

DataX Web可视化优秀的工具简介 DataX Web是基于阿里云DataX构建的可视化管理界面,提供更便捷的任务调整和执行方式。本文介绍了DataX Web的安装部署方法,包括: DataX核心软件的两种安装方式:直接下载二进制包或源码编译 基础配置示例(Stream读写器演示) Web端的部署方案(Linux生产环境和开发环境) 数据库初始化及项目配置调整 通过DataX We
DataX Web介绍及安装(DataX可视化界面)
- datax GitHub地址:https://github.com/alibaba/DataX.git
- datax web Git地址:https://github.com/WeiYe-Jing/datax-web
- datax 下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
DataX web界面预览
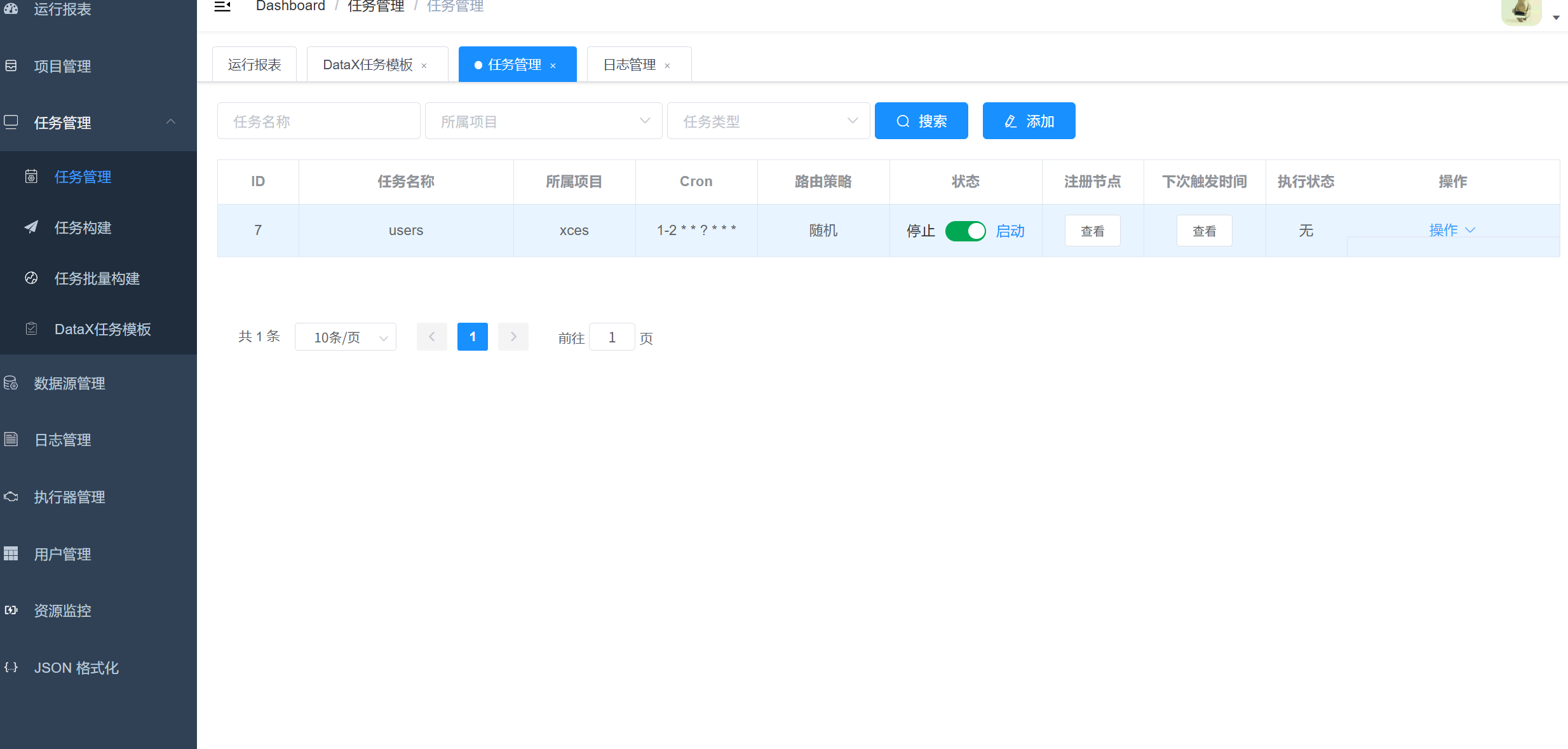
DataX web架构图
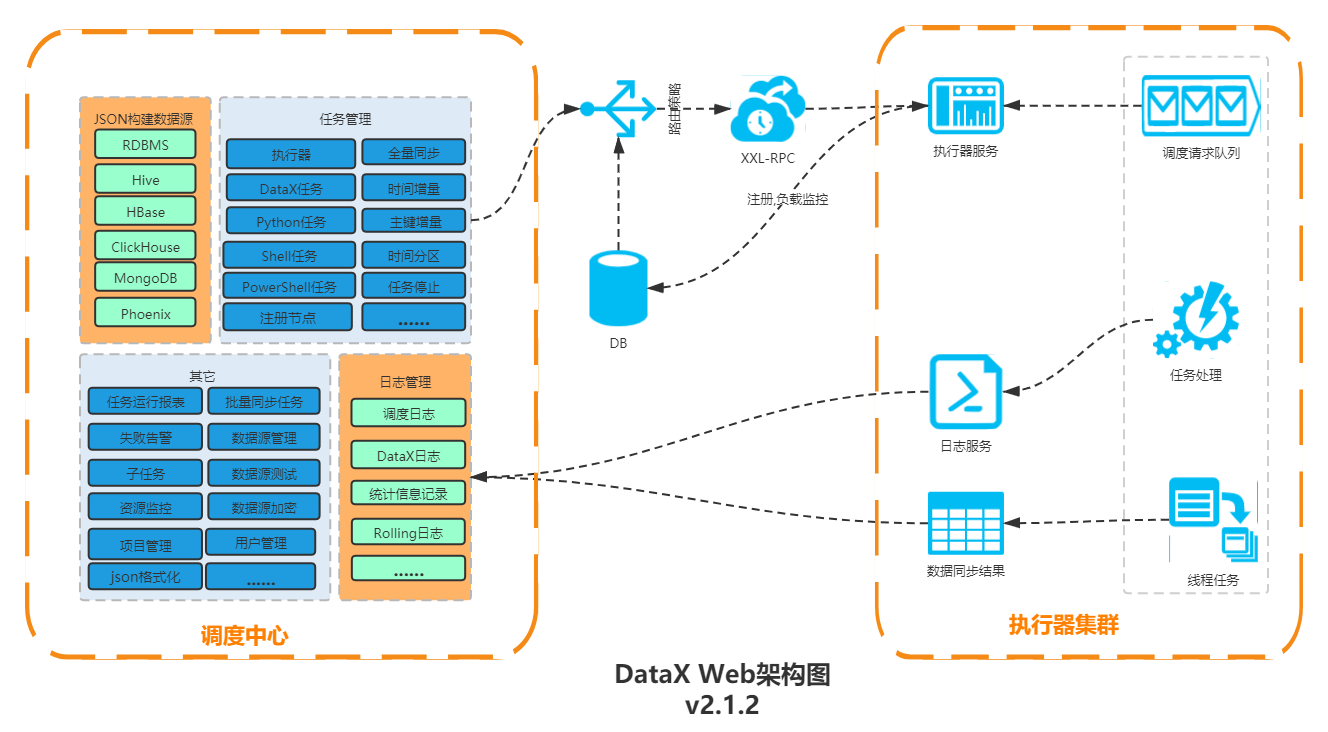
DataX Web用户手册
一、Github下载
二、安装DataX
方法一、直接下载DataX工具包:DataX下载地址
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME }/bin $ python datax.py {YOUR_JOB.json }自检脚本: python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
方法二、下载DataX源码,自己编译:DataX源码
(1)、下载DataX源码:
$ git clone git@github.com:alibaba/DataX.git(2)、通过maven打包:
$ cd {DataX_source_code_home } $ mvn -U clean package assembly:assembly -Dmaven.test.skip=true打包成功,日志显示如下:
[INFO] BUILD SUCCESS [INFO] ----------------------------------------------------------------- [INFO] Total time: 08:12 min [INFO] Finished at: 2015-12-13T16:26:48+08:00 [INFO] Final Memory: 133M/960M [INFO] -----------------------------------------------------------------打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home } $ ls ./target/datax/datax/ bin conf job lib log log_perf plugin script tmp配置示例:从stream读取数据并打印到控制台
第一步、创建创业的配置文件(json格式)
可以通过命令查看配置模板: python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
$ cd {YOUR_DATAX_HOME }/bin $ python datax.py -r streamreader -w streamwriter DataX (UNKNOWN_DATAX_VERSION), From Alibaba ! Copyright (C) 2010-2015, Alibaba Group. All Rights Reserved. Please refer to the streamreader document: https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md Please refer to the streamwriter document: https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md Please save the following configuration as a json file and use python {DATAX_HOME }/bin/datax.py {JSON_FILE_NAME }.json to run the job. { "job": { "content": [ { "reader": { "name": "streamreader", "parameter": { "column": [], "sliceRecordCount": "" } }, "writer": { "name": "streamwriter", "parameter": { "encoding": "", "print": true } } } ], "setting": { "speed": { "channel": "" } } } }根据模板配置json如下:
#stream2stream.json { "job": { "content": [ { "reader": { "name": "streamreader", "parameter": { "sliceRecordCount": 10, "column": [ { "type": "long", "value": "10" }, { "type": "string", "value": "hello,你好,世界-DataX" } ] } }, "writer": { "name": "streamwriter", "parameter": { "encoding": "UTF-8", "print": true } } } ], "setting": { "speed": { "channel": 5 } } } }第二步:启动DataX
