

afl-fuzz.c详解
main函数中fuzz主循环
第一次循环
while(1){
u8 skipped_fuzz;
cull_queue(); //精简队列
skipped_fuzz=fuzz_one(use_argv); //fuzz_one不执行为1,否则返回0
if(!stop_soon&&sync_id&&!skipped_fuzz){ //fuzz_one未执行
if(!(sync_interval_cnt++ % SYNC_INTERVAL))
sync_fuzzers(use_argv);
}
queue_cur=queue_cur->next; /*开始测试下一个queue*/
current_entry++;
}
关键函数
fuzz_one
if(pending_favored),是否存在受青睐的
•如果存在受青睐的,对于这一项被fuzz过或者这一项不是favored,有99%的概率被跳过
•如果不存在受青睐的,对于不是dumb模式,这一项不是favored,并且测试用例满足一定数量 (queue_path>10,这里阈值为10个),继续进行分支
•如果当前的循环次数大于1且这一项没被fuzz过,有75%的概率被跳过,不满足条件会有更大的概率被跳 过(95%)
映射文件内容到内存
•mmap函数用于将文件按文件内容映射到内存中,接着给out_buf用ck_alloc_nozero分配len大小的全零内存, 最后用cur_depth记录当前测试用例的深度。
CALIBRATION校准阶段:如果出现校准错误且少于3次,用calibrate再次校准
TRIMMING修剪阶段:如果当前不是dumb模式且这个测试用例没有被修剪过,调用trim_case函数对in_buf进行 修剪并复制到out_buf中
PERFORMANCE SCORE:在确定性模糊阶段前计算性能评分,并根据一些条件决定是否跳过确定性模糊阶段(对 于相同的输入和相同的程序执行环境,每次运行都会产生相同的输出)
•首先调用calculate_score计算性能评分,接着如果满足命令行参数-d被指定,当前测试用例被fuzz过,当 前测试用例之前通过确定性测试三者之一可以直接跳转到havoc_stage阶段(同时也会考虑到多个主实例的协 同关系,这里不展开),最后令doing_det=1表示正在进行确定性模糊测试。
SIMPLE BITFLIP (+dictionary construction)
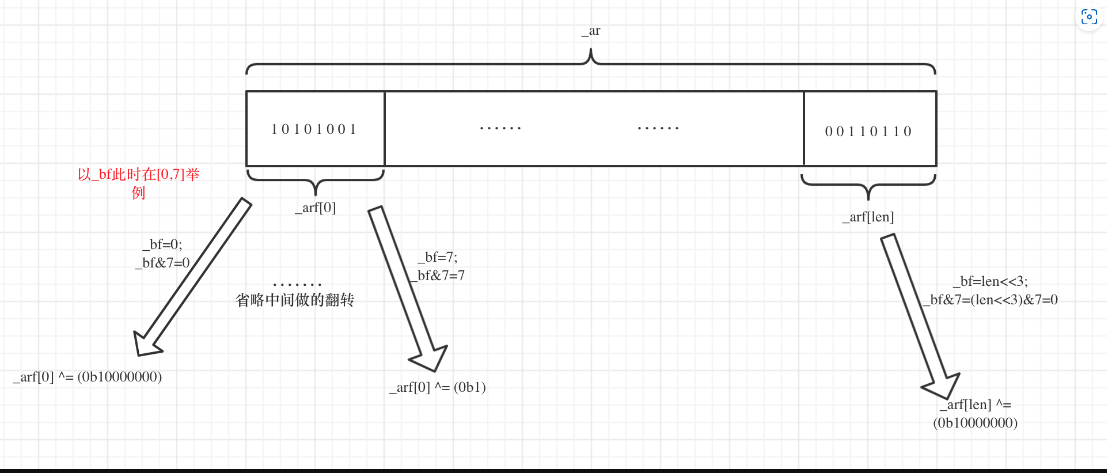
#define FLIP_BIT(_ar, _b) do { \ u8* _arf = (u8*)(_ar); \ u32 _bf = (_b); \ _arf[(_bf) >> 3] ^= (128 >> ((_bf) & 7)); \ } while (0)
这里定义了一个比较重要的函数:((_bf)>>3)^表示右移3位做异或,(_bf) & 7中后面一般是len长度,相当于模7,产生了(0,1,2,3,4,5,6,7),(128 >> ((_bf) & 7))就表示将128依次右移0-7个单位产生了二进制 (10000000-1)。
连起来理解,意思就是每8次为一个循环,128分别右移0、1、2、3、4、5、6、7位,将右移后的数字与 _arf[i]进行异或翻转,相当于每一位都进行一次翻转,如下图
Single walking bit
stage_short = "flip1"; //给当前阶段一个简短的标识符,即'flip1' stage_max = len << 3; //计算当前阶段的最大迭代次数,len是当前测试用例的长度 stage_name = "bitflip 1/1"; for (stage_cur = 0; stage_cur < stage_max; stage_cur++) { //每运行8次循环_arf(大小为一个字节)的下标+1 stage_cur_byte = stage_cur >> 3; FLIP_BIT(out_buf, stage_cur); if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry; FLIP_BIT(out_buf, stage_cur);
把这个阶段命名为"bitflip 1/1",for循环中把out_buf每8位分为一组且每一位都进行一次异或翻转,调用 common_fuzz_stuff进行fuzz,fuzz完毕后再调用FLIP_BIT翻转回来。
同时bit flip 1/1中对每个比特的最低位做特殊处理,收集符合条件的字符串添加到自动队列中。
•如果在处理两个相邻比特的最低位时发现执行路径发生变化,代表发现新的token,token可以理解成输入用 例的敏感部分,同时保证只有实际发生位翻转导致执行路径发生变化时,才将最低位添加到字符串中。
•当目前处于文件末尾且哈希值不变时,在满足一些特定条件时将其添加到自动队列中。
