NTU ML2023Spring Part3.14 lifelong learning
示例代码中需要实现 MAS.
class mas(object):
"""
@article{aljundi2017memory,
title={Memory Aware Synapses: Learning what (not) to forget},
author={Aljundi, Rahaf and Babiloni, Francesca and Elhoseiny, Mohamed and Rohrbach, Marcus and Tuytelaars, Tinne},
booktitle={ECCV},
year={2018},
url={https://eccv2018.org/openaccess/content_ECCV_2018/papers/Rahaf_Aljundi_Memory_Aware_Synapses_ECCV_2018_paper.pdf}
}
"""
def __init__(self, model: nn.Module, dataloader, device, prev_guards=[None]):
self.model = model
self.dataloader = dataloader
# extract all parameters in models
self.params = {n: p for n, p in self.model.named_parameters() if p.requires_grad}
# initialize parameters
self.p_old = {}
self.device = device
# save previous guards
self.previous_guards_list = prev_guards
# generate Omega(Ω) matrix for MAS
self._precision_matrices = self.calculate_importance()
# keep the old parameter in self.p_old
for n, p in self.params.items():
self.p_old[n] = p.clone().detach()
def calculate_importance(self):
precision_matrices = {}
# initialize Omega(Ω) matrix(all filled zero)
for n, p in self.params.items():
precision_matrices[n] = p.clone().detach().fill_(0)
for i in range(len(self.previous_guards_list)):
if self.previous_guards_list[i]:
precision_matrices[n] += self.previous_guards_list[i][n]
self.model.eval()
if self.dataloader is not None:
num_data = len(self.dataloader)
for data in self.dataloader:
self.model.zero_grad()
output = self.model(data[0].to(self.device))
################################################################
##### TODO: generate Omega(Ω) matrix for MAS. #####
################################################################
################################################################
loss = output.pow(2).sum()
loss.backward()
for n, p in self.model.named_parameters():
precision_matrices[n].data += abs(p.grad.data) / num_data
precision_matrices = {n: p for n, p in precision_matrices.items()}
return precision_matrices
def penalty(self, model: nn.Module):
loss = 0
for n, p in model.named_parameters():
_loss = self._precision_matrices[n] * (p - self.p_old[n]) ** 2
loss += _loss.sum()
return loss
def update(self, model):
# do nothing
return
其他的都实现好了,也不用做任何调整,跑 2~3h 即可.
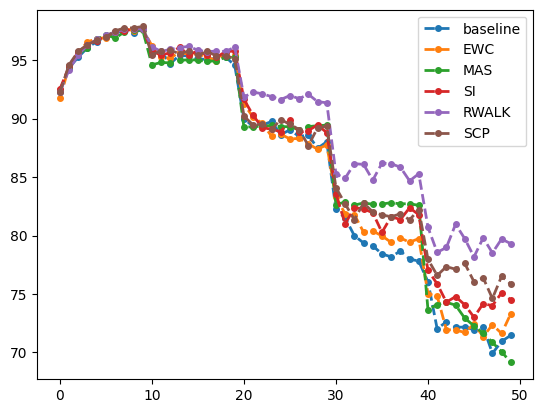
这个 MAS 就是逊,连 baseline 都打不过(也可能是实现错了?).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号