

多伦多大学跨形态融合具身导航!X-Nav:面向移动机器人的端到端跨形态导航学习方式

作者:Haitong Wang, Aaron Hao Tan, Angus Fung, Goldie Nejat
单位:多伦多大学机械与工业工程系
论文标题:X-Nav: Learning End-to-End Cross-Embodiment Navigation for Mobile Robots
论文链接:https://www.arxiv.org/pdf/2507.14731
任务主页:https://cross-embodiment-nav.github.io/

主要贡献
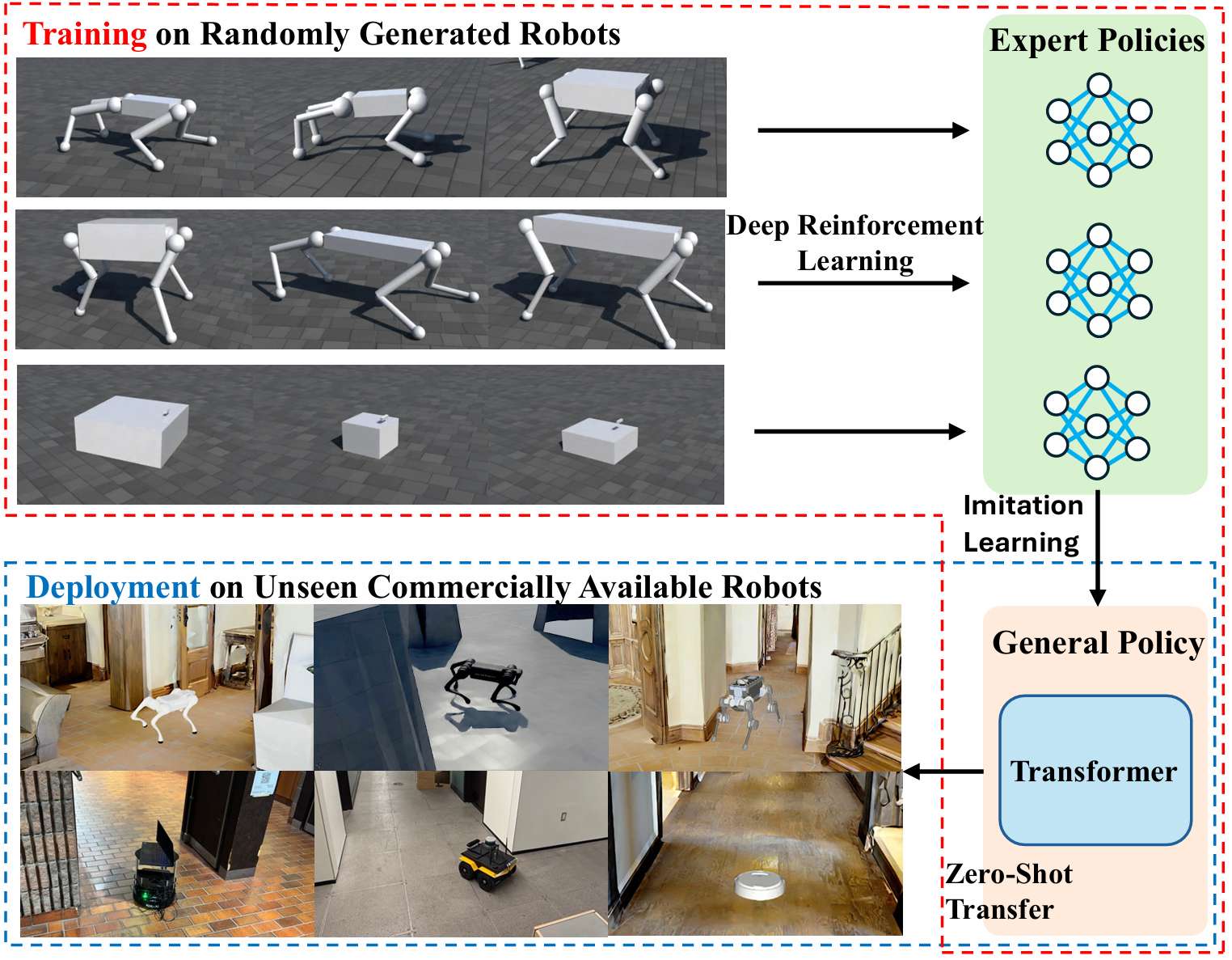
提出了端到端跨实体(cross-embodiment)导航框架X-Nav,能够训练出一个统一的策略,使其允许部署在多种不同类型的移动机器人(包括轮式和四足机器人)上,解决了现有导航方法依赖于特定机器人实体(embodiment)而导致泛化能力受限的问题。
设计了两阶段学习框架:第一阶段利用深度强化学习(DRL)在大量随机生成的机器人实体上训练多个专家策略;第二阶段利用导航动作分块(Nav-ACT)结合 Transformer 模型,将专家策略的知识蒸馏到一个通用导航策略中,该通用策略许可直接将视觉和本体感知观测映射到低级控制指令,实现对新机器人实体的零样本(zero-shot)泛化。
研究背景