$ cd {YOUR_DATAX_DIR_BIN } $ python datax.py ./stream2stream.json同步结束,显示日志如下:
... 2015-12-17 11:20:25.263 [job-0] INFO JobContainer - 任务启动时刻 : 2015-12-17 11:20:15 任务结束时刻 : 2015-12-17 11:20:25 任务总计耗时 : 10s 任务平均流量 : 205B/s 记录写入速度 : 5rec/s 读出记录总数 : 50 读写失败总数 : 0
三、Web部署
1.linux环境部署
2.开发环境部署(或参考文档 Debug)
2.1 创建数据库
执行bin/db下面的datax_web.sql文件(注意老版本更新语句有指定库名)
2.2 修改项目配置
1.修改datax_admin下resources/application.yml文件
#数据源
datasource:
username: root
password: root
url: jdbc:mysql://localhost:3306/datax_web?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver修改数据源配置,目前仅支持mysql
# 配置mybatis-plus打印sql日志
logging:
level:
com.wugui.datax.admin.mapper: error
path: ./data/applogs/admin修改日志路径path
# datax-web email
mail:
host: smtp.qq.com
port: 25
username: xxx@qq.com
password: xxx
properties:
mail:
smtp:
auth: true
starttls:
enable: true
required: true
socketFactory:
class: javax.net.ssl.SSLSocketFactory修改邮件发送配置(不需要可以不修改)
2.修改datax_executor下resources/application.yml文件
# log config
logging:
config: classpath:logback.xml
path: ./data/applogs/executor/jobhandler修改日志路径path
datax:
job:
admin:
### datax-web admin address
addresses: http://127.0.0.1:8080
executor:
appname: datax-executor
ip:
port: 9999
### job log path
logpath: ./data/applogs/executor/jobhandler
### job log retention days
logretentiondays: 30
executor:
jsonpath: /Users/mac/data/applogs
pypath: /Users/mac/tools/datax/bin/datax.py修改datax.job配置
- admin.addresses datax_admin部署地址,如调度中心集群部署存在多个地址则用逗号分隔,执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";
- executor.appname 执行器AppName,每个执行器机器集群的唯一标示,执行器心跳注册分组依据;
- executor.ip 默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 “执行器注册” 和 “调度中心请求并触发任务”;
- executor.port 执行器Server端口号,默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
- executor.logpath 执行器运行日志文件存储磁盘路径,需要对该路径拥有读写权限;
- executor.logretentiondays 执行器日志文件保存天数,过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
- executor.jsonpath datax json临时文件保存路径
- pypath DataX启动脚本地址,例如:xxx/datax/bin/datax.py 如果系统配置DataX环境变量(DATAX_HOME),logpath、jsonpath、pypath可不配,log文件和临时json存放在环境变量路径下。
四、启动项目
1.本地idea开发环境
- 1.运行datax_admin下 DataXAdminApplication
- 2.运行datax_executor下 DataXExecutorApplication
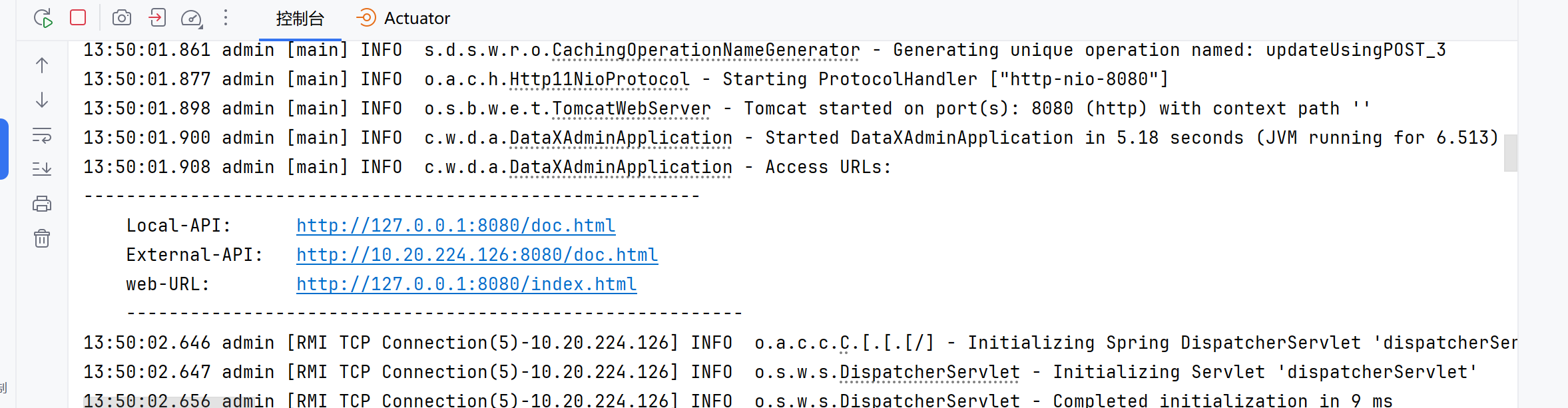
admin启动成功后日志会输出三个地址,两个接口文档地址,一个前端页面地址
五、启动成功
启动成功后打开页面(默认管理员用户名:admin 密码:123456)
六、集群部署
调度中心、执行器支持集群部署,提升调度系统容灾和可用性。
1.调度中心集群:
DB配置保持一致;
集群机器时钟保持一致(单机集群忽视);2.执行器集群:
执行器回调地址(admin.addresses)需要保持一致;执行器根据该配置进行执行器自动注册等操作。
同一个执行器集群内AppName(executor.appname)需要保持一致;调度中心根据该配置动态发现不同集群的在线执行器列表。
七、Datax遇到的问题
1、配置文件不存在
[main] WARN ConfigParser - 插件[streamreader,streamwriter]加载失败,1s后重试... Exception:Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件.
