攻防世界XCTF刷题纪录
攻防世界xctf刷题记录
难度1
ereere
难度1
用8.3的IDA 反编译不出来,用的IDA9.0
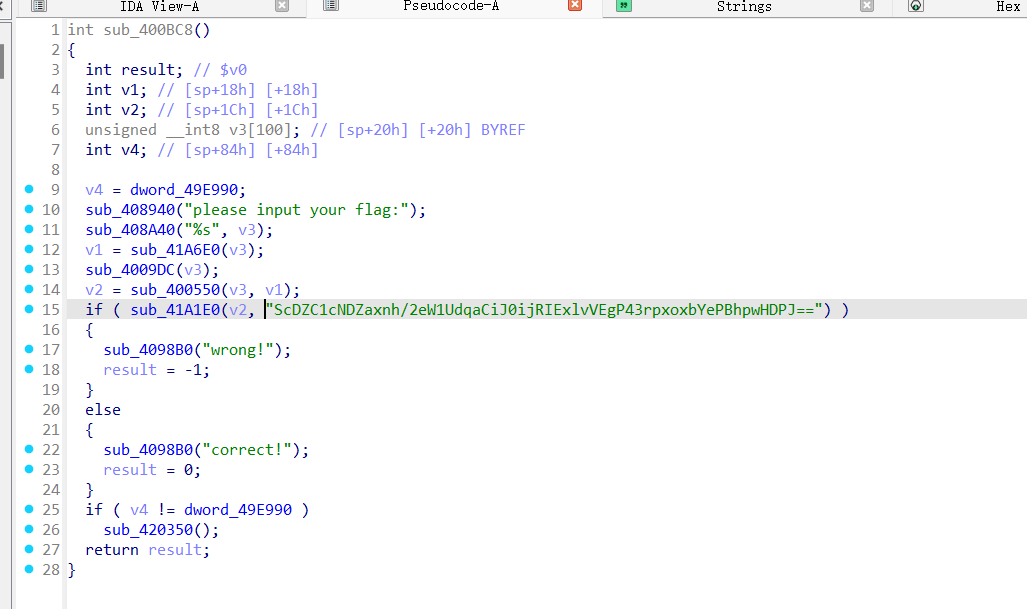
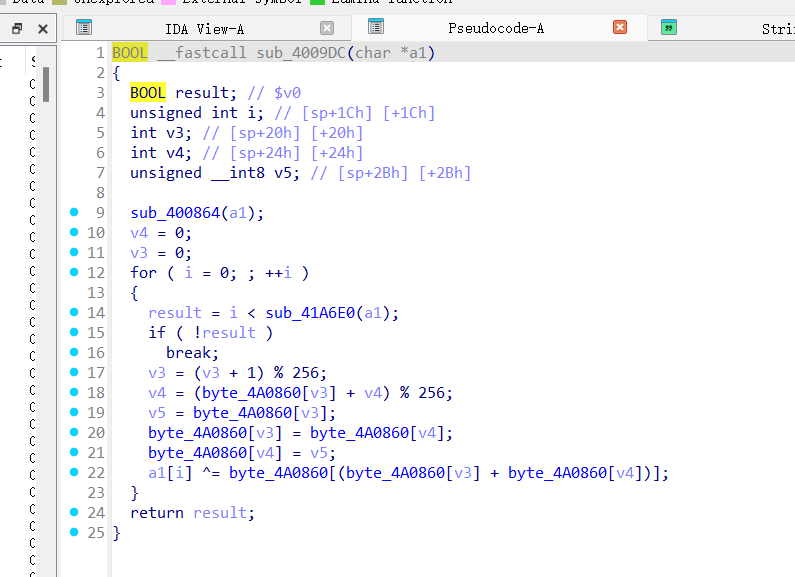
sub_4009DC这个函数有点东西,%256不用看一眼RC4
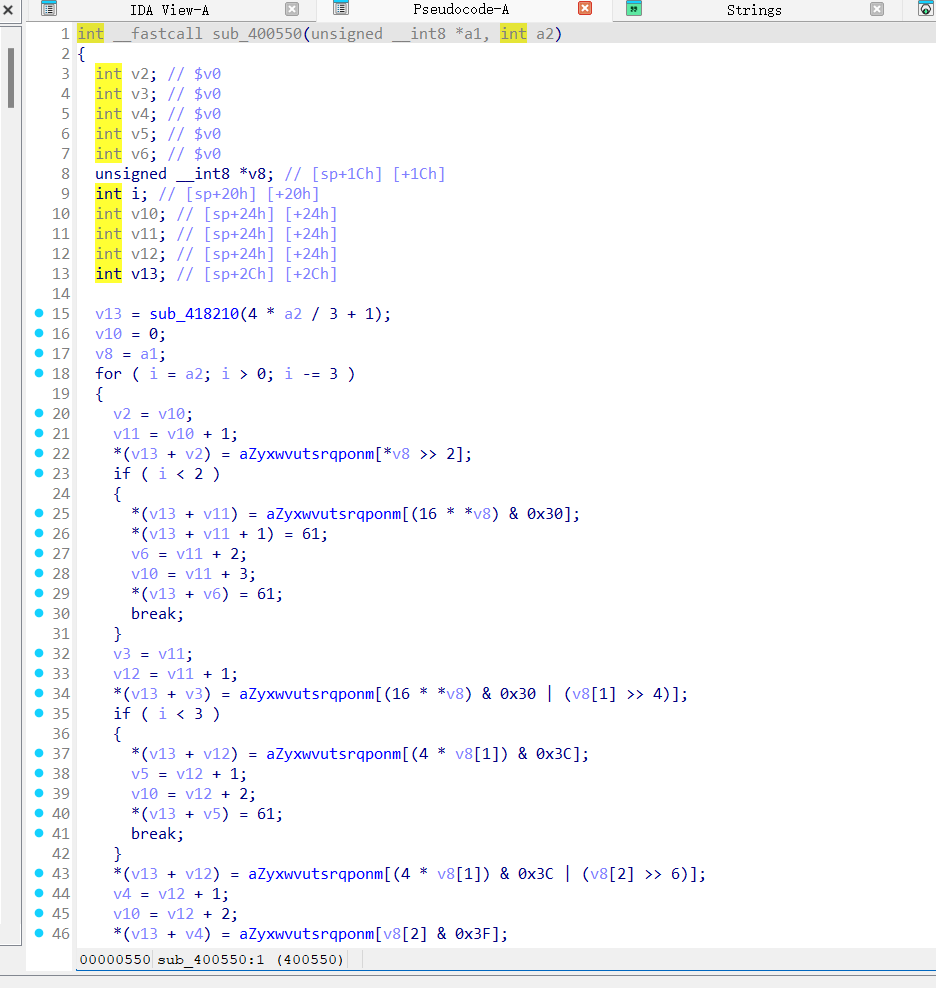
这个函数应该是base64,只不过表是魔改的
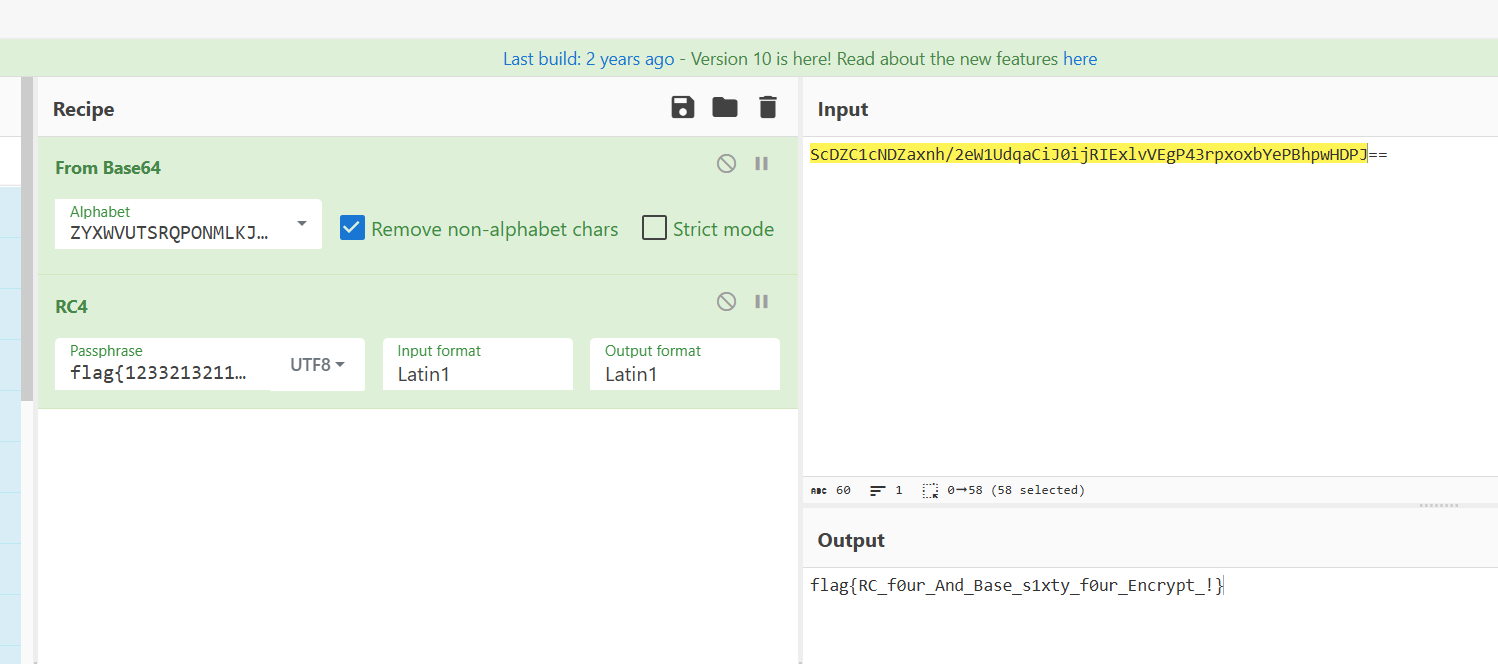
bad_python
难度1
这tm是难度1?我愿称为难度2(
题目给的pyc文件是有问题的,疑似修改了前缀头

修改成这样再用在线Pyc转py就行
# Visit https://www.lddgo.net/string/pyc-compile-decompile for more information
# Python 3.6 (3379)
from ctypes import *
from Crypto.Util.number import bytes_to_long
from Crypto.Util.number import long_to_bytes
def encrypt(v, k):
v0 = c_uint32(v[0])
v1 = c_uint32(v[1])
sum1 = c_uint32(0)
delta = 195935983
for i in range(32):
v0.value += (v1.value << 4 ^ v1.value >> 7) + v1.value ^ sum1.value + k[sum1.value & 3]
sum1.value += delta
v1.value += (v0.value << 4 ^ v0.value >> 7) + v0.value ^ sum1.value + k[sum1.value >> 9 & 3]
return (
v0.value, v1.value)
if __name__ == "__main__":
flag = input("please input your flag:")
k = [255, 187, 51, 68]
if len(flag) != 32:
print("wrong!")
exit(-1)
a = []
for i in range(0, 32, 8):
v1 = bytes_to_long(bytes(flag[i:i + 4], "ascii"))
v2 = bytes_to_long(bytes(flag[i + 4:i + 8], "ascii"))
a += encrypt([v1, v2], k)
enc = [
4006073346, 2582197823, 2235293281, 558171287, 2425328816, 1715140098,
986348143, 1948615354]
for i in range(8):
if enc[i] != a[i]:
print("wrong!")
