

YOLOv8【卷积创新篇·第8节】小波卷积与多尺度特征融合创新! - 实践
本文收录于 《YOLOv8实战:从入门到深度优化》 专栏,该专栏专注于分享我在YOLOv8目标检测模型中的实战经验,涵盖从入门基础到深度优化的全方位解决方案。无论你是计算机视觉的新手,还是具有多年深度学习经验的专家,本专栏都将为你提供高效、可复现的技术方案,助你掌握YOLOv8的核心技术,提升目标检测性能,突破瓶颈,优化模型,并加速项目开发!
内容声明: 本专栏持续复现网络上各种顶会内容(全网改进最全的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来。
全文目录:
前言
大家好!欢迎回到我们的《YOLOv8专栏》!在本节中,我们将深入探讨一个融合了经典信号处理智慧与现代神经网络架构的创新技术——小波卷积(Wavelet Convolution)。传统卷积神经网络(CNN)在提取空间特征方面表现卓越,但对于同时包含空间和频率域信息的复杂纹理和多尺度目标,常常显得力不从心。小波变换作为一种强大的多分辨率分析工具,能够将信号(如图像特征)分解到不同频率的子带中,为我们提供了全新的特征提取视角。本文将从“为什么需要小波”的基础理论出发,循序渐进地介绍离散小波变换(DWT)的原理,手把手教您如何设计并实现一个即插即用的小波卷积模块。更重要的是,我们将详细探讨如何将这一创新模块无缝集成到YOLOv8的骨干网络和颈部结构中,并通过详尽的代码解析与实验分析,展示其在增强纹理特征表达、提升多尺度目标检测性能方面的巨大潜力。准备好,让我们一起用“小波”的视角,为YOLOv8开启一扇新的性能提升之门!✨
一、温故知新:上容回顾 (MSCB多尺度卷积块)
在上期的内容 《YOLOv8【卷积创新篇·第7节】MSCB多尺度块设计与优化》 中,我们共同探讨了如何通过构建多分支、并行化的卷积结构来显式地增强模型的多尺度特征提取能力。
我们回顾一下核心知识点:
- 核心动机:自然图像中的目标尺寸变化极大,单一尺寸的卷积核(如3x3)拥有固定的感受野,难以同时高效地捕捉大、中、小不同尺寸目标的特征。
- MSCB计:其核心思想借鉴了Inception网络的精髓,在一个模块内设计了多个并行的卷积分支,每个分支使用不同大小的卷积核(如1x1, 3x3, 5x5)或不同空洞率的空洞卷积。这使得MSCB模块能够同时从多个“视角”观察输入特征图,获得丰富的多尺度信息。
- 特征融合:各个分支提取的特征图最终通过拼接(Concatenation)或相加(Addition)的方式进行融合,并通常会经过一个1x1卷积进行通道整合与信息交互,最终输出一个蕴含了多尺度上下文的特征图。
通过集成MSCB,我们旨在让YOLOv8的每一层特征都具备更强的尺度感知能力,从而在面对尺寸混杂的检测场景时,表现得更加鲁棒。
MSCB是从空间域入手,通过组合不同野 来解决多尺度问题。而今天,我们将另辟蹊径,从一个全新的维度——频率域——来探索多尺度特征融合的奥秘,这便是我们本节的主角:小波卷积。它与MSCB的设计哲学异曲同工,但实现路径和理论基础却截然不同,让我们一同揭开它的神秘面纱吧!
二、理论的:为什么我们需要小波变换?
在深入代码之前,我们必须先理解其背后的动机。这不仅能让我们知其然,更能知其所以然。
2.1 传统卷积的“视界”局限
标准的卷积操作,本质上是一个在局部邻域内进行加权求和的模板匹配过程。一个3x3的卷积核,其“视界”(感受野)就是3x3。虽然通过堆叠卷积层可以扩大感受野,但这种扩大是均质的、线性的。它擅长捕捉图像的空间结构信息,如边缘、角点、纹理等。
然而,图像信息不仅仅存在于空间域,同样也存在于频率域。
- 低频信息:代表了图像中平缓、大面积的区域,如天空、墙壁的轮廓。
- 高频信息:代表了图像中剧烈变化的细节部分,如物体的边缘、精细的纹理、噪声等。
传统卷积在处理这些信息时是“一视同仁”的,它将高频和低频信息混合在一起进行处理,这在某些场景下会成为性能的瓶颈。例如,对于需要精细纹理来区分的物体(如不同种类的布料、木材),或者需要抑制高频噪声的场景,传统卷积就显得有些力不从心了。
2.2 傅里叶变换的遗憾:丢失空间信息
熟悉信号处理的朋友可能会立刻想到 傅里叶变换ourier Transform),它能将信号从时域(或空间域)转换到频域,完美地分析出信号由哪些频率的正弦波组成。
 应运而生。它就像一个“数学显微镜”,可以让我们在不同的尺度(频率)下观察信号,并且还能告诉我们这些频率成分出现在什么位置。
小波变换的核心是母小波(Mother Wavelet),一个具有局部性(在时间/空间上是有限的)的波形。通过对母小波进行伸缩(Scaling) 和 平移(Translation),可以得到一系列的“小波基函数”。
- 伸缩:对应频率分析。将母小波拉伸,可以匹配信号的低频成分;将母小波压缩,可以匹配信号的高频成分。
- 平移:对应空间定位。将小波基函数在信号上滑动,就可以分析出不同位置的频率信息。
这种特性使得小波变换能够同时提供空间和频率的局部信息,实现了完美的时频/空频局部化分析。这正是我们增强CNN特征表达能力所梦寐以求的特性!
