
数据分析3
kmeans:
import numpy as np
import random
import matplotlib.pyplot as plt
def distance(point1, point2): # 计算距离(欧几里得距离)
return np.sqrt(np.sum((point1 - point2) ** 2))
def k_means(data, k, max_iter=10000):
centers = {} # 初始聚类中心
# 初始化,随机选k个样本作为初始聚类中心。 random.sample(): 随机不重复抽取k个值
n_data = data.shape[0] # 样本个数
for idx, i in enumerate(random.sample(range(n_data), k)):
# idx取值范围[0, k-1],代表第几个聚类中心; data[i]为随机选取的样本作为聚类中心
centers[idx] = data[i]
# 开始迭代
for i in range(max_iter): # 迭代次数
print("开始第{}次迭代".format(i+1))
clusters = {} # 聚类结果,聚类中心的索引idx -> [样本集合]
for j in range(k): # 初始化为空列表
clusters[j] = []
for sample in data: # 遍历每个样本
distances = [] # 计算该样本到每个聚类中心的距离 (只会有k个元素)
for c in centers: # 遍历每个聚类中心
# 添加该样本点到聚类中心的距离
distances.append(distance(sample, centers[c]))
idx = np.argmin(distances) # 最小距离的索引
clusters[idx].append(sample) # 将该样本添加到第idx个聚类中心
pre_centers = centers.copy() # 记录之前的聚类中心点
for c in clusters.keys():
# 重新计算中心点(计算该聚类中心的所有样本的均值)
centers[c] = np.mean(clusters[c], axis=0)
is_convergent = True
for c in centers:
if distance(pre_centers[c], centers[c]) > 1e-8: # 中心点是否变化
is_convergent = False
break
if is_convergent == True:
# 如果新旧聚类中心不变,则迭代停止
break
return centers, clusters
def predict(p_data, centers): # 预测新样本点所在的类
# 计算p_data 到每个聚类中心的距离,然后返回距离最小所在的聚类。
distances = [distance(p_data, centers[c]) for c in centers]
return np.argmin(distances)
x=np.random.randint(0,high=10,size=(200,2))
centers,clusters=k_means(x,3)
print(centers)
clusters
for center in centers:
plt.scatter(centers[center][0],centers[center][1],marker='*',s=150)
colors=['r','b','y','m','c','g']
for c in clusters:
for point in clusters[c]:
plt.scatter(point[0],point[1],c=colors[c])
数据探索:
import pandas as pd
import matplotlib.pyplot as plt
datafile="C:/Users/admin/Documents/WeChat Files/wxid_b0fz4hqogenr22/FileStorage/File/2023-03/air_data.csv"
resultfile="C:/Users/admin/Documents/WeChat Files/wxid_b0fz4hqogenr22/FileStorage/File/2023-03/explore.csv"
data=pd.read_csv(datafile,encoding='utf-8')
explore=data.describe(percentiles=[],include='all').T
explore['null']=len(data)-explore['count']
explore=explore[['null','max','min']]