移动机器人在多样化和复杂环境中执行任务(如人员搜索检测、未知环境探索等)时,导航能力至关重要。然而,现有的机器人导航方法大多依赖于特定机器人的运动学、动力学和传感器调整,导致这些方法难以泛化到具有不同形态属性的其他机器人上,限制了其在多种机器人平台上的通用性。
虽然已有研究尝试通过模仿学习(IL)或深度强化学习(DRL)来解决跨实体导航问题,但这些方法仍然依赖于实体特定的模块,如路径点跟踪控制器或动力学模型,需要针对每个机器人实体进行单独调整,并且在规划速度或跟踪路径点方面存在不足。
问题描述

目标:要求机器人从起始位置 ls 导航到目标位置 lg,在未知复杂环境中完成任务。
导航依据:机器人需要根据视觉观测(深度图像)、目标位置和本体感知观测(如 IMU 和电机编码器数据)来执行动作。
机器人类型:考虑轮式机器人和四足机器人,分别定义了它们的本体感知观测和动作空间。
导航目标:最小化从起始位置到目标位置的旅行距离。

X-Nav架构
X-Nav框架的目标是开发一个能够跨不同机器人形态(如轮式和四足机器人)通用的导航策略。该框架通过以下两个阶段实现:
阶段1:专家策略学习:运用深度强化学习(DRL)训练多个专家策略,每个专家策略针对一组特定的机器人形态。
阶段2:通用策略蒸馏:将专家策略的知识蒸馏到一个单一的通用策略中,该策略能够直接将视觉和本体感知观测映射到低级控制指令,从而实现对未见机器人形态的零样本(zero-shot)泛化。
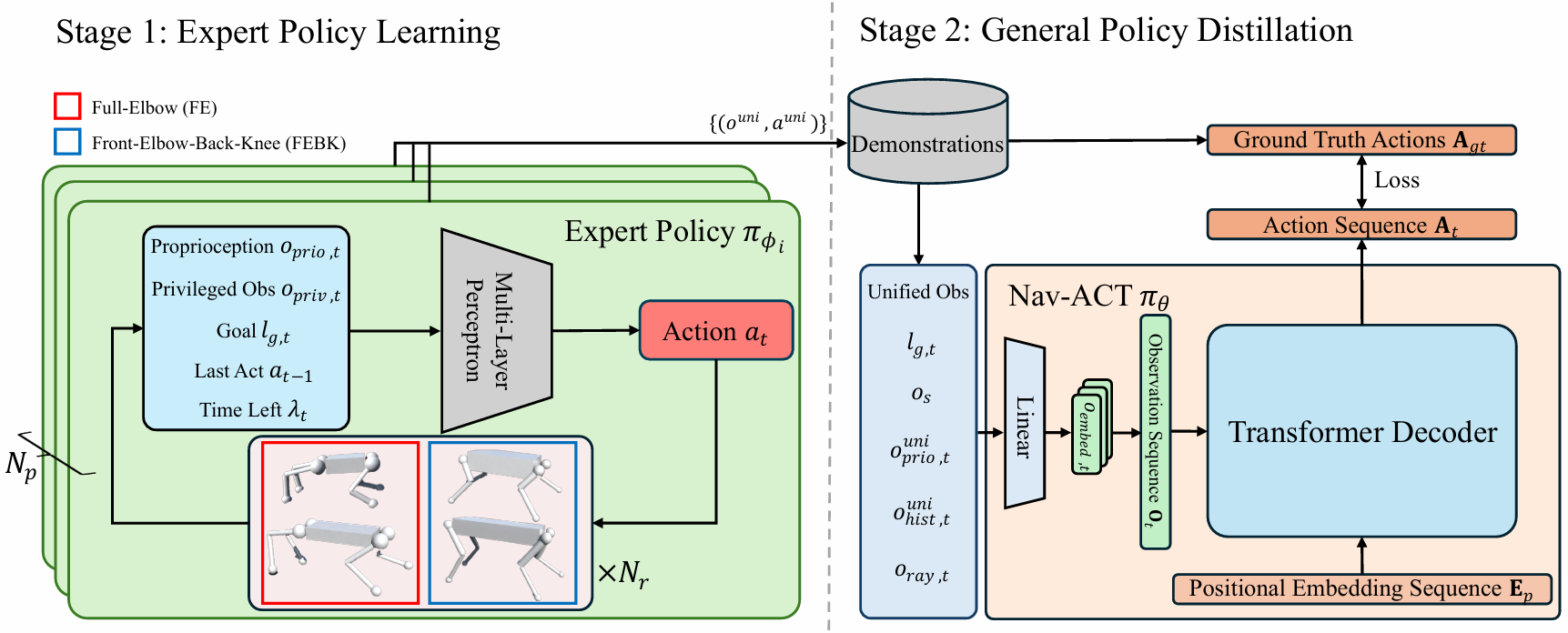
阶段1:专家策略学习
观测和动作空间
