

ComfyUI进阶:AnimateAnyone-Evolved图片跳舞全流程,静态人像动态化技术解析 - 指南
将静态图片中的人物转化为流畅跳舞的动态视频,是AI视觉创作中兼具技术难度与创意价值的方向。ComfyUI通过ComfyUI-AnimateAnyone-Evolved插件,结合多模态模型与姿态迁移算法,实现了"人物特征保留+动作自然迁移"的双重突破。本文将从应用场景、技术架构、节点参数到实战案例,全面解析这一工作流,帮助进阶用户掌握静态图像动态化的核心技术。
一、图片跳舞技术的应用场景与核心价值
图片跳舞技术并非简单的"动作叠加",而是通过AI理解人物结构与动作规律,在保留原图服装、发型、表情等特征的同时,赋予符合物理逻辑的舞蹈动作。其核心价值体现在:
(一)典型应用场景
| 应用场景 | 传统解决方案痛点 | AnimateAnyone-Evolved优势 |
|---|---|---|
| 虚拟偶像内容生产 | 3D建模+动作捕捉成本高(单角色投入超10万元) | 静态插画生成动态舞蹈视频,成本降低90% |
| 电商服装展示 | 实拍模特视频需频繁更换服装,周期长 | 静态服装图生成多角度跳舞视频,快速迭代款式 |
| 社交媒体创意内容 | 短视频同质化严重,静态图片互动率低 | 头像/插画跳热门舞蹈,提升内容辨识度与转发率 |
| 教育动画制作 | 传统手绘动画效率低,难以适配个性化需求 | 教材人物图片生成跳舞教学视频,增强趣味性 |
(二)技能突破点
与早期"图片动起来"的方案(如基于AnimateDiff的容易动作迁移)相比,AnimateAnyone-Evolved的核心突破在于:
| 技术维度 | 早期方案缺陷 | AnimateAnyone-Evolved解决方案 |
|---|---|---|
| 人物一致性 | 动作迁移中易出现面部扭曲、服装变形 | 基于CLIP视觉特征锁定人物身份,帧间特征一致性达95%+ |
| 动作流畅度 | 关节运动生硬,易出现"木偶感" | 引入3D姿态预测模型,模拟真实人体运动学规律 |
| 风格兼容性 | 仅支持写实风格,动漫/插画适配差 | 兼容SD全系列模型,利用LoRA扩展至任意风格 |
| 细节保留 | 毛发、饰品等细节易丢失 | 多尺度特征融合网络,保留1px级细节(如项链、纽扣) |
二、ComfyUI-AnimateAnyone-Evolved插件配置与模型准备
该插件依赖多模态模型协同工作,需严格按照路径配置,否则会出现"模型加载失败"或"生成乱码"等问题。
(一)插件下载与安装
插件安装(二选一):
- Manager安装(推荐):
打开ComfyUI → 点击Manager→Available标签 → 搜索AnimateAnyone-Evolved→ 点击Install,自动安装依赖。 - 手动安装:
cd custom_nodes git clone https://github.com/MrForExample/ComfyUI-AnimateAnyone-Evolved.git # 替换为官方仓库地址 cd ComfyUI-AnimateAnyone-Evolved pip install -r requirements.txt
- Manager安装(推荐):
依赖检查:
需确保环境中安装torch>=2.1.0、diffusers>=0.26.3、opencv-python>=4.8.1,可通过pip list | grep 库名验证,版本不符时用pip install --upgrade 库名更新。
(二)核心模型下载与放置
| 模型类型 | 下载地址 | 关键文件 | 放置路径 | 核心作用 |
|---|---|---|---|---|
| VAE | hf-mirror.com/stabilityai/sd-vae-ft-mse | diffusion_pytorch_model.bin | models/vae/ | 优化图像色彩与细节解码 |
| 稳定扩散UNet | hf-mirror.com/lambdalabs/sd-image-variations-diffusers | unet/diffusion_pytorch_model.bin | models/unet/ | 提供图像生成基础能力 |