三、核心技术:离散小波变换(DWT)与图像处理
对于计算机处理的数字图像,我们通常使用离散小波变换(Discrete Wavelet Transform, DWT)。
3.1 2D离散小波变换的魔法:一分为四
当我们将DWT应用于2D图像时,最常见的做法是进行一级分解,这会将一张图像分解为四个大小为原始图像一半的子带(Sub-bands):
- LL (Low-Low子带:近似分量。它由对原始图像的行和列都进行低通滤波得到,保留了图像最主要的、平缓的低频信息,相当于一个缩小的、模糊的原始图像。
- LH (Low-High) 子:水平细节。由对行进行低通滤波、对列进行高通滤波得到,因此保留了图像的水平方向边缘和细节。
- HL (High-Low) 子带:垂直细节。由对行进行高通滤波、对列进行低通滤波得到,因此保留了图像的垂直方向边缘和细节。
- HH (High-High) 子带:对节。由对行和列都进行高通滤波得到,因此保留了图像的对角线方向边缘和细节。
这个过程可以用下面的流程图清晰地表示:
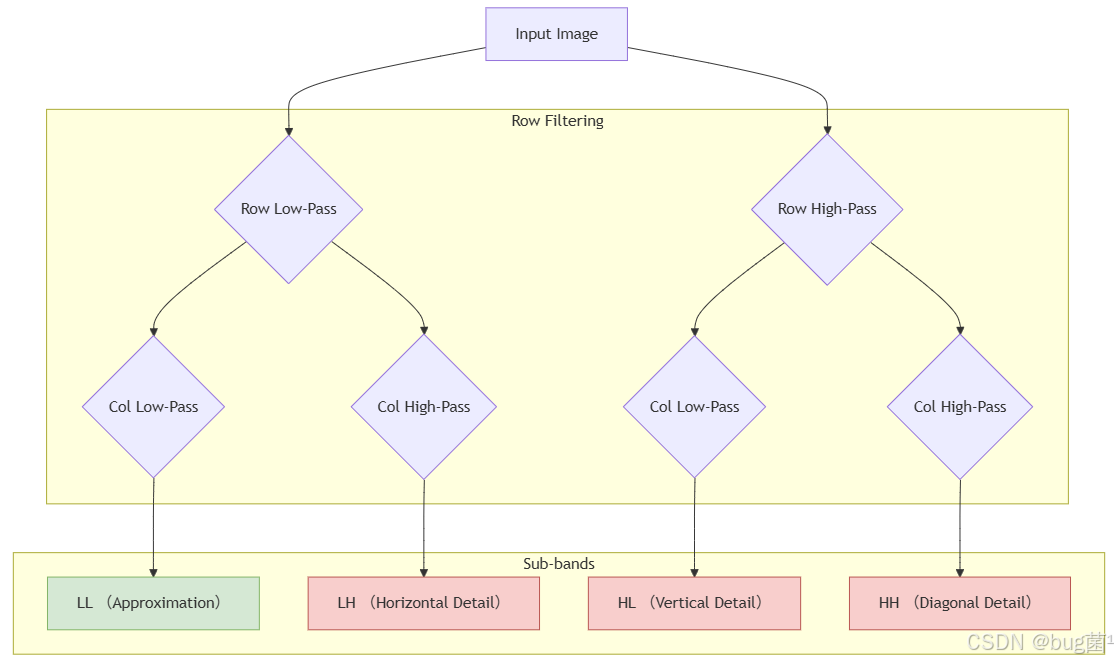
重要的是,这个分解过程是可逆的。通过逆离散小波变换(Inverse DWT, IDWT),我们可以用这四个子带完美地重建出原始图像。这为我们在神经网络中构建一个无损的信息分解与重构模块提供了可能。
3.2 DWT子带的可视化与理解
| 原始图像 (Original) | DWT 分解结果 |
|---|---|
| 原始图像展示了Lena的全貌 | |
| LL 子带(左上角):低频部分,类似原始图像的缩略图,包含了主要的轮廓信息。 | HL 子带(右上角):显示了垂直方向的边缘,突出物体的轮廓(如帽子的边缘、肩膀的轮廓)。 |
| LH 子带(左下角):显示水平方向的细节,体现了图像中的水平纹理(如帽檐的纹理)。 | HH 子带(右下角):呈现了图像的对角线纹理和细节,展示高频部分。 |
在DWT分解后,图像的低频信息和高频信息被分开:
- LL子带包含图像的主要轮廓和较平滑的区域。
- HL子带突出了垂直方向的边缘。
- LH子带展示了水平方向的细节和纹理。
- HH子带则显示了图像的高频细节,特别是对角线方向的纹理。
这些不同的子带为后续的处理提供了不同层次的信息,有助于进行图像压缩、特征提取等任务。
3.3 Python代码实战:使用PyWavelets库实现图像DWT分解
在Python中,我们可以非常方便地使用PyWavelets库来进行小波变换。下面的代码展示了如何对一张图像进行DWT分解并可视化结果。
提示:在运行代码前,请确保已经安装了必要的库:
pip install pywavelets opencv-python numpy matplotlib
import numpy as np
import pywt
import cv2
import matplotlib.pyplot as plt
def dwt_image_visualization(image_path):
"""
对输入图像进行DWT分解并可视化四个子带。
参数:
image_path (str): 输入图像的路径。
"""
# --- 1. 读取并预处理图像 ---
# 使用OpenCV读取图像,并转换为灰度图
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 将图像数据类型转换为float32,便于计算
img = np.float32(img)
# 归一化到[0, 255]范围
img /= 255
# --- 2. 执行2D离散小波变换 ---
# 使用 'haar' 小波进行单层分解
# coeffs 是一个包含分解系数的元组
# cA: 近似分量 (LL)
# (cH, cV, cD): 水平、垂直、对角细节分量 (LH, HL, HH)
coeffs = pywt.dwt2(img, 'haar')
cA, (cH, cV, cD) = coeffs
# --- 3. 可视化结果 ---
# 创建一个2x2的子图布局
fig, axes = plt.subplots(2, 2, figsize=(10, 10))
# 显示LL子带 (Approximation)
axes[0, 0].imshow(cA, cmap='gray')
axes[0, 0].set_title('Approximation (LL)')
axes[0, 0].set_xticks([])
axes[0, 0].set_yticks([])
# 显示LH子带 (Horizontal)
axes[0, 1].imshow(cH, cmap='gray')
axes[0, 1].set_title('Horizontal Detail (LH)')
axes[0, 1].set_xticks([])
axes[0, 1].set_yticks([])
# 显示HL子带 (Vertical)
axes[1, 0].imshow(cV, cmap='gray')
axes[1, 0].set_title('Vertical Detail (HL)')
axes[1, 0].set_xticks([])
axes[1, 0].set_yticks([])
# 显示HH子带 (Diagonal)
axes[1, 1].imshow(cD, cmap='gray')
axes[1, 1].set_title('Diagonal Detail (HH)')
axes[1, 1].set_xticks([])
axes[1, 1].set_yticks([])
plt.suptitle('DWT Sub-band Decomposition', fontsize=16)
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