•a_collect是一个数组,用于保存可能成为token的字符串,a_len的作用记录正在收集的字符串的长度
stage_finds[STAGE_FLIP1] += new_hit_cnt - orig_hit_cnt; //flip1新发现的路径和crashes总和 stage_cycles[STAGE_FLIP1] += stage_max; //common_fuzz——stuff执行的次数
Two walking bits
stage_name = "bitflip 2/1"; stage_short = "flip2"; stage_max = (len << 3) - 1; //每次连续翻转这一位和下一位,所以要减一 orig_hit_cnt = new_hit_cnt; for (stage_cur = 0; stage_cur < stage_max; stage_cur++) { stage_cur_byte = stage_cur >> 3; FLIP_BIT(out_buf, stage_cur); FLIP_BIT(out_buf, stage_cur + 1); if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry; FLIP_BIT(out_buf, stage_cur); FLIP_BIT(out_buf, stage_cur + 1); } new_hit_cnt = queued_paths + unique_crashes; stage_finds[STAGE_FLIP2] += new_hit_cnt - orig_hit_cnt; stage_cycles[STAGE_FLIP2] += stage_max;
之前是每次翻转1bit就进行执行一次common_fuzz_stuff,现在变成每次连续翻转相邻的2bit执行一次 common_fuzz_stuff
Four walking bits:每次连续翻转4bit
Walk byte:这里开始以整数个byte为单位进行翻转,与上面按bit有些不同
•首先不采用flip_bit进行翻转,而是使用0xFF
•会定义一个effector map:在对一整个byte进行翻转时,如果执行路径和原始路径不一致,,就将该byte在 effector map中标记为1,可以理解为有效的,否则为0。可以理解为如果一整个byte被翻转后,依然无法造 成执行路径的改变,那么这个比特很大概率是不是metadata而是普通的data,对整个的fuzzing过程意义不 大,在后续的变异可以跳过,这里可以理解为是一次对文件格式的启发式判断。
•如果是dumb模式或者len太短,直接对执行路径整体取反,这样会使执行路径改变,从而令effector map为1
•当effector map密度过大时,会直接将整个eff_map都标记为1,即使不这样做,也不会省很多时间
Two walking bytes
if (len < 2) goto skip_bitflip; //长度小于2.跳转到skip_bitflip
if (!eff_map[EFF_APOS(i)] && !eff_map[EFF_APOS(i + 1)]) { //若相邻的两个bytes没有一个被标记为1,那么直接跳过这两个bytes继续遍历后面的 stage_max--; continue; //跳过当前循环的剩余代码,进入下一次循环 }
skip_bitflip: if (no_arith) goto skip_arith; //若设置了no_arith,可以跳过算数运算部分(ARITHMETIC INC/DEC),直接进入INTERESTING VALUES
Four walking bytes:和Two walking bytes类似,没有什么特殊。
ARITHMETIC INC/DEC
8-bit arithmetics
这部分是进行加减变异的,只对被eff_map标记为1的进行变异
for (j = 1; j <= ARITH_MAX; j++) { u8 r = orig ^ (orig + j); /* Do arithmetic operations only if the result couldn't be a product of a bitflip. */ if (!could_be_bitflip(r)) { stage_cur_val = j; out_buf[i] = orig + j; if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry; stage_cur++; } else stage_max--;
ARITH_MAX最大为35,就是对目标整数进行+1,+2,...,+35,-1,-2,...,-35的加减变异。同时有两种情况会 选择跳过这次变异。第一个是在eff_map中没有被标记为1的,第二个是变异后的结果与之前bitflip翻转后的结果一致时,就不会再执行fuzz。
