

工业界实战之数据存储格式与精度 - 指南
数据存储
常见存储格式与精度
不会损失精度:二进制存储(npy, npz, pickle, HDF5, Feather, Arrow, Parquet 等)。
可能损失精度:文本格式存储(csv, json, txt),取决于导出时保留的小数位数。
必然损失精度:强制数据类型降级(float64 存成 float32/float16 等)。
不会有精度损失的情况
二进制格式存储(精确保留底层内存表示)
.npy/.npz(NumPy 格式).pkl(Python pickle)HDF5(
h5/hdf5,如果使用 float32/float64 存储)Feather / Arrow 格式
Parquet(数值类型不做额外转换时)
原因:这些格式会直接存储数据的二进制表示(比如 float64 的 IEEE 754 表示),只要读写时保持相同的数据类型,就不会有额外的精度损失。
可能有精度损失的情况
文本格式存储(需要数值 ↔ 字符串 转换)
.csv/.tsv/.txtJSON (
.json)XML
YAML
原因:
浮点数在写出时会被转成字符串(小数点后的位数有限,比如默认 6 位/15 位),再读入时再转回浮点数,可能丢失部分精度。
如果手动设置高精度输出(如
np.savetxt(..., fmt="%.18e")),损失可以忽略,但文件会更大。在使用map reduce时候,json不是一种特别好的保存方式
一定会有精度损失的情况
强制类型降级
float64 → float32 → float16
int64 → int32 → int16
无论什么存储格式,只要数据类型被降级,就会损失精度(小数位或数值范围)。
比如:np.float64(0.1234567890123456) 存成 float32 就会截断成 0.12345679。
二进制存储 vs 文本存储
二进制存储(比如
.npy、HDF5):