explore.colmns=[u'空值数',u'最大值',u'最小值']
explore.to_csv(resultfile)
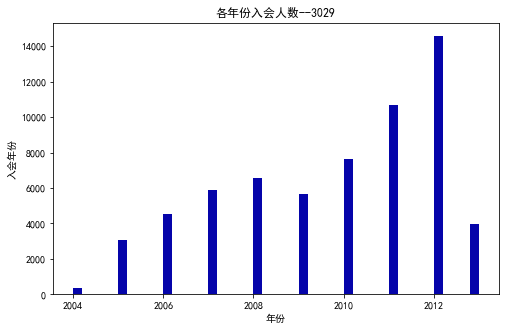
from datetime import datetime
ffp=data['FFP_DATE'].apply(lambda x:datetime.strptime(x,'%Y/%m/%d'))
ffp_year=ffp.map(lambda x:x.year)
fig=plt.figure(figsize=(8,5))
plt.rcParams['font.sans-serif']='SimHei'
plt.rcParams['axes.unicode_minus']=False
plt.hist(ffp_year,bins='auto',color='#0504aa')
plt.xlabel('年份')
plt.ylabel('入会年份')
plt.title('各年份入会人数--3029')
plt.show()
plt.close
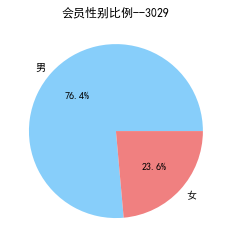
male=pd.value_counts(data['GENDER'])['男']
female=pd.value_counts(data['GENDER'])['女']
fig=plt.figure(figsize=(7,4))
plt.pie([male,female],labels=['男','女'],colors=['lightskyblue','lightcoral'],autopct='%1.1f%%')
plt.title('会员性别比例--3029')
plt.show()
plt.close
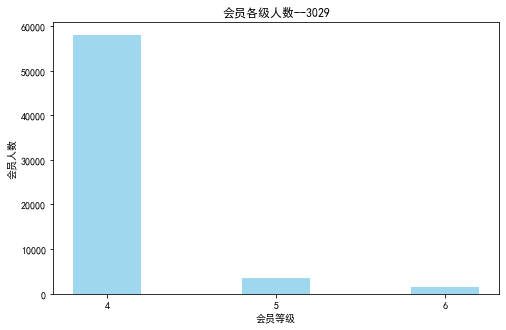
lv_four=pd.value_counts(data['FFP_TIER'])[4]
lv_five=pd.value_counts(data['FFP_TIER'])[5]
lv_six=pd.value_counts(data['FFP_TIER'])[6]
fig=plt.figure(figsize=(8,5))
plt.bar(x=range(3),height=[lv_four,lv_five,lv_six],width=0.4,alpha=0.8,color='skyblue')
plt.xticks([index for index in range(3)],['4','5','6'])
plt.xlabel('会员等级')
plt.ylabel('会员人数')
plt.title('会员各级人数--3029')
plt.show()
plt.close
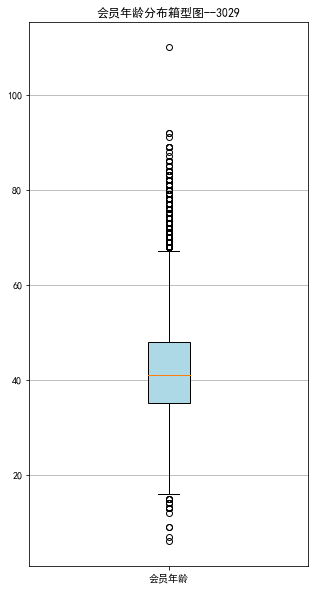
age=data['AGE'].dropna()
age=age.astype('int64')
fig=plt.figure(figsize=(5,10))
plt.boxplot(age,
patch_artist=True,
labels=['会员年龄'],
boxprops={'facecolor':'lightblue'})
plt.title('会员年龄分布箱型图--3029')
plt.grid(axis='y')
plt.show()
plt.close
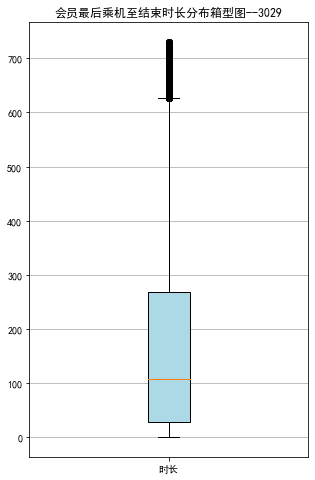
lte=data['LAST_TO_END']
fc=data['FLIGHT_COUNT']
sks=data['SEG_KM_SUM']
fig=plt.figure(figsize=(5,8))
plt.boxplot(lte,
patch_artist=True,
labels=['时长'],
boxprops={'facecolor':'lightblue'})
plt.title('会员最后乘机至结束时长分布箱型图--3029')
plt.grid(axis='y')
plt.show()
plt.close
fig=plt.figure(figsize=(5,8))
plt.boxplot(fc,
patch_artist=True,
labels=['飞行次数'],
boxprops={'facecolor':'lightblue'})
plt.title('会员飞行次数分布箱型图--3029')
plt.grid(axis='y')
plt.show()
plt.close

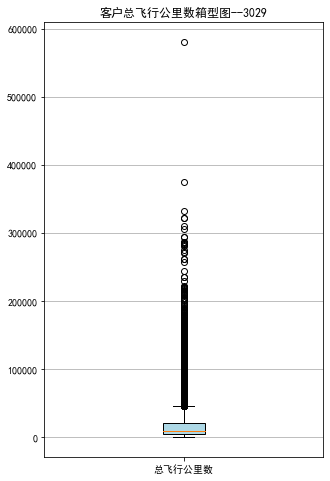
fig=plt.figure(figsize=(5,8))
plt.boxplot(sks,
patch_artist=True,
labels=['总飞行公里数'],
boxprops={'facecolor':'lightblue'})