exit(-1)
print("flag is flag{%s}" % flag)
这一眼TEA啊
exp:
from Crypto.Util.number import bytes_to_long, long_to_bytes
from ctypes import c_uint32
def decrypt(v, k):
v0 = c_uint32(v[0])
v1 = c_uint32(v[1])
delta = 195935983
sum1 = c_uint32(delta * 32)
for i in range(32):
v1.value -= (v0.value << 4 ^ v0.value >> 7) + v0.value ^ sum1.value + k[sum1.value >> 9 & 3]
sum1.value -= delta
v0.value -= (v1.value << 4 ^ v1.value >> 7) + v1.value ^ sum1.value + k[sum1.value & 3]
return (v0.value, v1.value)
enc = [
4006073346, 2582197823, 2235293281, 558171287,
2425328816, 1715140098, 986348143, 1948615354
]
k = [255, 187, 51, 68]
flag_bytes = b''
for i in range(0, 8, 2):
v0, v1 = decrypt([enc[i], enc[i+1]], k)
# 转换为字节
part1 = long_to_bytes(v0)
part2 = long_to_bytes(v1)
# 补全不足4字节的部分
part1 = b'\x00' * (4 - len(part1)) + part1
part2 = b'\x00' * (4 - len(part2)) + part2
flag_bytes += part1 + part2
print("flag{%s}" % flag_bytes.decode('ascii'))
crypt
难度1
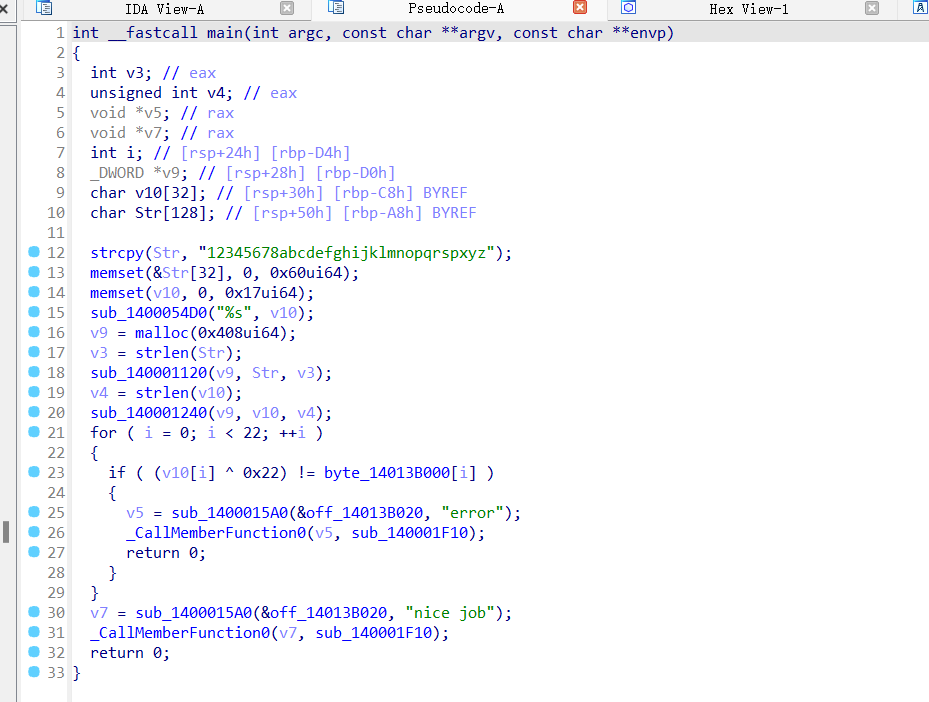
看看sub_140001120函数
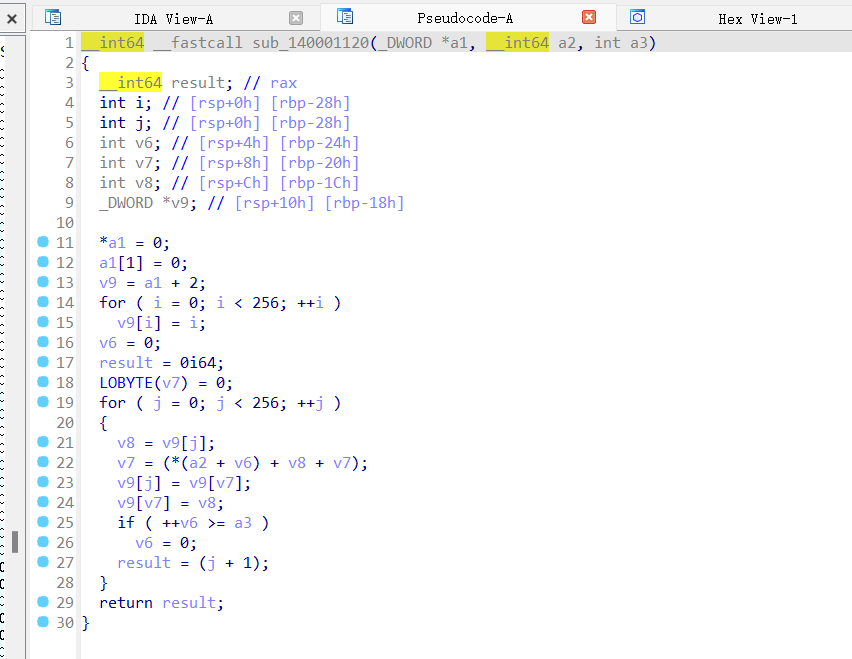
。。。RC4
解密流程:
1.xor 0x22
2.RC4解密
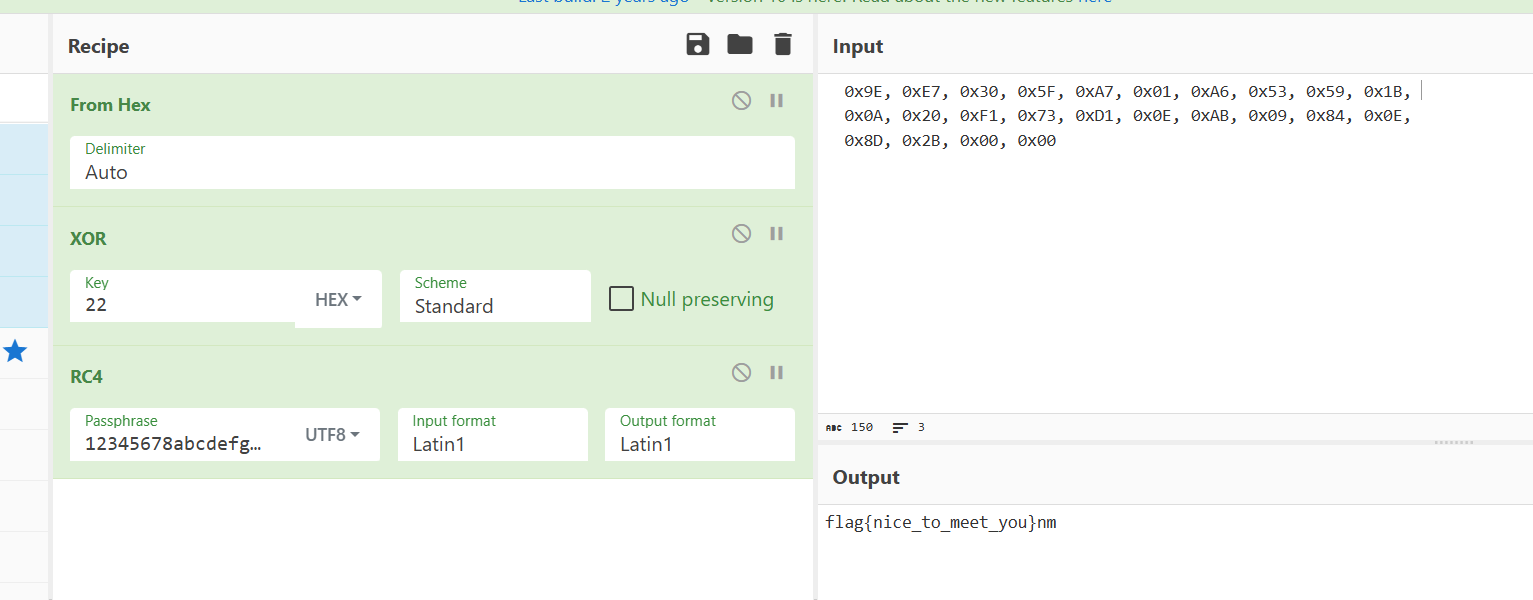
最后一个nm是什么?(恼)
1000Click
难度1
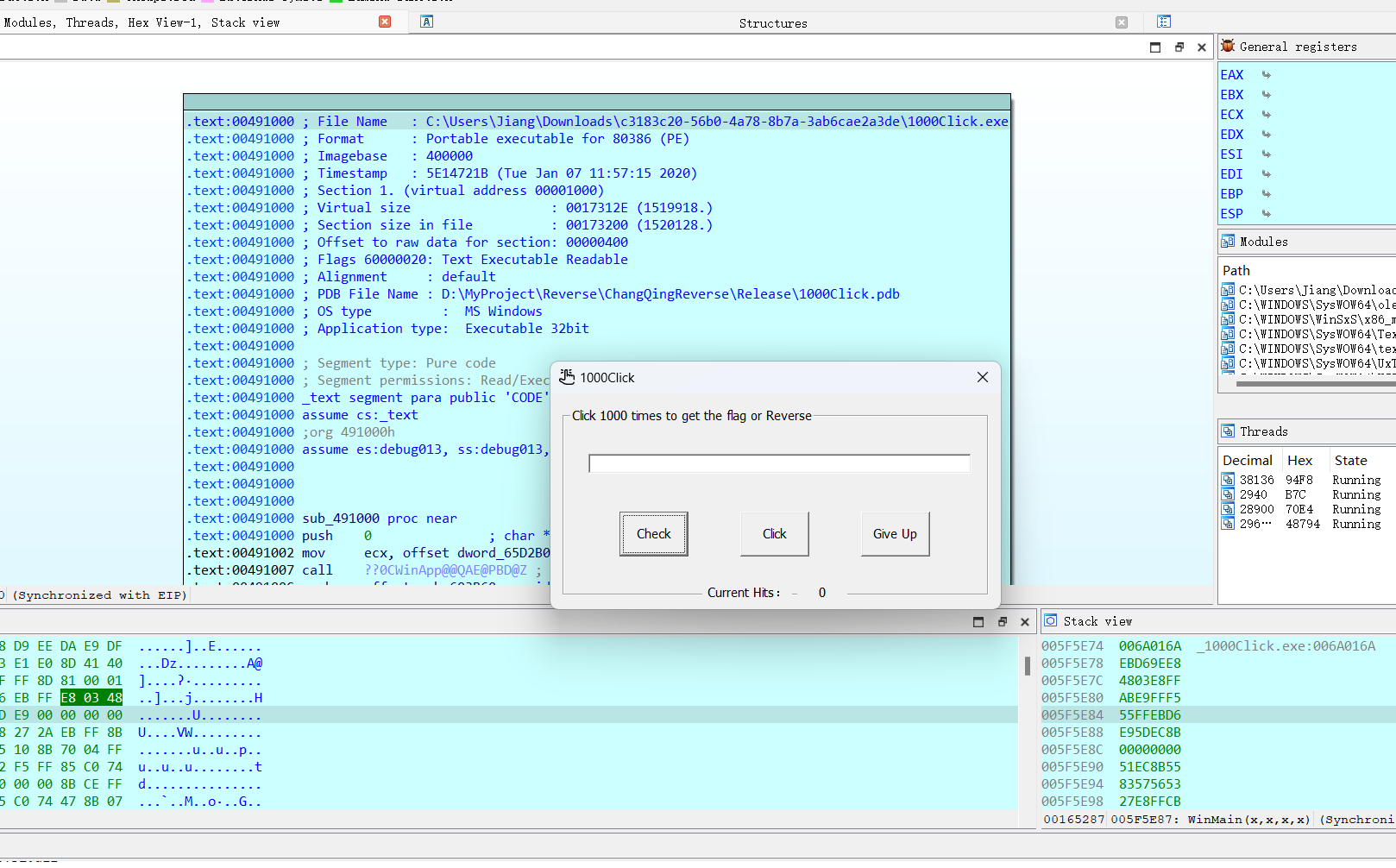
进去之后没看到什么有用的东西,先调试一下,好像要点1000次?