直接把这串字节(01000000 01001000 …)写到文件里,读出来完全一样,不丢精度。3.14存进去后实际上是:01000000 01001000 11110101 11000011这就是它的 二进制表示。文本存储(比如
.csv、.json):
会把3.14转成字符串"3.14",然后存入文件。
下次再读的时候,需要解析字符串"3.14"→ 转成浮点数 → 重新编码成二进制。
如果存的时候截断了,比如"3.140000",那读回来就不一定等于原值。
总结 “存储二进制表示”= 把数据在内存里的0/1 编码(字节序列)原封不动写到文件里,而不是转成人能看的字符串。
存储时间/读取时间/存储空间
【数据面试滑铁卢】Python数据常用存储格式(纯效率比对展示)_哔哩哔哩_bilibili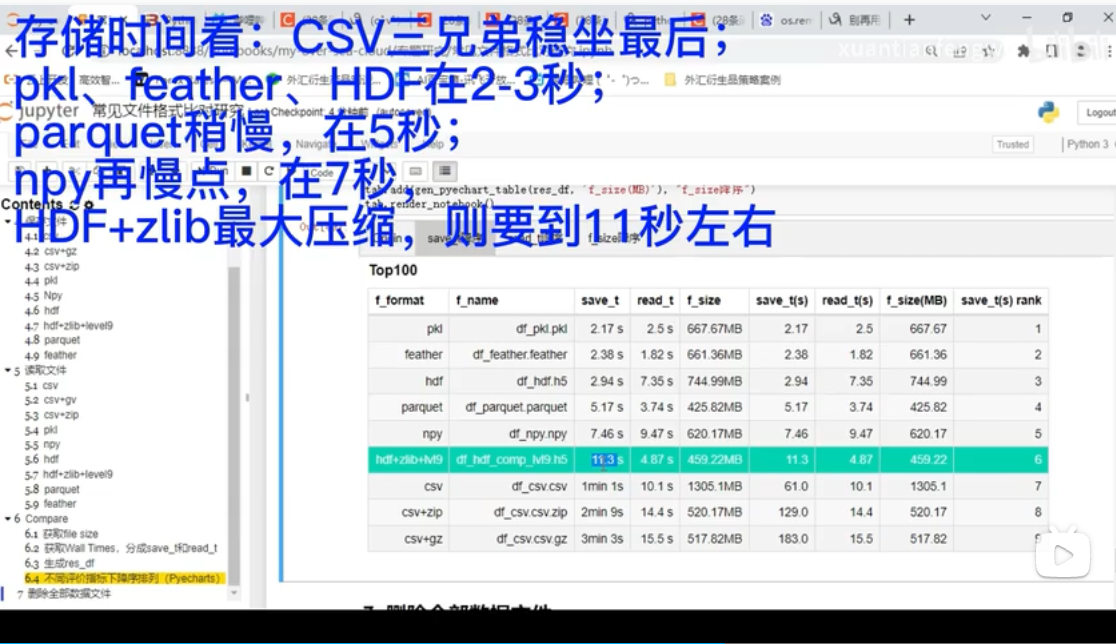
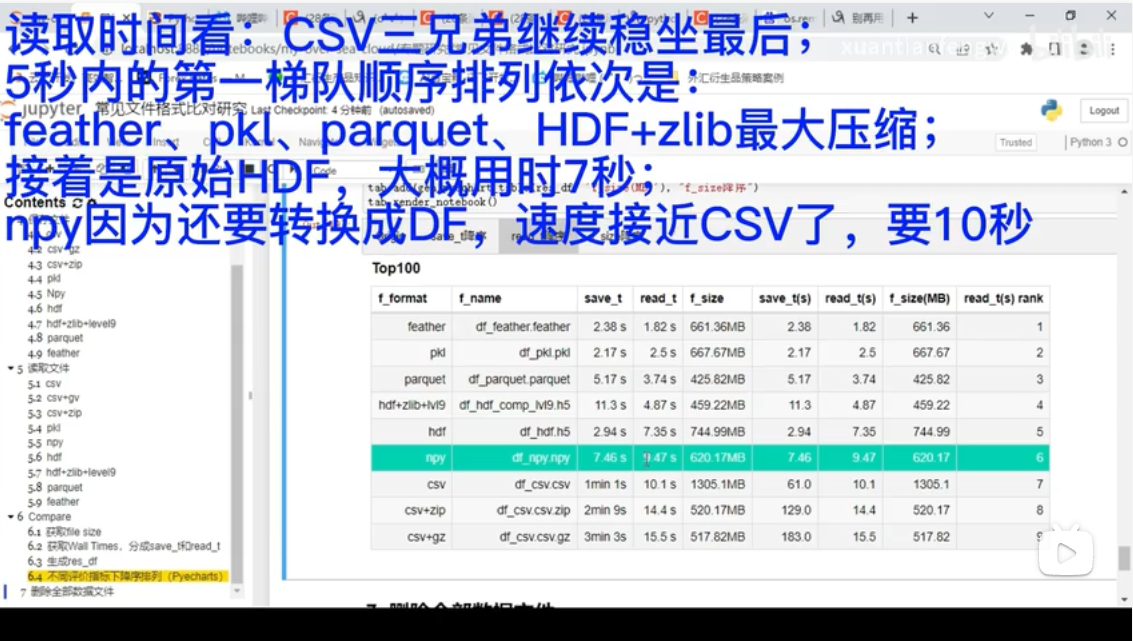
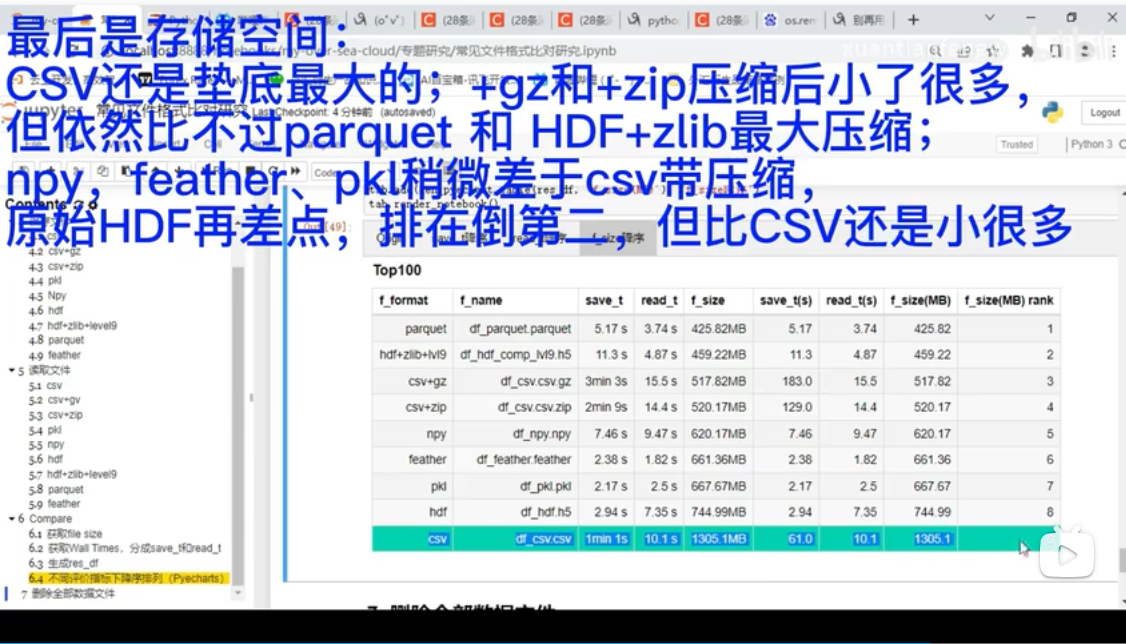
行存储和列存储

- 按行处理多→ 选择行连续存储
- 按列分析多→ 选择列连续存储
- 深度学习通常选择行连续:符合批量处理模式
- 注意框架默认:NumPy/PyTorch默认行连续,需要时进行转换
Pandas DataFrame默认使用行连续存储行连续的就是不管源文件是什么格式,转换为DataFrame后通常
Apache Arrow (Feather格式的底层) /Parquet使用列连续存储
csv/json是行存储
实际工程考虑
一般用feather/parquet/pickle都比较多 兼顾效率和精度
yaml格式用来存超参数 更有可读性
哪怕理论上float64精度最高,但在实践中:
- float32通常已足够:大多数深度学习框架默认使用float32
- 存储空间平衡:float64占用双倍空间
- 计算效率:GPU对float32优化更好
精度
1. float32 (单精度浮点数,FP32)
