实用指南:InvokeAI 开源项目深度技术分析
项目概述
InvokeAI 是一个基于 Stable Diffusion 的创意引擎,为专业人士、艺术家和爱好者提供强大的 AI 驱动图像生成技术。该项目采用现代化的全栈架构,提供了业界领先的 Web UI 和完整的工作流管理解决方案。
技术栈分析
后端技术栈
- Python 3.8+: 核心编程语言
- FastAPI: 高性能异步 Web 框架,提供 HTTP API
- Socket.IO: 实时双向通信
- Pydantic: 数据验证和序列化
- PyTorch: 深度学习框架
- Diffusers: Hugging Face 的扩散模型库
- SQLite: 轻量级数据库存储
- OpenCV: 图像处理
前端技术栈
- TypeScript: 类型安全的 JavaScript 超集
- React 18: 用户界面库
- Redux Toolkit: 状态管理
- Chakra UI: 组件库
- Mantine: UI 组件库
- Konva: 2D Canvas 库(用于 Unified Canvas)
- Vite: 现代构建工具
AI/ML 技术栈
- Stable Diffusion 1.5/2.0/XL: 图像生成模型
- FLUX: 最新的图像生成模型
- ControlNet: 图像控制技术
- LoRA: 低秩适应技术
- Textual Inversion: 文本反转嵌入
项目架构分析
整体架构图
┌─────────────────┐ ┌─────────────────┐
│ Web UI │ │ CLI │
│ (React) │ │ (Python) │
└─────────┬───────┘ └─────────┬───────┘
│ │
└──────┬───────────────┘
│
┌────────────┴─────────────┐
│ Web API │
│ FastAPI + Socket.IO │
└────────────┬─────────────┘
│
┌────────────┴─────────────┐
│ Invoke Framework │
│ Invoker | Sessions │
│ Services| Invocations │
└────────────┬─────────────┘
│
┌────────────┴─────────────┐
│ AI Core │
│ Diffusion Models │
│ Image Processing │
└──────────────────────────┘核心组件说明
1. Invoker(调用器)
- 框架的主要接口
- 管理会话和调用队列
- 维护调用服务和调用器服务
2. Sessions(会话)
- 维护调用图和执行历史
- 支持动态添加调用
- 不支持循环图结构
3. Invocations(调用)
- 独立的执行单元
- 位于
/invokeai/app/invocations - 自动发现和注册机制
4. Services(服务)
- 为调用提供核心功能访问
- 支持不同实现的抽象接口
- 按需加载模块依赖
优势分析
技术优势
- 现代化架构: 采用 FastAPI + React 的现代全栈架构
- 高性能: 异步处理,支持并发操作
- 可扩展性: 模块化设计,易于添加新功能
- 类型安全: Python 使用 Pydantic,前端使用 TypeScript
- 实时交互: Socket.IO 提供实时状态更新
- 工作流系统: 节点式工作流,支持复杂管道
用户体验优势
- 统一画布: 集成的画布实现,支持所有核心生成功能
- 直观界面: 业界领先的 Web UI 设计
- 灵活工作流: 可视化节点编辑器
- 丰富功能: 支持 inpainting、outpainting、upscaling 等
开发者友好
- 良好的文档: 完整的开发和贡献文档
- 自动化 CLI: 基于元数据自动生成
- 插件系统: 易于扩展的调用系统
- 活跃社区: Discord 支持和 GitHub 讨论
劣势分析
技术挑战
- 资源需求: GPU 内存需求较高
- 复杂性: 多层架构增加了系统复杂性