观测空间:每个时间步的观测包括上一时刻的动作、本体感知信息、目标位置、剩余时间、特权观测(如机器人形态参数和地面真实地形高度扫描)。
动作空间:对于轮式机器人,动作是线性和角速度的二维向量;对于四足机器人,动作是12个关节的目标位置。
形态随机化
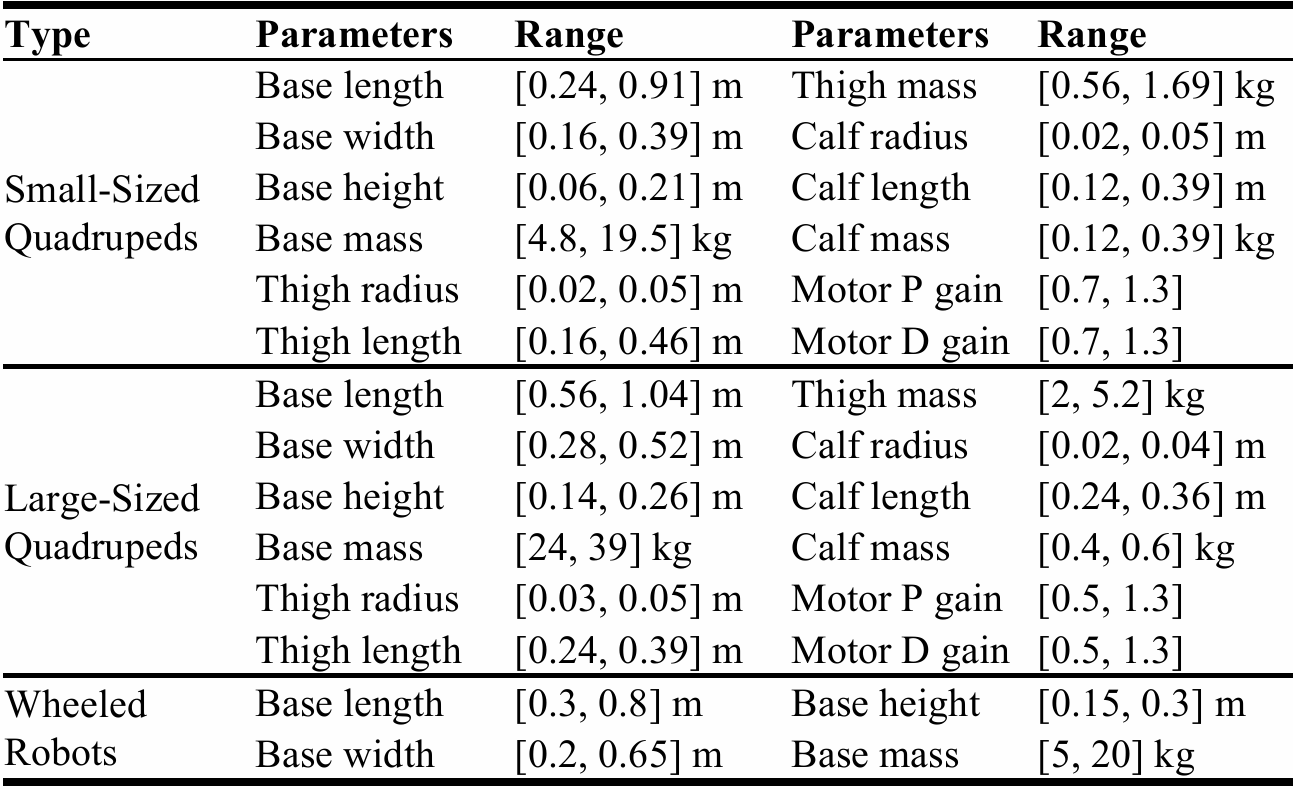
通过随机采样机器人形态参数(如质量、尺寸、关节参数等)生成多样化的机器人形态,确保训练中覆盖广泛的机器人类型。
对于四足机器人,还设计了模板来计算电机PD增益,以确保生成的机器人能够产生足够的力矩。
深度强化学习
使用近端策略优化(PPO)算法训练专家策略,因为其在学习机器人运动和导航方面具有稳定性和效率。
每个专家策略网络搭建为多层感知机(MLP),并进行大规模并行训练。
奖励函数

奖励函数包括任务奖励(如到达目标位置)和正则化奖励(如平滑运动、避免碰撞等)。
轮式机器人和四足机器人共享任务奖励,但正则化奖励不同。
课程学习
使用游戏启发式课程,从轻松到复杂逐步训练导航策略。
环境由多个子区域组成,每个子区域包含不同类型的障碍物(如盒子、金字塔、圆柱),难度级别由障碍物密度和尺寸决定。
根据机器人与目标的距离动态调整训练难度。
域随机化
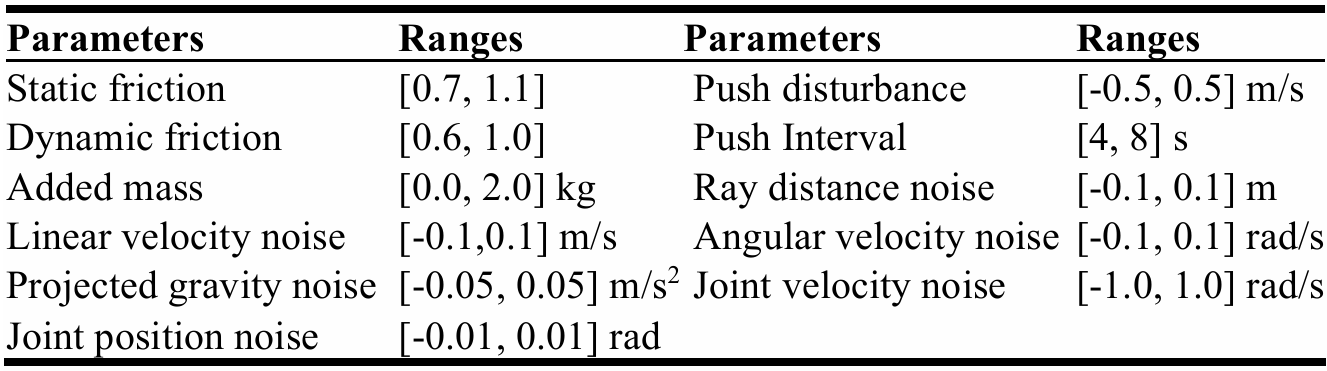
通过随机化摩擦系数、机器人质量、施加干扰力等,提高策略的鲁棒性,以便从仿真环境迁移到真实环境。
阶段2:通用策略蒸馏
统一观测和动作空间
定义统一的观测和动作空间,以便在不同机器人形态之间进行泛化。
