 10h |
| • Code Review | • 代码复审 | 5h | 12h |
| • Test | • 测试(自我测试,修改代码,提交修改) | 5h | 6h |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 0.5h | 1h |
| • Size Measurement | • 计算工作量 | 0.5h | 1.5h |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 1h | 2h |
| 合计 | 25h | 43h |
解题思路描述
题目主要要求的无非三点,字符数,单词总数,行数。字符数一个个字符的接收然后统计
行数的话用的是getline方法一行行分析的也没什么太大的问题。这个单词总数有点歧义
本想用 两个空格 来锁住一个单词,但后来发现123file123这种不能算作单词,后根据
需求先把两个空格之间的提取出来content,先检测长度是否大于4.因为“ is” 这种的其
实也不能算作单词再检测content的前四位是否都是字母用ASCII来检测
代码规范制定链接
设计与实现过程
统计字符数
fstream infile(argv[1],ios::in);
//以下为fstream关键代码
while(!infile.eof())
{
char ch;
infile.get( ch );
a++;
}
a-=1;//因为会多读入一个 \0结尾 不在本次要求当中
统计行数
while(outfile.getline(str,256))
{
int tmp = 0;
for(int i = 0; i < strlen(str); i++)
{
if(isnum_str(str[i]))
{
//cnt[0]++; //曾经想用cnt[0]记字符数后来发现行不通
tmp++; //统计字符数,tmp局部变量用来区分是不是一个空行。
}
}
if(tmp != 0){
cnt[2]++; //统计行数
}
tmp = 0;
}
统计单词数 可以分为判断是否是一个单词,以及记录是单词的单词两个部分
第一部分判断的主要代码
string::size_type start = 0;
string::size_type end = eachline.find_first_of(".,?! ");
int flag=0;
while (end != string::npos) //npos就是这一行到头啦;
{
string content = eachline.substr(start, end - start);
