深入理解大语言模型:从token到next token prediction,小白程序员必学指南 - 详解
这篇文章介绍了大语言模型(LLM)的核心原理,重点讲解next token prediction机制。详细解释了token概念、tokenization过程、embedding和位置编码的添加方法,以及预训练和推理阶段的实现。还介绍了温度参数如何控制生成文本的随机性,并提供了nano-GPT的代码实现,帮助理解大语言模型的工作原理。

要理解大语言模型(LLM),首先要理解它的本质,无论预训练、微调还是在推理阶段,核心都是next token prediction,也就是以自回归的方式从左到右逐步生成文本。
什么是 token
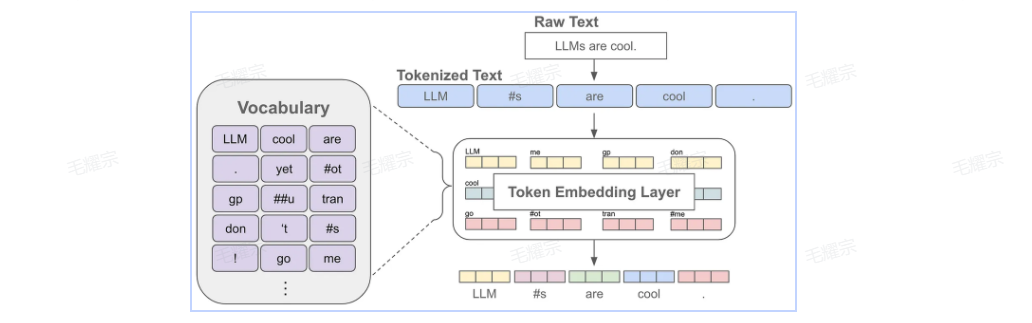
token是指文本中的一个词或者子词,给定一句文本,送入语言模型前首先要做的是对原始文本进行tokenize,也就是把一个文本序列拆分为离散的token序洌

其中,tokenize是在无标签的语料上训练得到的一个token数量固定且唯一的分词器,这里的token数量就是大家常说的词表
英文中的 Token
- 在英文中,Token 通常是单词、子词或标点符号。一个单词可能对应一个 Token,也可能被拆分为多个 Token。例如,“unhappiness” 可能被拆分为 “un”、“happi” 和 “ness”。