利用 CE修改一下
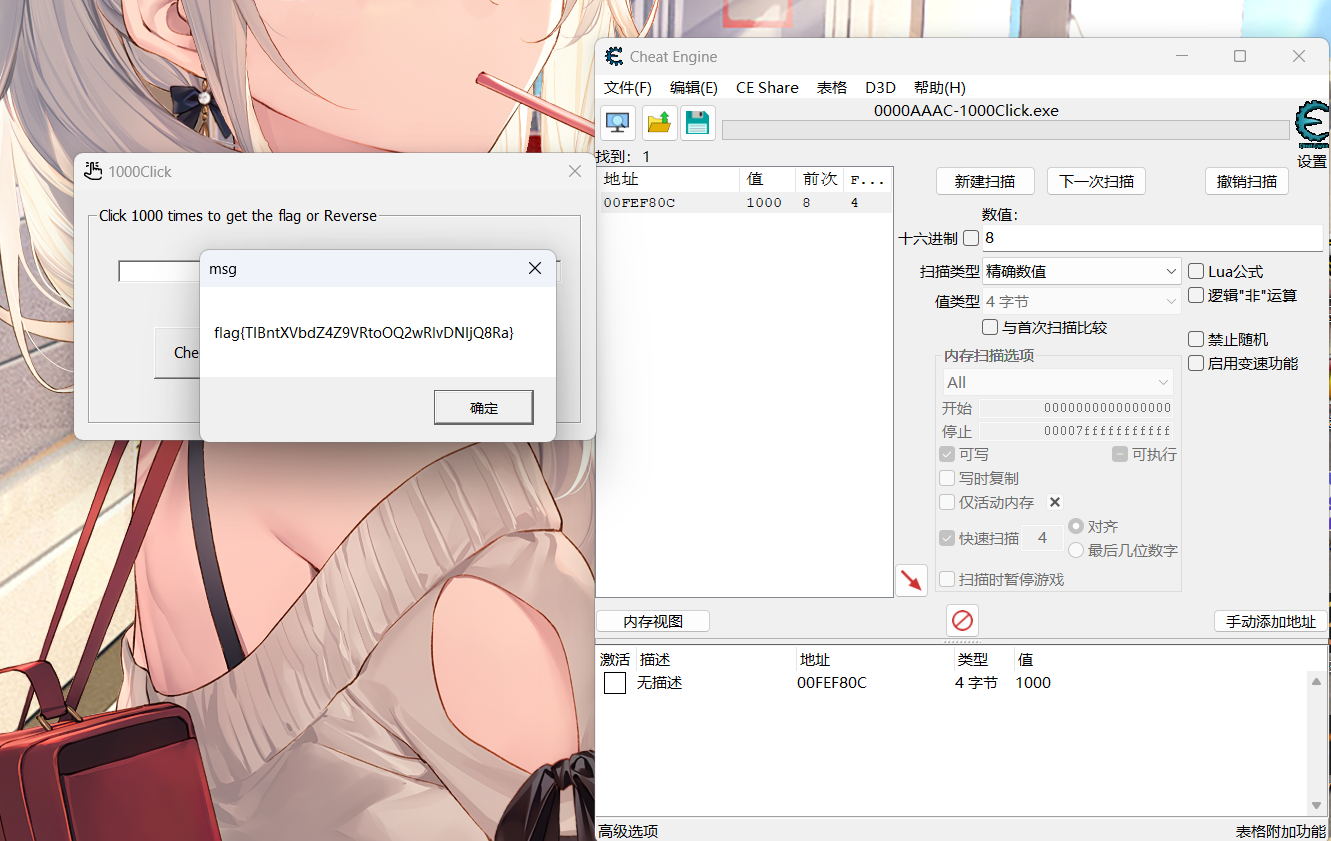
flag{TlBntXVbdZ4Z9VRto0Q2wRIvDNIjQ8Ra}
没绷住,其实我搜过flag
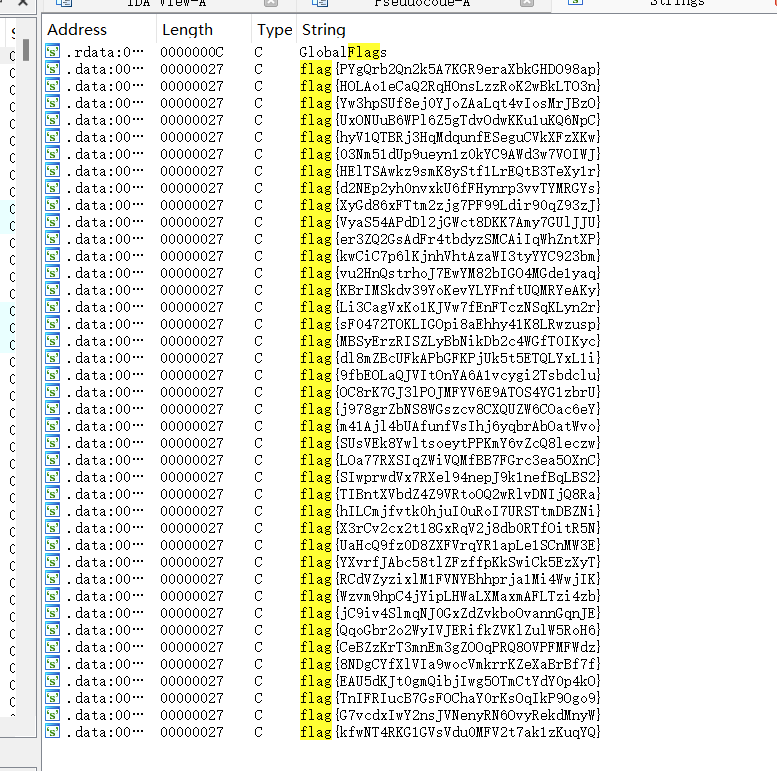
只不过太多了,懒得看
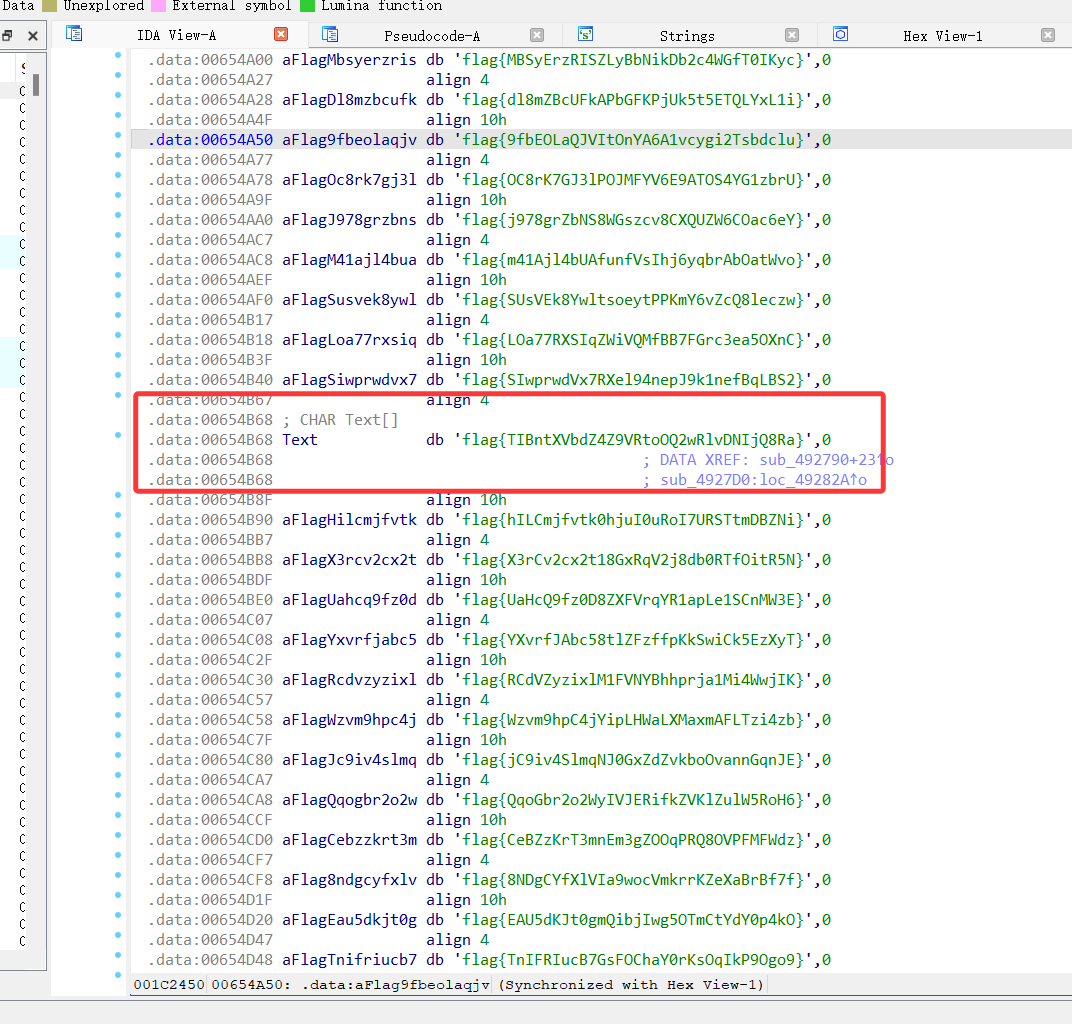
这个很特殊的
reverse_re3
难度1
要用虚拟机动调提取迷宫
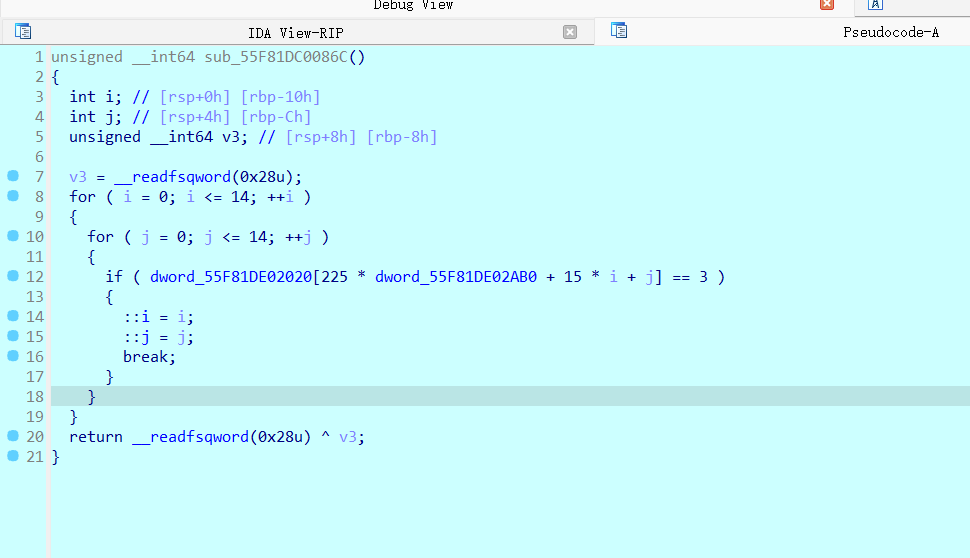
注意到225×3,太大了
先提取到45×15有
1 1 1 1 1 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 0 3 1 1 0 0 0 0 0 0
1 1 1 1 1 0 0 0 1 0 0 0 0 0 0
1 1 1 1 1 0 0 0 1 0 0 0 0 0 0
1 1 1 1 1 0 0 0 1 1 1 1 1 0 0
1 1 1 1 1 0 0 0 0 0 0 0 1 0 0
1 1 1 1 1 0 0 0 0 0 0 0 1 0 0
1 1 1 1 1 0 0 0 0 0 0 0 1 1 0
1 1 1 1 1 0 0 0 0 0 0 0 0 1 0
1 1 1 1 1 0 0 0 0 0 0 0 0 4 0
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 0 3 1 1 1 1 1 0 0 0 0 0 0
1 1 0 1 1 0 0 0 1 0 0 0 0 0 0
1 1 0 0 0 0 0 0 1 0 0 0 0 0 0
1 1 0 1 1 0 0 0 1 1 1 1 1 0 0
1 1 0 1 1 0 0 0 0 0 0 0 1 0 0
1 1 0 1 1 0 0 0 0 0 0 0 1 0 0
1 1 0 1 1 0 0 0 0 0 1 1 1 1 0
1 1 0 1 1 0 0 0 0 0 1 0 0 1 0
1 1 0 1 1 0 0 0 0 0 1 0 0 0 0
1 1 0 1 1 1 1 1 1 0 1 0 1 1 0
1 1 0 1 1 1 1 1 1 1 1 1 1 1 0
1 1 0 0 0 0 0 0 0 0 0 0 0 4 0
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 3 1 1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 1 0 1 1 1 0 0 0 0 0 0 0
0 0 0 1 1 1 0 1 0 0 0 0 0 0 0
0 0 0 0 1 0 0 1 0 0 0 0 0 0 0
0 1 1 0 1 0 0 1 0 0 0 0 0 0 0
0 0 1 1 1 0 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 1 1 1 0 0 0 0
0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
0 0 0 0 0 0 0 0 0 0 1 1 1 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 4 0
可见分为3个小迷宫
ddsssddddsssdssdddddsssddddsssaassssdddsddssddwddssssssdddssssdddss
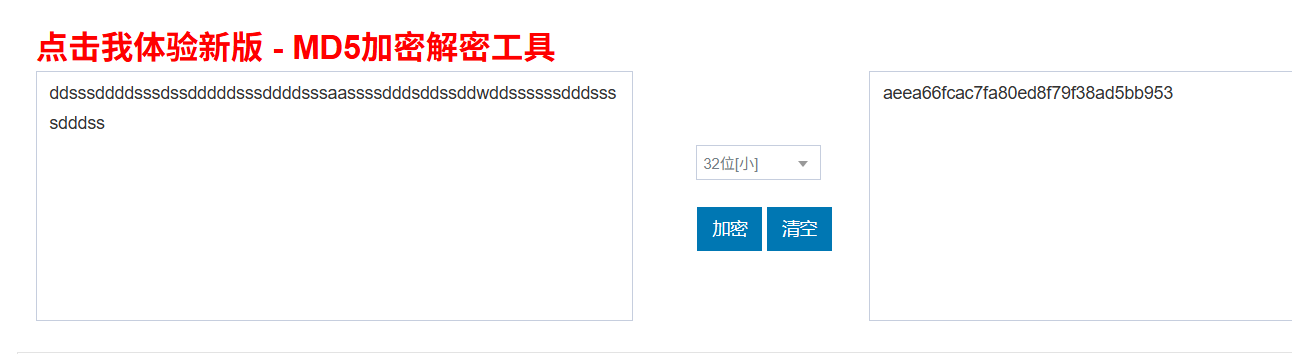
lucknum
难度1
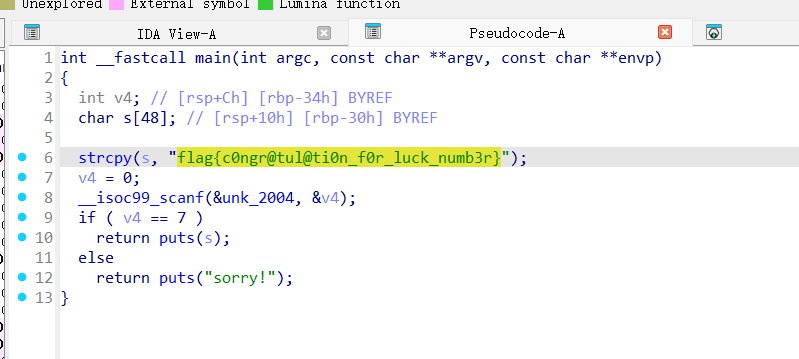
我草?