| CLIP Vision | hf-mirror.com/lambdalabs/sd-image-variations-diffusers | clip_vision_model.bin | models/clip_vision/ | 提取静态图像特征,锁定人物身份 |
| AnimateAnyone预训练模型 | hf-mirror.com/patrolli/AnimateAnyone | denoising_unet.pth、motion_module.pth、pose_guider.pth、reference_unet.pth | models/animate_anyone/ | 核心动作迁移模型,处理姿态与特征融合 |
注意:预训练模型总大小约12GB,建议使用迅雷等工具断点续传;国内用户经过hf-mirror加速时,需确保文件完整性(校验MD5值)。
三、图片跳舞工作流创建:节点架构与参数详解
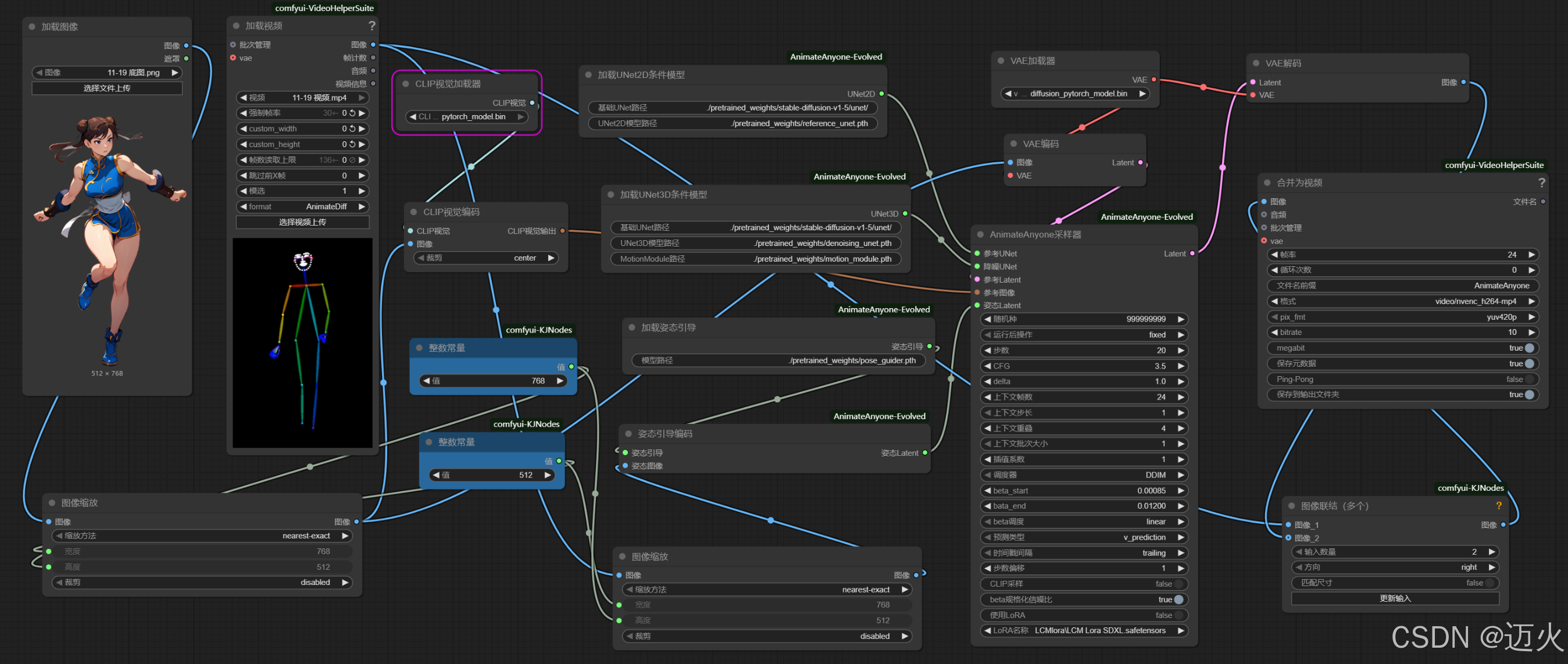
AnimateAnyone-Evolved工作流通过"特征锁定→姿态解析→动态融合→视频生成"四阶段处理,实现静态图片到跳舞视频的转化。核心节点包括10+关键组件,需严格按依赖关系连接。
(一)工作流架构
(二)核心节点参数解析
1. 输入处理节点
Load Image:
Image Path:静态人像路径(建议分辨率512×768,全身照,正面视角)Resize Mode:Crop and Resize(保留人物主体,裁除冗余背景)Output Size:(512, 768)(与参考视频宽高比一致,避免拉伸)注职:加载的图片凡寸必须与加载的视频尺寸相同,否则运行时会报错
Load Video (参考舞蹈):
Video Path:舞蹈视频路径(建议10-20秒,单人舞蹈,动作清晰)Frame Rate:24fps(平衡流畅度与计算量)Max Frames:300(超过300帧建议分段处理,避免OOM)
2. 特征与姿态节点
CLIP Vision Encoder:
Model Path:指向clip_vision_model.bin
Pose Sequence Encoder:
Smooth Factor:0.2-0.3(平滑姿态序列,减少参考视频的抖动)Pose Weight:0.8(控制参考姿态对生成结果的影响强度)
3. 生成核心节点
AnimateAnyone Sampler(核心生成节点):
Steps:25-30(动态生成需比静态图多5-10步,确保帧间一致性)CFG Scale:7.0-7.5(过高易导致"过度拟合姿态",丢失人像特征)Denoising Strength:0.8(平衡动态生成与特征保留)Motion Consistency:0.7(帧间动态一致性权重,降低闪烁)
Load UNet2D/UNet3D:
UNet2D Path:指向unet/diffusion_pytorch_model.bin(负责空间细节)UNet3D Path:指向动态模型(负责时序连贯性)Weight Ratio (2D:3D):6:4(空间细节优先,兼顾动态流畅)
4. 输出节点
- Video Merger:
Codec:libx264(通用编码,兼容性强)Bitrate:10000kbps(512×768分辨率的最佳画质/体积比)Audio Path(可选):添加背景音乐(需与视频时长匹配)
(三)参数调优原则
| 场景 | 核心参数调整 | 效果目标 |
|---|---|---|
| 动漫风格 | CLIP Feature Strength=0.85,CFG Scale=6.5 | 降低特征强度,避免过度写实破坏动漫感 |
| 写实风格 | CLIP Feature Strength=1.0,Motion Consistency=0.8 | 强化特征锁定与动态一致性,提升真实感 |
| 快速预览 | Steps=20,Max Frames=100 | 牺牲部分细节,缩短生成时间(适合参数调试) |
| 高清输出 | Steps=30,Output Size=1024×1536 | 配合ESRGAN放大,提升细节丰富度 |
