

从0开始学习R语言--Day14--贝叶斯统计与结构方程模型 - 详解
贝叶斯统计
在很多时候,我们经常会看到在统计分析中出现很多反直觉的结论,比如假如有一种病,人群中的患病率为1%,患者真患病时,检测结果为阳性的概率是99%,如果没有,则检测结果为阳性的概率是5%,但是如果让我们计算一个人检测结果为阳性时真正患病的概率为多少,根据概率公式P(患病|检测为阳性) = [P(检测为阳性|患病)× P(患病)]/P(检测为阳性) 我们可以计算,而P(检测为阳性)可以通过全概率公式P(检测为阳性)=P(检测为阳性|患病)P(患病) + P(检测为阳性|没患病)P(没患病)得出,计算得到的结果为16.67%,可能有人会疑惑,为什么患真病的前提下,检测为阳性时99%,反过来就只有16.67%,其实会有这样的错句,一是因为没抓住基础的概率,即本身该病的患病率就是很低的1%,二是在人群中没病但检测为阳性的人(5%×99%≈4.95%)比有病且检测为阳性的人(1%×99%≈0.99%)多很多。
这种先有对数据样本的初始判断,观察数据在给定假设下的表现,通过后续检验后得出新判断的过程,就是贝叶斯统计,其中,初始的判断叫做先验概率(Prior),即人群中的患病率1%;在某个假设成立的情况下,观察到的表现叫做似然值(Likehood),即患者有病时检测为阳性的概率和没病时检测为阳性的概率,这里是否有病就是假设;在看到计算结果后得出的新判断叫做后验概率(Posterior)。
下面我们依然是给出一个例子来解释:
# 加载必要的库library(tidyverse)library(ggplot2) # 定义参数p_disease % mutate( test_result = case_when( disease == 1 ~ rbinom(n(), 1, p_true_positive), disease == 0 ~ rbinom(n(), 1, p_false_positive) ) ) # 计算实际阳性中患病的比例empirical_posterior % filter(test_result == 1) %>% summarise( p_disease_given_positive = mean(disease) ) %>% pull() cat(sprintf("\n模拟数据中阳性结果实际患病的比例: %.2f%%", empirical_posterior * 100)) # 创建列联表展示结果table(sim_data$disease, sim_data$test_result) %>% addmargins() %>% knitr::kable(caption = "疾病与检测结果的列联表")输出:
检测为阳性时实际患病的概率: 16.67%> 模拟数据中阳性结果实际患病的比例: 17.09%> Table: 疾病与检测结果的列联表 | | 0| 1| Sum||:---|----:|---:|-----:||0 | 9414| 485| 9899||1 | 1| 100| 101||Sum | 9415| 585| 10000|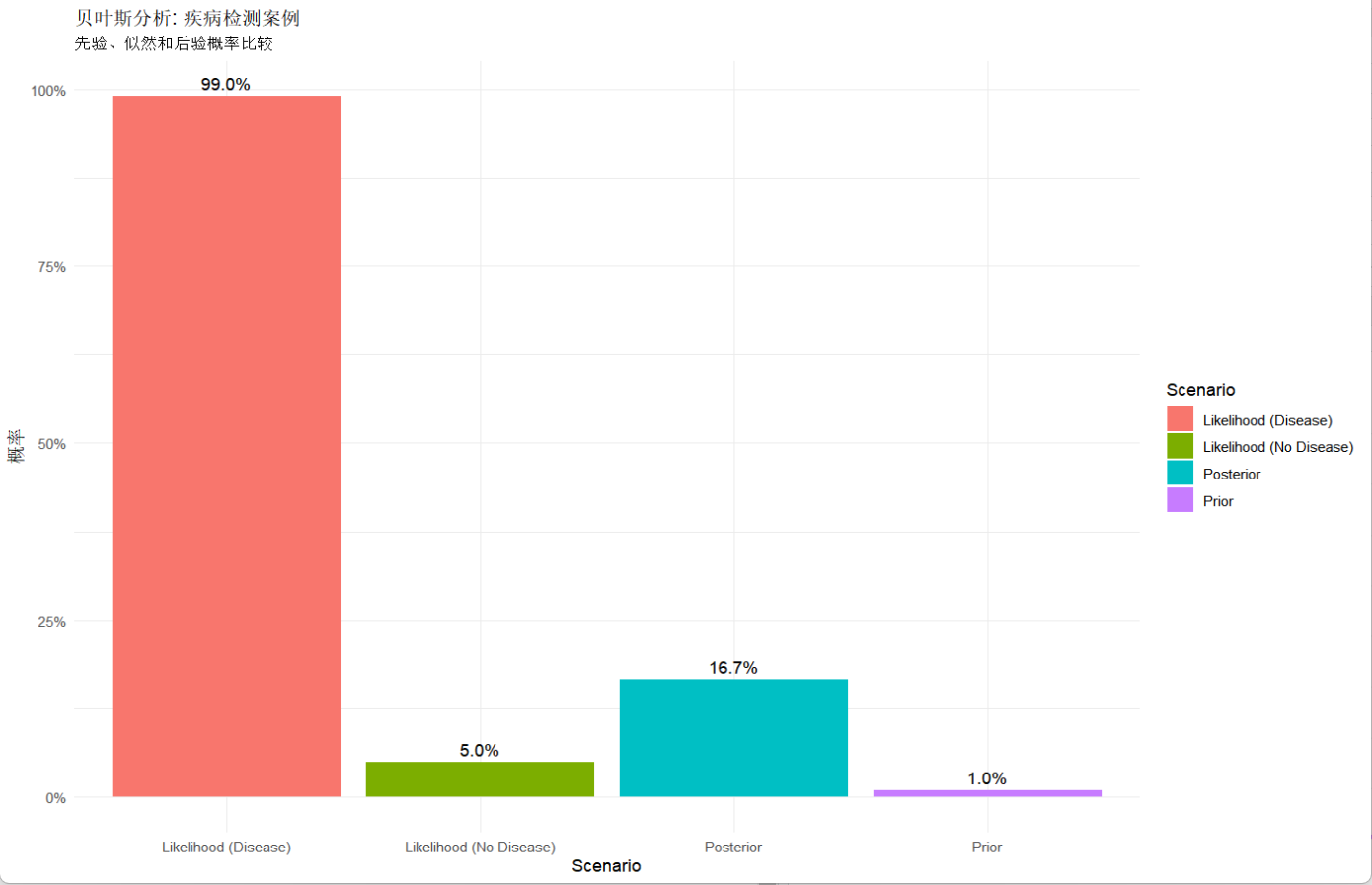
从输出中我们可以看到,模拟数据中的实际患病率与我们用贝叶斯统计计算得出的差不多,而输出的列表里也能观察到阳性预测的正确率只有100/585≈17.09%,这说明在实际上的应用场景中,我们在看到类似于“99%的准确率”时不要被误导,要验证过基础概率后再下结论,相对的,假如在信用评分模型中,用户的违约率很低,那么如果出现很多高风险决策,这也可能是误报,当然最好是要查看背后的解释。
结构方程模型
事实上,并不是所有的数据都会跟我们平常做练习和书上的一样是每个都很好理解的,很多时候我们想研究的变量,是分散在不同的数据上的,这个时候探讨出变量间的关系,就需要我们潜在的变量了,是这些变量在无形之中担当了变量之间的桥梁。
例如我们知道不同的老师对学生成绩有不同的影响,也许我们会去分析不同的教学方法是怎么影响成绩的,但如果直接对这两者做回归分析,很多时候效果都会很差,究其原因是因为教学方法很可能是间接影响了B,再由B去影响学生成绩,所以这里的重点工作就变成了如何找出B。当然,这种潜在变量并不是唯一的,需要我们提出假设去验证。
但往往潜在变量都是抽象的(毕竟明显的变量在拿到数据的时候,就会看出来),这个时候就需要我们自己人为设计一些测量的工具来代替潜在变量的影响,假设我们认为潜在变量是教学质量,那么我们就可以从教师评分,课程设计、作业反馈上得出来(前提是控制同一批能力差不多的学生),通过设计问题和学生对知识掌握过程中的进步,我们可以得出该教师方法的质量处于什么水平;亦或者认为潜在变量是学生的学习动机,那么可能就需要用学生平时的学习时间,在课堂上的互动程度,对自我的评价,通过学生对学习的感兴趣程度和是否积极的态度来判断。
依然是举一个例子来说明:
library(lavaan) # 结构方程建模library(tidySEM) # 可视化library(ggplot2) # 基础绘图library(dplyr) set.seed(123)n_students % filter(op == "=~") %>% ggplot(aes(x = rhs, y = std.all, fill = lhs)) + geom_col(position = "dodge") + geom_hline(yintercept = 0.5, linetype = "dashed", color = "red") + labs(title = "标准化因子载荷", y = "标准化系数", x = "观测指标") + coord_flip() + theme_minimal()输出:
lavaan 0.6-19 ended normally after 77 iterations Estimator ML Optimization method NLMINB Number of model parameters 19 Number of observations 300 Model Test User Model: Standard Scaled Test Statistic 20.142 20.875 Degrees of freedom 17 17 P-value (Chi-square) 0.267 0.232 Scaling correction factor 0.965 Yuan-Bentler correction (Mplus variant) Model Test Baseline Model: Test statistic 544.259 551.226 Degrees of freedom 28 28 P-value 0.000 0.000 Scaling correction factor 0.987 User Model versus Baseline Model: Comparative Fit Index (CFI) 0.994 0.993 Tucker-Lewis Index (TLI) 0.990 0.988 Robust Comparative Fit Index (CFI) 0.993 Robust Tucker-Lewis Index (TLI) 0.988 Loglikelihood and Information Criteria: Loglikelihood user model (H0) -4424.677 -4424.677 Scaling correction factor 1.023 for the MLR correction Loglikelihood unrestricted model (H1) -4414.606 -4414.606 Scaling correction factor 0.995 for the MLR correction Akaike (AIC) 8887.354 8887.354 Bayesian (BIC) 8957.726 8957.726 Sample-size adjusted Bayesian (SABIC) 8897.470 8897.470 Root Mean Square Error of Approximation: RMSEA 0.025 0.028 90 Percent confidence interval - lower 0.000 0.000 90 Percent confidence interval - upper 0.060 0.063 P-value H_0: RMSEA = 0.080 0.002 0.004 Robust RMSEA 0.027 90 Percent confidence interval - lower 0.000 90 Percent confidence interval - upper 0.061 P-value H_0: Robust RMSEA = 0.080 0.003 Standardized Root Mean Square Residual: SRMR 0.038 0.038 Parameter Estimates: Standard errors Sandwich Information bread Observed Observed information based on Hessian Latent Variables: Estimate Std.Err z-value P(>|z|) Std.lv Std.all motivation =~ study_time 1.000 0.473 0.859 participation 1.435 0.159 9.022 0.000 0.679 0.547 self_eval 1.013 0.159 6.355 0.000 0.480 0.435 teaching_quality =~ teach_rating 1.000 0.812 0.618 course_diff -0.680 0.135 -5.046 0.000 -0.552 -0.473 hw_feedback 0.840 0.174 4.838 0.000 0.683 0.580 Regressions: Estimate Std.Err z-value P(>|z|) Std.lv Std.all math_score ~ motivation 9.753 1.191 8.190 0.000 4.616 0.623 teaching_qulty 3.792 0.726 5.224 0.000 3.080 0.415 chinese_score ~ motivation 11.243 1.080 10.411 