Reversing-x64Elf-100
难度1
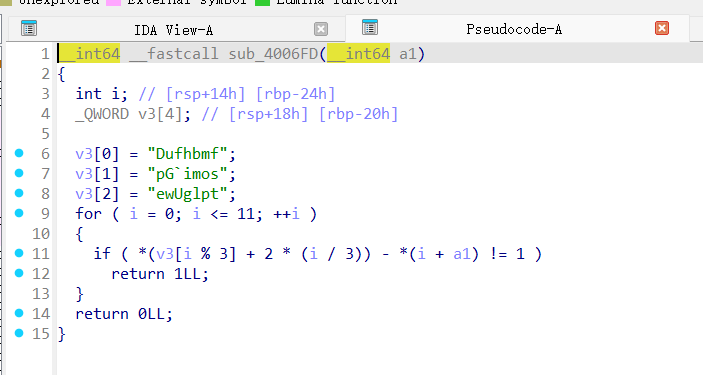
交给AI
v3 = [
"Dufhbmf",
"pG`imos",
"ewUglpt"
]
flag = []
for i in range(12):
c = chr(ord(v3[i % 3][2 * (i // 3)]) - 1)
flag.append(c)
print("flag{%s}" % ''.join(flag))
难度2
BABYRE
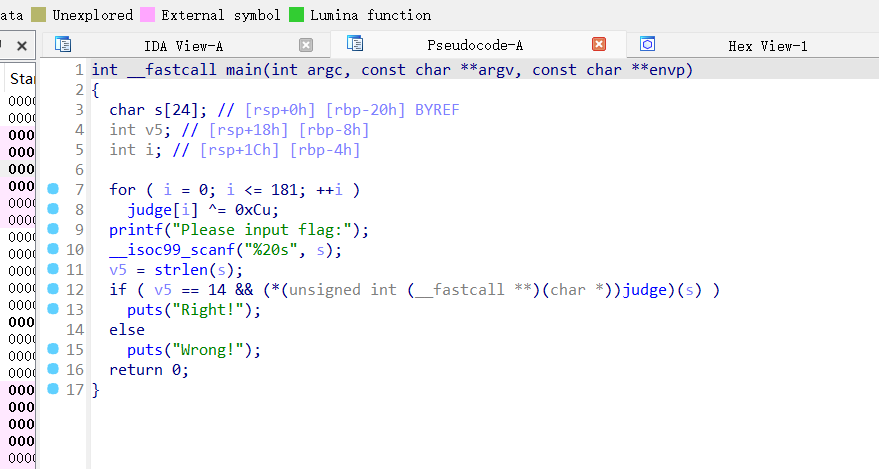
最上面有个xor
xor完是一堆乱码,估计肯定和judge这个东西有关
动调一下
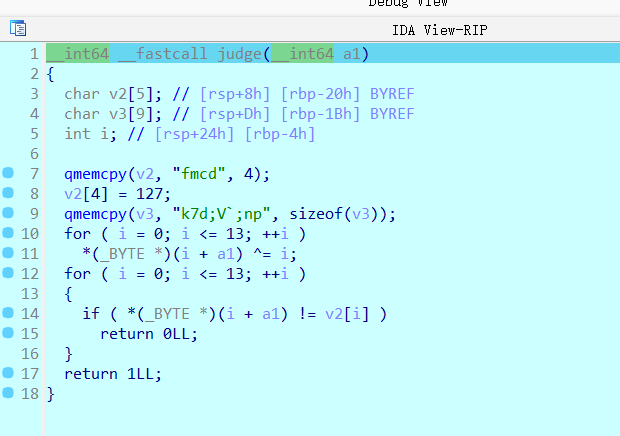
实际上就是自身xor
crazy
代码有点东西啊。。。
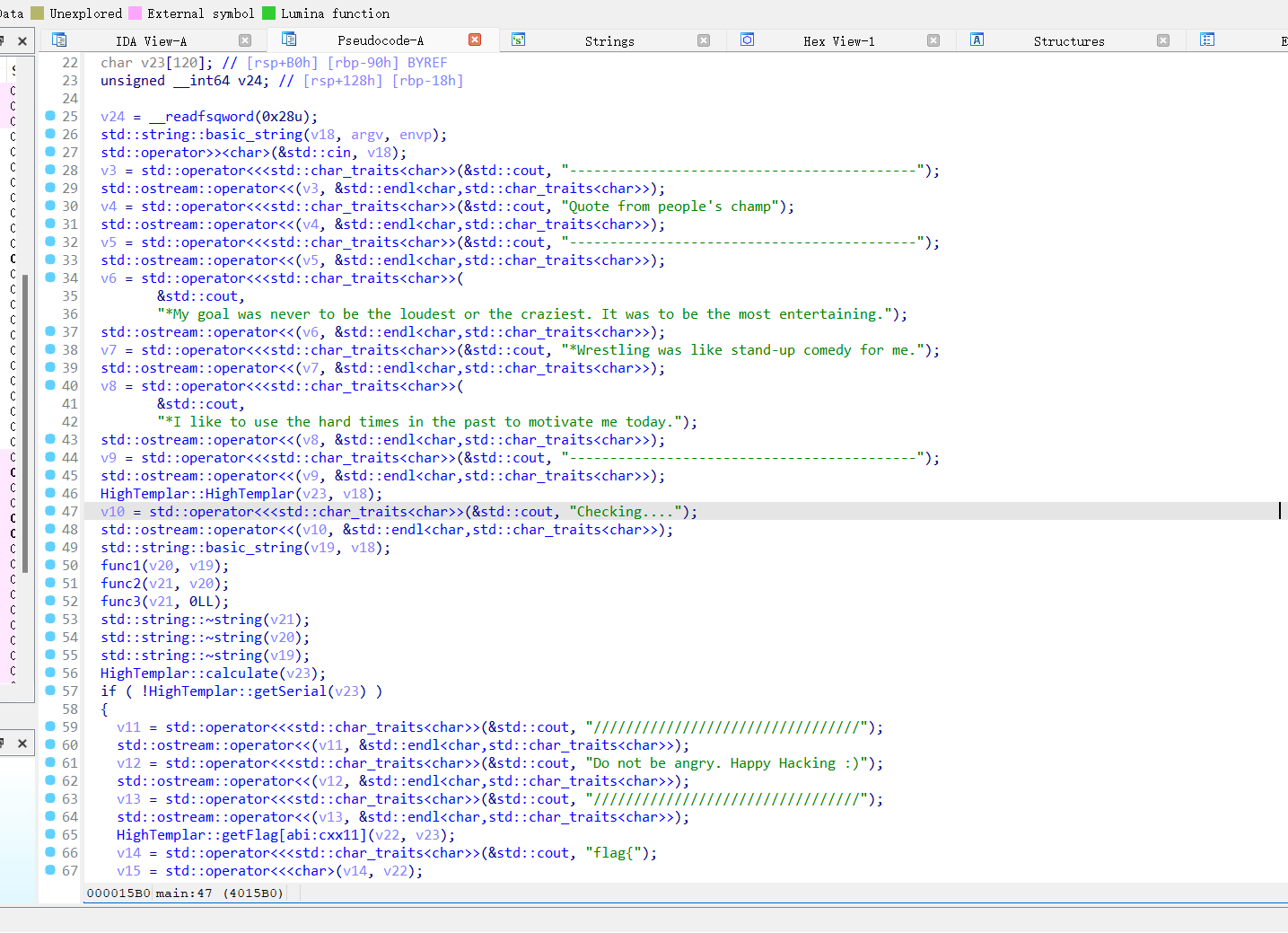
C++代码花里胡哨的
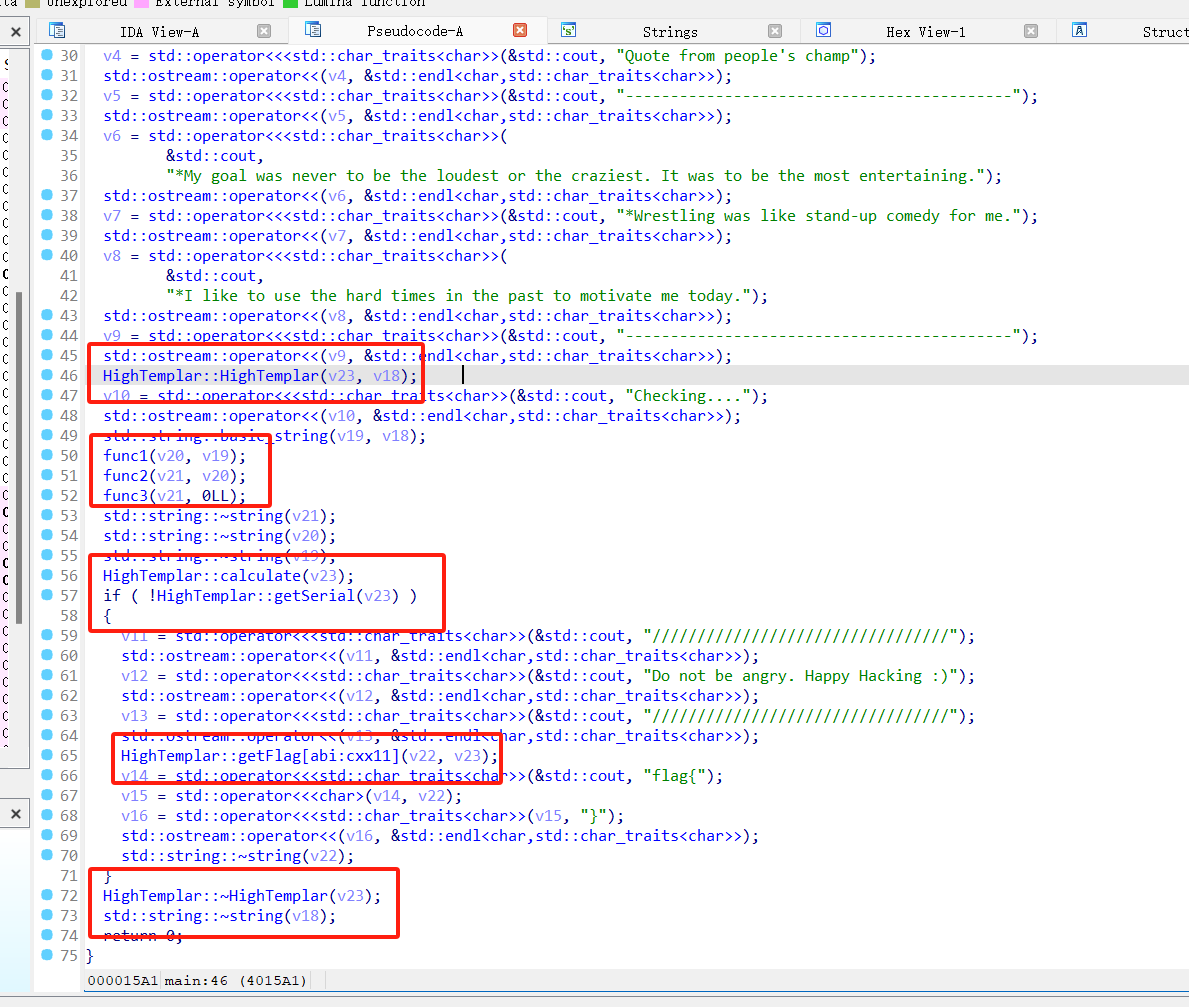
这几个函数都是要看的
先看看HighTemplar::HighTemplar函数
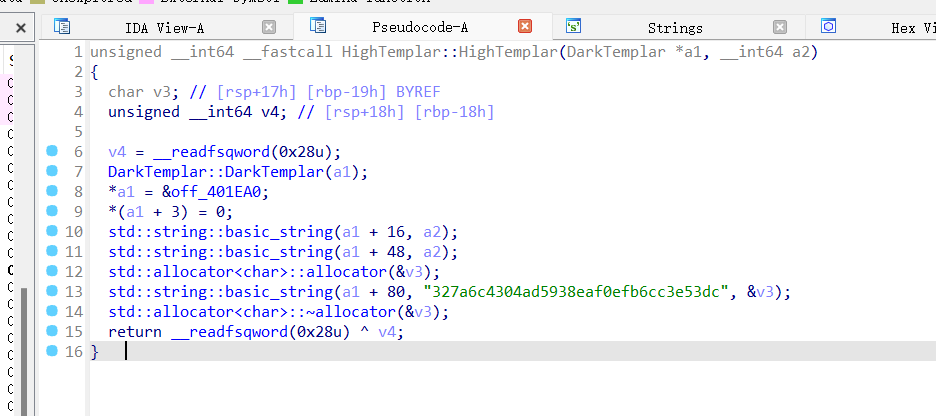
应该是关键字符串了
fun1,2,3没看明白在干什么
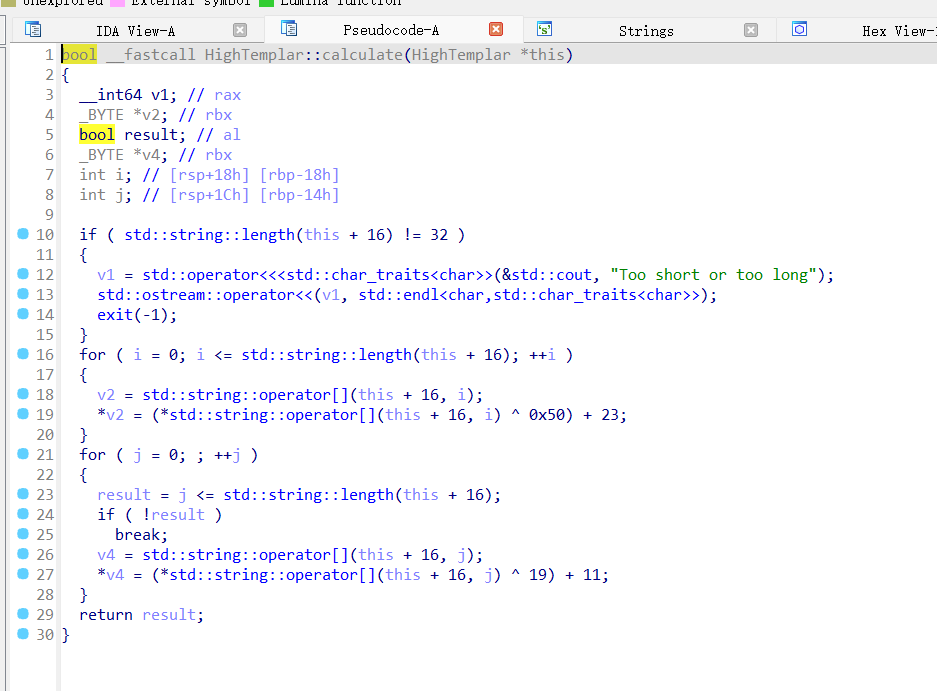
HighTemplar::calculate函数里面判断字符串长度等于32
以及一些xor运算
a="327a6c4304ad5938eaf0efb6cc3e53dc"
b=""
c=""
print(len(a))
for i in range(len(a)):
b+=chr((ord(a[i])-11)^19)
for i in range(len(b)):
c+=chr((ord(b[i])-23)^80)
print(c)
#tMx~qdstOs~crvtwb~aOba}qddtbrtcd
完了就一直看,尼玛看不出来了 搜的wp发现这tm是flag。。。。
IgniteMe
兄弟们没AI我真做不会一点儿啊
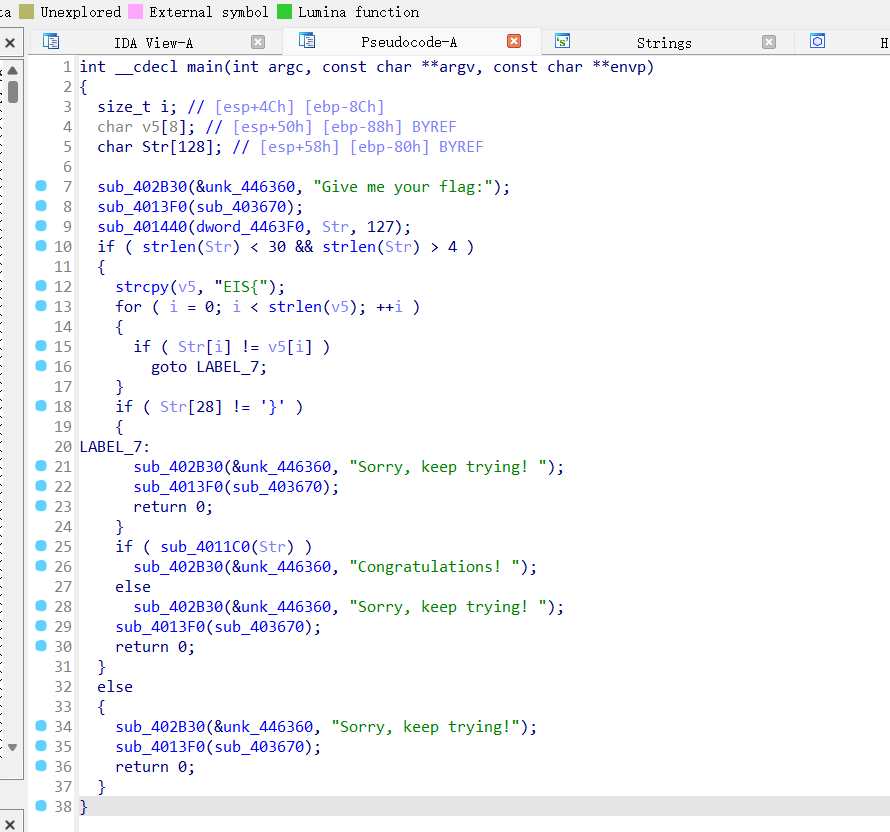
sub_4011C0才是关键函数
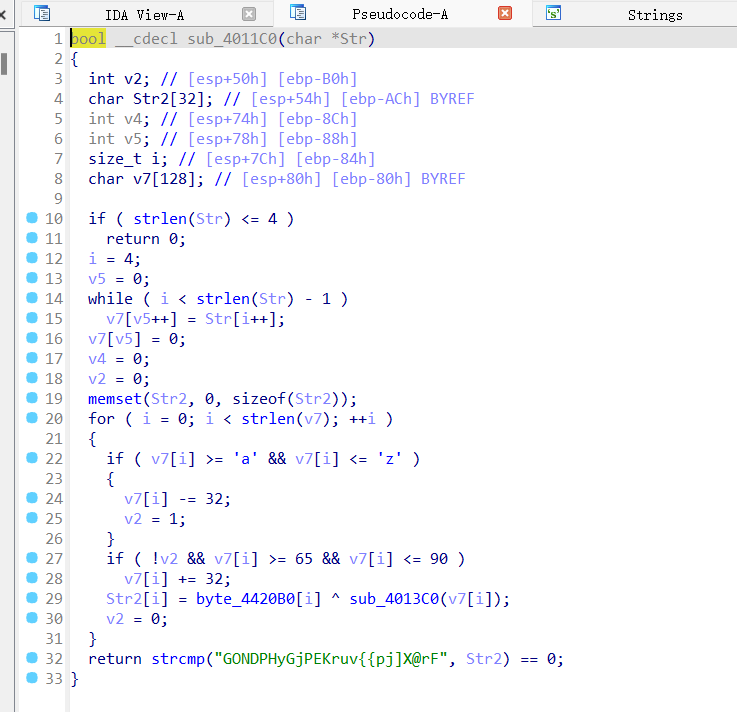
交给豆包
byte_4420B0 = [13, 19, 23, 17, 2, 1, 32, 29, 12, 2,
25, 47, 23, 43, 36, 31, 30, 22, 9, 15,
21, 39, 19, 38, 10, 47, 30, 26, 45, 12,
34, 4]
target_str = "GONDPHyGjPEKruv{{pj]X@rF"
def sub_4013C0_reversed(c):