plt.title('客户总飞行公里数箱型图--3029')
plt.grid(axis='y')
plt.show()
plt.close
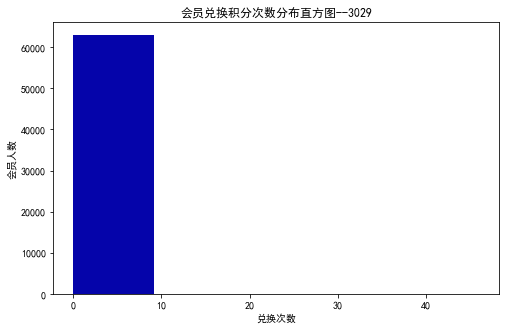
ec=data['EXCHANGE_COUNT']
fig=plt.figure(figsize=(8,5))
plt.hist(ec,bins=5,color='#0504aa')
plt.xlabel('兑换次数')
plt.ylabel('会员人数')
plt.title('会员兑换积分次数分布直方图--3029')
plt.show()
plt.close
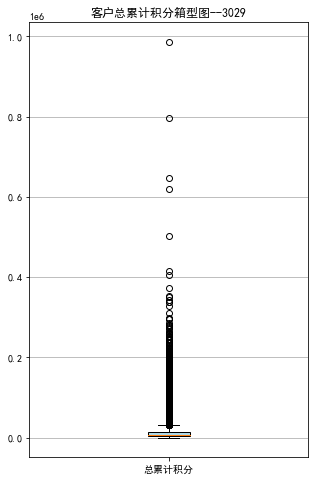
ps=data['Points_Sum']
fig=plt.figure(figsize=(5,8))
plt.boxplot(ps,
patch_artist=True,
labels=['总累计积分'],
boxprops={'facecolor':'lightblue'})
plt.title('客户总累计积分箱型图--3029')
plt.grid(axis='y')
plt.show()
plt.close
data_corr=data[['FFP_TIER','FLIGHT_COUNT','LAST_TO_END','SEG_KM_SUM','EXCHANGE_COUNT','Points_Sum']]
age1=data['AGE'].fillna(0)
data_corr['AGE']=age1.astype('int64')
data_corr['ffp_year']=ffp_year
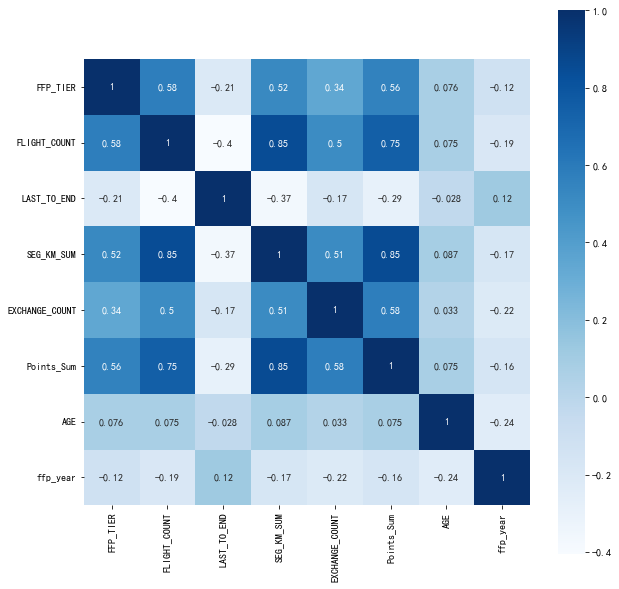
dt_corr=data_corr.corr(method='pearson')
print('相关性矩阵为:\n',dt_corr)
import seaborn as sns
plt.subplots(figsize=(10,10))
sns.heatmap(dt_corr,annot=True,vmax=1,square=True,cmap='Blues')
plt.show()
plt.close
数据清洗:
import numpy as np
import pandas as pd
datafile="C:/Users/admin/Documents/WeChat Files/wxid_b0fz4hqogenr22/FileStorage/File/2023-03/air_data.csv"
cleanedfile=r"C:\Users\admin\Documents\WeChat Files\wxid_b0fz4hqogenr22\FileStorage\File\2023-03\data_cleaned.csv"
airline_data=pd.read_csv(datafile,encoding='utf-8')
print('原始数据的形状为:',airline_data.shape)
airline_notnull=airline_data.loc[airline_data['SUM_YR_1'].notnull()&
airline_data['SUM_YR_2'].notnull(),:]
print('删除缺失记录后的数据形状为:',airline_notnull.shape)
index1=airline_notnull['SUM_YR_1']!=0
index2=airline_notnull['SUM_YR_2']!=0
index3=(airline_notnull['SEG_KM_SUM']>0)&(airline_notnull['avg_discount']!=0)
index4=airline_notnull['AGE']>100
airline=airline_notnull[(index1|index2)&index3&~index4]
print('数据清洗后数据形状为:',airline.shape)
airline.to_csv(cleanedfile)

airline.to_csv(cleanedfile)
airline=pd.read_csv(cleanedfile,encoding='utf-8')
airline_selection=airline[['FFP_DATE','LOAD_TIME','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]
print('筛选的属性前五行为:\n',airline_selection.head())

L=pd.to_datetime(airline_selection['LOAD_TIME']) - \
pd.to_datetime(airline_selection['FFP_DATE'])
