
KDD2025 | FreRA:归纳频域三大优势,全局 + 独立 + 紧凑,时序分类、异常检测全拿捏! - 指南
本篇论文来自KDD2025第二轮,最新前沿时序技术,设计了一个FreRA方法,通过挖掘频域的全局、独立和紧凑特性,设计轻量级自动增强机制,在时间序列分类、异常检测和迁移学习任务中实现了卓越性能。
了解顶会最新技术,紧跟科研潮流,研究与写作才能保持在时代一线,全部73篇KDD2025(1+2轮)前沿时序合集小时已经整理好了,在功浩“时序大模型”发送“资料”扫码回复“KDD2025时序合集”即可自取~其他顶会时序合集也可以回复相关顶会名称自取哈~(AAAI25,ICLR25,ICML25等)
文章信息
论文名称:FreRA: A Frequency-Refined Augmentation for Contrastive Learning on Time Series Classification
论文作者:Tian Tian、Chunyan Miao、Hangwei Qian

研究背景
时间序列分类在活动识别、语音识别、工业监控等领域应用广泛,但依赖大量标注素材,而标注成本高且易出错。对比学习作为无监督表示学习的高效框架,其性能高度依赖数据增强策略。然而,现有方法存在明显缺陷:
时域增强多借鉴视觉领域方法,未适配时间序列特性,易扭曲语义信息。
频域增强或引入无关噪声,或依赖先验知识(如有效带宽),且缺乏普适性。
现有自动增强方法(如 InfoTS、AutoTCL)仍无法完全保留语义完整性,导致下游任务性能下降。
因此文章提出了频域优势与 FreRA 设计以解决上述问题。
模型框架
提出频域三大核心优势:
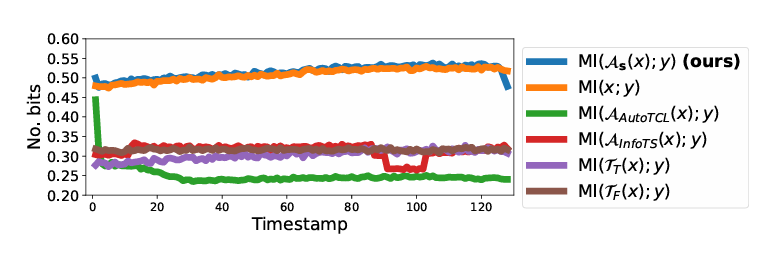
全局特性:每个频率分量通过离散傅里叶变换(DFT)编码全时间戳信息,天然承载全局语义,对分类任务至关重要。
独立特性:傅里叶基的正交性使频率分量相互独立,便于分离关键与非关键信息,避免修改干扰语义。
紧凑特性:基于帕塞瓦尔定理,信号能量在频域集中于少量分量,关键语义信息分布紧凑,降低信息丢失风险。
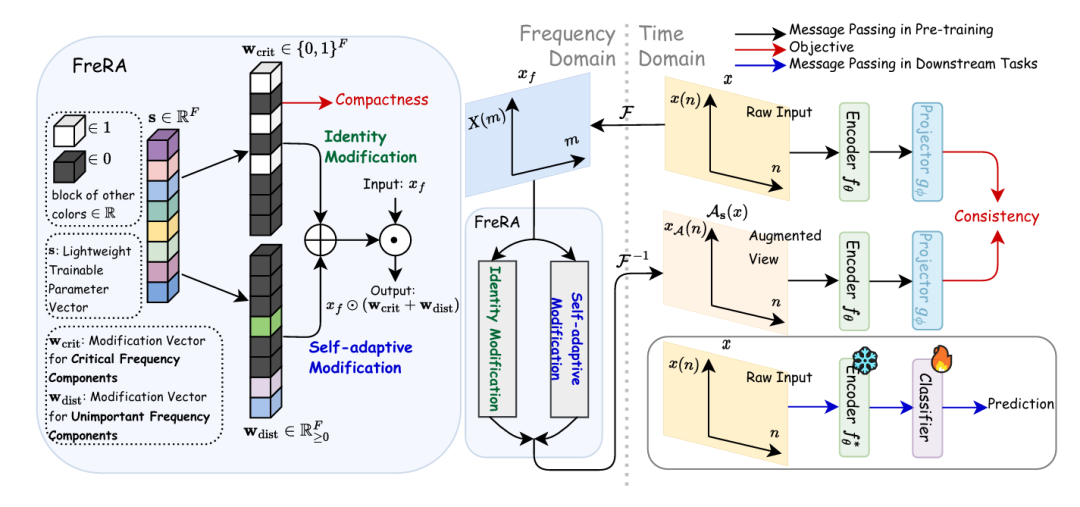
设计了FreRA方法:
FreRA核心思想:自适应精细化频率分量,借助轻量级可训练参数向量s捕捉频域语义分布,实现关键与非关键分量的分离与针对性修改。
有两大修改机制:
语义感知身份修改:通过 Gumbel-Softmax 重参数化生成二进制向量,保留关键频率分量的语义信息。
语义无关自适应修改:基于参数向量s的统计信息确定非关键分量,经过失真向量注入方差,且对应用停止梯度操作避免反向传播干扰。
优化目标:结合 InfoNCE 对比损失(拉近正样本对、推远负样本对)和L1 范数正则化(控制关键分量比例,避免冗余),搭建与对比学习框架的联合训练。
实验数据
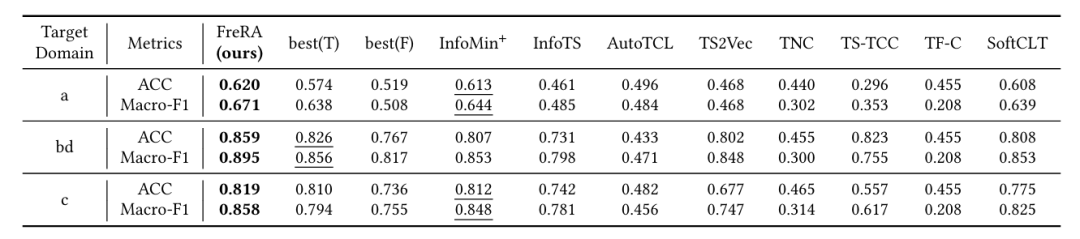
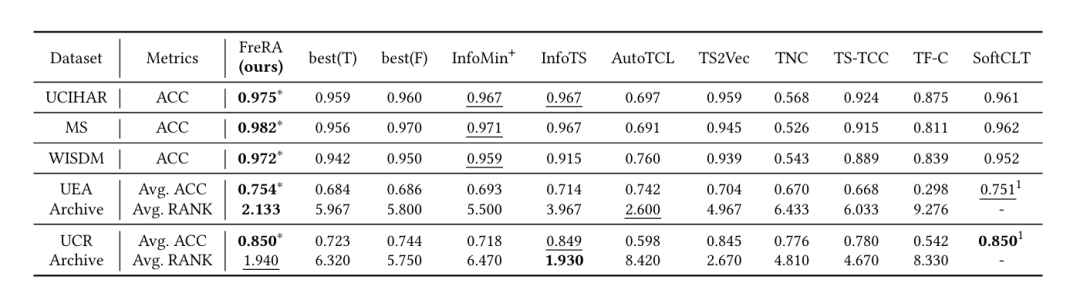
数据集:涵盖 135 个数据集,包括 UCR/UEA archive、3 个大型 HAR 信息集(UCIHAR、MS、WISDM)、异常检测数据集(FD)和迁移学习素材集(SHAR)。
基线:对比 10 类基线手段,包括 11 种时域增强、5 种频域增强、3 种自动增强(InfoMin、InfoTS、AutoTCL)和 5 种对比学习框架(TS2Vec、TNC 等)。
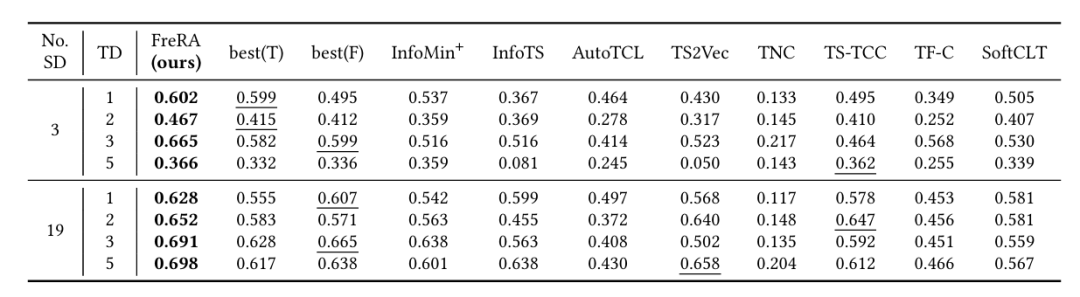
关键实验结果:
时间序列分类:在 UCIHAR、MS、WISDM 上准确率分别达 97.5%、98.2%、97.2%,显著优于基线;在 UEA(平均准确率 75.4%)和 UCR(平均准确率 85.0%)archive 上排名第一。
异常检测:在 FD 数据集的所有目标域中,准确率和 Macro-F1 分数均居首,验证了语义保留能力。
迁移学习:在 SHAR 数据集的低资源和高资源场景下,泛化性能优于所有基线,体现强鲁棒性。
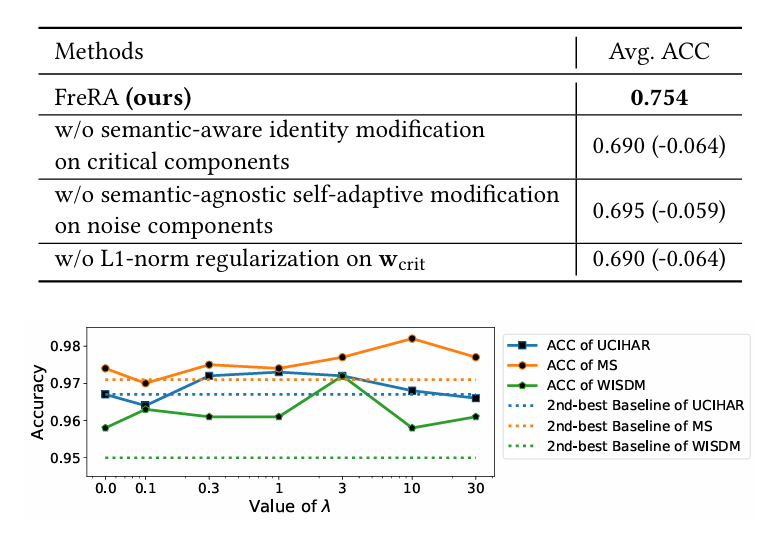
消融实验:移除身份修改、自适应修改或正则化组件后,平均准确率下降 5.9%-6.4%,证明各组件必要性。
灵活性与鲁棒性:可无缝集成到 TS2Vec、SimCLR、BYOL 等框架,且对超参数 λ 不敏感,性能稳定。

小小总结
FreRA通过挖掘频域的全局、独立和紧凑特性,设计轻量级自动增强机制,在时间序列分类、异常检测和迁移学习任务中实现了卓越性能。其即插即用特性和语义保留能力为时间序列无监督表示学习提供了有效解决方案。
2025顶会前沿时序合集,攻豪关注“时序大模型”,回复“资料”即可自取~

关注小时,持续学习前沿时序技术!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号