# 使用示例图片进行测试
# 请将 'lena.png' 替换为你自己的图片路径
# 为了方便运行,我们先用代码生成一个简单的测试图片
from PIL import Image
try:
# 尝试从网络加载lena图片
import requests
from io import BytesIO
response = requests.get("https://raw.githubusercontent.com/y-x-c/utils/main/figures/lena.png")
img = Image.open(BytesIO(response.content))
img.save("lena.png")
test_image_path = "lena.png"
print("Lena image downloaded successfully.")
dwt_image_visualization(test_image_path)
except Exception as e:
print(f"Failed to download image, please provide a local image path. Error: {e
}")
# 你可以取消下面一行的注释,并换成你本地的图片路径
# dwt_image_visualization('/path/to/your/image.jpg')这段代码直观地展示了DWT的强大能力。现在,我们的目标是将这种能力赋予YOLOv8,让它在处理特征图时也能进行类似的多频段分析。
四、创新融合:小波卷积(WTConv)的设计与实现
4.1 小波卷积的设计哲学
我们设计的小波卷积(Wavelet Convolution, WTConv) 模块,其核心思想是在标准的卷积流程中嵌入DWT和IDWT。具体步骤如下:
分解 (Decomposition):接收一个输入特征图
X。使用DWT将其分解为四个子带:LL,LH,HL,HH。处理 (Processing):对这四个子带分别进行卷积操作。这里可以有不同的策略:
- 策略A(共享权重): 用同一个卷积核处理所有四个子带,以节省参数。
- 策略B(独立权重): 为每个子带分配独立的卷积核。这会增加参数量,但可能带来更好的性能,因为它允许网络学习如何针对性地处理不同频段的信息(例如,对低频轮廓使用一种卷积,对高频纹理使用另一种)。
重构 (Reconstruction):将处理后的四个子带通过IDWT重新组合,恢复到原始特征图的尺寸。
通过这个过程,WTConv模块能够在保持输入输出形状不变的同时,对特征进行一次深入的“空-频域”联合处理。
4.2 基于PyTorch的nn.Module实现
为了在YOLOv8(基于PyTorch)中使用,我们需要将DWT和IDWT实现为PyTorch的层。幸运的是,我们可以利用PyWavelets库,并将其包装在nn.Module中。
下面是一个完整、可运行的小波卷积模块WTConv的实现代码。
import torch
import torch.nn as nn
import pywt
import numpy as np
# ---------------------------------------------------
# 步骤1:实现DWT和IDWT作为PyTorch可微分操作
# ---------------------------------------------------
class DWT_2D
(nn.Module):
"""
实现2D离散小波变换作为PyTorch层。
"""
def __init__(self, wavelet='haar'):
"""
初始化DWT层。
参数:
wavelet (str): 使用的小波类型,如 'haar', 'db1', 'coif1'等。
"""
super(DWT_2D, self).__init__()
self.wavelet = wavelet
# 获取小波变换的滤波器系数
# w = pywt.Wavelet(wavelet)
# dec_lo, dec_hi, rec_lo, rec_hi = w.filter_bank
# dec_lo (低通分解), dec_hi (高通分解)
# rec_lo (低通重构), rec_hi (高通重构)
# 使用Haar小波的固定滤波器
# 这是Haar小波的低通和高通分解滤波器
dec_lo = [1/np.sqrt(2), 1/np.sqrt(2)]
dec_hi = [-1/np.sqrt(2), 1/np.sqrt(2)]
# 将滤波器转换为torch张量
# 准备用于2D卷积的滤波器形状 (out_channels, in_channels, height, width)
# LL: 低通 x 低通
# LH: 低通 x 高通
# HL: 高通 x 低通
# HH: 高通 x 高通
# 创建四个滤波器
filter_ll = torch.tensor(dec_lo)[:, None] * torch.tensor(dec_lo)[None, :]
filter_lh = torch.tensor(dec_lo)[:, None] * torch.tensor(dec_hi)[None, :]
filter_hl = torch.tensor(dec_hi)[:, None] * torch.tensor(dec_lo)[None, :]
filter_hh = torch.tensor(dec_hi)[:, None] * torch.tensor(dec_hi)[None, :]
# 将四个滤波器堆叠起来
# 最终形状为 (4, 1, 2, 2)
self.filters = torch.stack([filter_ll, filter_lh, filter_hl, filter_hh], dim=0)
# 注册为模型的缓冲区,这样它会被移动到正确的设备(CPU/GPU)
self.register_buffer('wavelet_filters', self.filters)