[main] ERROR Engine -
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件.
at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:26)
at com.alibaba.datax.common.util.Configuration.from(Configuration.java:95)
at com.alibaba.datax.core.util.ConfigParser.parseOnePluginConfig(ConfigParser.java:153)
at com.alibaba.datax.core.util.ConfigParser.parsePluginConfig(ConfigParser.java:125)
at com.alibaba.datax.core.util.ConfigParser.parse(ConfigParser.java:63)
at com.alibaba.datax.core.Engine.entry(Engine.java:137)
at com.alibaba.datax.core.Engine.main(Engine.java:204)解决方案:将 plugin 目录下的所有的以 _ 开头的文件都删除即可
2、Python版本问题
DataX 这个项目本身是用 Python2 进行开发的,因此需要使用 Python2 的版本进行执行。但是我们安装的 Python 版本是 3,而且 3 和 2 的语法差异还是比较大的。因此直接使用 python3 去执行的话,会出现问题。
3、[datax]报错 File “datax.py”, line 114 print readerRef
解决方案:更换安装目录下bin的对应文件:datax.py, dxprof.y, perftrace.py
datax.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
Life's short, Python more.
"""
import sys
import os
import signal
import subprocess
import time
import re
import socket
import json
from optparse import OptionParser
from optparse import OptionGroup
from string import Template
import codecs
import platform
def isWindows():
return platform.system() == 'Windows'
DATAX_HOME = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
DATAX_VERSION = 'DATAX-OPENSOURCE-3.0'
if isWindows():
codecs.register(lambda name: name == 'cp65001' and codecs.lookup('utf-8') or None)
CLASS_PATH = ("%s/lib/*") % (DATAX_HOME)
else:
CLASS_PATH = ("%s/lib/*:.") % (DATAX_HOME)
LOGBACK_FILE = ("%s/conf/logback.xml") % (DATAX_HOME)
DEFAULT_JVM = "-Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=%s/log" % (DATAX_HOME)
DEFAULT_PROPERTY_CONF = "-Dfile.encoding=UTF-8 -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=%s -Dlogback.configurationFile=%s" % (
DATAX_HOME, LOGBACK_FILE)
ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params} com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (
DEFAULT_PROPERTY_CONF, CLASS_PATH)
REMOTE_DEBUG_CONFIG = "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,address=9999"
RET_STATE = {
"KILL": 143,
"FAIL": -1,
"OK": 0,
"RUN": 1,
"RETRY": 2
}
def getLocalIp():
try:
return socket.gethostbyname(socket.getfqdn(socket.gethostname()))
except:
return "Unknown"
def suicide(signum, e):
global child_process
print >> sys.stderr, "[Error] DataX receive unexpected signal %d, starts to suicide." % (signum)
if child_process:
child_process.send_signal(signal.SIGQUIT)
time.sleep(1)
child_process.kill()
print >> sys.stderr, "DataX Process was killed ! you did ?"