- 一般来说,1 个 Token 对应 3 至 4 个字母,或者约 0.75 个单词。
中文中的 Token
- 在中文中,Token 通常是单个汉字或经过分词后的词语。例如,“人工智能” 可能被拆分为 “人工” 和 “智能”。
- 不同平台对 Token 的定义有所不同。例如,通义千问和千帆大模型中 1 Token 等于 1 个汉字,而腾讯混元大模型中 1 Token 约等于 1.8 个汉字
当我们对文本进行分词后,每个token可以对应一个embedding,这也就是语言模型中的embedding层,获得某个token的embedding就类似一个查表的过程
我们知道文本序列是有顺序的,而常见的语言模型都是基于注意力机制的transformer结构,无法自动考虑文本的前后顺序,因此需要自动加上位置编码,也就是每个位置有一个位置embedding 然后和对应位置的token embedding进行相加
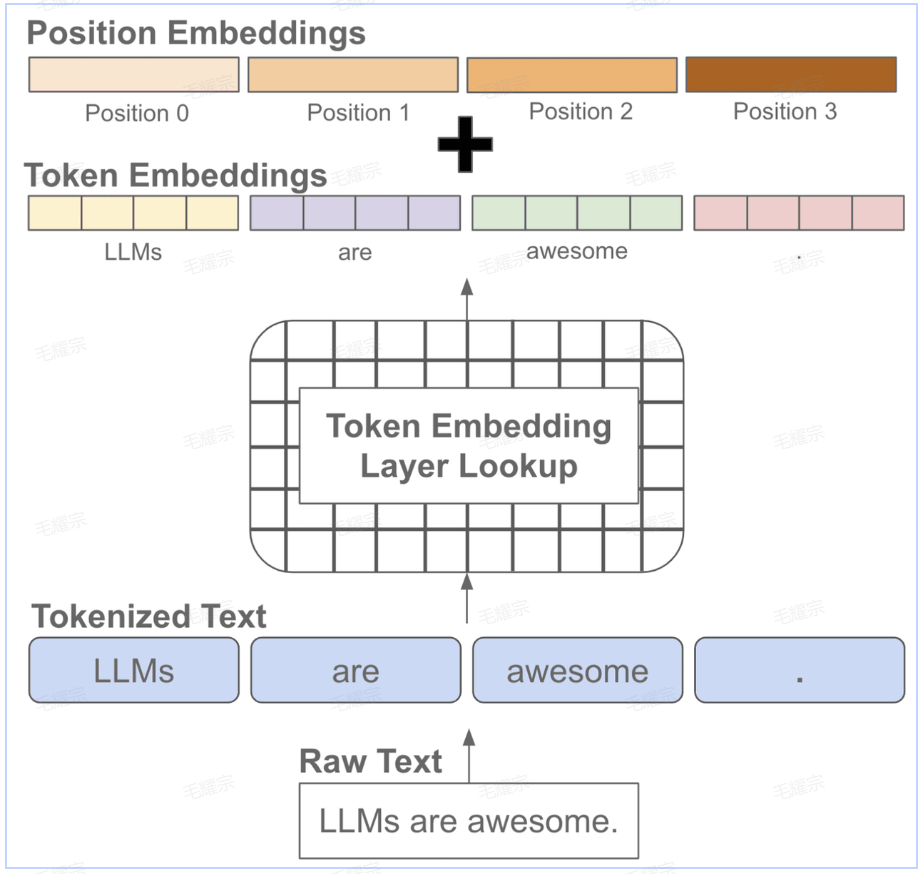
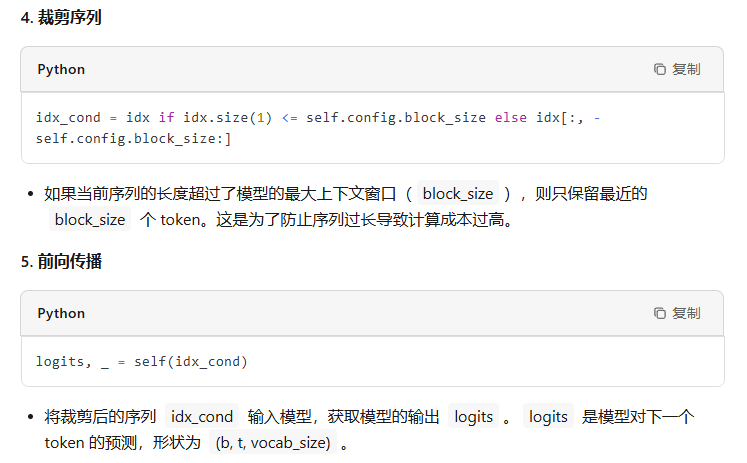
在模型训练或推理阶段大家经常会听到上下文长度这个词,它指的是模型训练时接收的token训练的最大长度,如果在训练阶段只学习了一个较短长度的位置embedding,那模型在推理阶段就不能够适用于较长文本(因为它没见过长文本的位置编码)