def forward(self, x):
"""
前向传播。
参数:
x (Tensor): 输入特征图,形状为 (B, C, H, W)。
返回:
四元组 (LL, LH, HL, HH),每个子带的形状为 (B, C, H/2, W/2)。
"""
B, C, H, W = x.shape
# 将输入张量重塑,以将通道维度视为批次维度
# 这样我们可以对每个通道独立应用相同的2D卷积滤波器
# 形状变为 (B*C, 1, H, W)
x_reshaped = x.reshape(B * C, 1, H, W)
# 准备滤波器
# 扩展滤波器以匹配输入通道
# 形状变为 (4, 1, 2, 2)
filters = self.wavelet_filters.to(x.device, dtype=x.dtype)
# 使用卷积实现DWT
# stride=2 实现下采样
# padding=0
# 输出形状为 (B*C, 4, H/2, W/2)
out = nn.functional.conv2d(x_reshaped, filters, stride=2)
# 重新整理输出
# 将通道维度分离出来
# 形状恢复为 (B, C, 4, H/2, W/2)
out = out.reshape(B, C, 4, H // 2, W // 2)
# 分离四个子带
LL = out[:, :, 0, :, :]
LH = out[:, :, 1, :, :]
HL = out[:, :, 2, :, :]
HH = out[:, :, 3, :, :]
return LL, LH, HL, HH
class IDWT_2D
(nn.Module):
"""
实现2D逆离散小波变换作为PyTorch层。
"""
def __init__(self, wavelet='haar'):
"""
初始化IDWT层。
"""
super(IDWT_2D, self).__init__()
self.wavelet = wavelet
# 使用Haar小波的固定重构滤波器
rec_lo = [1/np.sqrt(2), 1/np.sqrt(2)]
rec_hi = [1/np.sqrt(2), -1/np.sqrt(2)] # 注意,与dec_hi符号相反
# 创建四个重构滤波器
filter_ll = torch.tensor(rec_lo)[:, None] * torch.tensor(rec_lo)[None, :]
filter_lh = torch.tensor(rec_lo)[:, None] * torch.tensor(rec_hi)[None, :]
filter_hl = torch.tensor(rec_hi)[:, None] * torch.tensor(rec_lo)[None, :]
filter_hh = torch.tensor(rec_hi)[:, None] * torch.tensor(rec_hi)[None, :]
self.filters = torch.stack([filter_ll, filter_lh, filter_hl, filter_hh], dim=0)
self.register_buffer('wavelet_rec_filters', self.filters)
def forward(self, LL, LH, HL, HH):
"""
前向传播。
参数:
LL, LH, HL, HH (Tensor): DWT的四个子带。
返回:
重构后的特征图。
"""
# 将四个子带在通道维度上拼接
# 输入形状 (B, C, H/2, W/2) -> (B, C, 4, H/2, W/2)
coeffs = torch.stack([LL, LH, HL, HH], dim=2)
B, C, _, H, W = coeffs.shape
# 重塑以进行卷积操作
# (B*C, 4, H, W)
coeffs_reshaped = coeffs.reshape(B * C, 4, H, W)
# 准备滤波器
filters = self.wavelet_rec_filters.to(coeffs.device, dtype=coeffs.dtype)
# 将滤波器形状从 (4, 1, 2, 2) 变为 (1, 4, 2, 2) 以用于转置卷积
# 实际上,我们需要 (in_channels, out_channels, kH, kW)
# 这里 in_channels=4, out_channels=1
filters = filters.permute(1, 0, 2, 3).flip(2, 3) # 转置卷积核需要翻转
# 使用转置卷积实现IDWT(上采样和滤波)
# stride=2
# 输出形状 (B*C, 1, H*2, W*2)
out = nn.functional.conv_transpose2d(coeffs_reshaped, filters, stride=2)
# 恢复原始形状 (B, C, H*2, W*2)
out = out.reshape(B, C, H * 2, W * 2)
return out
# ---------------------------------------------------
# 步骤2:构建WTConv模块
# ---------------------------------------------------
class WTConv
(nn.Module):
"""
小波卷积模块。
执行 DWT -> 卷积 -> IDWT 的流程。
"""
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, separate=False):
"""
初始化WTConv模块。
参数:
in_channels (int): 输入通道数。