sys.exit(RET_STATE["KILL"])
def register_signal():
if not isWindows():
global child_process
signal.signal(2, suicide)
signal.signal(3, suicide)
signal.signal(15, suicide)
def getOptionParser():
usage = "usage: %prog [options] job-url-or-path"
parser = OptionParser(usage=usage)
prodEnvOptionGroup = OptionGroup(parser, "Product Env Options",
"Normal user use these options to set jvm parameters, job runtime mode etc. "
"Make sure these options can be used in Product Env.")
prodEnvOptionGroup.add_option("-j", "--jvm", metavar="<jvm parameters>", dest="jvmParameters", action="store",
default=DEFAULT_JVM, help="Set jvm parameters if necessary.")
prodEnvOptionGroup.add_option("--jobid", metavar="<job unique id>", dest="jobid", action="store", default="-1",
help="Set job unique id when running by Distribute/Local Mode.")
prodEnvOptionGroup.add_option("-m", "--mode", metavar="<job runtime mode>",
action="store", default="standalone",
help="Set job runtime mode such as: standalone, local, distribute. "
"Default mode is standalone.")
prodEnvOptionGroup.add_option("-p", "--params", metavar="<parameter used in job config>",
action="store", dest="params",
help='Set job parameter, eg: the source tableName you want to set it by command, '
'then you can use like this: -p"-DtableName=your-table-name", '
'if you have mutiple parameters: -p"-DtableName=your-table-name -DcolumnName=your-column-name".'
'Note: you should config in you job tableName with ${tableName}.')
prodEnvOptionGroup.add_option("-r", "--reader", metavar="<parameter used in view job config[reader] template>",
action="store", dest="reader",type="string",
help='View job config[reader] template, eg: mysqlreader,streamreader')
prodEnvOptionGroup.add_option("-w", "--writer", metavar="<parameter used in view job config[writer] template>",
action="store", dest="writer",type="string",
help='View job config[writer] template, eg: mysqlwriter,streamwriter')
parser.add_option_group(prodEnvOptionGroup)
devEnvOptionGroup = OptionGroup(parser, "Develop/Debug Options",
"Developer use these options to trace more details of DataX.")
devEnvOptionGroup.add_option("-d", "--debug", dest="remoteDebug", action="store_true",
help="Set to remote debug mode.")
devEnvOptionGroup.add_option("--loglevel", metavar="<log level>", dest="loglevel", action="store",
default="info", help="Set log level such as: debug, info, all etc.")
parser.add_option_group(devEnvOptionGroup)
return parser
def generateJobConfigTemplate(reader, writer):
readerRef = "Please refer to the %s document:\n https://github.com/alibaba/DataX/blob/master/%s/doc/%s.md \n" % (reader,reader,reader)
writerRef = "Please refer to the %s document:\n https://github.com/alibaba/DataX/blob/master/%s/doc/%s.md \n " % (writer,writer,writer)
print(readerRef)
print(writerRef)
jobGuid = 'Please save the following configuration as a json file and use\n python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json \nto run the job.\n'
print(jobGuid)
jobTemplate={
"job": {
"setting": {
"speed": {
"channel": ""
}
},
"content": [
{
"reader": {
},
"writer": {
}
}
]
}
}
readerTemplatePath = "%s/plugin/reader/%s/plugin_job_template.json" % (DATAX_HOME,reader)
writerTemplatePath = "%s/plugin/writer/%s/plugin_job_template.json" % (DATAX_HOME,writer)
try:
readerPar = readPluginTemplate(readerTemplatePath);
except Exception as e:
print("Read reader[%s] template error: can\'t find file %s" % (reader,readerTemplatePath))
try:
writerPar = readPluginTemplate(writerTemplatePath);
except Exception as e:
print("Read writer[%s] template error: : can\'t find file %s" % (writer,writerTemplatePath))
jobTemplate['job']['content'][0]['reader'] = readerPar;
jobTemplate['job']['content'][0]['writer'] = writerPar;
print(json.dumps(jobTemplate, indent=4, sort_keys=True))
def readPluginTemplate(plugin):
with open(plugin, 'r') as f:
return json.load(f)
def isUrl(path):
if not path:
return False
assert (isinstance(path, str))
m = re.match(r"^http[s]?://\S+\w*", path.lower())
if m:
return True
else:
return False
def buildStartCommand(options, args):
commandMap = {
}
tempJVMCommand = DEFAULT_JVM
if options.jvmParameters:
tempJVMCommand = tempJVMCommand + " " + options.jvmParameters
if options.remoteDebug:
tempJVMCommand = tempJVMCommand + " " + REMOTE_DEBUG_CONFIG
print('local ip: ', getLocalIp())
if options.loglevel:
tempJVMCommand = tempJVMCommand + " " + ("-Dloglevel=%s" % (options.loglevel))
if options.mode:
commandMap["mode"] = options.mode
# jobResource 可能是 URL,也可能是本地文件路径(相对,绝对)
jobResource = args[0]
if not isUrl(jobResource):
jobResource = os.path.abspath(jobResource)
if jobResource.lower().startswith("file://"):