# 逆向 sub_4013C0 函数: (a1 ^ 0x55) + 72
return (c - 72) ^ 0x55
# 第一步:逆向异或操作和 sub_4013C0
v7 = []
for i in range(len(target_str)):
if i < len(byte_4420B0):
key = byte_4420B0[i]
else:
# 如果目标字符串比 byte_4420B0 长,需要处理越界情况
# 这里假设使用 byte_4420B0 的最后一个元素重复
key = byte_4420B0[-1]
# 逆向异或操作
encrypted_char = ord(target_str[i])
temp = encrypted_char ^ key
# 逆向 sub_4013C0 函数
original_char = sub_4013C0_reversed(temp)
v7.append(chr(original_char))
# 构建 v7 字符串
v7_str = ''.join(v7)
print(f"v7 字符串: {v7_str}")
# 第二步:尝试还原大小写转换
# 注意:这一步是近似还原,因为原始算法中的 v2 标志状态可能难以完全逆向
# 这里采用简化处理,假设每个字符独立转换
possible_flag_part = []
v2 = 0 # 跟踪转换状态
for c in v7_str:
if c.isupper():
# 可能是从小写转换过来的
possible_lower = c.lower()
possible_flag_part.append(possible_lower)
v2 = 1 # 标记有小写转大写的操作
elif c.islower():
# 可能是从大写转换过来的,但只有在 v2=0 时
if not v2:
possible_upper = c.upper()
possible_flag_part.append(possible_upper)
else:
possible_flag_part.append(c)
else:
possible_flag_part.append(c)
# 构建可能的原始子字符串
possible_substring = ''.join(possible_flag_part)
print(f"可能的中间子字符串: {possible_substring}")
# 第三步:构造完整flag(假设格式为 flag{...})
# 原始函数从输入字符串的第5个字符开始处理,所以我们需要添加前4个字符
# 假设格式为 flagCTF{...},所以前4个字符是 "flagCTF"
flag = "flag{" + possible_substring + "}"
print(f"可能的flag: {flag}")
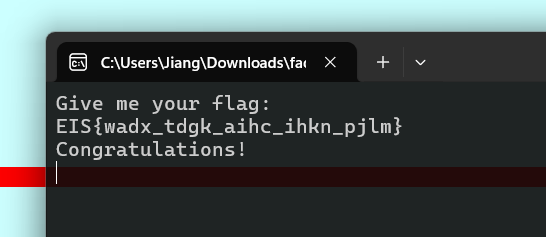
parallel-comparator-200
前言:AI牛逼!!!!!!!!!!!!!!