0.000 5.322 0.750 motivation ~ teaching_qulty -0.073 0.055 -1.333 0.183 -0.125 -0.125 Covariances: Estimate Std.Err z-value P(>|z|) Std.lv Std.all .math_score ~~ .chinese_score 3.446 2.361 1.460 0.144 3.446 0.139 Variances: Estimate Std.Err z-value P(>|z|) Std.lv Std.all .study_time 0.079 0.017 4.801 0.000 0.079 0.262 .participation 1.079 0.099 10.941 0.000 1.079 0.701 .self_eval 0.986 0.085 11.611 0.000 0.986 0.811 .teach_rating 1.070 0.146 7.344 0.000 1.070 0.619 .course_diff 1.062 0.098 10.879 0.000 1.062 0.777 .hw_feedback 0.918 0.111 8.297 0.000 0.918 0.663 .math_score 27.738 3.708 7.480 0.000 27.738 0.504 .chinese_score 22.022 2.557 8.613 0.000 22.022 0.437 .motivation 0.221 0.028 7.806 0.000 0.984 0.984 teaching_qulty 0.660 0.168 3.935 0.000 1.000 1.000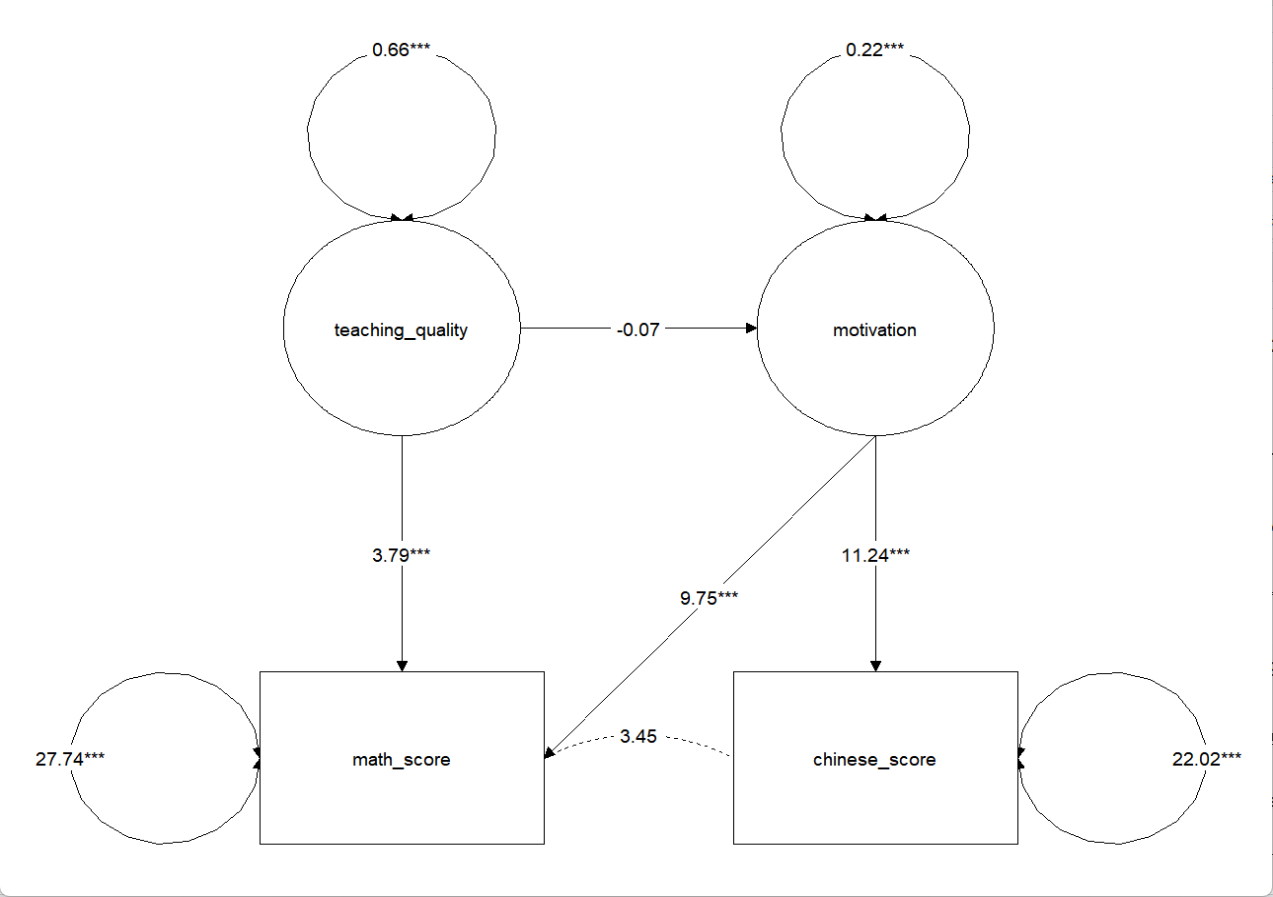
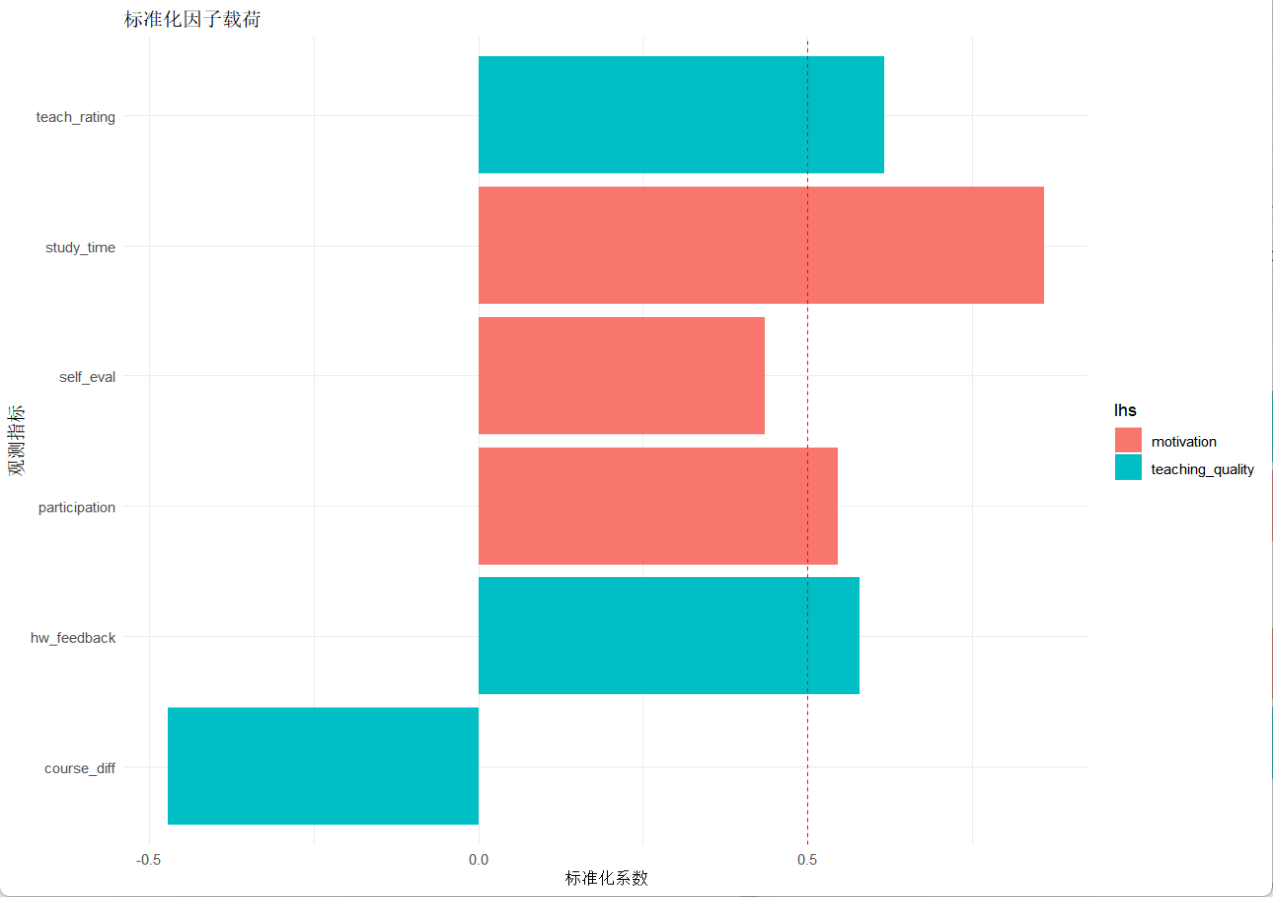
从输出中我们可以看到,CFI,RMSEA等指标都在标准范围内,说明模型与数据的匹配性较高;观察学习动机和教学质量中的指标,可以发现学习时间最能反映学习动机,而自我评价对模型的影响则较小;观察教学质量中的指标,可以发现课程难度与教学质量是负相关的,这也在我们的预期之内,毕竟越难的课,学生听懂的难度也会加大,而不是好的老师就能一下子把学生教会。综合来看,学习动机对语文和数学的成绩都较大,而教学质量会直接影响数学成绩,而对学习动机的影响反倒不大((β=-0.125, p=0.183))。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号