

本文介绍常见的激活函数及python实现。如identity, sigmoid, tanh,ReLU ,Leaky ReLU,Swish等函数。 - 详解
3.激活函数
有很多激活函数处理神经元的输出。激活函数
![]() 应该是什么呢?答案是,不重要。当然不完全是真的。明显还是有点重要, 只不过没有你想象的那么重要。几乎任何形式的函数(单调的,平滑的)就行。多年来试过许多不同的函数。尽管一些比另一些工作得更好,但是都能得到想要的结果。记住:激活函数只不过是数学函数用来转换z到输出yˆ 。我们看一下最常用的。
应该是什么呢?答案是,不重要。当然不完全是真的。明显还是有点重要, 只不过没有你想象的那么重要。几乎任何形式的函数(单调的,平滑的)就行。多年来试过许多不同的函数。尽管一些比另一些工作得更好,但是都能得到想要的结果。记住:激活函数只不过是数学函数用来转换z到输出yˆ 。我们看一下最常用的。
Identity函数
这是你许可使用的最基本的函数。通常它记为I(z).它不变的返回输入值。数学上我们有
f (z ) = I (z ) = z
这个简单的函数在讨论线性回归时派上用场。图3-6是它看起来的样子.

用Python的numpy实现identity函数很简单.
#List3-3
def identity(z):return z
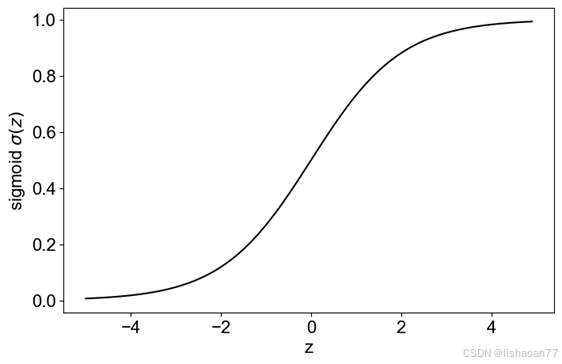
Sigmoid函数
这是返回0 到1之间的值的最常用的函数。它记为σ(z).

它特别的用于必须预测概率作为输出的模型(记住概率只能取0 到1之间的值).在图3-7你看它的形状。注意在Python里,如果z足够大,测返回0或 1 (取决于z的符号) 以舍入误差。在分类问题里,我们经常计算logσ(z) 或log(1 − σ(z)) ,因此这可能是Python里误差的来源,因这它试图计算log 0,没有定义的就是而这.例如,你可能开始看到出现nan当计算损失函数时(详见后面).我们在后面会看到这种现像的例子。

图3-7. sigmoid激活函数是s-形的函数,取值从0到1
注意虽然σ(z)不会超过0 或1, 但是在Python编程里,现实很不同.缘于非常大的z (正或负), Python可能修约结果为0或1.这会给你错误当你为分类计算损失函数时(后面给你解释和例子) ,因为我们需要计算log σ(z) 和log(1 − σ(z)) ,因此, Python试图计算log0, 而这是没有定义的.这可能出现,例如,如果你不归一化输入数据,或者你不正确的初始化权重.现在,重要的是要记住尽管数学上所有的东西好像都受控,但是实现的编程可能很困难。记住调试模型时,损失函数可能会得到nan.
z的行为可以见图3-7。计算可以用numpy函数这样写:
#List3-4
s = np.divide(1.0, np.add(1.0, np.exp(-z)))
注意我们有两个就是非常有用的是知道若numpy数组, A 和B, 下面是相等的: A/B 等于np.divide(A,B), A+B等于np.add(A,B), A-B 等于np.subtract(A,B), A*B等于np.multiply(A,B).若是你熟悉面向对象编程,我们说在numpy里,基本的操作如/, *, +,和-,都是重载的。也要注意所有这四个numpy操作都是元素级的。
我们可以更可读的形式写sigmoid函数(最起码对人类可读) 如下:
#List3-5
def sigmoid(z):
s = 1.0 / (1.0 + np.exp(-z))return s
如我们前面所述, 1.0 + np.exp(-z)等于np.add(1.0, np.exp(-z)),和1.0 / (np.add(1.0, np.exp(-z)))等于np.divide(1.0, np.add(1.0, np.exp(-z))).
我想让你注意公式的另一点。np.exp(-z)有z的维(通常是向量它的长度等于观察数),而1.0是标量(一维实体). Python如何加它们呢?这称为广播。Python里,对像受一定的约束,将广播更小的数组(本例是1.0) 到更大的数组里,以便最后两者有相同的维。本例中, 1.0成为与z有相同维的数组,所有元素数填充为1.0。这是要理解的要紧的概念,它很有用。例如,你不用在数组里变换数值。Python会为你考虑。其它情况的广播很复杂超出了本书的范围。但是重要的是要知道Python在后台做一些事情。
Tanh (Hyperbolic Tangent Activation)激活函数
hyperbolic tangent也是s-shaped曲线取值为 -1到1。
f (z ) = tanh(z )
在图3-8, 你可以看到它的形状。在Python里,可以很容易的实现,如下:
#List3-6
def tanh(z):
return np.tanh(z)