jobResource = jobResource[len("file://"):]
jobParams = ("-Dlog.file.name=%s") % (jobResource[-20:].replace('/', '_').replace('.', '_'))
if options.params:
jobParams = jobParams + " " + options.params
if options.jobid:
commandMap["jobid"] = options.jobid
commandMap["jvm"] = tempJVMCommand
commandMap["params"] = jobParams
commandMap["job"] = jobResource
return Template(ENGINE_COMMAND).substitute(**commandMap)
def printCopyright():
print('''
DataX (%s), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
''' % DATAX_VERSION)
sys.stdout.flush()
if __name__ == "__main__":
printCopyright()
parser = getOptionParser()
options, args = parser.parse_args(sys.argv[1:])
if options.reader is not None and options.writer is not None:
generateJobConfigTemplate(options.reader,options.writer)
sys.exit(RET_STATE['OK'])
if len(args) != 1:
parser.print_help()
sys.exit(RET_STATE['FAIL'])
startCommand = buildStartCommand(options, args)
# print startCommand
child_process = subprocess.Popen(startCommand, shell=True)
register_signal()
(stdout, stderr) = child_process.communicate()
sys.exit(child_process.returncode)dxprof.y
#! /usr/bin/env python
# vim: set expandtab tabstop=4 shiftwidth=4 foldmethod=marker nu:
import re
import sys
import time
REG_SQL_WAKE = re.compile(r'Begin\s+to\s+read\s+record\s+by\s+Sql', re.IGNORECASE)
REG_SQL_DONE = re.compile(r'Finished\s+read\s+record\s+by\s+Sql', re.IGNORECASE)
REG_SQL_PATH = re.compile(r'from\s+(\w+)(\s+where|\s*$)', re.IGNORECASE)
REG_SQL_JDBC = re.compile(r'jdbcUrl:\s*\[(.+?)\]', re.IGNORECASE)
REG_SQL_UUID = re.compile(r'(\d+\-)+reader')
REG_COMMIT_UUID = re.compile(r'(\d+\-)+writer')
REG_COMMIT_WAKE = re.compile(r'begin\s+to\s+commit\s+blocks', re.IGNORECASE)
REG_COMMIT_DONE = re.compile(r'commit\s+blocks\s+ok', re.IGNORECASE)
# {{{ function parse_timestamp() #
def parse_timestamp(line):
try:
ts = int(time.mktime(time.strptime(line[0:19], '%Y-%m-%d %H:%M:%S')))
except:
ts = 0
return ts
# }}} #
# {{{ function parse_query_host() #
def parse_query_host(line):
ori = REG_SQL_JDBC.search(line)
if (not ori):
return ''
ori = ori.group(1).split('?')[0]
off = ori.find('@')
if (off >
-1):
ori = ori[off+1:len(ori)]
else:
off = ori.find('//')
if (off >
-1):
ori = ori[off+2:len(ori)]
return ori.lower()
# }}} #
# {{{ function parse_query_table() #
def parse_query_table(line):
ori = REG_SQL_PATH.search(line)
return (ori and ori.group(1).lower()) or ''
# }}} #
# {{{ function parse_reader_task() #
def parse_task(fname):
global LAST_SQL_UUID
global LAST_COMMIT_UUID
global DATAX_JOBDICT
global DATAX_JOBDICT_COMMIT
global UNIXTIME
LAST_SQL_UUID = ''
DATAX_JOBDICT = {
}
LAST_COMMIT_UUID = ''
DATAX_JOBDICT_COMMIT = {
}
UNIXTIME = int(time.time())
with open(fname, 'r') as f:
for line in f.readlines():
line = line.strip()
if (LAST_SQL_UUID and (LAST_SQL_UUID in DATAX_JOBDICT)):
DATAX_JOBDICT[LAST_SQL_UUID]['host'] = parse_query_host(line)
LAST_SQL_UUID = ''
if line.find('CommonRdbmsReader$Task') >
0:
parse_read_task(line)
elif line.find('commit blocks') >
0:
parse_write_task(line)
else:
continue
# }}} #
# {{{ function parse_read_task() #
def parse_read_task(line):
ser = REG_SQL_UUID.search(line)
if not ser:
return
LAST_SQL_UUID = ser.group()
if REG_SQL_WAKE.search(line):
DATAX_JOBDICT[LAST_SQL_UUID] = {
'stat' : 'R',
'wake' : parse_timestamp(line),
'done' : UNIXTIME,
'host' : parse_query_host(line),
'path' : parse_query_table(line)
}
elif ((LAST_SQL_UUID in DATAX_JOBDICT) and REG_SQL_DONE.search(line)):
DATAX_JOBDICT[LAST_SQL_UUID]['stat'] = 'D'
DATAX_JOBDICT[LAST_SQL_UUID]['done'] = parse_timestamp(line)
# }}} #
# {{{ function parse_write_task() #
def parse_write_task(line):
ser = REG_COMMIT_UUID.search(line)
if not ser:
return
LAST_COMMIT_UUID = ser.group()
if REG_COMMIT_WAKE.search(line):
DATAX_JOBDICT_COMMIT[LAST_COMMIT_UUID] = {
'stat' : 'R',
'wake' : parse_timestamp(line),
'done' : UNIXTIME,
}
elif ((LAST_COMMIT_UUID in DATAX_JOBDICT_COMMIT) and REG_COMMIT_DONE.search(line)):
DATAX_JOBDICT_COMMIT[LAST_COMMIT_UUID]['stat'] = 'D'
DATAX_JOBDICT_COMMIT[LAST_COMMIT_UUID]['done'] = parse_timestamp(line)
# }}} #
# {{{ function result_analyse() #
def result_analyse():
def compare(a, b):
return b['cost'] - a['cost']
tasklist = []
hostsmap = {
}
statvars = {
'sum' : 0, 'cnt' : 0, 'svr' : 0, 'max' : 0, 'min' : int(time.time())
}
tasklist_commit = []
statvars_commit = {
'sum' : 0, 'cnt' : 0
}
for idx in DATAX_JOBDICT:
item = DATAX_JOBDICT[idx]
item['uuid'] = idx;
item['cost'] = item['done'] - item['wake']
tasklist.append(item);
if (not (item['host'] in hostsmap)):
hostsmap[item['host']] = 1
statvars['svr'] += 1
if (item['cost'] >
-1 and item['cost'] <
864000):