- 依赖管理: 大量 AI/ML 依赖,版本兼容性问题
- 性能瓶颈: 大模型加载和推理时间较长
使用限制
- 硬件要求: 需要兼容的 GPU 硬件
- 学习曲线: 高级功能需要一定学习成本
- 存储空间: 模型文件占用大量存储空间
- 网络依赖: 模型下载需要稳定网络连接
使用场景
1. 艺术创作
- 概念艺术: 快速生成概念设计稿
- 插画制作: 生成高质量插画作品
- 风格探索: 尝试不同艺术风格
2. 商业设计
- 营销素材: 生成广告和宣传图片
- 产品设计: 快速原型和概念验证
- 品牌设计: Logo 和视觉元素创建
3. 内容创作
- 社交媒体: 生成吸引人的社交媒体内容
- 博客文章: 配图和头图生成
- 游戏开发: 角色和场景设计
4. 教育培训
- AI 教学: 演示 AI 图像生成技术
- 创意培训: 艺术和设计课程辅助
- 研究项目: 学术研究和实验
5. 个人娱乐
- 头像生成: 个性化头像制作
- 艺术探索: 个人创意实验
- 礼品定制: 个性化礼品设计
代码结构分析
目录结构
invokeai/
├── app/ # 核心应用
│ ├── api/ # API 路由和端点
│ ├── invocations/ # 调用实现
│ ├── services/ # 服务层
│ └── api_app.py # FastAPI 应用
├── frontend/ # 前端代码
│ ├── web/ # React Web UI
│ └── cli/ # CLI 实现
├── backend/ # AI 核心功能
│ ├── model_management/ # 模型管理
│ ├── stable_diffusion/ # SD 实现
│ └── util/ # 工具函数
└── configs/ # 配置文件关键模块
1. API 层 (/invokeai/app/api/)
python
# routers/images.py - 图像相关 API
@router.post("/", response_model=ImageDTO)
async def create_image(
image_request: ImageGenerationRequest,
invoker: Invoker = Depends(get_invoker)
):
# 图像生成逻辑
pass2. 调用层 (/invokeai/app/invocations/)
python
# text_to_image.py - 文本到图像调用
class TextToImageInvocation(BaseInvocation):
"""Generate image from text prompt"""
prompt: str = InputField(description="Text prompt")
width: int = InputField(default=512)
height: int = InputField(default=512)
def invoke(self, context: InvocationContext) -> ImageOutput:
# 实现文本到图像生成
pass3. 服务层 (/invokeai/app/services/)
python
# image_records.py - 图像记录服务
class ImageRecordStorageService(ABC):
@abstractmethod
def get(self, image_name: str) -> ImageRecord:
pass
@abstractmethod
def save(self, image: ImageRecord) -> None:
pass主要执行步骤
1. 应用启动流程
- 配置加载: 读取配置文件和环境变量
- 服务初始化: 创建各种服务实例
- 模型加载: 加载 AI 模型到内存
- API 启动: 启动 FastAPI 服务器
- WebUI 服务: 提供静态文件服务
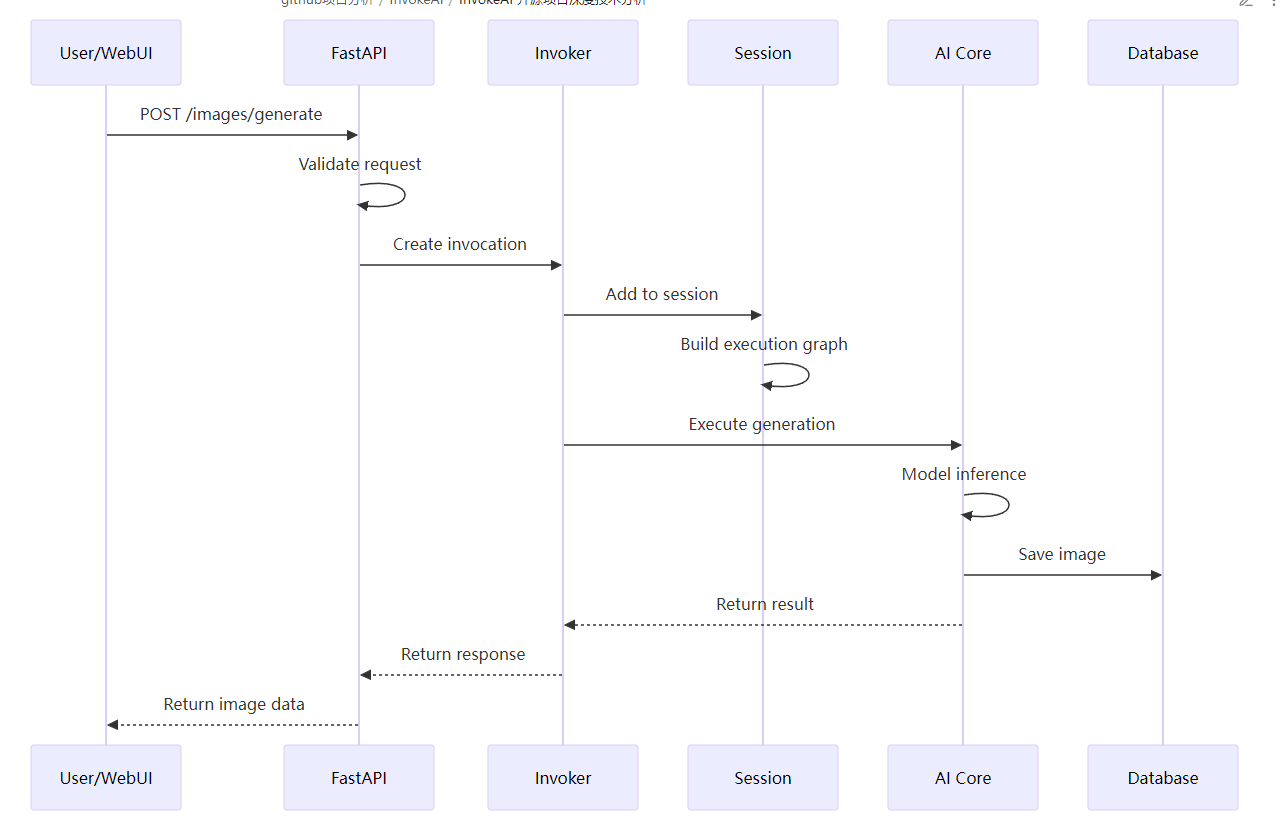
2. 图像生成流程
- 请求接收: API 接收生成请求
- 参数验证: Pydantic 验证输入参数