统一观测包括目标位置、机器人尺寸、本体感知信息、历史动作和观测,以及从深度图像中提取的统一激光雷达扫描。
统一动作是一个14维向量,前两维表示轮式机器人的线速度和角速度,后12维表示四足机器人的关节目标位置。
演示收集
使用阶段1中训练的专家策略在随机生成的环境中收集演示数据。
每个演示包含一系列统一观测和动作,覆盖了训练中使用的全部机器人形态多样性。
Nav-ACT
引入Nav-ACT模型,利用Transformer架构将统一观测映射到动作序列。
Nav-ACT包含编码器和Transformer解码器,能够基于观测序列生成动作序列。
启用均方误差(MSE)损失函数进行训练。
推理
在推理阶段,对于轮式机器人,采用时间集成(TE)技能平滑动作,避免剧烈运动;对于四足机器人,直接使用动作序列中的第一个动作以适应动态变化。
策略训练
专家策略学习
设置:训练了3个专家策略,分别针对小型四足机器人(质量小于30kg)、大型四足机器人(质量大于30kg)和轮式机器人。每个类型生成了4096个机器人形态,用于训练和数据收集。
训练环境:整体训练环境由384个子区域组成,每个子区域涵盖随机生成的障碍物,地形复杂度逐步增加。
训练细节:使用NVIDIA RTX 4090 GPU进行训练,每个专家策略训练了4000个周期,使用Adam优化器,学习率为0.001。
通用策略蒸馏
设置:使用了5帧历史观测和动作,统一激光雷达扫描的视场角为90°,最小和最大射程分别为0.2米和8米,射线数量为128。