map<string, int>::iterator it = mapA.find(content);
if(content.length()>3&&is_lower_alpha(content[0])&&is_lower_alpha(content[1])
&&is_lower_alpha(content[2])&&is_lower_alpha(content[3]))//判断是否前四个都是字符
{
if (it == mapA.end())
{
mapA.insert(pair<string, int>(content, 1));//赋值的时候只接受pair类型;
} else
{
++it->second;
}
}
start = end + 1;
end = eachline.find_first_of(".,?! ", start);
}
第二部分 记录单词总数的代码:
利用map的特性会根据key自动排序,就省去自己从大到小排序词频了,其中mapA是初记录
也是排序用样长度则首字母以a b c 这样排序 mapb则在mapa基础上再将 单词以频率降
序排列
word_count=0;
for (map<string, int>::iterator it1 = mapA.begin(); it1 != mapA.end();++it1)
{
mapB.insert(pair<int, string>(it1->second, it1->first));//方便map自动根据出现次数排序
word_count+=it1->second;//顺手统计
}
性能改进
最初判断是否符合“单词的定义”,我将所有的条件层层嵌套
if(is_lower_alpha(content[0])){
if(is_lower_alpha(content[1])){
if(is_lower_alpha(content[2])){
if(is_lower_alpha(content[3])){
++it->second;
}
}
}
}
这样子实在是太浪费时间了,层层嵌套,看似逻辑有序,实则避免了很多不必要的判断
例如如果content本身就不到四个字符 比如is the 这种 又何谈单词?于是我将所有
判断条件结合在一切少去很多不必要的 判断
if(content.length()>3&&is_lower_alpha(content[0])&&is_lower_alpha(content[1])
&&is_lower_alpha(content[2])&&is_lower_alpha(content[3]))
单元测试
单元测试为了方便快捷,现设计出自我测试的函数
