
Python决策树中文乱码解决
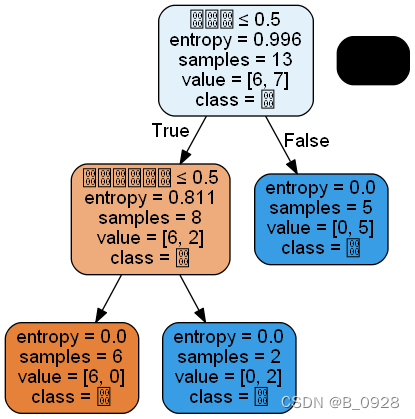
首先我也去找过网络上的很多文章,也提出了很多方法供我解决问题,但是最终试了很多都不行,比如去修改“C:\Program Files (x86)\Graphviz2.38\fonts\fonts.cont”文件中的某些代码,但是我电脑打开看的时候已经是修改过的(可能是我之前有过修改),还是不能解决掉问题,结果出来还是如下图所示。
from math import log import pandas as pd from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from sklearn import tree import graphviz import pydotplus
#建立模型 ent_tree= tree.DecisionTreeClassifier(criterion="entropy", min_samples_split=2, max_depth=5, min_impurity_decrease=0.0) #训练模型 ent_tree.fit(Xtrain,Ytrain) 点击并拖拽以移动 #生成dot文件 dot_tree= tree.export_graphviz(ent_tree, out_file=None, feature_names=X.columns, class_names=['否', '是'], filled=True, rounded=True, special_characters=True) graph_tree = pydotplus.graph_from_dot_data(dot_tree) # 保存图片 graph_tree.write_png("ent_tree.png") #展示图片 from IPython.display import Image Image(graph_tree.create_png())
![]()
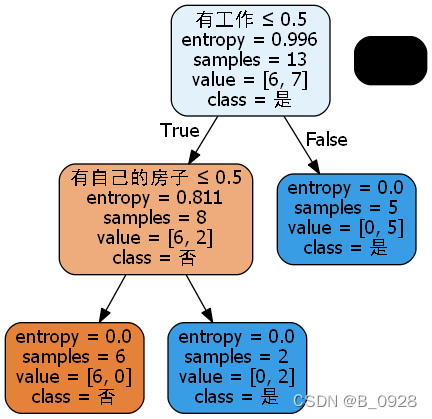
最终参考一篇文章后终于解决了这个问题。
解决方法如下所示:
将生成的dot文件中的字体'helvetica'替换为'MicrosoftYaHei'就可以成功解决中文乱码的问题了。
![]()
参考链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号