题目:
#include <stdlib.h>
#include <stdio.h>
#include <pthread.h>
#define FLAG_LEN 20
void * checking(void *arg) {
char *result = malloc(sizeof(char));
char *argument = (char *)arg;
*result = (argument[0]+argument[1]) ^ argument[2];
return result;
}
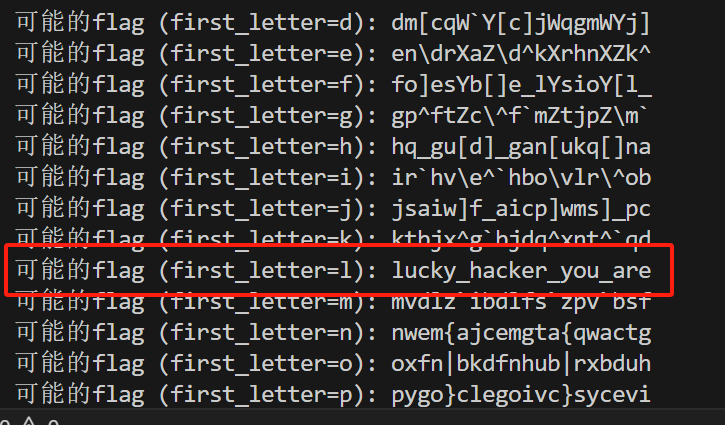
int highly_optimized_parallel_comparsion(char *user_string)
{
int initialization_number;
int i;
char generated_string[FLAG_LEN + 1];
generated_string[FLAG_LEN] = '\0';
while ((initialization_number = random()) >= 64);
int first_letter;
first_letter = (initialization_number % 26) + 97;
pthread_t thread[FLAG_LEN];
char differences[FLAG_LEN] = {0, 9, -9, -1, 13, -13, -4, -11, -9, -1, -7, 6, -13, 13, 3, 9, -13, -11, 6, -7};
char *arguments[20];
for (i = 0; i < FLAG_LEN; i++) {
arguments[i] = (char *)malloc(3*sizeof(char));
arguments[i][0] = first_letter;
arguments[i][1] = differences[i];
arguments[i][2] = user_string[i];
pthread_create((pthread_t*)(thread+i), NULL, checking, arguments[i]);
}
void *result;
int just_a_string[FLAG_LEN] = {115, 116, 114, 97, 110, 103, 101, 95, 115, 116, 114, 105, 110, 103, 95, 105, 116, 95, 105, 115};
for (i = 0; i < FLAG_LEN; i++) {
pthread_join(*(thread+i), &result);
generated_string[i] = *(char *)result + just_a_string[i];
free(result);
free(arguments[i]);
}
int is_ok = 1;
for (i = 0; i < FLAG_LEN; i++) {
if (generated_string[i] != just_a_string[i])
return 0;
}
return 1;
}
int main()
{
char *user_string = (char *)calloc(FLAG_LEN+1, sizeof(char));
fgets(user_string, FLAG_LEN+1, stdin);
int is_ok = highly_optimized_parallel_comparsion(user_string);
if (is_ok)
printf("You win!\n");
else
printf("Wrong!\n");
return 0;
}
交给AI
differences = [0, 9, -9, -1, 13, -13, -4, -11, -9, -1, -7, 6, -13, 13, 3, 9, -13, -11, 6, -7]
just_a_string = [115, 116, 114, 97, 110, 103, 101, 95, 115, 116, 114, 105, 110, 103, 95, 105, 116, 95, 105, 115]
FLAG_LEN = 20
# 尝试所有可能的first_letter (97-122, 即'a'-'z')
for first_letter in range(97, 123):
flag = []
valid = True
for i in range(FLAG_LEN):
# 计算user_string[i]
c = first_letter + differences[i]
# 检查是否是可打印字符
if c < 32 or c > 126:
valid = False
break
flag.append(chr(c))
# 如果所有字符都是可打印的,输出结果
if valid:
print(f"可能的flag (first_letter={chr(first_letter)}): {''.join(flag)}")
secret-galaxy-300
这题3个文件都是相同的,不影响
没看明白什么东西
好像什么数据库?
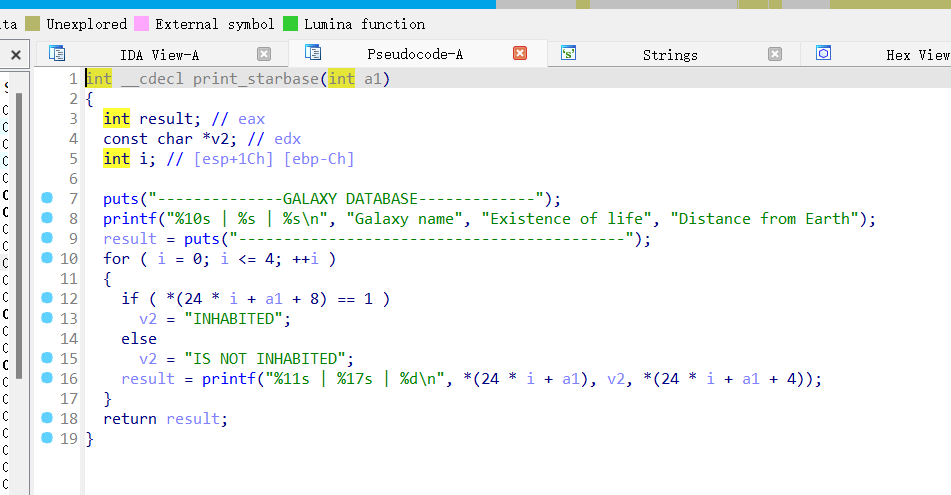
注意到这个gala函数

在末尾处下断点跑起来
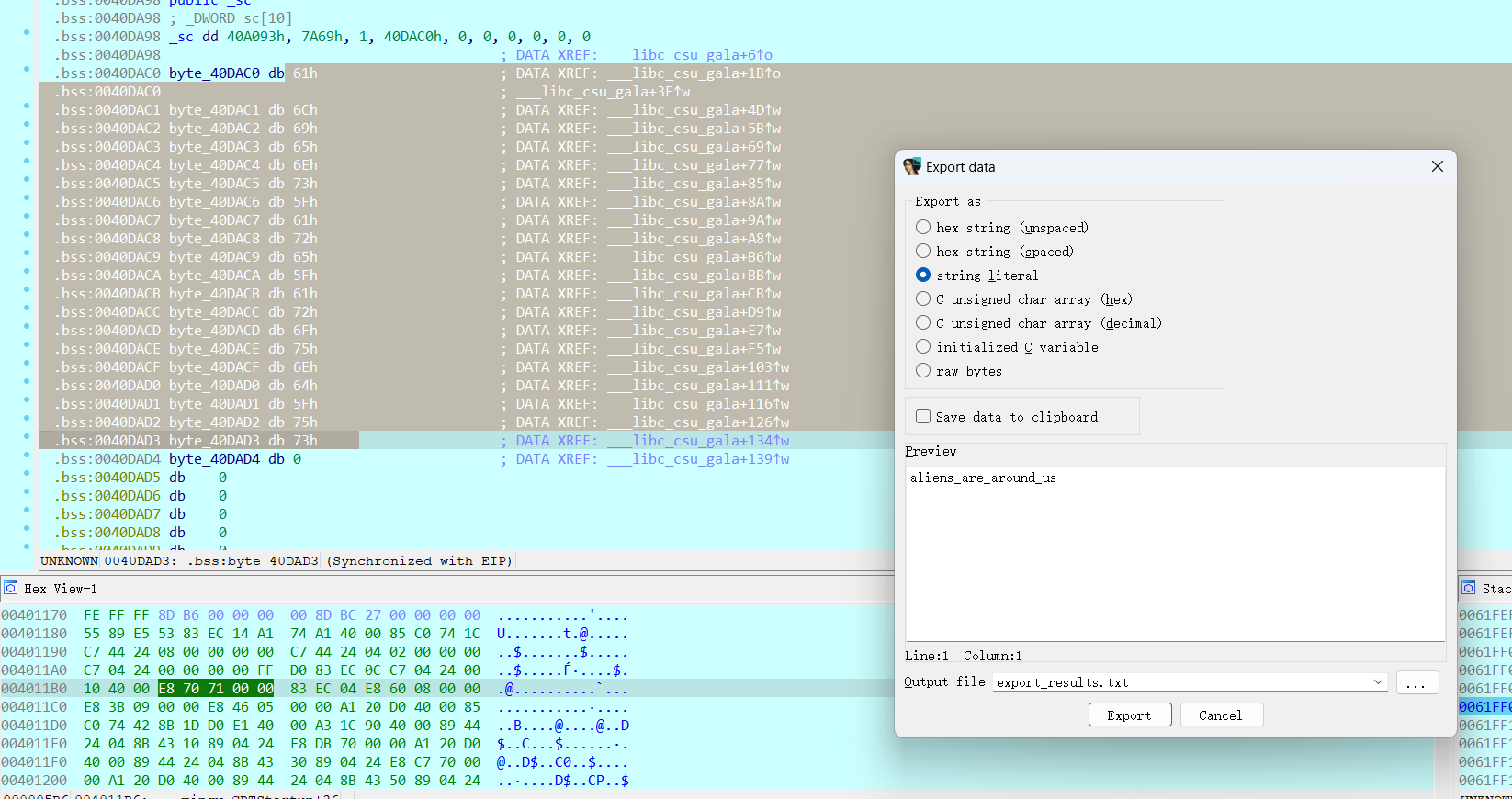
aliens_are_around_us
没绷住,纯是瞎捣鼓出来的
simple-check-100
这题和上题一样,三个文件不影响
交给AI
flag_data = [
220, 23, 191, 91, 212, 10, 210, 27, 125, 218,
167, 149, 181, 50, 16, 246, 28, 101, 83, 83,
103, 186, 234, 110, 120, 34, 114, 211
]
v7 = [
84, -56, 126, -29, 100, -57, 22, -102, -51, 17,
101, 50, 45, -29, -45, 67, -110, -87, -99, -46,
-26, 109, 44, -45, -74, -67, -2, 106
]
# 将有符号数转换为无符号数(模拟C语言中的字节操作)
def to_unsigned(byte):
return byte & 0xFF
# 方法一:类比C代码实现
flag_chars = []
for i in range(7):
# 从v7中提取4个字节并组合成一个32位整数(小端序)
byte0 = to_unsigned(v7[4 * i])
byte1 = to_unsigned(v7[4 * i + 1])
byte2 = to_unsigned(v7[4 * i + 2])
byte3 = to_unsigned(v7[4 * i + 3])
combined = byte0 + (byte1 << 8) + (byte2 << 16) + (byte3 << 24)
# 与0xDEADBEEF异或
v2 = combined ^ 0xDEADBEEF
# 将结果转换回字节数组(小端序)
v3 = [(v2 >> (8 * j)) & 0xFF for j in range(4)]
# 按j从3到0的顺序处理每个字节
for j in reversed(range(4)):
flag_char = v3[j] ^ flag_data[4 * i + j]
flag_chars.append(chr(flag_char))
# 输出flag
print(''.join(flag_chars))
#flag_is_you_know_cracking!!!
真不是我划水(
re1-100
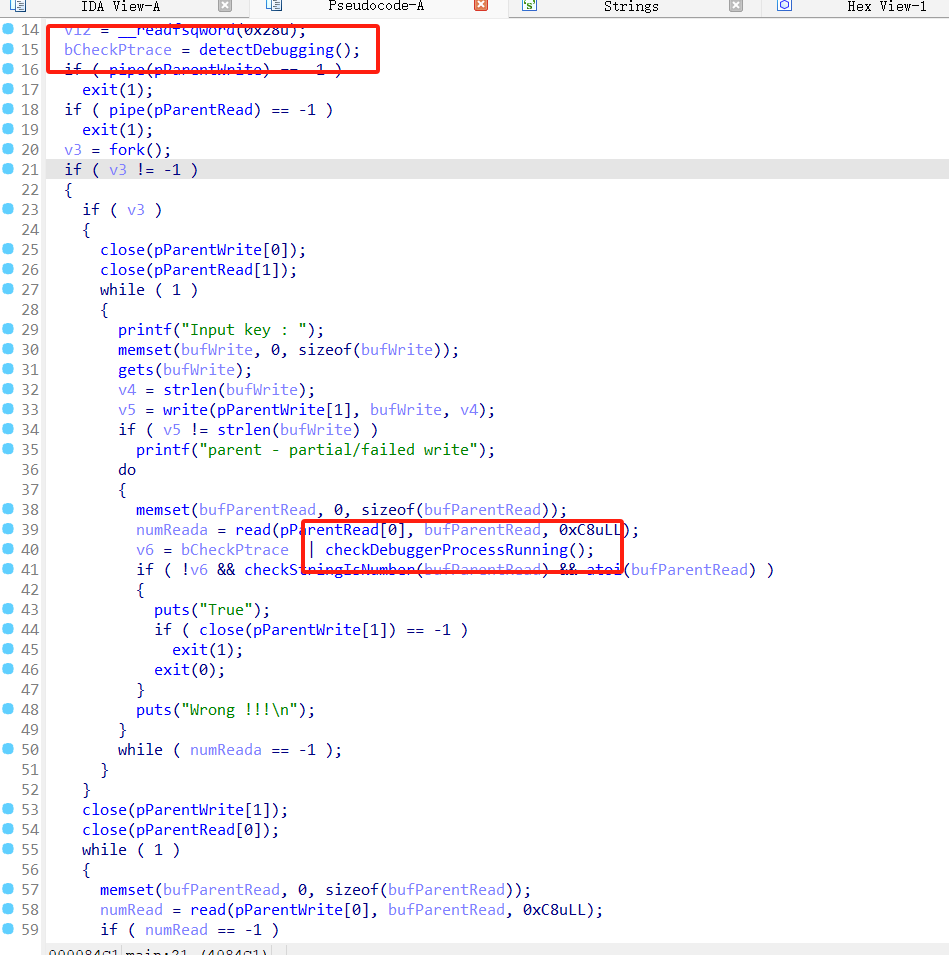
卧槽,这是什么?反调试?