L=L.astype('str').str.split().str[0]
L=L.astype('int')/30
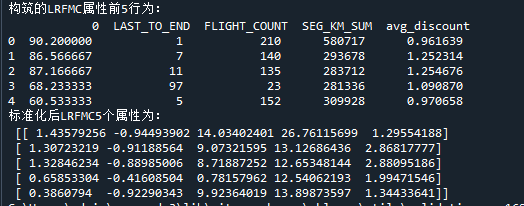
airline_features=pd.concat([L,airline_selection.iloc[:,2:]],axis=1)
print('构筑的LRFMC属性前5行为:\n',airline_features.head())
from sklearn.preprocessing import StandardScaler
data=StandardScaler().fit_transform(airline_features)
np.savez(r"C:\Users\admin\Documents\WeChat Files\wxid_b0fz4hqogenr22\FileStorage\File\2023-03\airline_scale.npz",data)
print('标准化后LRFMC5个属性为:\n',data[:5,:])
Kmeans聚类:
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
airline_scale=np.load(r"C:\Users\admin\Documents\WeChat Files\wxid_b0fz4hqogenr22\FileStorage\File\2023-03\airline_scale.npz")['arr_0']
k=5
kmeans_model=KMeans(n_clusters=k,n_init=4,random_state=123)
fit_kmeans=kmeans_model.fit(airline_scale)
kmeans_cc=kmeans_model.cluster_centers_
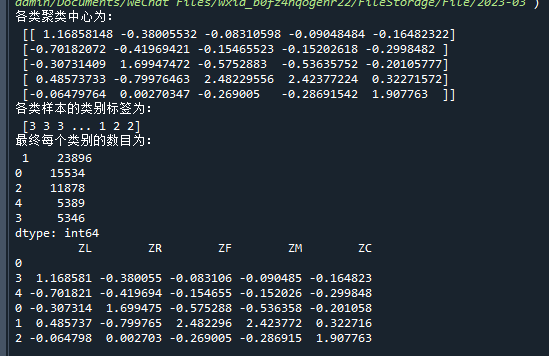
print('各类聚类中心为:\n',kmeans_cc)
kmeans_labels=kmeans_model.labels_
print('各类样本的类别标签为:\n',kmeans_labels)
r1=pd.Series(kmeans_model.labels_).value_counts()
print('最终每个类别的数目为:\n',r1)
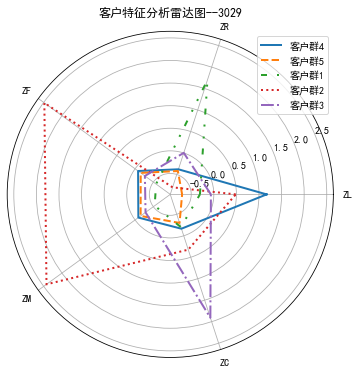
cluster_center=pd.DataFrame(kmeans_model.cluster_centers_,\
columns=['ZL','ZR','ZF','ZM','ZC'])
cluster_center.index=pd.DataFrame(kmeans_model.labels_).\
drop_duplicates().iloc[:,0]
print(cluster_center)
import matplotlib.pyplot as plt
labels=['ZL','ZR','ZF','ZM','ZC']
legen=['客户群'+str(i+1)for i in cluster_center.index]
lstype=['-','--',(0,(3,5,1,5,1,5)),':',"-."]
kinds=list(cluster_center.iloc[:,0])
cluster_center=pd.concat([cluster_center,cluster_center[['ZL']]],axis=1)
centers=np.array(cluster_center.iloc[:,0:])
n=len(labels)
angle=np.linspace(0,2*np.pi,n,endpoint=False)
angle=np.concatenate((angle,[angle[0]]))
fig=plt.figure(figsize=(8,6))
ax=fig.add_subplot(111,polar=True)
plt.rcParams['font.sans-serif']='SimHei'
plt.rcParams['axes.unicode_minus']=False
for i in range(len(kinds)):
ax.plot(angle,centers[i],linestyle=lstype[i],linewidth=2,label=kinds[i])
ang=angle*180/np.pi
ax.set_thetagrids(ang[:-1],labels)
plt.title('客户特征分析雷达图--3029')
plt.legend(legen)
plt.show()
plt.close

 浙公网安备 33010602011771号
浙公网安备 33010602011771号