statvars['sum'] += item['cost']
statvars['cnt'] += 1
statvars['max'] = max(statvars['max'], item['done'])
statvars['min'] = min(statvars['min'], item['wake'])
for idx in DATAX_JOBDICT_COMMIT:
itemc = DATAX_JOBDICT_COMMIT[idx]
itemc['uuid'] = idx
itemc['cost'] = itemc['done'] - itemc['wake']
tasklist_commit.append(itemc)
if (itemc['cost'] >
-1 and itemc['cost'] <
864000):
statvars_commit['sum'] += itemc['cost']
statvars_commit['cnt'] += 1
ttl = (statvars['max'] - statvars['min']) or 1
idx = float(statvars['cnt']) / (statvars['sum'] or ttl)
tasklist.sort(compare)
for item in tasklist:
print('%s\t%s.%s\t%s\t%s\t% 4d\t% 2.1f%%\t% .2f' %(item['stat'], item['host'], item['path'],
time.strftime('%H:%M:%S', time.localtime(item['wake'])),
(('D' == item['stat']) and time.strftime('%H:%M:%S', time.localtime(item['done']))) or '--',
item['cost'], 100 * item['cost'] / ttl, idx * item['cost']))
if (not len(tasklist) or not statvars['cnt']):
return
print('\n--- DataX Profiling Statistics ---')
print('%d task(s) on %d server(s), Total elapsed %d second(s), %.2f second(s) per task in average' %(statvars['cnt'],
statvars['svr'], statvars['sum'], float(statvars['sum']) / statvars['cnt']))
print('Actually cost %d second(s) (%s - %s), task concurrency: %.2f, tilt index: %.2f' %(ttl,
time.strftime('%H:%M:%S', time.localtime(statvars['min'])),
time.strftime('%H:%M:%S', time.localtime(statvars['max'])),
float(statvars['sum']) / ttl, idx * tasklist[0]['cost']))
idx_commit = float(statvars_commit['cnt']) / (statvars_commit['sum'] or ttl)
tasklist_commit.sort(compare)
print('%d task(s) done odps comit, Total elapsed %d second(s), %.2f second(s) per task in average, tilt index: %.2f' % (
statvars_commit['cnt'],
statvars_commit['sum'], float(statvars_commit['sum']) / statvars_commit['cnt'],
idx_commit * tasklist_commit[0]['cost']))
# }}} #
if (len(sys.argv) <
2):
print("Usage: %s filename" %(sys.argv[0]))
quit(1)
else:
parse_task(sys.argv[1])
result_analyse()perftrace.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
Life's short, Python more.
"""
import re
import os
import sys
import json
import uuid
import signal
import time
import subprocess
from optparse import OptionParser
reload(sys)
sys.setdefaultencoding('utf8')
##begin cli & help logic
def getOptionParser():
usage = getUsage()
parser = OptionParser(usage = usage)
#rdbms reader and writer
parser.add_option('-r', '--reader', action='store', dest='reader', help='trace datasource read performance with specified !json! string')
parser.add_option('-w', '--writer', action='store', dest='writer', help='trace datasource write performance with specified !json! string')
parser.add_option('-c', '--channel', action='store', dest='channel', default='1', help='the number of concurrent sync thread, the default is 1')
parser.add_option('-f', '--file', action='store', help='existing datax configuration file, include reader and writer params')
parser.add_option('-t', '--type', action='store', default='reader', help='trace which side\'s performance, cooperate with -f --file params, need to be reader or writer')
parser.add_option('-d', '--delete', action='store', default='true', help='delete temporary files, the default value is true')
#parser.add_option('-h', '--help', action='store', default='true', help='print usage information')
return parser
def getUsage():
return '''
The following params are available for -r --reader:
[these params is for rdbms reader, used to trace rdbms read performance, it's like datax's key]
*datasourceType: datasource type, may be mysql|drds|oracle|ads|sqlserver|postgresql|db2 etc...
*jdbcUrl: datasource jdbc connection string, mysql as a example: jdbc:mysql://ip:port/database
*username: username for datasource
*password: password for datasource
*table: table name for read data
column: column to be read, the default value is ['*']
splitPk: the splitPk column of rdbms table
where: limit the scope of the performance data set
fetchSize: how many rows to be fetched at each communicate
[these params is for stream reader, used to trace rdbms write performance]
reader-sliceRecordCount: how man test data to mock(each channel), the default value is 10000
reader-column : stream reader while generate test data(type supports: string|long|date|double|bool|bytes; support constant value and random function),demo: [{"type":"string","value":"abc"},{"type":"string","random":"10,20"}]
The following params are available for -w --writer:
[these params is for rdbms writer, used to trace rdbms write performance, it's like datax's key]
datasourceType: datasource type, may be mysql|drds|oracle|ads|sqlserver|postgresql|db2|ads etc...