这是最常用的浮点数表示方式,符合IEEE 754 标准。
总位数:32 位
组成:
1 位符号位 (sign)
8 位指数位 (exponent)
23 位尾数位 (mantissa / significand)
优点:范围大、精度高,广泛用于数值计算、科学计算、传统训练。
缺点:存储和计算开销大,速度相对慢。
2. float16 (半精度浮点数,FP16)
为减少存储和加速计算而出现。
总位数:16 位
组成:
1 位符号位
5 位指数位
10 位尾数位
优点:
占用显存减少一半(相比 FP32)
运算速度快(尤其在 GPU 的 Tensor Core 上)
缺点:
范围和精度小于 FP32,容易出现溢出 (overflow) 或下溢 (underflow)
对数值稳定性要求较高(训练时常用混合精度训练:权重 FP32 存,计算用 FP16)
3. float8 (超低精度浮点数,FP8)
这是最新兴的格式,主要用于大模型训练 / 推理加速,NVIDIA Hopper 架构 (H100) 已帮助。
总位数:8 位
常见标准:
E4M3:4 位指数 + 3 位尾数
E5M2:5 位指数 + 2 位尾数
优点:
存储量仅 FP32 的 1/4,带宽和显存占用大幅下降
硬件上加速非常明显(矩阵乘法吞吐率翻倍)
缺点:
精度更低,表示范围有限
必须依赖缩放因子 (scaling factor)等技巧来保持数值稳定性
4. 三者之间的关系
FP32→ 精度最高,开销最大,用作“基准”。
FP16→ 精度折中,显存/速度提升 2 倍,常用于混合精度训练。
FP8→ 精度最低,但速度与存储优势最大,用于大模型分布式训练/推理。
常见用法是 分层混合精度:
训练中:权重和梯度可能保留 FP16/FP32,而激活值和部分计算用 FP8。
推理中:大部分用 FP8,关键部分用 FP16/FP32 保证准确度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号