好像没什么用

关键代码
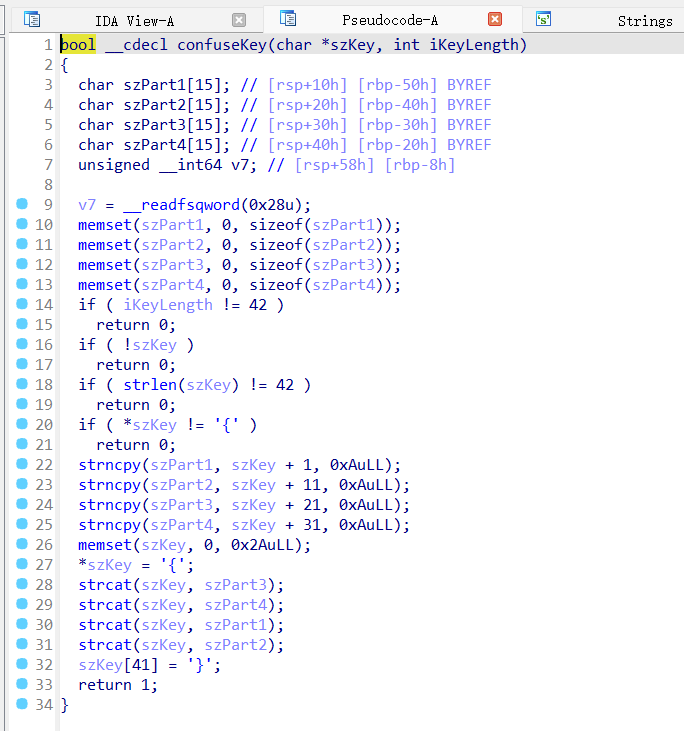
实际上就是算上{}是42个字符,去掉{}是40个,分成4份,一份10个,打乱顺序拼凑而已
daf29f5903 4938ae4efd 53fc275d81 053ed5be8c
顺序是3412
53fc275d81053ed5be8cdaf29f59034938ae4efd

elrond32
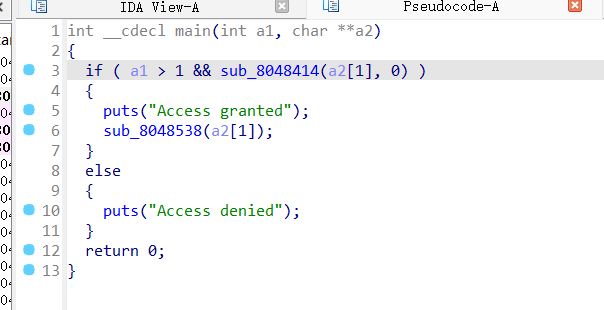
int __cdecl sub_8048414(_BYTE *a1, int a2)
{
int result; // eax
switch ( a2 )
{
case 0:
if ( *a1 == 'i' )
goto LABEL_19;
result = 0;
break;
case 1:
if ( *a1 == 'e' )
goto LABEL_19;
result = 0;
break;
case 3:
if ( *a1 == 'n' )
goto LABEL_19;
result = 0;
break;
case 4:
if ( *a1 == 'd' )
goto LABEL_19;
result = 0;
break;
case 5:
if ( *a1 == 'a' )
goto LABEL_19;
result = 0;
break;
case 6:
if ( *a1 == 'g' )
goto LABEL_19;
result = 0;
break;
case 7:
if ( *a1 == 's' )
goto LABEL_19;
result = 0;
break;
case 9:
if ( *a1 == 'r' )
LABEL_19:
result = sub_8048414(a1 + 1, 7 * (a2 + 1) % 11);
else
result = 0;
break;
default:
result = 1;
break;
}
return result;
}
应该是挨个输出,调试完是isengard
int __cdecl sub_8048538(int a1)
{
int v2[33]; // [esp+18h] [ebp-A0h] BYREF
int i; // [esp+9Ch] [ebp-1Ch]
qmemcpy(v2, &dword_8048760, sizeof(v2));
for ( i = 0; i <= 32; ++i )
putchar(v2[i] ^ *(a1 + i % 8));
return putchar(10);
}
这个看着好,dword的dump脚本是
import struct
def read_signed_dwords_from_addr(addr, length):
print("")
for i in range(0, length, 4):
dword_value = get_wide_dword(addr + i)
signed_value = struct.unpack('i', struct.pack('I', dword_value))[0]
print(f"{signed_value},", end="")
read_signed_dwords_from_addr(0x08048760,0x81)
exp:
v2 = [15, 31, 4, 9, 28, 18, 66, 9, 12, 68, 13, 7, 9, 6, 45, 55, 89, 30, 0, 89, 15, 8, 28, 35, 54, 7, 85, 2, 12, 8, 65, 10, 20]
key = [ord(c) for c in "isengard"] # [105, 115, 101, 110, 103, 97, 114, 100]
flag = []
for i in range(len(v2)):
k = i % 8 # 循环使用key的8个字节
flag_char = v2[i] ^ key[k]
flag.append(chr(flag_char))
print('解密后的flag:', ''.join(flag))
#解密后的flag: flag{s0me7hing_S0me7hinG_t0lki3n}
notsequence
请问这是难度2?
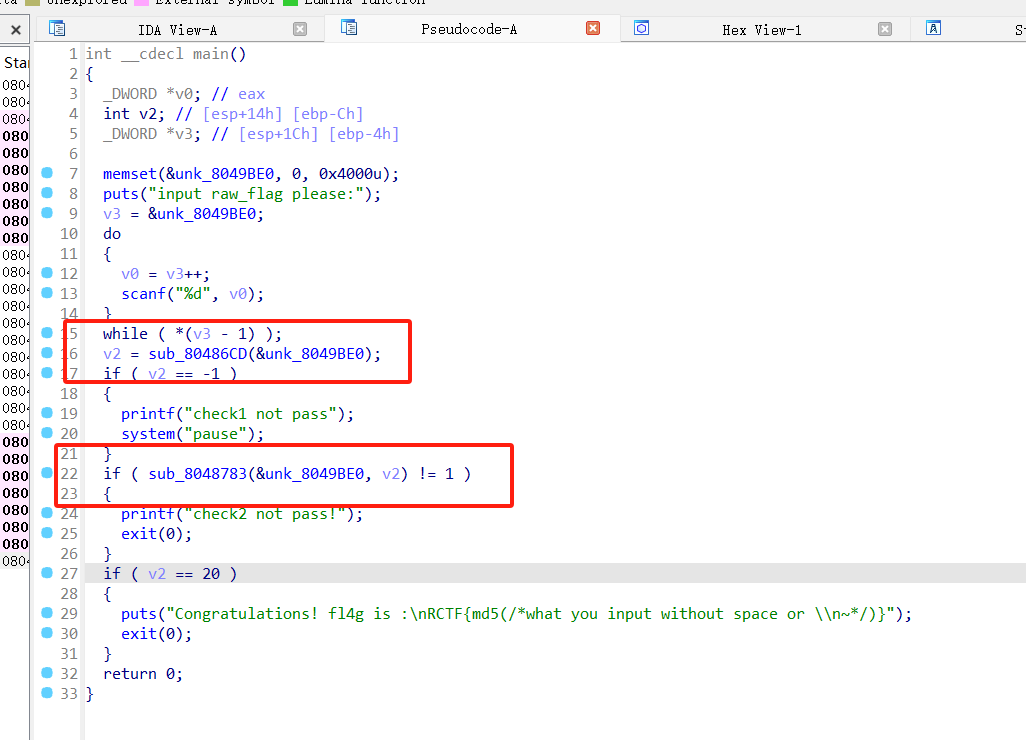
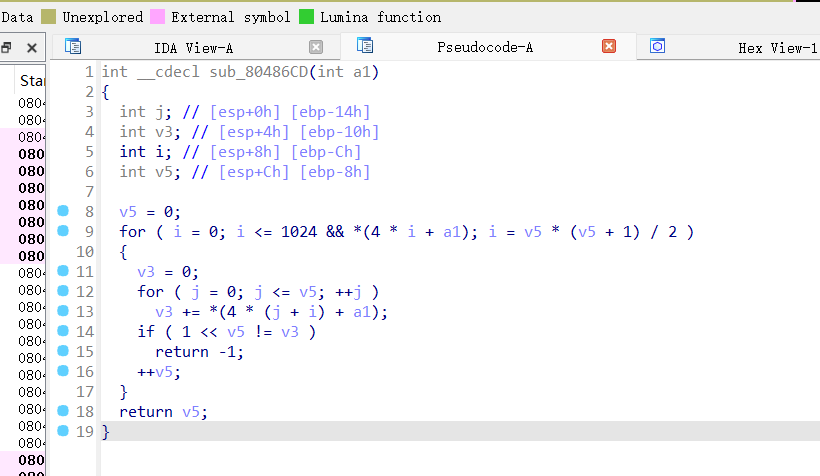
这个函数似乎在验证一个类似杨辉(帕斯卡)三角形的结构,其中每一行的和必须等于 2 的行数次幂。
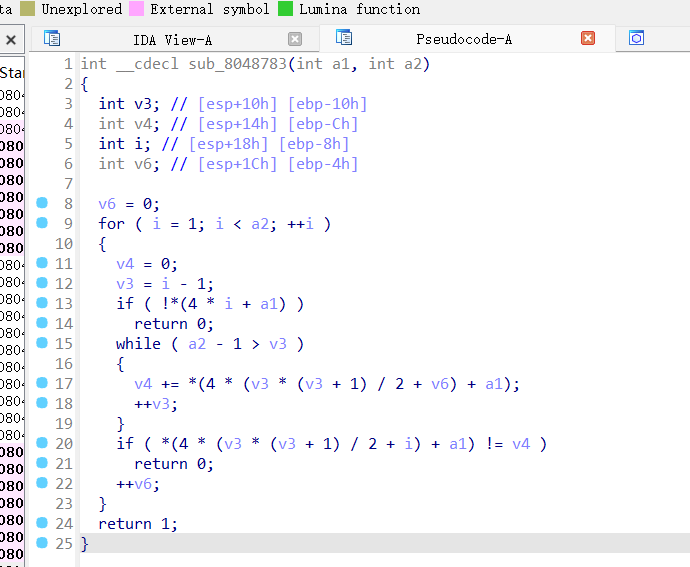
这个函数则是验证每个数等于它肩上两数的和
那么得到flag则需要v2=20,就是杨辉三角第20层时前面所有数字
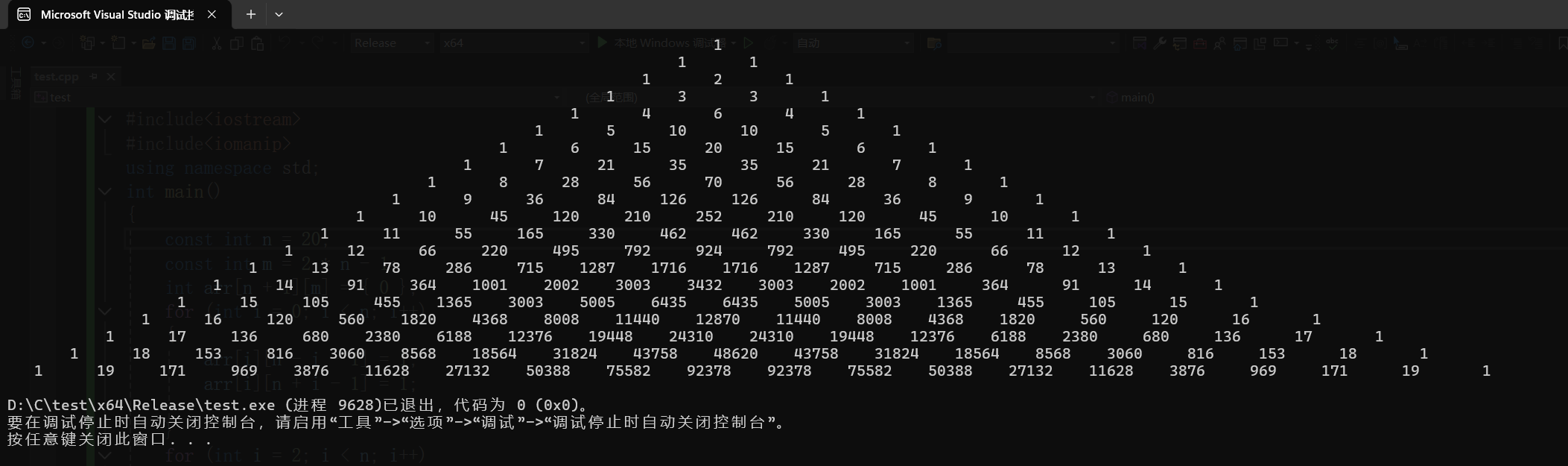
得到:1111211331146411510105116152015611721353521711828567056288119368412612684369111045120210252210120451011115516533046246233016555111112662204957929247924952206612111378286715128717161716128771528678131114913641001200230033432300320021001364911411151054551365300350056435643550053003136545510515111612056018204368800811440128701144080084368182056012016111713668023806188123761944824310243101944812376618823806801361711181538163060856818564318244375848620437583182418564856830608161531811191719693876116282713250388755829237892378755825038827132116283876969171191