图3-8. tanh (或hyperbolic function)是s-形曲线取值从-1 到1
ReLU (Rectified Linear Unit)激活函数
ReLU激活函数(图3-9)有下面的公式:
f (z ) = max (0,z )

花一些时间来探索如何用Python聪明的构建ReLU 函数是值得的。注意,当我们开始利用TensorFlow时,它已经为我们构建了。但是观察不同的 Python实现的区别是很有指导意义的,当实现繁琐的深度学习模型时。
在Python里,你可以用多个方法达成ReLU函数。下面列出4种。(请先理解它们如何工作。)
- np.maximum(x, 0, x)
- np.maximum(x, 0)
3.x * (x > 0)
4.(abs(x)+ x) / 2
这4种方法有不同的执行速度。我们来产生108个元素的numpy数组, 如下:
x = np.random.random(10**8)
现在我们来测试一下4种版本的ReLU函数到它时所需要的时间。运行下面的代码:
#List3-7
x = np.random.random(10**8)print("Method 1:")
%timeit -n10 np.maximum(x, 0, x)
print("Method 2:")
%timeit -n10 np.maximum(x, 0)
print("Method 3:")
%timeit -n10 x * (x > 0)
print("Method 4:")
%timeit -n10 (abs(x)+ x) / 2
The results follow:
Method 1:
2.66 ms ± 500μs per loop (mean ±std. dev. of 7 runs, 10 loops each)Method2:
6.35 ms ± 836μs per loop (mean ±std. dev. of 7 runs, 10 loops each)Method3:
4.37 ms ± 780μs per loop (mean ±std. dev. of 7 runs, 10 loops each)Method4:
- ms ± 784μs per loop (mean ±std. dev. of 7runs, 10 loops each)
区别很明显。方法1 的速度为方法4的4倍。numpy 高度优化的,很多例程用就是库C语言写的。不过如保有效的编程仍然会有区别并有很大的影响。为什么np.maximum(x, 0, x)要比np.maximum(x, 0)快呢?第一个版本在原位更新x, 通过不用创建新的数组。这能够节省很多时间,特别是当数组很大时。如果你不想(或不能)原位更新输入向量, 你仍然要以采用np.maximum(x, 0)版本。
一个建立看起来这样:
#List3-8
def relu(z):
return np.maximum(z, 0)
注意记住:当优化你的代码时,即便是小的变更都可能会有很大的不同。在深度学习紡程里,相同的代码块可能重复上百成次或上亿次,所以即便是小的改进对长时间运行都会有大的影响。花时间优化你的代码是值得的.
Leaky ReLU
Leaky ReLU (也称为parametric rectified linear unit)公式如下

其中α 是一个参数特别是有0.01阶.在图3-10,你可以看到α = 0.05的例子。这个值使x > 0和x < 0的区别更明显。通常,应用小的α,但是测试你的模型得找到最佳值。