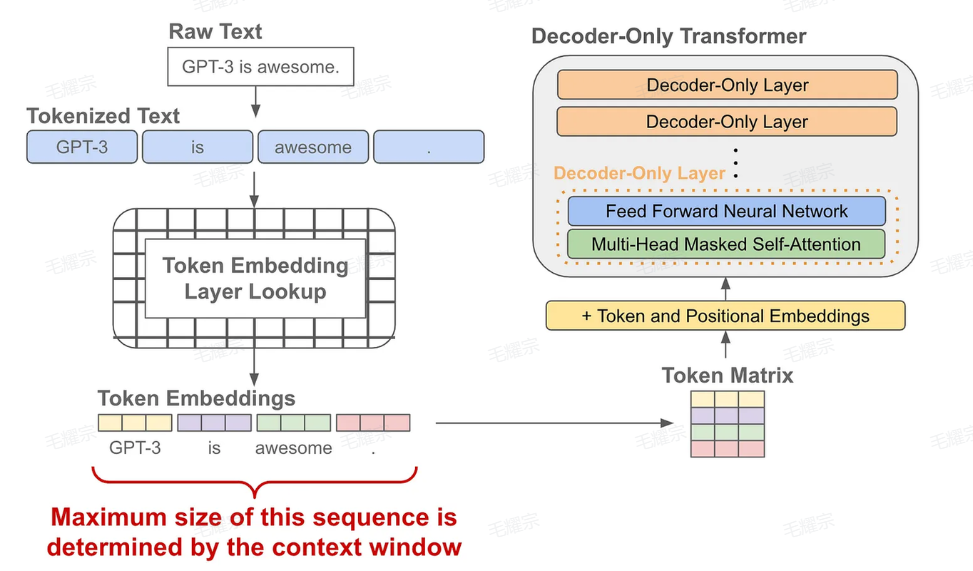
语言模型的预训练
当我们有了token的embedding和位置embedding后,将它们送入一个decoder-only的transofrmer模型,它会在每个token的位置输出一个对应的embedding(可以理解为就像是做了个特征加工)
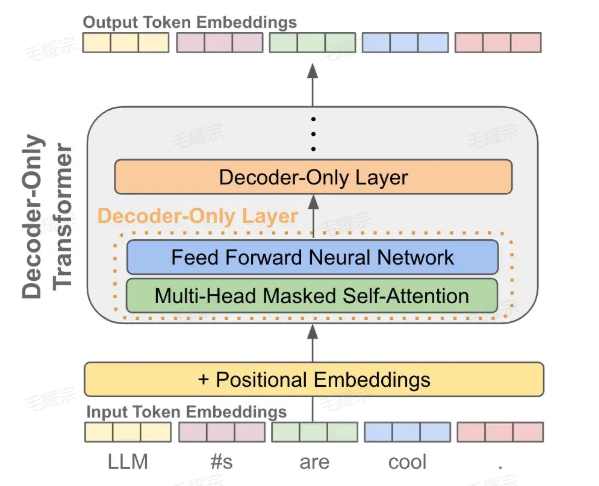
有了每个token的一个输出embedding后,我们就可以拿它来做 next token prediction了,其实就是当作一个分类问题来看待:
- 首先我们把输出embedding送入一个线性层,输出的维度是词表的大小,就是让预测这个token的下一个token属于词表的"哪一个"
- 为了将输出概率归一化,需要再进行一个softmax变换
- 训练时就是最大化这个概率使得它能够预测真实的下一个token
- 推理时就是从这个概率分布中采样下一个token
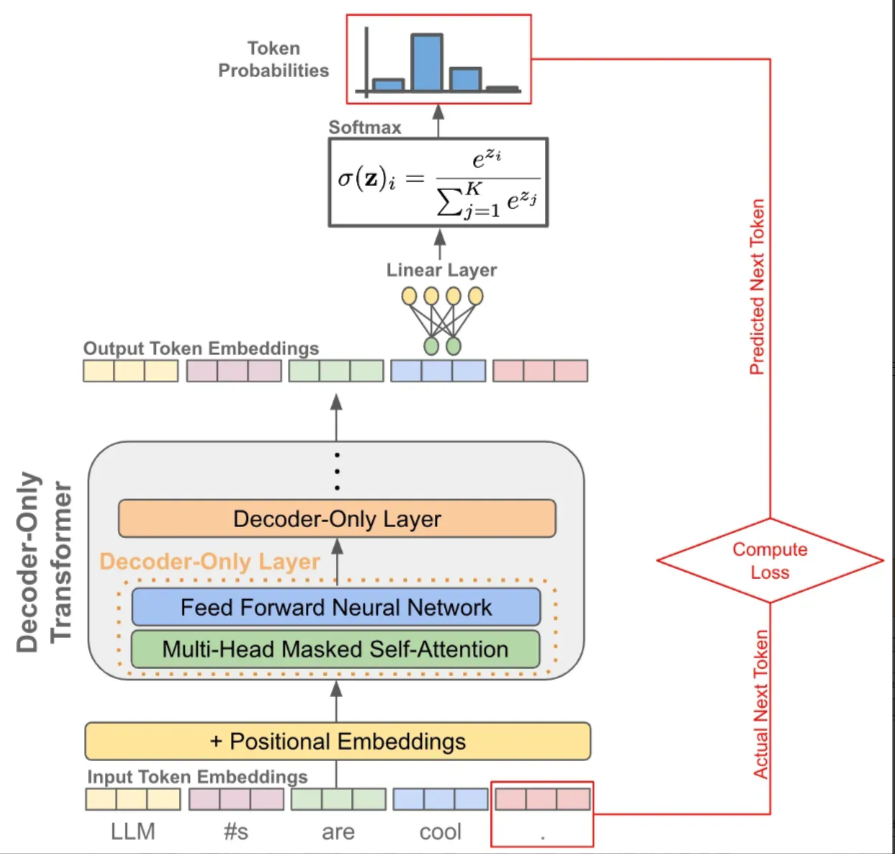
训练阶段: 因为有 因果自注意力(Causal Self-Attention)的存在,我们可以一次性对一整个句子每个token进行下一个token的预测,并计算所有位置token的loss