md5一下RCTF{37894beff1c632010dd6d524aa9604db}
ReverseMe-120
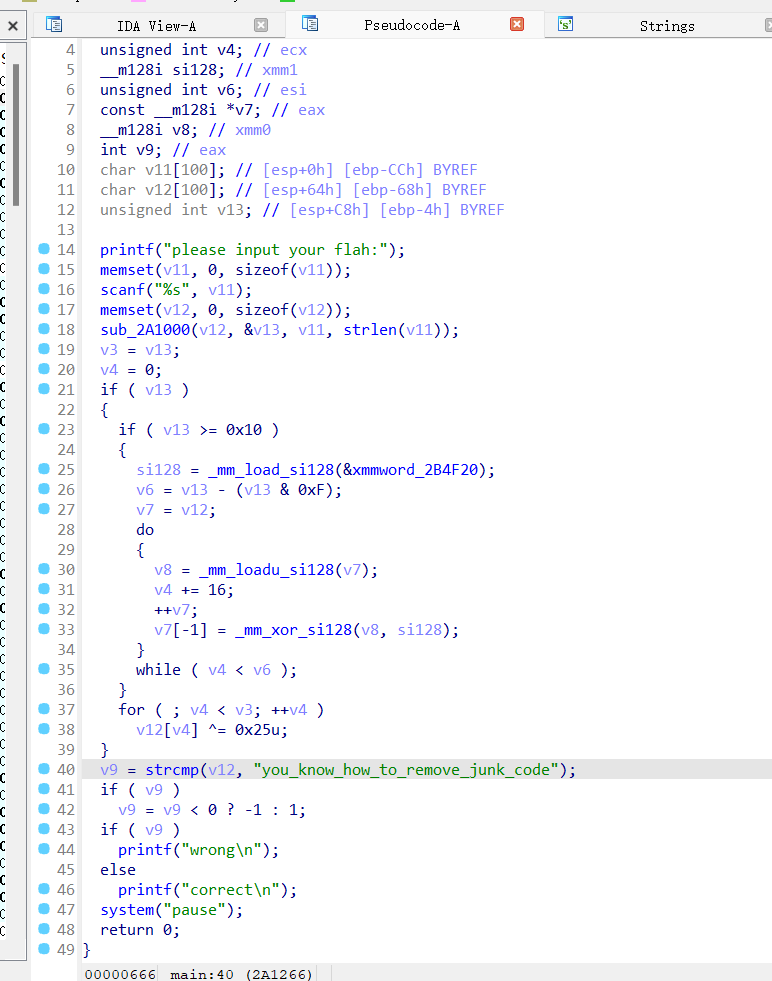
SUB_2A1000好像是个Base64函数,交给AI
根据提供的 main 函数代码,这是一个用于验证用户输入 flag 的程序。程序接收用户输入,经过特定处理后与目标字符串 "you_know_how_to_remove_junk_code" 比较。以下是对程序逻辑的分析和 flag 生成方法:
程序逻辑分析
用户输入处理:
用户输入被读取到v11缓冲区。
sub_2A1000函数对输入进行处理,结果存储在v12中,长度为v13。
数据转换:
块处理(16 字节为单位):
如果处理后的数据长度≥16 字节,每 16 字节与常量xmmword_2B4F20进行 XOR 操作。
常量xmmword_2B4F20的值为:0x6E, 0x79, 0x6D, 0x6D, 0x6A, 0x6A, 0x6D, 0x6E, 0x79, 0x6A, 0x6E, 0x6D, 0x6A, 0x6E, 0x6D, 0x6A。
剩余字节处理:
不足 16 字节的部分,每个字节与0x25进行 XOR 操作。
结果验证:
最终处理后的字符串必须等于 "you_know_how_to_remove_junk_code" 才能通过验证。
逆向推导 flag
要生成正确的 flag,需要逆向上述过程:
对目标字符串进行处理:
前 16 字节与常量xmmword_2B4F20进行 XOR。
剩余字节与0x25进行 XOR。
调用sub_2A1000的逆函数:
由于sub_2A1000的具体实现未知,假设它可能是某种编码(如 Base64)或简单转换。
然后把一些细节丢给AI,写一份代码
写的几处跑不起来,我修改了一下,能跑了
import base64
# 定义byte_2B4E40映射表
byte_2B4E40 = [
127, 127, 127, 127, 127, 127, 127, 127, 127, 127,
127, 127, 127, 127, 127, 127, 127, 127, 127, 127,
127, 127, 127, 127, 127, 127, 127, 127, 127, 127,
127, 127, 127, 127, 127, 127, 127, 127, 127, 127,
127, 127, 127, 62, 127, 127, 127, 63, 52, 53,
54, 55, 56, 57, 58, 59, 60, 61, 127, 127,
127, 64, 127, 127, 127, 0, 1, 2, 3, 4,
5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24,
25, 127, 127, 127, 127, 127, 127, 26, 27, 28,
29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48,
49, 50, 51, 127, 127, 127, 127, 127
]
# 从解码表逆向推导出编码表
def build_encoding_table():
encoding_table = ['='] * 64
# 只遍历byte_2B4E40中存在的索引
for i in range(len(byte_2B4E40)):
if byte_2B4E40[i] < 64:
encoding_table[byte_2B4E40[i]] = chr(i)
return ''.join(encoding_table)
# 使用自定义编码表进行Base64编码
def custom_base64_encode(data):
encoding_table = build_encoding_table()
encoded = base64.b64encode(data).decode('ascii')
# 替换标准Base64字符为自定义字符
standard = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
return encoded.translate(str.maketrans(standard, encoding_table))
# 目标字符串
target = "you_know_how_to_remove_junk_code"
target_bytes = target.encode('ascii')
# 步骤1: 逆向XOR操作(前16字节与0x25 XOR,其余与0x25 XOR)
xor_constant = bytes([0x25] * 16) # xmmword_2B4F20现在全为0x25
processed = bytearray()
for i in range(len(target_bytes)):
if i < 16:
processed.append(target_bytes[i] ^ xor_constant[i])
else:
processed.append(target_bytes[i] ^ 0x25) # 剩余字节仍与0x25 XOR
# 步骤2: 使用自定义Base64编码
flag = custom_base64_encode(processed)
print(f"生成的flag: {flag}")
Shuffle
这是难度2??
re-for-50-plz-50
我愿成为难度1。。。
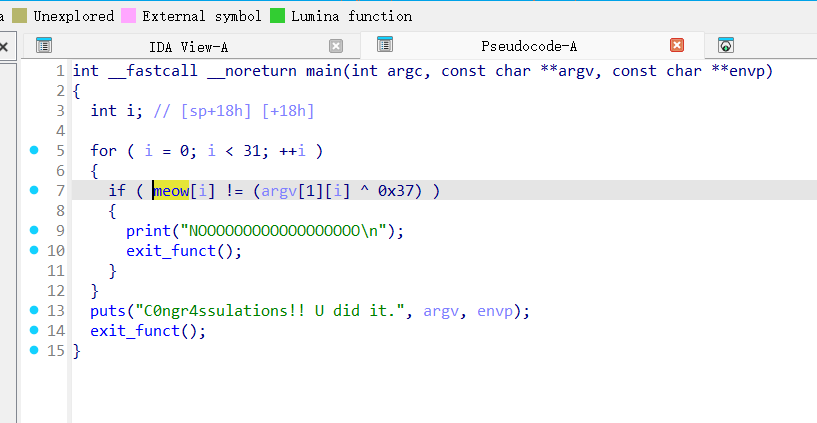
xor而已
a="cbtcqLUBChERV[[Nh@_X^D]X_YPV[CJ"
flag=""
for i in range(len(a)):
flag+=chr(ord(a[i])^0x37)
print(flag)
srm-50
这就是难度1啊。。怎么放难度2来了
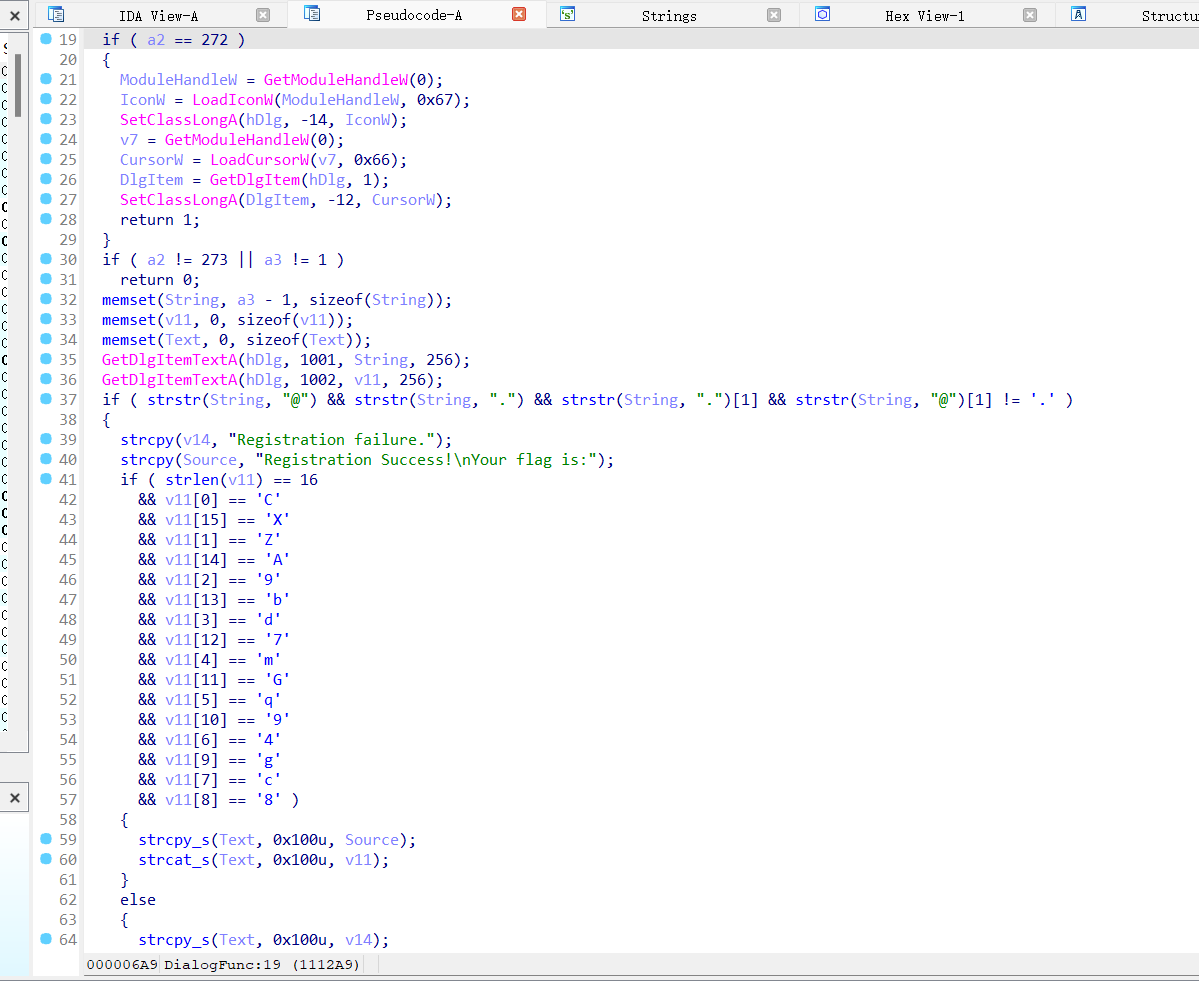
提取v11 = "CZ9dmq4c8g9G7bAX"
这个就是flag

 浙公网安备 33010602011771号
浙公网安备 33010602011771号