out_channels (int): 输出通道数。
kernel_size (int): 卷积核大小。
stride (int): 卷积步长。
padding (int): 卷积填充。
separate (bool): 是否为每个子带使用独立的卷积核。
True: 参数量更大,可能性能更好。
False: 参数共享,更轻量。
"""
super(WTConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.separate = separate
self.dwt = DWT_2D(wavelet='haar')
self.idwt = IDWT_2D(wavelet='haar')
if separate:
# 为四个子带分别定义卷积层
# 输出通道数需要相应调整,以保证最后IDWT后总通道数正确
# 这里我们让每个分支输出 out_channels,最后拼接成 4*out_channels
# 这是不正确的,因为IDWT要求输入通道数与DWT的输入通道数一致。
# 正确的做法是,每个分支输入输出通道数不变
self.conv_ll = nn.Conv2d(in_channels, in_channels, kernel_size, stride, padding)
self.conv_lh = nn.Conv2d(in_channels, in_channels, kernel_size, stride, padding)
self.conv_hl = nn.Conv2d(in_channels, in_channels, kernel_size, stride, padding)
self.conv_hh = nn.Conv2d(in_channels, in_channels, kernel_size, stride, padding)
else:
# 所有子带共享一个卷积层
self.conv = nn.Conv2d(in_channels, in_channels, kernel_size, stride, padding)
# 如果输入输出通道数不同,需要一个额外的1x1卷积来匹配通道
if in_channels != out_channels:
self.channel_matcher = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
else:
self.channel_matcher = nn.Identity()
def forward(self, x):
"""
前向传播。
"""
# 1. DWT分解
LL, LH, HL, HH = self.dwt(x)
# 2. 对每个子带进行卷积
if self.separate:
LL_c = self.conv_ll(LL)
LH_c = self.conv_lh(LH)
HL_c = self.conv_hl(HL)
HH_c = self.conv_hh(HH)
else:
LL_c = self.conv(LL)
LH_c = self.conv(LH)
HL_c = self.conv(HL)
HH_c = self.conv(HH)
# 3. IDWT重构
reconstructed = self.idwt(LL_c, LH_c, HL_c, HH_c)
# 4. 如果需要,匹配输出通道
out = self.channel_matcher(reconstructed)
return out
# --- 模块测试 ---
if __name__ == '__main__':
# 创建一个随机输入张量 (Batch, Channels, Height, Width)
test_tensor = torch.randn(2, 64, 32, 32)
# 测试DWT
print("--- Testing DWT ---")
dwt_layer = DWT_2D()
ll, lh, hl, hh = dwt_layer(test_tensor)
print(f"Input shape: {test_tensor.shape
}")
print(f"LL shape: {ll.shape
}, LH shape: {lh.shape
}, HL shape: {hl.shape
}, HH shape: {hh.shape
}")
# 测试IDWT
print("\n--- Testing IDWT ---")
idwt_layer = IDWT_2D()
reconstructed_tensor = idwt_layer(ll, lh, hl, hh)
print(f"Reconstructed shape: {reconstructed_tensor.shape
}")
# 检查重构误差
reconstruction_error = torch.mean(torch.abs(test_tensor - reconstructed_tensor))
print(f"Reconstruction error (should be close to 0): {reconstruction_error.item():.6f
}")
# 测试WTConv模块
print("\n--- Testing WTConv ---")
# Case 1: in_channels == out_channels, separate=False
wt_conv_1 = WTConv(in_channels=64, out_channels=64, separate=False)
output_1 = wt_conv_1(test_tensor)
print(f"WTConv (shared) output shape: {output_1.shape
}")