因果自注意力通过引入一个“掩码”(mask)来实现这一机制。具体来说:
- 在计算注意力权重时,模型会将当前时刻之后的所有位置的注意力权重设置为零。
- 这样,模型在预测下一个词时,只能基于已经生成的词(即前面的词)来进行预测。
推理阶段:以自回归的方式进行预测
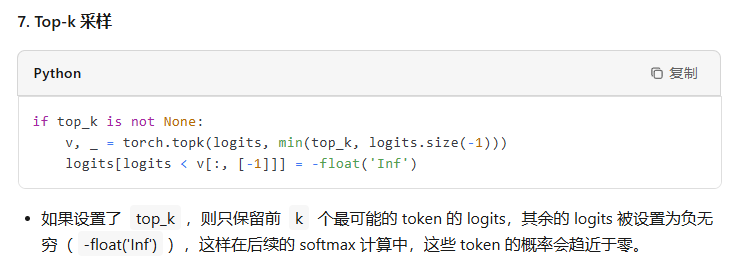
其中,在预测下一个token时,每次我们都有一个概率分布用于采样,根据不同场景选择采样策略会略有不同,比如有贪婪策略、核采样、Top-k采样等,另外经常会看到Temperature这个概念,它是用来控制生成的随机性的,温度系数越小越稳定。
代码实现
https://github.com/karpathy/nanoGPT/tree/master
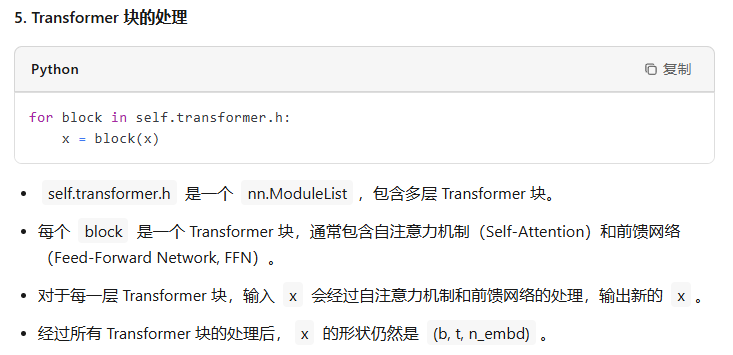
对于各种基于Transformer的模型,它们都是由很多个Block堆起来的,每个Block主要有两个部分组成:
- Multi-headed Causal Self-Attention
- Feed-forward Neural Network
结构的示意图如下:
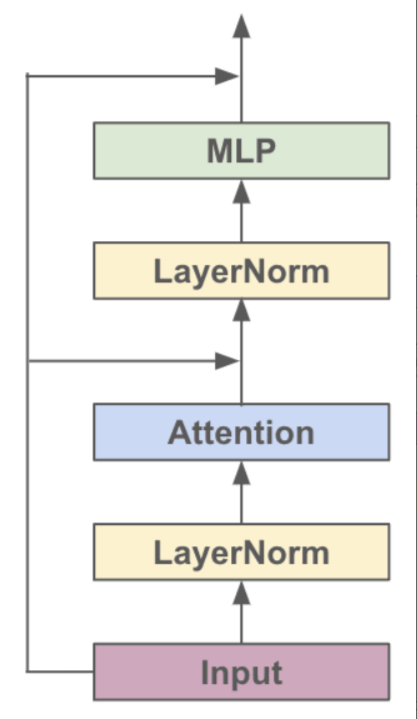
看图搭一下单个Block