图3-10. Leaky ℝeLU激活函数使用α = 0.05
在Python里,你可以这样完成,若是relu(z)函数已经定义:
#List3-9
def lrelu(z, alpha):
return relu(z) - alpha * relu(-z)
Swish激活函数
最近, Ramachandran, Zopf,和Le在Google Brain研究新的激活函数,称为Swish, 在深度学习领域有很大的作用。它的定义是
f (z ) = zs (b z )
其中β 是可学习参数.在图3-11,你可以看到这个激活函数找3个参数β: 0.1, 0.5,和10.0. 这个团队的研究表明,容易的用Swish替代ReLU 可以改进ImageNet的准确率0.9%. 在今天的深度学习领域,那是很大的值。你可能在ImageNet找到更多信息www.image-net.org/.

ImageNet是大的图像数据库,通常用来标杆新的网络架构或算法,例如使用不同激活函数的网络。
其它激活函数
还有很多别的激活函数,可是很少用。作为参考,下面的额外的一些。列表是很全但只让你知道在开发神经网络时还有很多激活函数可用。
- ArcTan
f (z ) = tan-1z
- Exponential Linear unit (ELU)

Softplus
![]()
我们前面介绍了非线性函数σ 为 sigmoidal函数。尽管sigmoidal是全连接网络经典的非线性函数,近年来研究者发现了别的激活函数,有名的rectified linear激活函数(常缩写为 ReLU 或 relu) σ (x) = max( x, 0)比sigmoidal工作得更好。这种经验观察是基于深度网络的vanishing gradient 难题,对于 sigmoidal 函数,几乎所有输入的斜率为零,结果,更深的网络,梯度为零。对于 ReLU函数,对于更多的输入空间斜率不为零,允许非零的梯度传播。图3-12说明sigmoidal和ReLU 激活函数。

图 3-12. Sigmoidal 和 ReLU 激活函数.
最常见的激活函数可能是rectified linear unit(ReLU),
![]() = max( 0, x)。要是你不能确定启用哪个函数,这个可能是黙认最好的。其它常见的选择是hyperbolic tangent, tanh(x) , 以及logistic sigmoid,
= max( 0, x)。要是你不能确定启用哪个函数,这个可能是黙认最好的。其它常见的选择是hyperbolic tangent, tanh(x) , 以及logistic sigmoid,
![]() = 1/ (1 + e−x)。这些函数如图3-13所示。
= 1/ (1 + e−x)。这些函数如图3-13所示。

图 3-13. 三个常见的激活函数: the rectified linear unit, hyperbolic tangent,
和logistic sigmoid.
注意 实践者老是使用两个激活函数: sigmoid和 relu ( relu可能是最常见的). 用这两者,你都可以获得很好的结果,并得到足够艰难的网络架构,都可以逼近任何非线性函数。记住使用tensorflow时,你不用自己实现函数。 tensorflow 已经为你提供了高效的实现。但是知道每个函数的行为以理解什么时候使用它们是重要的。
#List3-10
Numpy版本的激活函数
import numpy as np
import random
import matplotlib.pyplot as plt
import matplotlib as mpl
绘图函数
def myplot(x,y, name, xlab, ylab):
plt.rc('font', family='arial')
plt.rc('xtick', labelsize='x-small')
plt.rc('ytick', labelsize='x-small')
plt.tight_layout()
fig = plt.figure(figsize=(8, 5))
ax = fig.add_subplot(1, 1, 1)
plt.tick_params(labelsize=16)
ax.plot(x, y, ls='solid', color = 'black')
ax.set_xlabel(xlab, fontsize = 16)
ax.set_ylabel(ylab, fontsize = 16)
绘制激活函数 创建数组 开始创建用于绘制不同的激活函数的数据
x = np.arange(-5,5,0.1)
identity = x
sigmoid = 1.0 / (1.0 + np.exp(-x))
arctan = np.tanh(x)
relu = np.maximum(x, 0)
leakyrelu = relu - 0.05 * np.maximum(-x, 0)
Identity激活函数
myplot(x, identity, 'Figure_1-4', 'z', 'Identity $I(z)$')