# Case 2: in_channels != out_channels, separate=True
wt_conv_2 = WTConv(in_channels=64, out_channels=128, separate=True)
output_2 = wt_conv_2(test_tensor)
print(f"WTConv (separate) output shape: {output_2.shape
}")4.3 代码深度解析
DWT_2D模块:- 我们没有直接使用循环或复杂的索引,而是巧妙地利用2D卷积来实现DWT。
haar小波的分解滤波器是 [ 1 / s q r t ( 2 ) , 1 / s q r t ( 2 ) ] [1/sqrt(2),1/sqrt(2)] [1/sqrt(2),1/sqrt(2)](低通)和 [ − 1 / s q r t ( 2 ) , 1 / s q r t ( 2 ) ] [-1/sqrt(2), 1/sqrt(2)] [−1/sqrt(2),1/sqrt(2)](高通)。 - 通过将这两种1D滤波器进行外积,我们得到了四个2D滤波器(
filter_ll,filter_lh,filter_hl,filter_hh),它们的大小都是2x2。 - 将这四个滤波器作为`conv2d的权重,并设置
stride=2,就可以一次性计算出所有四个子带,并且完成了2倍的下采样。这是一种非常高效的实现方式。 register_buffer用于注册不会被视为模型参数的张量(即,在反向传播中不需要要计算梯度),但它会随着模型一起被移动到CPU或GPU。
- 我们没有直接使用循环或复杂的索引,而是巧妙地利用2D卷积来实现DWT。
IDWT_2D模块:- IDWT是DWT的逆过程,我们使用转置卷积(
conv_transpose2d) 来实现。转置卷积可以同时完成上采样和卷积操作。
- IDWT是DWT的逆过程,我们使用转置卷积(
其滤波器是
DWT滤波器的“逆”,同样通过高效的卷积操作,将四个子带融合成一个完整的特征图。
WTConv主模块:- 它将
DWT_2D和IDWT_2D串联起来,中间加入了标准的nn.Conv2d层。 separate参数提供了一个灵活的选项,允许用户在参数效率和模型容量之间做权衡。separate=True时,参数量大约是`False时的四倍,但为网络学习特定于频率的模式提供了更大的自由度。channel_matcher确保了模块的通用性,无论输入输出通道是否匹配,它都能作为一个标准的构建块使用。
- 它将
这段代码不仅是一个概念验证,它是一个健壮、高效且可直接用于任何PyTorch模型的构建块。
五、实战演练:YOLOv8小波卷积
现在,激动人心的时刻到了!我们要将我们精心打造的WTConv模块植入到强大的YOLOv8模型中。
5.1 集成策略:替换还是增强?
我们可以在YOLOv8的多个位置集成WTConv,每种策略都有其独特的优势。
策略一:在主干网络(Backne)中集成
我们可以用WTConv替换掉主干网络中的部分Conv或C2f模块。
- 优势: 从网络的早期就开始引入空-频域分析能力,使得底层特征就同时包含丰富的空间和频率信息,为后续层提供更高质量的特征基础。
- 劣势: 可能会增加模型的计算负担,尤其是在高分辨率的浅层网络中。
- 适用场景: 当检测任务对物体的精细纹理、材料质感非常敏感时(如工业瑕疵检测、农作物病害识别),此策略可能效果显著。
相关流程图示 (替换C2f):
策略二:在颈部网络(Neck)中集成
YOLOv8的PANet颈部结构负责融合来自主干网络不同层级的特征。我们可以在这里的上采样或下采样路径中,使用WTConv替换Conv。
- 优势: 专注于改善多尺度特征的融合过程。DWT的分解特性天然地适合处理和融合不同分辨率的特征图。
- 劣势: 对底层特征的质量依赖较高。
- 适用场景: 普遍适用于需要提升大、小目标检测均衡性的场景。
策略三:作为样层
传统下采样(stride=2的卷积或MaxPooling)会丢失信息。DWT本身就是一个2倍下采样的过程(生成LL子带),但同时保留了高频细节在其他子带中。我们可以设计一个基于DWT的下采样模块。
- 思路: 输入特征图 -> DWT -> 只传递LL子带到下一层。同时,可以将LH, HL, HH子带通过旁路连接(shortcut)或注意力机制融合到后续层,实现信息的补偿。
- 优势: 实现信息损失更少的下采样,理论上可以保留更多细节。
- 劣势: 设计相对复杂,需要仔细处理旁路连接。
我们将以策略一为例,展示具体的步骤。
5.2 修改YOLOv8模型配置文件(YAML)
首先,我们需要在模型的.yaml文件中定义我们的新模块。假设我们将YOLOv8n的最后一个C2f块替换为`WTonv`。
打开yolov8n.yaml文件,找到backbone的定义部分。
原始yolov8n.l (部分):
# Ultralytics YOLO , AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv8.0n backbone
backbone:
# [from, number, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]] # 2
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]] # 4
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]] # 6
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]] # 8
- [-1, 1, SPPF, [1024, 5]] # 9 我们将第8层的C2f替换为WTConv。我们需要为WTConv定义参数[out_channels, separate]。假设我们使用共享权重的版本。
修改后的yolov8n-wtconv.yaml ():