classBlock(nn.Module):整个nano-GPT的结构
classGPT(nn.Module):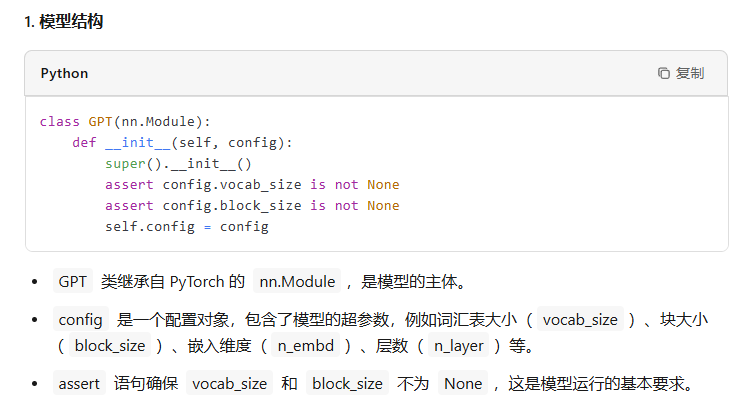
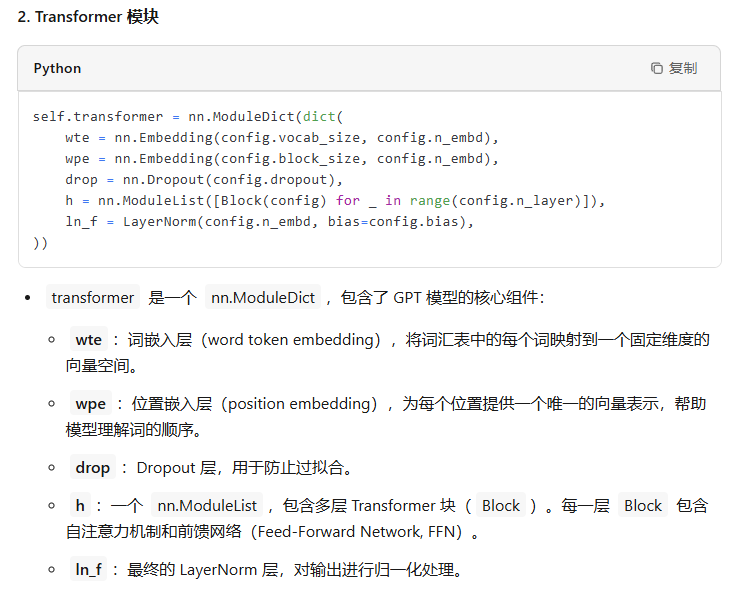
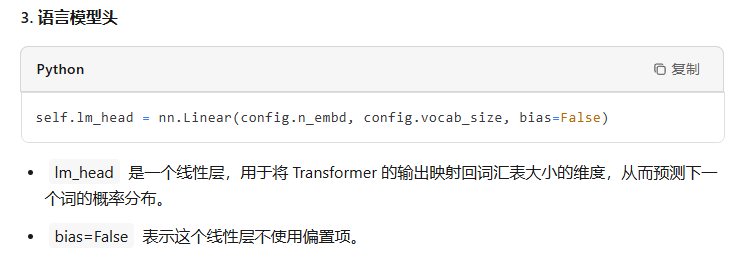
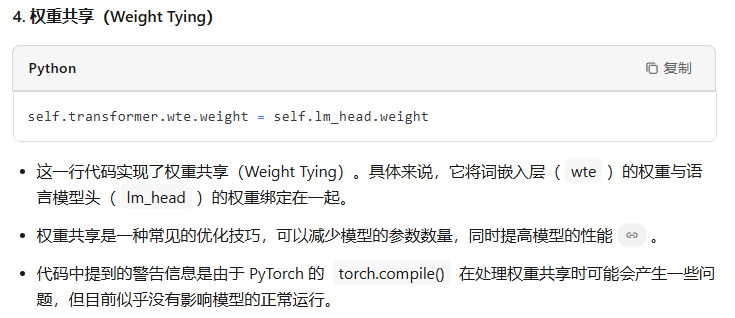
最后一层用来分类的线性层的权重和token embedding层的权重共享。
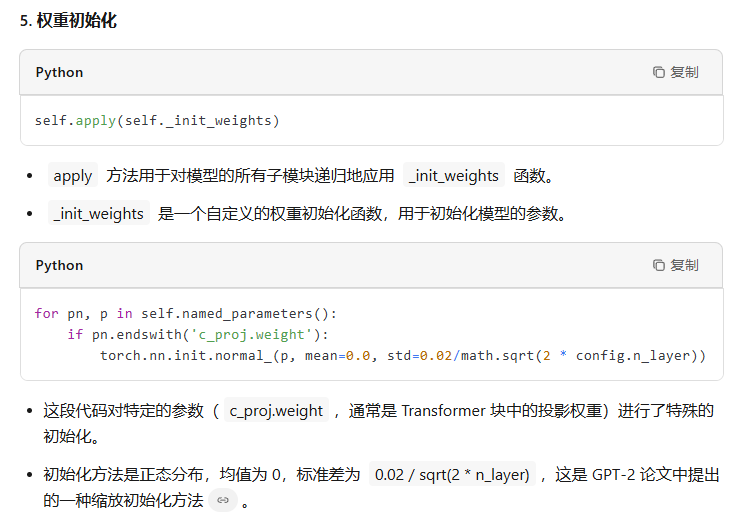
训练和推理的forward
首先需要构建token embedding和位置embedding,把它们叠加起来后过一个dropout,然后就可以送入transformer的block中了。
pos = torch.arange(0, t, dtype=torch.long, device=device) # shape (t)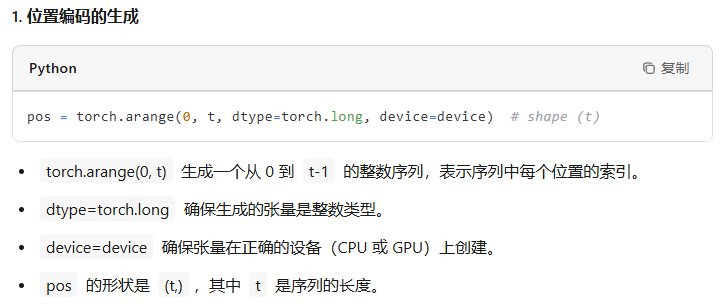


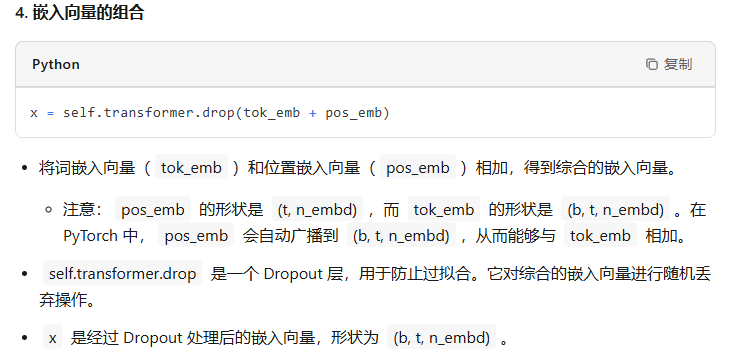

接下来看推理阶段
- 根据当前输入序列进行一次前向传播