void test(ofstream &t){//测试函数
for(int a=0;a<100000000;a++){
t<<"ddaa ";
if(a%50==0&&a!=0){//每行字符数
t<<"\n";
}
}
}
- 对于一些小的测试就不放出统计时间了直接上图

异常测试,抛出提示

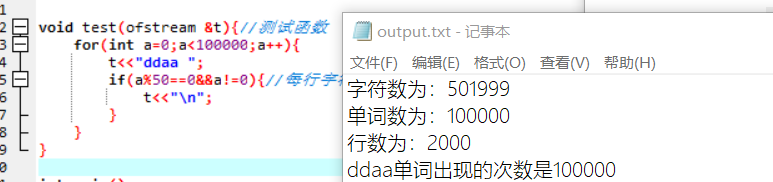
识别空白行非有效行,以及各种标识符
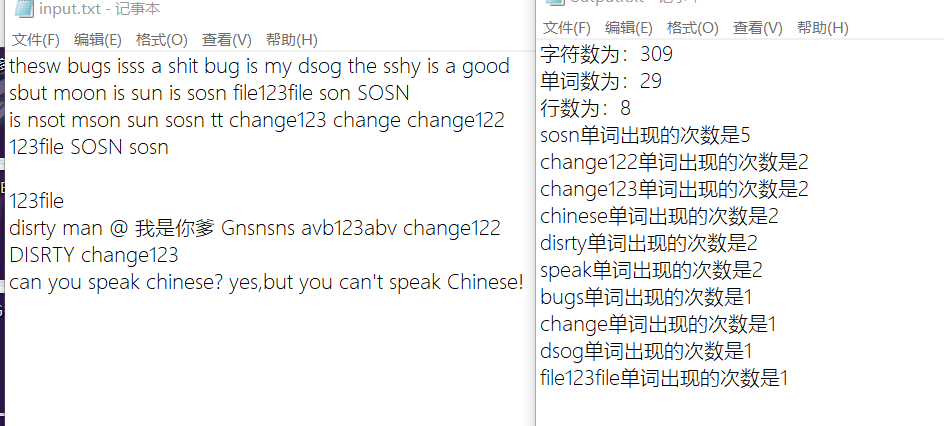
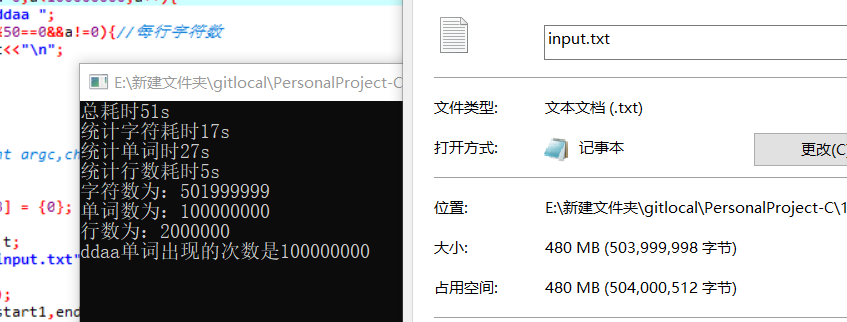
大数据下的测试程序性能5000w左右的字符程序在5s左右可以算出,由于vs的单元测试方法与其类似
但并无代码覆盖率的功能我就利用c++自带的clock来计算 对应模块从开始到结束 所花的时间

5e 相当于500M的文件需要50s左右可见 计算功能的时间复杂度是线性递增的
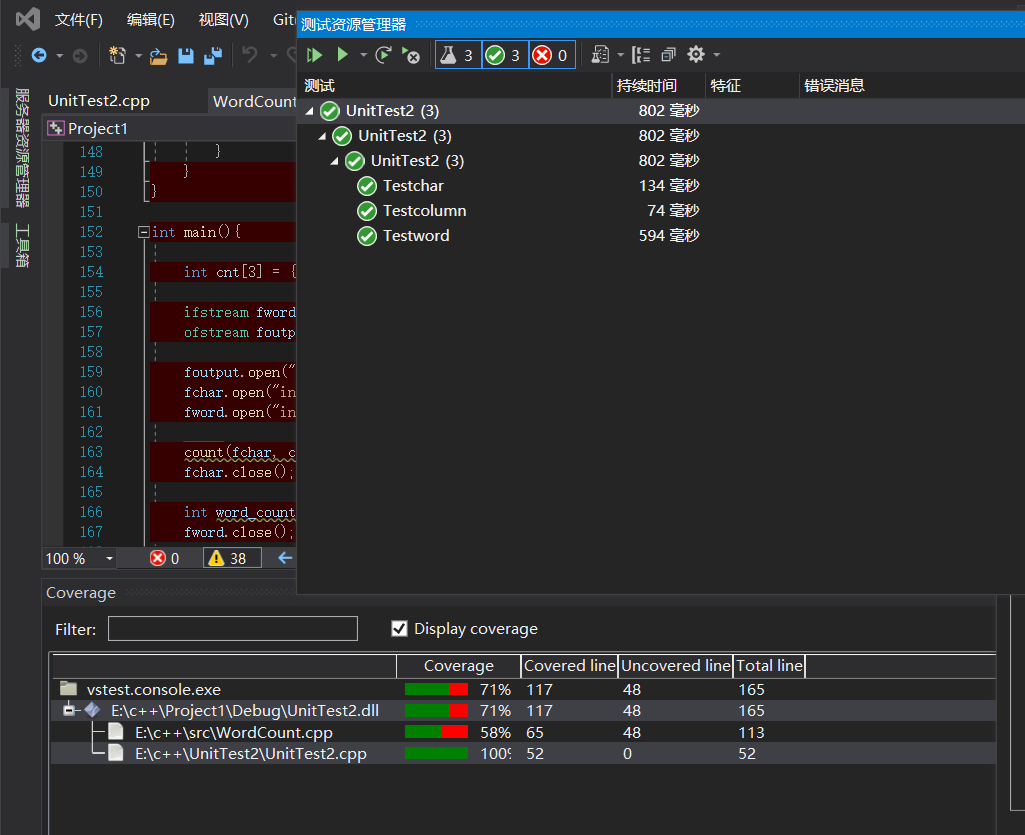
代码覆盖率如下
异常处理说明
本次的异常,程序经测试会自动忽略中文,所遇到的异常错误,目前为止只是文件格式异常
或者是失误操作,一般来说文本内容不会集中在一行,所以有些文本例如一行单词太多的。
会直接抛出异常,此时output文件中会提示错误
心路历程与收获
通过本次的作业,我意识到了团队合作的重要性,我和预期相差最大的就是代码复审,当我选择和我同学连麦一起做的时候
我总会被他看似找茬,实则有用的建议不断的重写,重写再重写代码,合作伙伴总能想到我很多想不到的测试点,这也让我
花了更多的时间在复审,和测试上。
同时也是第一次接触单元测试,在我好不容易搞清楚如何用vs进行c++的单元测试后(实际上我又花了好多时间重装,下载
vs包括清c盘)我发现单元测试的原理不过是测试每个接口的性能,既然如此,我干脆就自己写一个测试行数,一是因为c盘满了vs
很多东西装不上,而且下载的特别慢因为不是国内的网络,而且我找不到代码覆盖率在哪。这也说明了这次作业我的另外一个弊
端,就是起步慢。因为过年那几天实在不想写,导致后面没有很多时间去弄清楚一些,根本没搞懂的东西。(我重装vs测试的时
候已经是快截止了)而且装了也测试不了代码覆盖率。可能以后更适合我的方法是笨鸟先飞吧。
同时我也意识到代码规范性的东西重要性,最显著的区别就是,我其实是先写代码再改规范性的。这就让我在改规范性之前
自己都有点看不懂自己的代码(因为是断断续续做的)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号