# ... (参数部分不变) ...
# YOLOv8.0n backbone with WTConv
backbone:
# [from, number, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]] # 2
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]] # 4
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]] # 6
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
# 将原来的 C2f 替换为 WTConv
# WTConv 参数: [out_channels, separate (0 for False, 1 for True)]
# 输入通道数会从上一层自动推断 (1024)
- [-1, 3, WTConv, [1024, 0]] # 8 (REPLACED)
- [-1, 1, SPPF, [1024, 5]] # 95.3 注册新模块:让YOLOv8“认识”WTConv
仅仅修改YAML文件是不够的,YOLOv8的解析器需要知道WTConv这个字符串对应哪个Python类。我们需要将WTConv模块的定义代码添加到YOLOv8的项目代码中,并进行注册。
- 添加代码文件: 将我们上面编写的
WTConv完整代码(包含`DWT_,IDWT_2D,WTConv类)保存为一个Python文件,例如 \ultralytics/nn/modules/tconv.py`。 - 导入并注册: 打开
ultralytics/nn/tasks.py文件(或者相关的模型构建文件),在文件的开头部分,从我们新建的文件中导入WTConv类,并将其添加到MODULES字典或类似的注册表中,让YOLOv8的解析器能够找到它。
修改 ultralytics/nn/tasks.py (示例):
# ... 其他的导入 ...
from ultralytics.nn.modules import (AIFI, C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x,
Classify, Concat, Conv, Conv2, ConvTranspose, Detect, DWConv, DWConvTranspose,
Focus, GhostBottleneck, GhostConv, HGBlock, HGStem, Pose, RepC3, RepConv,
RTDETRDecoder, Segment)
# --- 在这里添加我们的导入 ---
from ultralytics.nn.modules.wtconv import WTConv
# ... (文件中的其他代码) ...
def parse_model(d, ch, verbose=True): # model_dict, input_channels
# ... (函数内代码) ...
# 在 for 循环解析每一层之前,确保我们的模块在可识别的列表中
# YOLOv8 v8.1+ 可能使用了一种自动注册机制,但手动添加可以确保兼容性
# 通常,你只需要确保你的模块类被导入到这个作用域即可
# 如果有类似下面的字典,就添加进去
# modules = { 'Conv': Conv, 'C2f': C2f, ... }
# 如果没有,确保导入语句被执行就可能足够了
# 在循环内部,解析器会根据 'm' 的字符串 (如 'WTConv') 寻找对应的类
# for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):
# m = eval(m) if isinstance(m, str) else m # eval strings
# ...
# 你需要确保当 m = "WTConv" 时, eval(m) 能够找到我们导入的 WTConv 类。
# 上面的导入语句通常就能保证这一点。
# ... (函数的其余部分) ...注意:不同版本的YOLOv8代码结构可能略有不同。核心思想是找到模型解析函数(通常是
parse_model),并确保它能够通过模块名称字符串找到你添加的模块类。最简单的方法就是将你的模块类和YOLOv8原生的模块(如Conv,C2f)放在一起被导入。
5.4 完整代码集成示例
为了方便您实践,这里提供一个简化的集成思路:
项目准备: 克隆最新的YOLOv8仓库。
git clone https://github.com/ultralytics/ultralytics.git创建: 在
ultralytics/nn/modules/目录下创建一个新文件custom.py。粘贴代码: 将上面我们编写的
DWT_2D,IDWT_2D,WTConv三个类的完整代码粘贴到custom.py中。修改
__init__.py: 打开ultralytics/nn/modules/__init__.py文件,在文件末尾添加一行,以导出我们的新模块:# ... 其他导出 ... from .custom import WTConv __all__ = (..., 'WTConv') # 将 'WTConv' 添加到 __all__ 列表中YAML: 在项目根目录下创建一个
yolov8n-wtconv.yaml文件,内容如5.2节所示。开始训练: 现在你可以像使用官方模型一样,使用这个新的配置文件进行训练了!