- 会话创建: 创建新的执行会话
- 调用图构建: 构建调用执行图
- 模型推理: 执行 AI 模型推理
- 结果处理: 处理和存储生成结果
- 响应返回: 返回结果给客户端
3. 工作流执行流程
- 工作流解析: 解析节点和连接
- 依赖分析: 分析节点依赖关系
- 执行规划: 制定执行计划
- 逐步执行: 按顺序执行节点
- 状态更新: 实时更新执行状态
- 结果汇总: 收集最终结果
时序图
图像生成时序图
mermaid
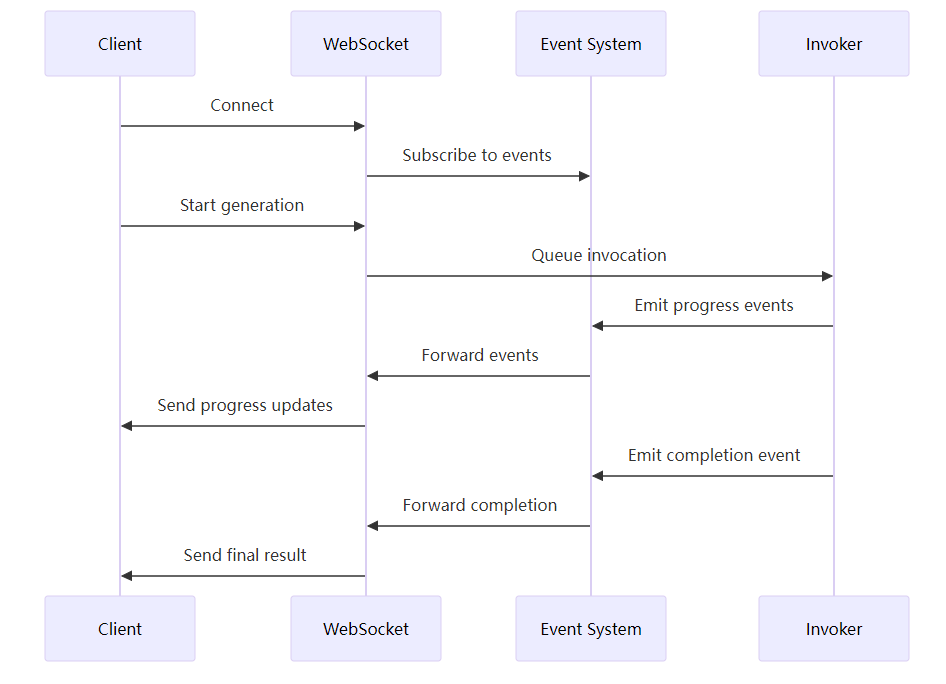
WebSocket 通信时序图
mermaid
开发示例
1. 创建自定义调用
python
# custom_filter.py
from invokeai.app.invocations.baseinvocation import (
BaseInvocation,
InputField,
InvocationContext
)
from invokeai.app.invocations.image import ImageField, ImageOutput
from invokeai.app.services.image_records import ImageCategory
from PIL import Image, ImageFilter
class BlurInvocation(BaseInvocation):
"""Apply blur filter to image"""
# 输入字段定义
image: ImageField = InputField(description="Input image")
radius: float = InputField(
default=2.0,
ge=0.0,
le=50.0,
description="Blur radius"
)
def invoke(self, context: InvocationContext) -> ImageOutput:
# 获取输入图像
image = context.services.images.get_pil_image(
self.image.image_name
)
# 应用模糊滤镜
blurred = image.filter(ImageFilter.GaussianBlur(self.radius))
# 保存结果图像
image_dto = context.services.images.create(
image=blurred,
image_origin=ResourceOrigin.INTERNAL,
image_category=ImageCategory.GENERAL,
session_id=context.graph_execution_state_id,
node_id=self.id,
)
return ImageOutput(
image=ImageField(image_name=image_dto.image_name),
width=blurred.width,
height=blurred.height,
)2. 创建自定义服务
python
# custom_service.py
from abc import ABC, abstractmethod
from typing import Optional
import requests
class WeatherServiceBase(ABC):
"""Weather service interface"""
@abstractmethod
def get_weather(self, location: str) -> dict:
pass
class OpenWeatherService(WeatherServiceBase):
"""OpenWeather API implementation"""
def __init__(self, api_key: str):
self.api_key = api_key
self.base_url = "https://api.openweathermap.org/data/2.5"
def get_weather(self, location: str) -> dict:
url = f"{self.base_url}/weather"
params = {
"q": location,
"appid": self.api_key,
"units": "metric"
}
response = requests.get(url, params=params)
return response.json()
# 在调用中使用服务
class WeatherPromptInvocation(BaseInvocation):
"""Generate weather-based prompt"""
location: str = InputField(description="Location for weather")
def invoke(self, context: InvocationContext) -> StringOutput:
# 从服务容器获取天气服务
weather_service = context.services.get("weather")
weather_data = weather_service.get_weather(self.location)
# 基于天气生成提示词
condition = weather_data["weather"][0]["main"].lower()
prompt = f"A beautiful {condition} day in {self.location}"
return StringOutput(value=prompt)3. 前端组件开发
typescript
// CustomFilterNode.tsx
import { memo } from 'react';
import { Handle, Position } from 'reactflow';
import { Box, FormControl, FormLabel, NumberInput } from '@chakra-ui/react';
import { useNodeData } from 'features/nodes/hooks/useNodeData';
const CustomFilterNode = ({ id }: { id: string }) => {
const { data, updateNodeData } = useNodeData(id);
const handleRadiusChange = (value: number) => {
updateNodeData(id, { radius: value });
};
return (
Blur Radius
handleRadiusChange(value)}
min={0}
max={50}
step={0.1}
/>
);
};
export default memo(CustomFilterNode);二次开发建议
1. 开发环境搭建
环境要求
- Python 3.8+
- Node.js 16+
- CUDA 兼容 GPU(推荐)
- 8GB+ 系统内存
- 20GB+ 存储空间
安装步骤
bash
# 克隆仓库
git clone https://github.com/invoke-ai/InvokeAI.git
cd InvokeAI
# 创建虚拟环境
python -m venv .venv
source .venv/bin/activate # Linux/Mac
# .venv\Scripts\activate # Windows
# 安装依赖
pip install -e ".[dev]"
# 安装前端依赖
cd invokeai/frontend/web
npm install2. 开发最佳实践
代码规范
- Python: 遵循 PEP 8,使用 black 格式化
- TypeScript: 遵循项目 ESLint 配置
- 提交信息: 使用 Conventional Commits 格式
- 测试覆盖: 为新功能编写单元测试
架构原则
- 单一职责: 每个调用只做一件事
- 依赖注入: 通过服务容器管理依赖
- 接口抽象: 为服务定义抽象接口