四、实战案例:二次元人物跳舞蹈
以"将二次元人物转化为跳舞蹈的视频"为例,详解完整操作步骤与效果优化。
(一)素材准备
| 素材类型 | 规格要求 | 示例描述 |
|---|---|---|
| 静态图片 | 512×768px,PNG格式,透明背景 | 二次元女性角色,双马尾,JK制服,正面全身 |
| 参考视频 | 15秒,24fps,1080p,单人正面舞蹈 | 女团舞蹈片段,动作包含手臂摆动、脚步移动 |
(二)关键参数配置
特征锁定优化:
CLIP Vision Encoder:Feature Strength=0.9,Face Attention=0.95(强化二次元面部特征)
姿态迁移控制:
Pose Weight=0.75(避免舞蹈动作过大导致角色变形)Smooth Factor=0.25(平滑参考视频中的快速动作,适配二次元风格)
生成参数:
Steps=20,CFG Scale=3.5
(三)效果优化与问题处理
| 问题现象 | 技术原因 | 解决方案 |
|---|---|---|
| 角色面部闪烁 | 帧间面部特征匹配失败 | 启用Face Stabilizer节点,Stability=0.8 |
| 服装纹理丢失 | UNet2D权重不足 | 提高UNet2D权重至70%,Denoising Strength=0.78 |
| 动作卡顿 | 参考视频帧率低或姿态编码不足 | 参考视频提至30fps,Pose Sequence Encoder步数增至50 |
| 背景穿透人物 | 人像分割不彻底 | 前置Image Masker节点,用SAM生成人物蒙版 |
(四)输出效果
ComfyUI-AnimateAnyone-Evolved
五、进阶技巧与扩展应用
(一)风格迁移扩展
多风格适配:
- 写实转卡通:加载
Toonify LoRA,权重0.6,CFG Scale降至6.5 - 油画风格:添加
Oil Painting LoRA,配合VAE调整色域
- 写实转卡通:加载
角色特征微调:
- 表情控制:在
CLIP Encoder后添加Expression Controller,锁定微笑表情 - 服装变体:用
Inpaint节点替换部分服装元素(如将JK制服改为连衣裙)
- 表情控制:在
(二)性能优化策略
显存占用控制:
- 12GB显存:限制
Max Frames=200,Output Size=512×768 - 24GB显存:可并行处理2组视频,启用
Batch Processing节点
- 12GB显存:限制
生成速度提升:
- 启用
TensorRT加速:UNet推理速度提升2倍(需安装对应插件) - 降低
Steps至20,配合Fast Sampler(如DPM++ 3M SDE)
- 启用
(三)商业级应用扩展
虚拟偶像直播:
- 工作流+OBS推流:实时将静态头像转为跳舞虚拟形象
- 关键:用
Low Latency Mode,牺牲部分细节换取500ms内延迟
批量内容生产:
- 用
Loop Controller节点,为10+静态图应用同一舞蹈动作 - 配合
Metadata Writer,自动添加水印与版权信息
- 用
总结
ComfyUI-AnimateAnyone-Evolved插件通过多模态模型协同,突破了静态图像动态化的核心瓶颈,使"图片跳舞"从创意概念变为可落地的技术方案。其核心价值在于:
- 特征锁定精度:CLIP视觉编码实现95%+的人物一致性
- 动作自然度:3D姿态模型+时序编码,模拟真实人体运动规律
- 风格扩展性:兼容SD全生态模型/LoRA,适配任意创作风格
进阶用户需重点掌握:
- 特征强度与姿态权重的平衡调节(核心矛盾点)
- 帧间一致性优化技巧(闪烁控制是关键)
- 不同风格下的参数适配逻辑
随着模型迭代,未来该技术将支持多人互动舞蹈、复杂场景融合等高级功能。掌握本文工作流,你将能飞快将静态素材转化为动态内容,为虚拟偶像、电商营销、创意短视频等领域提供技术支撑。
若本文对你有帮助,欢迎点赞收藏,评论区可分享你的实践案例或技术疑问!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号