yolo train data=coco128.yaml model=yolov8n-wtconv.yaml epochs=100 imgsz=640
搞定!就是这么简单,YOLOv8的灵活性让我们的创新集成变得轻而易举。
六、实验与展望:性能分析与未来方向
6.1 预期效果理与细节的双重增强
集成WTConv后,我们预期会观察到以下性能变化:
- mAP提升: 特别是在那些依赖精细纹理进行分类和定位的数据集上(如遥感图像中的飞机、船只检测,医学影像中的病灶识别,布匹瑕疵检测等),mAP有望获得提升。
- 小目标检测改善: DWT能够保留高频细节,这对于小目标的边缘和结构信息至关重要。因此,
WTConv可能会提升模型对小目标的召回率和精度。 - 鲁增强: 对于包含噪声或伪影的图像,
WTConv可能表现出更好的鲁棒性,因为它能够将高频噪声分离到特定子带中,网络可以学习去抑制这些子带的响应。
6.2 计算复杂度率权衡
天下没有免费的午餐。WTConv的引入也会带来额外的计算开销。
参数量:
separate=False(共享权重)时,WTConv比一个标准Conv多出的主要是DWT/IDWT的计算,参数量增加不多(只有一个Conv层)。separate=True(独立权重)时,参数量是一个标准Conv的四倍,会显著增加模型大小。
FLOPs: DWT和IDWT本身涉及卷积操作,会增加模型的计算量(FLOPs)。这可能导致训练和推理速度小幅下降。
因此,在使用WTConv时,需要进行细致的消融实验,找到替换模块的数量、位置以及是否使用separate模式的最佳平衡点,以在性能提升和效率损失之间做出最优权衡。
6.3 潜在应用场景
除了通用的目标检测,WTConv的特性使其在以下领域具有巨大潜力:
- 图像复原与去噪: 在DWT子带上进行处理是图像去噪的经典方法。将此思想融入检测模型,可能实现去噪与检测的端到端联合优化。
- 图像超分辨率: 低频LL子带包含了图像的宏观结构,可以用于超分辨率任务中的结构保持。
- 对抗攻击: 对抗样本通常通过添加高频扰动来攻击模型。
WTConv可以将这些扰动分离到高频子带,使得模型有可能学习到如何忽略它们。
七、总结与展望
在本篇内容中,我们进行了一次跨越传统信号处理与现代深度学习的探索。
- 我们从传统卷积的局限性出发,理解了引入**频率域分析的必要性。
- 我们深入学习了小波变换,特别是2D-DWT的原理,并掌握了如何用代码实现它对图像的分解。
- 我们从零开始,设计并实现了一个即插即用的**小波卷积模块(TConv`)**,并提供了两种权重策略(共享/独立)。
- 我们手把手地演示了如何将
WTConv无`无缝集成到YOLOv8的架构中,并给出了详细的配置文件和代码修改指南。 - 最后,我们分析了TConv`的预期效果、计算成本,并展望了其广阔的应用前景。
小波卷积为我们打开了一扇新的大门,它证明了经典的数学工具在深度学习时代依然能绽放出耀眼的光芒。它提醒我们,模型创新的道路不止是堆叠更深的网络或是设计更复杂的注意力,有时,回归基础,从不同的数学视角审视问题,或许能收获意想不到的惊喜。
希望本节课的内容能为您带来启发!动手试试将WTConv应用到你的项目中吧,期待你的成果!
八、敬请期待:下期内容预告 (深度可分离卷积)
今天,我们通过WTConv探索了如何从“深度”和“质量”上提升特征的表达能力。然而,在许多实际应用中,尤其是在移动端和嵌入式设备上,模型的“效率”和“速度”同样至关重要。
在下一节 《YOLOv8【卷积创新第9节】深度可分离卷积优化策略研究》 中,我们将把目光转向轻量化网络设计的核心基石——深度离卷积(Depthwise Separable Convolution)。
- 它如何将一个标准的卷积拆解为两步,从而实现计算量和参数量的指数级下降?
- MobileNet、ShuffleNet等经典轻量化网络是如何巧妙利用它的?
- 我们如何在YOLOv8中应用深度可分离卷积,来打造一个又快又准的定制化模型?
我们将一起揭开它高效的秘密,并探索一系列优化策略。敬请期待,我们下期再见!
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
PS:如果你在按照本文提供的方法进行YOLOv8优化后,依然遇到问题,请不要急躁或抱怨!YOLOv8作为一个高度复杂的目标检测框架,其优化过程涉及硬件、数据集、训练参数等多方面因素。如果你在应用过程中遇到新的Bug或未解决的问题,欢迎将其粘贴到评论区,我们可以一起分析、探讨解决方案。如果你有新的优化思路,也欢迎分享给大家,互相学习,共同进步!
文末福利,等你来拿!
文中讨论的技术问题大部分来源于我在YOLOv8项目开发中的亲身经历,也有部分来自网络及读者提供的案例。如果文中内容涉及版权问题,请及时告知,我会立即修改或删除。同时,部分解答思路和步骤来自全网社区及人工智能问答平台,若未能帮助到你,还请谅解!YOLOv8模型的优化过程复杂多变,遇到不同的环境、数据集或任务时,解决方案也各不相同。如果你有更优的解决方案,欢迎在评论区分享,撰写教程与方案,帮助更多开发者提升YOLOv8应用的精度与效率!
OK,以上就是我这期关于YOLOv8优化的解决方案,如果你还想深入了解更多YOLOv8相关的优化策略与技巧,欢迎查看我专门收集YOLOv8及其他目标检测技术的专栏《YOLOv8实战:从入门到深度优化》。希望我的分享能帮你解决在YOLOv8应用中的难题,提升你的技术水平。下期再见!
码字不易,如果这篇文章对你有所帮助,帮忙给我来个一键三连(关注、点赞、收藏),你的支持是我持续创作的最大动力。
同时也推荐大家关注我的公众号:「猿圈奇妙屋」,第一时间获取更多YOLOv8优化内容及技术资源,包括目标检测相关的最新优化方案、BAT大厂面试题、技术书籍、工具等,期待与你一起学习,共同进步!
Who am I?
我是bug菌,CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等社区博客专家,C站博客之星Top30,华为云多年度十佳博主,掘金多年度人气作者Top40,掘金等各大社区平台签约作者,51CTO年度博主Top12,掘金/InfoQ/51CTO等社区优质创作者;全网粉丝合计 30w+;更多精彩福利点击这里;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试真题、4000G PDF电子书籍、简历模板等海量资料,你想要的我都有,关键是你不来拿。

-End-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号