16-bit arithmetics,both endians
for (j = 1; j <= ARITH_MAX; j++) { u16 r1 = orig ^ (orig + j), //j为1时异或后r1为1 r2 = orig ^ (orig - j), r3 = orig ^ SWAP16(SWAP16(orig) + j), //经过字节顺序翻转(SWAP16)后的异或运算结果 r4 = orig ^ SWAP16(SWAP16(orig) - j);
同时考虑了大端序和小端序
大端字节序:数据的高位字节存储在低地址,低位字节存储在高地址,考虑十六进制数'0xABCD',存储为'0xABCD'
小端字节序中,存储为'0xDCBA'
if ((orig & 0xff) + j > 0xff && !could_be_bitflip(r1)) { //检查是否发生了1byte以上的溢出
并且不是bitflip的产物 stage_cur_val = j; *(u16*)(out_buf + i) = orig + j; if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry; stage_cur++; } else stage_max--;
orig & 0xff 表示取 orig 的最低字节(低8位),这是为了忽略除最低字节外的其他字节的影响。这里为什么一定要大于1比特以上的溢出,猜测是因为对于位翻转来说,它只会影响单个位,而不会导致整个字节的变化,因此,为了确保发生的是更大范围的变化,代码限定了溢出必须至少是1字节,以增加测试的多样性和复杂性。
32-bit arthmetics,both endians:同上16 bits,同样对大端序和小端序都进行变异。
INTERESTING VALUES 替换变异
会实现存储一些特殊的数interesting_8,16,32这种用于接下来的替换
8/8 以字节为单位进行替换变异,考虑eff_map和冗余变换,之后进行fuzz
16/8 以两个字节为单位,去除之前的冗余,同时考虑大小端序(只有大于一个字节的单位时才需要考虑两种排序方法)
32/8 以四个字节为单位,原理同16/8
DICTIONARY STUFF
变异过程分为三部分:user extras(over),user extras(insert),auto extras(over)
user extras(over)覆盖阶段:将用户提供的extras[]数组以memcpy的方式替换到原文件中,会跳过一些特殊情况,比如extras_cnt>MAX_DET_EXTRAS,out_buf数组与extras相等等等,然后进行fuzz
user extras(insert)插入阶段:先分配内存空间,把extras.data中的数据复制到ex_tmp中,对新产生的ex_tmp进行fuzz。
auto extras(over):将另一个数组a_extras的data数据内容依次替换到原文件中,进行fuzz
截止到目前,已经完成了全部的deterministic fuzz
接下来的变异会充满随机性,对于dumb mode或者从fuzzer则会直接从这里开始
RANDOM HAVOC 随机毁灭阶段
充满了各种随机生成的变异,是对原文件的“大破坏”,包含很多轮。
case 0:随机选取某个bit进行翻转
case 1:随机选取某个byte,将其用随机的interesting value替换
case 2:随机选取某个word,将其设置为随机的interesting_16,大小端随机选择
case 3:随机选取某个dword,将其设置为随机的interesting_32,大小端随机选择
case 4:随机选取byte进行减变异
case 5:随机选取byte进行加变异
case 6:随机选取word进行减变异,大小端随机选择
case 7:随机选取word进行加变异,大小端随机选择
case 8:随机选取dword进行减变异,大小端随机选择
case 9:随机选取dword进行加变异,大小端随机选择
case 10:随机选择byte进行异或翻转
case 11-12:删除字节,希望使保留文件尽可能小
case 13:75%克隆+25%插入恒定字节插入
case 14:随机选取某个位置替换一段随机内容,这段内容75%是原来out_buf[]中的内容,25%是随机生成的一 段相同的数字(随机生成的数字中,50%是原来out_buf中的内容,50%是随机生成)
case 15:随机选取一个位置,用随机选取的extra token替换
case 16:随机选取一个位置,用随机选取的extra token插入
SPLICING拼接阶段
如果上述策略仍然没有发现新的发现,那么就会把当前的输入,随机选取另一个输入进行拼接,回到上一个havoc阶段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号