Sigmoid激活函数
myplot(x, sigmoid, 'Figure_1-5', 'z', 'sigmoid $\sigma(z)$')
tanh激活函数
myplot(x, arctan, 'Figure_1-6', 'z', r'Hyperbolic Tangent $\tanh(z)$')

ReLU激活函数
myplot(x, relu, 'Figure_1-7', 'z', 'ReLU')

Leaky ReLU激活函数
myplot(x, leakyrelu, 'Figure_1-8', 'z', 'Leaky ReLU')

SWISH激活函数
swish1 = x / (1.0 + np.exp(-0.1*x))
swish2 = x / (1.0 + np.exp(-0.5*x))
swish3 = x / (1.0 + np.exp(-10.0*x))
plt.rc('font', family='arial')
#plt.rc('font',**{'family':'serif','serif':['Palatino']})
plt.rc('xtick', labelsize='x-small')
plt.rc('ytick', labelsize='x-small')
plt.tight_layout()
fig = plt.figure(figsize=(8, 5))
ax = fig.add_subplot(1, 1, 1)
plt.tick_params(labelsize=16)
ax.plot(x, swish1, ls='solid', color = 'black', label=r'$\beta=0.1$')
ax.plot(x, swish2, ls='dashed', color = 'black', label=r'$\beta=0.5$')
ax.plot(x, swish3, ls='dotted', color = 'black', label=r'$\beta=10.0$')
ax.set_xlabel('z', fontsize = 16)
ax.set_ylabel('SWISH activation function', fontsize = 16)
#plt.xlim(0,8)
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0., fontsize = 16)

#List3-11
#我们在这里介绍Tensorflow的激活函数。首先从加载必要的库开始。
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.python.framework import ops
ops.reset_default_graph()
初始化用于绘图的X的范围值
x_vals = np.linspace(start=-10., stop=10., num=100)
激活函数:
ReLU激活函数
print(tf.nn.relu([-3., 3., 10.]))
y_relu = tf.nn.relu(x_vals)
ReLU-6激活函数
print(tf.nn.relu6([-3., 3., 10.]))
y_relu6 = tf.nn.relu6(x_vals)
Sigmoid激活函数
print(tf.nn.sigmoid([-1., 0., 1.]))
y_sigmoid = tf.nn.sigmoid(x_vals)
Hyper Tangent激活函数
print(tf.nn.tanh([-1., 0., 1.]))
y_tanh = tf.nn.tanh(x_vals)
Softsign激活函数
print(tf.nn.softsign([-1., 0., 1.]))
y_softsign = tf.nn.softsign(x_vals)
Softplus激活函数
print(tf.nn.softplus([-1., 0., 1.]))
y_softplus = tf.nn.softplus(x_vals)
Exponential linear激活函数
print(tf.nn.elu([-1., 0., 1.]))
y_elu = tf.nn.elu(x_vals)
绘制不同的函数
plt.plot(x_vals, y_softplus, 'r--', label='Softplus', linewidth=2)
plt.plot(x_vals, y_relu, 'b:', label='ReLU', linewidth=2)
plt.plot(x_vals, y_relu6, 'g-.', label='ReLU6', linewidth=2)
plt.plot(x_vals, y_elu, 'k-', label='ExpLU', linewidth=0.5)
plt.ylim([-1.5,7])
plt.legend(loc='upper left')
plt.show()
plt.plot(x_vals, y_sigmoid, 'r--', label='Sigmoid', linewidth=2)
plt.plot(x_vals, y_tanh, 'b:', label='Tanh', linewidth=2)
plt.plot(x_vals, y_softsign, 'g-.', label='Softsign', linewidth=2)
plt.ylim([-2,2])
plt.legend(loc='upper left')
plt.show()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号