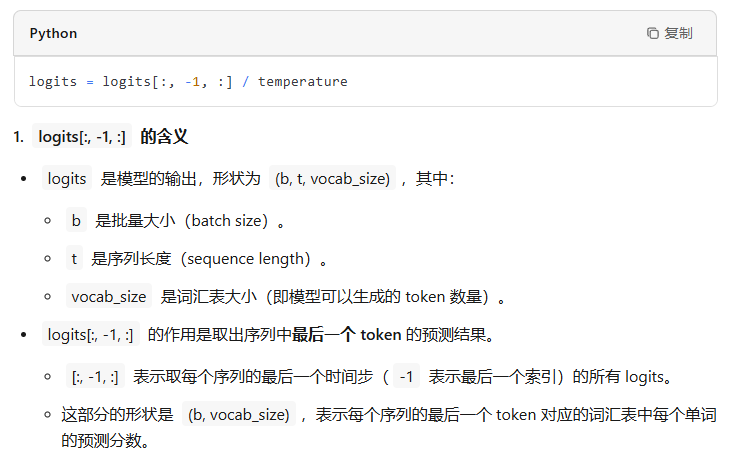
- 利用温度系数对输出概率分布进行调整
- 通过softmax进行归一化
- 从概率分布进行采样下一个token
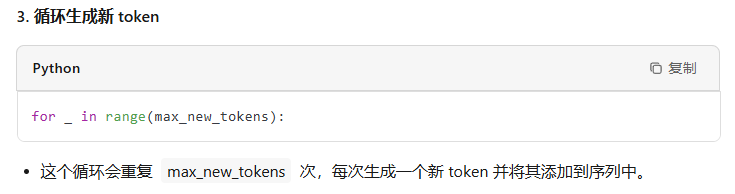
- 拼接到当前句子并再进入下一轮循环
@torch.no_grad()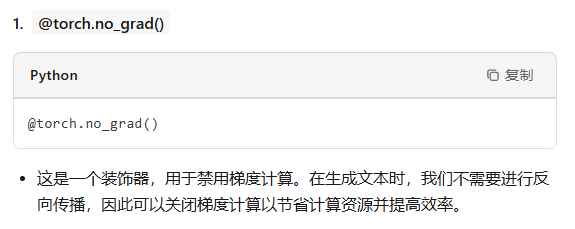
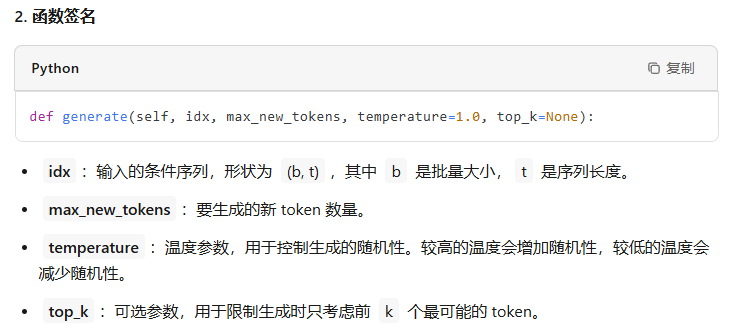

温度参数(Temperature)的作用
温度参数 temperature 是一个超参数,用于控制生成文本的随机性。它的作用是调整 logits 的分布,从而影响最终的概率分布。
具体来说:
temperature > 1:增加随机性当温度参数大于 1 时,会放大 logits 的值,使得 logits 的分布更加“平坦”。
这意味着在 softmax 转换为概率分布后,各个 token 的概率会更加接近,从而增加生成结果的随机性。
例如,假设原始 logits 是
[10, 20, 30],除以温度参数 2 后变为[5, 10, 15],经过 softmax 后,概率分布会更加均匀。temperature < 1:减少随机性当温度参数小于 1 时,会缩小 logits 的值,使得 logits 的分布更加“尖锐”。