- 错误处理: 使用统一的错误处理机制
3. 扩展开发指南
添加新调用类型
- 在
/invokeai/app/invocations/创建新文件 - 继承
BaseInvocation类 - 定义输入输出字段
- 实现
invoke方法 - 添加相应的前端组件
创建新服务
- 定义抽象基类接口
- 实现具体服务类
- 在服务配置中注册
- 在调用中使用服务
扩展 API 端点
- 在
/invokeai/app/api/routers/添加路由 - 定义请求/响应模型
- 实现业务逻辑
- 添加适当的错误处理
4. 性能优化建议
后端优化
- 模型缓存: 实现智能模型加载和卸载
- 批处理: 支持批量图像处理
- 异步处理: 使用异步操作减少阻塞
- 内存管理: 及时清理不必要的内存占用
前端优化
- 虚拟化: 对大列表使用虚拟滚动
- 懒加载: 按需加载组件和资源
- 缓存策略: 合理使用 React Query 缓存
- 代码分割: 使用动态导入减少包大小
5. 部署和分发
Docker 部署
dockerfile
# Dockerfile 示例
FROM python:3.10-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
EXPOSE 9090
CMD ["python", "-m", "invokeai.app.api_app"]云部署考虑
- 容器化: 使用 Docker 容器化应用
- 负载均衡: 配置适当的负载均衡策略
- 存储: 使用云存储服务存储模型和图像
- 监控: 集成监控和日志系统
6. 社区参与
贡献流程
- Fork 项目仓库
- 创建功能分支
- 实现功能并测试
- 提交 Pull Request
- 响应 Code Review
获取帮助
- Discord: 加入官方 Discord 社区
- GitHub: 参与 GitHub 讨论和 Issues
- 文档: 查阅官方开发文档
- 示例: 研究现有调用和服务实现
主要分析内容:
- 技术栈详解 - InvokeAI 使用 Python (Pydantic, FastAPI, diffusers) 和 TypeScript (React, Redux Toolkit, ChakraUI, Mantine, Konva) 等技术 InvokeAIInvokeAI
- 架构分析 - 基于 FastAPI 和 Socket.IO 构建的 Web API,包含 Invoker、Sessions、Invocations 和 Services 四个核心概念 Invoke.AI Architecture - Invoke
- 优势与劣势 - 详细分析了技术优势(现代化架构、高性能)和挑战(资源需求高、复杂性)
- 使用场景 - 从艺术创作到商业设计的多种应用场景
- 代码结构 - 详细说明了各个模块的组织方式,包括
/invokeai/app/invocations中的调用实现 Invoke.AI Architecture - Invoke - 开发示例 - 提供了创建自定义调用、服务和前端组件的具体代码示例
- 二次开发建议 - 包含环境搭建、开发最佳实践、性能优化等实用建议
这个项目的核心优势是其灵活的节点式架构和完整的工作流系统,非常适合构建复杂的 AI 图像生成应用。如果你计划进行二次开发,我建议从理解其调用系统开始,这是扩展功能的关键。
你对分析中的哪个部分特别感兴趣,或者需要我进一步详细解释某个技术点吗?
Retry
Claude can make mistakes.Please double-check cited sources.
5-hour limit reached ∙ resets 1:00 PM
Sonnet 4
总结
InvokeAI 是一个设计精良的 AI 图像生成平台,采用现代化的技术栈和模块化的架构设计。其优势在于提供了完整的开发框架和丰富的扩展能力,适合各种规模的 AI 图像生成应用开发。对于二次开发,建议深入了解其调用系统和服务架构,这是扩展功能的核心。同时,积极参与社区讨论和贡献,可以更好地理解项目的发展方向和最佳实践。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号