*jdbcUrl: datasource jdbc connection string, mysql as a example: jdbc:mysql://ip:port/database
*username: username for datasource
*password: password for datasource
*table: table name for write data
column: column to be writed, the default value is ['*']
batchSize: how many rows to be storeed at each communicate, the default value is 512
preSql: prepare sql to be executed before write data, the default value is ''
postSql: post sql to be executed end of write data, the default value is ''
url: required for ads, pattern is ip:port
schme: required for ads, ads database name
[these params is for stream writer, used to trace rdbms read performance]
writer-print: true means print data read from source datasource, the default value is false
The following params are available global control:
-c --channel: the number of concurrent tasks, the default value is 1
-f --file: existing completely dataX configuration file path
-t --type: test read or write performance for a datasource, couble be reader or writer, in collaboration with -f --file
-h --help: print help message
some demo:
perftrace.py --channel=10 --reader='{"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/database", "username":"", "password":"", "table": "", "where":"", "splitPk":"", "writer-print":"false"}'
perftrace.py --channel=10 --writer='{"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/database", "username":"", "password":"", "table": "", "reader-sliceRecordCount": "10000", "reader-column": [{"type":"string","value":"abc"},{"type":"string","random":"10,20"}]}'
perftrace.py --file=/tmp/datax.job.json --type=reader --reader='{"writer-print": "false"}'
perftrace.py --file=/tmp/datax.job.json --type=writer --writer='{"reader-sliceRecordCount": "10000", "reader-column": [{"type":"string","value":"abc"},{"type":"string","random":"10,20"}]}'
some example jdbc url pattern, may help:
jdbc:oracle:thin:@ip:port:database
jdbc:mysql://ip:port/database
jdbc:sqlserver://ip:port;DatabaseName=database
jdbc:postgresql://ip:port/database
warn: ads url pattern is ip:port
warn: test write performance will write data into your table, you can use a temporary table just for test.
'''
def printCopyright():
DATAX_VERSION = 'UNKNOWN_DATAX_VERSION'
print('''
DataX Util Tools (%s), From Alibaba !
Copyright (C) 2010-2016, Alibaba Group. All Rights Reserved.''' % DATAX_VERSION)
sys.stdout.flush()
def yesNoChoice():
yes = set(['yes','y', 'ye', ''])
no = set(['no','n'])
choice = raw_input().lower()
if choice in yes:
return True
elif choice in no:
return False
else:
sys.stdout.write("Please respond with 'yes' or 'no'")
##end cli & help logic
##begin process logic
def suicide(signum, e):
global childProcess
print >> sys.stderr, "[Error] Receive unexpected signal %d, starts to suicide." % (signum)
if childProcess:
childProcess.send_signal(signal.SIGQUIT)
time.sleep(1)
childProcess.kill()
print >> sys.stderr, "DataX Process was killed ! you did ?"
sys.exit(-1)
def registerSignal():
global childProcess
signal.signal(2, suicide)
signal.signal(3, suicide)
signal.signal(15, suicide)
def fork(command, isShell=False):
global childProcess
childProcess = subprocess.Popen(command, shell = isShell)
registerSignal()
(stdout, stderr) = childProcess.communicate()
#阻塞直到子进程结束
childProcess.wait()
return childProcess.returncode
##end process logic
##begin datax json generate logic
#warn: if not '': -> true; if not None: -> true
def notNone(obj, context):
if not obj:
raise Exception("Configuration property [%s] could not be blank!" % (context))
def attributeNotNone(obj, attributes):
for key in attributes:
notNone(obj.get(key), key)
def isBlank(value):
if value is None or len(value.strip()) == 0:
return True
return False
def parsePluginName(jdbcUrl, pluginType):
import re
#warn: drds
name = 'pluginName'
mysqlRegex = re.compile('jdbc:(mysql)://.*')
if (mysqlRegex.match(jdbcUrl)):
name = 'mysql'
postgresqlRegex = re.compile('jdbc:(postgresql)://.*')
if (postgresqlRegex.match(jdbcUrl)):
name = 'postgresql'
oracleRegex = re.compile('jdbc:(oracle):.*')
if (oracleRegex.match(jdbcUrl)):
name = 'oracle'
sqlserverRegex = re.compile('jdbc:(sqlserver)://.*')
if (sqlserverRegex.match(jdbcUrl)):
name = 'sqlserver'
db2Regex = re.compile('jdbc:(db2)://.*')
if (db2Regex.match(jdbcUrl)):
name = 'db2'
return "%s%s" % (name, pluginType)
def renderDataXJson(paramsDict, readerOrWriter = 'reader', channel = 1):
dataxTemplate = {
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "",
"parameter": {
"username": "",
"password": "",
"sliceRecordCount": "10000",
"column": [
"*"
],
"connection": [
{
"table": [],
"jdbcUrl": []
}
]
}
},
"writer": {
"name": "",
"parameter": {
"print": "false",
"connection": [
{
"table": [],
"jdbcUrl": ''
}
]
}
}
}
]
}
}
dataxTemplate['job']['setting']['speed']['channel'] = channel
dataxTemplateContent = dataxTemplate['job']['content'][0]
pluginName = ''
if paramsDict.get('datasourceType'):
pluginName = '%s%s' % (paramsDict['datasourceType'], readerOrWriter)
elif paramsDict.get('jdbcUrl'):
pluginName = parsePluginName(paramsDict['jdbcUrl'], readerOrWriter)
elif paramsDict.get('url'):
pluginName = 'adswriter'
theOtherSide = 'writer' if readerOrWriter == 'reader' else 'reader'
dataxPluginParamsContent = dataxTemplateContent.get(readerOrWriter).get('parameter')
dataxPluginParamsContent.update(paramsDict)
dataxPluginParamsContentOtherSide = dataxTemplateContent.get(theOtherSide).get('parameter')
if readerOrWriter == 'reader':
dataxTemplateContent.get('reader')['name'] = pluginName
dataxTemplateContent.get('writer')['name'] = 'streamwriter'
if paramsDict.get('writer-print'):
dataxPluginParamsContentOtherSide['print'] = paramsDict['writer-print']
del dataxPluginParamsContent['writer-print']
del dataxPluginParamsContentOtherSide['connection']