这意味着在 softmax 转换为概率分布后,高概率的 token 会更加突出,而低概率的 token 的概率会进一步降低,从而减少生成结果的随机性。
例如,假设原始 logits 是
[10, 20, 30],除以温度参数 0.5 后变为[20, 40, 60],经过 softmax 后,概率分布会更加集中在高概率的 token 上。temperature = 1:保持原始分布当温度参数等于 1 时,logits 不变,模型的输出概率分布保持原始的预测结果。
为什么要调整温度参数?
增加随机性(
temperature > 1):有助于生成更多样化的文本,避免模型总是生成相同的、高概率的 token。
适用于需要创造性或多样性的场景,例如诗歌生成、故事创作等。
减少随机性(
temperature < 1):有助于生成更稳定、更符合预期的文本,减少生成的噪声。
适用于需要高准确性的场景,例如机器翻译、问答系统等。
随着大模型的持续火爆,各行各业纷纷开始探索和搭建属于自己的私有化大模型,这无疑将催生大量对大模型人才的需求,也带来了前所未有的就业机遇。**正如雷军所说:“站在风口,猪都能飞起来。”**如今,大模型正成为科技领域的核心风口,是一个极具潜力的发展机会。能否抓住这个风口,将决定你是否能在未来竞争中占据先机。
那么,我们该如何学习大模型呢?