模型细节:Nav-ACT模型涵盖4层Transformer,每层有4个注意力头,嵌入大小为256,总参数量为485万。
训练细节:运用256的批量大小,学习率为0.0001,训练了100个周期,使用Adam优化器,权重衰减为0.001。
仿真实验
与SOTA方法的对比研究
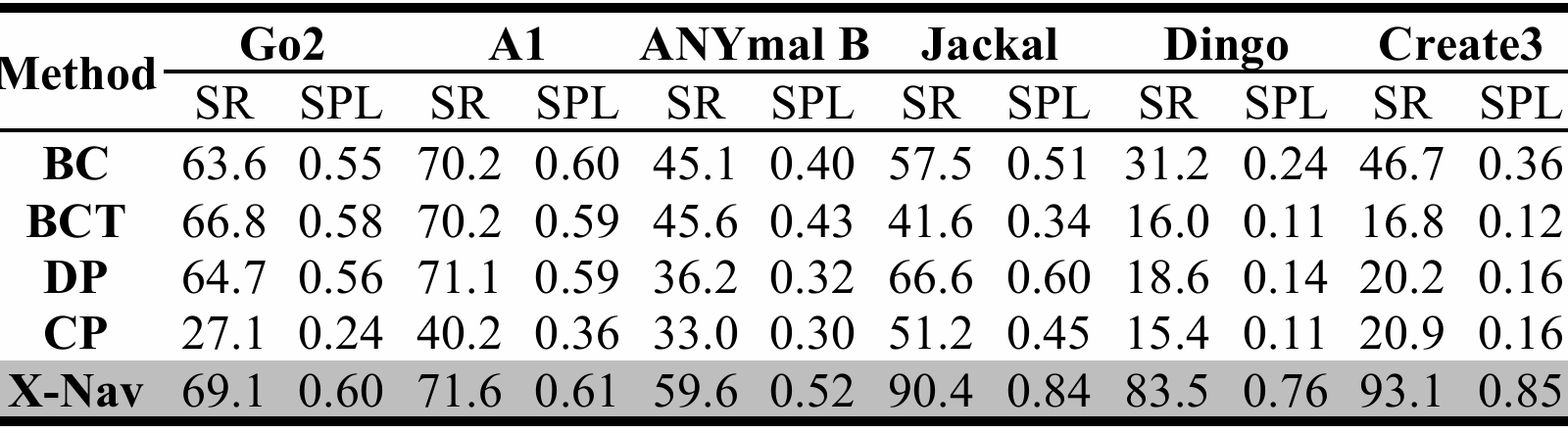
测试平台:采用了多种未参与训练的商业机器人平台,包括Clearpath Jackal、Clearpath Dingo、iRobot Create3(轮式机器人)和Unitree A1、Unitree Go2、ANYmal B(四足机器人)。
性能指标:使用成功率(SR)和归一化路径长度加权成功率(SPL)来评估导航性能。
结果:X-Nav在所有测试机器人上均取得了最高的SR和SPL,显著优于其他四种SOTA方法(如行为克隆BC、基于Transformer的行为克隆BCT、扩散策略DP和一致性策略CP)。

可扩展性研究
目标:验证X-Nav在训练时采用更多随机生成机器人形态时性能是否提升。
测试配置:分别使用128、1024和4096个随机生成的机器人形态进行训练和数据收集。
测试环境:使用Matterport3D(MP3D)数据集中的真实室内环境进行测试。
结果:随着训练中使用的随机机器人形态数量增加,X-Nav的SR和SPL显著提升,表明其能够更好地泛化到未见的机器人形态和环境。
消融研究
目的:验证X-Nav设计选择(如损失函数、推理策略)对性能的影响。
- 变体:
X-Nav with L1 Loss(使用L1损失训练)
X-Nav with Executing Chunk(执行完整动作块后再预测下一个动作块)
X-Nav without Temporal Ensemble(不使用时间集成TE)
X-Nav with Temporal Ensemble(对轮式和四足机器人均使用TE)
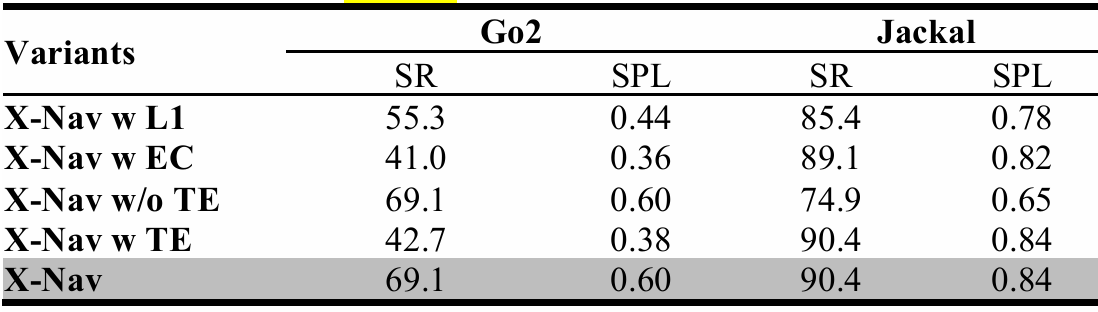
结果:标准X-Nav在所有变体中表现最佳。L1损失导致动作预测不够精确;执行完整动作块会延迟机器人对动态变化的适应;时间集成对轮式机器人有益,但对四足机器人响应速度有负面影响。
真实世界实验
测试环境:在室内(走廊、门厅、通道)和室外(公园,不平坦地形)环境中进行测试。
测试平台:使用TurtleBot2(配备Kinect传感器)和Clearpath Jackal(配备ZED 2立体相机)两种不同的轮式机器人。
结果:X-Nav在真实环境中实现了85%的成功率和0.79的SPL,展示了其在不同机器人形态、传感器配置和环境中的零样本迁移能力。
结论与未来工作
- 结论:
论文提出的 X-Nav 框架依据两个阶段的学习,成功达成了跨实体导航,能够在多种机器人实体上进行零样本泛化,并在模拟和真实世界环境中表现出良好的导航性能。
- 未来工作:
未来工作将扩展 X-Nav 至更多机器人类型(如人形机器人)和目标导航任务,以进一步拓展其适用范围。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号