if readerOrWriter == 'writer':
dataxTemplateContent.get('reader')['name'] = 'streamreader'
dataxTemplateContent.get('writer')['name'] = pluginName
if paramsDict.get('reader-column'):
dataxPluginParamsContentOtherSide['column'] = paramsDict['reader-column']
del dataxPluginParamsContent['reader-column']
if paramsDict.get('reader-sliceRecordCount'):
dataxPluginParamsContentOtherSide['sliceRecordCount'] = paramsDict['reader-sliceRecordCount']
del dataxPluginParamsContent['reader-sliceRecordCount']
del dataxPluginParamsContentOtherSide['connection']
if paramsDict.get('jdbcUrl'):
if readerOrWriter == 'reader':
dataxPluginParamsContent['connection'][0]['jdbcUrl'].append(paramsDict['jdbcUrl'])
else:
dataxPluginParamsContent['connection'][0]['jdbcUrl'] = paramsDict['jdbcUrl']
if paramsDict.get('table'):
dataxPluginParamsContent['connection'][0]['table'].append(paramsDict['table'])
traceJobJson = json.dumps(dataxTemplate, indent = 4)
return traceJobJson
def isUrl(path):
if not path:
return False
if not isinstance(path, str):
raise Exception('Configuration file path required for the string, you configure is:%s' % path)
m = re.match(r"^http[s]?://\S+\w*", path.lower())
if m:
return True
else:
return False
def readJobJsonFromLocal(jobConfigPath):
jobConfigContent = None
jobConfigPath = os.path.abspath(jobConfigPath)
file = open(jobConfigPath)
try:
jobConfigContent = file.read()
finally:
file.close()
if not jobConfigContent:
raise Exception("Your job configuration file read the result is empty, please check the configuration is legal, path: [%s]\nconfiguration:\n%s" % (jobConfigPath, str(jobConfigContent)))
return jobConfigContent
def readJobJsonFromRemote(jobConfigPath):
import urllib
conn = urllib.urlopen(jobConfigPath)
jobJson = conn.read()
return jobJson
def parseJson(strConfig, context):
try:
return json.loads(strConfig)
except Exception as e:
import traceback
traceback.print_exc()
sys.stdout.flush()
print >> sys.stderr, '%s %s need in line with json syntax' % (context, strConfig)
sys.exit(-1)
def convert(options, args):
traceJobJson = ''
if options.file:
if isUrl(options.file):
traceJobJson = readJobJsonFromRemote(options.file)
else:
traceJobJson = readJobJsonFromLocal(options.file)
traceJobDict = parseJson(traceJobJson, '%s content' % options.file)
attributeNotNone(traceJobDict, ['job'])
attributeNotNone(traceJobDict['job'], ['content'])
attributeNotNone(traceJobDict['job']['content'][0], ['reader', 'writer'])
attributeNotNone(traceJobDict['job']['content'][0]['reader'], ['name', 'parameter'])
attributeNotNone(traceJobDict['job']['content'][0]['writer'], ['name', 'parameter'])
if options.type == 'reader':
traceJobDict['job']['content'][0]['writer']['name'] = 'streamwriter'
if options.reader:
traceReaderDict = parseJson(options.reader, 'reader config')
if traceReaderDict.get('writer-print') is not None:
traceJobDict['job']['content'][0]['writer']['parameter']['print'] = traceReaderDict.get('writer-print')
else:
traceJobDict['job']['content'][0]['writer']['parameter']['print'] = 'false'
else:
traceJobDict['job']['content'][0]['writer']['parameter']['print'] = 'false'
elif options.type == 'writer':
traceJobDict['job']['content'][0]['reader']['name'] = 'streamreader'
if options.writer:
traceWriterDict = parseJson(options.writer, 'writer config')
if traceWriterDict.get('reader-column'):
traceJobDict['job']['content'][0]['reader']['parameter']['column'] = traceWriterDict['reader-column']
if traceWriterDict.get('reader-sliceRecordCount'):
traceJobDict['job']['content'][0]['reader']['parameter']['sliceRecordCount'] = traceWriterDict['reader-sliceRecordCount']
else:
columnSize = len(traceJobDict['job']['content'][0]['writer']['parameter']['column'])
streamReaderColumn = []
for i in range(columnSize):
streamReaderColumn.append({
"type": "long", "random": "2,10"
})
traceJobDict['job']['content'][0]['reader']['parameter']['column'] = streamReaderColumn
traceJobDict['job']['content'][0]['reader']['parameter']['sliceRecordCount'] = 10000
else:
pass#do nothing
return json.dumps(traceJobDict, indent = 4)
elif options.reader:
traceReaderDict = parseJson(options.reader, 'reader config')
return renderDataXJson(traceReaderDict, 'reader', options.channel)
elif options.writer:
traceWriterDict = parseJson(options.writer, 'writer config')
return renderDataXJson(traceWriterDict, 'writer', options.channel)
else:
print(getUsage())
sys.exit(-1)
#dataxParams = {}
#for opt, value in options.__dict__.items():
# dataxParams[opt] = value
##end datax json generate logic
if __name__ == "__main__":
printCopyright()
parser = getOptionParser()
options, args = parser.parse_args(sys.argv[1:])
#print options, args
dataxTraceJobJson = convert(options, args)
#由MAC地址、当前时间戳、随机数生成,可以保证全球范围内的唯一性
dataxJobPath = os.path.join(os.getcwd(), "perftrace-" + str(uuid.uuid1()))
jobConfigOk = True
if os.path.exists(dataxJobPath):
print("file already exists, truncate and rewrite it? %s" % dataxJobPath)
if yesNoChoice():
jobConfigOk = True
else:
print("exit failed, because of file conflict")
sys.exit(-1)
fileWriter = open(dataxJobPath, 'w')
fileWriter.write(dataxTraceJobJson)
fileWriter.close()
print("trace environments:")
print("dataxJobPath: %s" % dataxJobPath)
dataxHomePath = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
print("dataxHomePath: %s" % dataxHomePath)
dataxCommand = "%s %s" % (os.path.join(dataxHomePath, "bin", "datax.py"), dataxJobPath)
print("dataxCommand: %s" % dataxCommand)
returncode = fork(dataxCommand, True)
if options.delete == 'true':
os.remove(dataxJobPath)
sys.exit(returncode)4、datax运行时报错-数据库服务的IP地址或者Port错误
解决办法:
更换MySQL驱动包
驱动包位置:从datax解压文件夹进入datax/plugin/reader/mysqlreader/libs和datax/plugin/writer/mysqlreader/libs 将高版本的MySQL驱动包上传到该文件夹下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号