人工智能技术的迅猛发展,大模型已经成为推动行业变革的核心力量。然而,面对复杂的模型结构、庞大的参数量以及多样的应用场景,许多学习者常常感到无从下手。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。
为此,我们整理了一份全面的大模型学习路线,帮助大家快速梳理知识,形成自己的体系。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
大型预训练模型(如GPT-3、BERT、XLNet等)已经成为当今科技领域的一大热点。这些模型凭借其强大的语言理解和生成能力,正在改变我们对人工智能的认识。为了跟上这一趋势,越来越多的人开始学习大模型,希望能在这一领域找到属于自己的机会。
L1级别:启航篇 | 极速破界AI新时代
- AI大模型的前世今生:了解AI大模型的发展历程。
- 如何让大模型2C能力分析:探讨大模型在消费者市场的应用。
- 行业案例综合分析:分析不同行业的实际应用案例。
- 大模型核心原理:深入理解大模型的核心技术和工作原理。

L2阶段:攻坚篇 | RAG开发实战工坊
- RAG架构标准全流程:掌握RAG架构的开发流程。
- RAG商业落地案例分析:研究RAG技术在商业领域的成功案例。
- RAG商业模式规划:制定RAG技术的商业化和市场策略。
- 多模式RAG实践:进行多种模式的RAG开发和测试。

L3阶段:跃迁篇 | Agent智能体架构设计
- Agent核心功能设计:设计和实现Agent的核心功能。
- 从单智能体到多智能体协作:探讨多个智能体之间的协同工作。
- 智能体交互任务拆解:分解和设计智能体的交互任务。
- 10+Agent实践:进行超过十个Agent的实际项目练习。

L4阶段:精进篇 | 模型微调与私有化部署
- 打造您的专属服务模型:定制和优化自己的服务模型。
- 模型本地微调与私有化:在本地环境中调整和私有化模型。
- 大规模工业级项目实践:参与大型工业项目的实践。
- 模型部署与评估:部署和评估模型的性能和效果。

专题集:特训篇
- 全新升级模块:学习最新的技术和模块更新。
- 前沿行业热点:关注和研究当前行业的热点问题。
- AIGC与MPC跨领域应用:探索AIGC和MPC在不同领域的应用。

掌握以上五个板块的内容,您将能够系统地掌握AI大模型的知识体系,市场上大多数岗位都是可以胜任的。然而,要想达到更高的水平,还需要在算法和实战方面进行深入研究和探索。
- AI大模型学习路线图
- 100套AI大模型商业化落地方案
- 100集大模型视频教程
- 200本大模型PDF书籍
- LLM面试题合集
- AI产品经理资源合集
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,全面覆盖了AI大模型的理论探索、技术落地与行业实践等多个维度。无论您是从事科研工作的学者、专注于技术开发的工程师,还是对AI大模型充满兴趣的爱好者,这套报告都将为您带来丰富的知识储备与深刻的行业洞察,助力您更深入地理解和应用大模型技术。
三、大模型经典PDF籍
随着人工智能技术的迅猛发展,AI大模型已成为当前科技领域的核心热点。像GPT-3、BERT、XLNet等大型预训练模型,凭借其卓越的语言理解与生成能力,正在重新定义我们对人工智能的认知。为了帮助大家更高效地学习和掌握这些技术,以下这些PDF资料将是极具价值的学习资源。

四、AI大模型商业化落地方案
AI大模型商业化落地方案聚焦于如何将先进的大模型技术转化为实际的商业价值。通过结合行业场景与市场需求,该方案为企业提供了从技术落地到盈利模式的完整路径,助力实现智能化升级与创新突破。

希望以上内容能对大家学习大模型有所帮助。如有需要,请微信扫描下方CSDN官方认证二维码免费领取相关资源【保证100%免费】。

祝大家学习顺利,抓住机遇,共创美好未来!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号