

0.mysql基础sql
常用的数据库sql语句,数据库相关的技术和理论是成体系的,从基础使用到数据库原理,到性能优化,海量数据处理,但不同的技术角色所需掌握的深度是不同的:
如果你是一位普通系统软件开发人员掌握基本sql操作、数据库索引、存储结构等也够用
如果你是一位高并发系统的架构设计与开发者,那海量数据的数据库处理、锁机制、数据库性能优化也得深入理解
如果你是数据库管理员,那处理以上的技术知识,数据库原理以及其中的算法理论自然必不可少
一、建表
直接以案例说明,当前创建一张student_info的表
1.1 表的创建
CREATE TABLE `student_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`stu_no` bigint(20) NOT NULL COMMENT '学生编号',
`sex` tinyint(2) DEFAULT NULL COMMENT '性别,1-男,2-女',
`enrollment_date` varchar(10) NOT NULL COMMENT '入学日期,YYYYMMDD',
`address` varchar(500) DEFAULT NULL COMMENT '住址',
`class` varchar(20) DEFAULT NULL COMMENT '所在班级',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`is_deleted` tinyint(2) NOT NULL DEFAULT '0' COMMENT '软删除:0-未删/1-已删',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_stu_no` (`stu_no`),
KEY `idx_enro_date` (`enrollment_date`),
KEY `idx_update_time` (`update_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='学生信息表'
相比于一般教程里的入门建表语句,这个表稍微复杂了点,当然实际开发中几十个字段的表比比皆是
以下是对建表语句中的相关语句进行说明
1.2 mysql中的字段类型
-
整数类型:
TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT。分别用于存储不同范围的整数值。 -
浮点数类型:
FLOAT、DOUBLE、DECIMAL。分别用于存储单精度浮点数、双精度浮点数和高精度小数。 -
字符串类型:
CHAR、VARCHAR、TEXT、BLOB。分别用于存储定长字符串、变长字符串、长文本和二进制数据。 -
日期时间类型:
DATE、TIME、DATETIME、TIMESTAMP。分别用于存储日期、时间、日期时间和时间戳。 -
枚举类型:
ENUM。用于存储预定义的枚举值。 -
集合类型:
SET。用于存储预定义的集合值。 -
布尔类型:
BOOLEAN、BOOL、TINYINT(1)。用于存储布尔值。
更详细的类型内容就不展开了,需要注意的是,不同的字段类型有不同的存储空间和取值范围,应根据实际需求选择合适的字段类型。
NOT NULL、DEFAULT用来约束该字段的取值内容。
1.3 索引、主键与唯一键
UNIQUE KEY 和 PRIMARY KEY 都是 MySQL 中用于定义表的键的关键字,它们的区别如下:
-
主键(
PRIMARY KEY)是一种特殊的唯一键,用于唯一标识表中的每一行数据。每个表只能有一个主键,主键列的值不能为空(NOT NULL)。主键可以由一个或多个列组成,但是一般情况下只使用一个列作为主键。主键可以用于建立表之间的关系,如外键约束等。 -
唯一键(
UNIQUE KEY)用于保证表中某一列或多列的值唯一。每个表可以有多个唯一键,唯一键列的值可以为空(NULL)。唯一键可以由一个或多个列组成,唯一键列的值不能重复,但是可以有多个 NULL 值。 -
普通索引(
KEY):用于加速查询操作,可以由一个或多个列组成。普通索引可以在查询中使用,但不强制要求列的值唯一。
主键是特殊的唯一键,唯一键是特殊的索引。
主键和唯一键的区别在于,主键是一种特殊的唯一键,用于唯一标识表中的每一行数据,而唯一键只是保证表中某一列或多列的值唯一。
主键列的值不能为空,而唯一键列的值可以为空。主键可以用于建立表之间的关系,而唯一键不能。
综上所述,主键和唯一键都可以用于保证表中某一列或多列的值唯一,但是主键是一种特殊的唯一键,用于唯一标识表中的每一行数据,而唯一键只是保证表中某一列或多列的值唯一。
1.4 数据库引擎与字符集
-
ENGINE=InnoDB:这里在建表时指定InnoDB引擎,这也是当前Mysql默认的存储引擎 -
DEFAULT CHARSET=utf8mb4
MySQL数据库中的一种字符集设置,用于指定数据库、表或列的字符集,utf8mb4是一种字符集,支持Unicode编码,可以存储包括Emoji表情在内的各种字符。
在MySQL数据库中,字符集是指用于存储和处理文本数据的编码方式。如果不指定字符集,MySQL默认使用Latin1字符集,只能存储ASCII码范围内的字符,无法存储中文、日文、韩文等非ASCII字符。
因此,为了支持更广泛的字符集和多语言环境,需要在创建数据库、表或列时指定字符集。在MySQL 5.5.3及以上版本中,推荐使用utf8mb4字符集,以支持更广泛的字符范围。 -
COLLATE=utf8mb4_bin
MySQL数据库中的一种排序规则设置,用于指定数据库、表或列的排序规则。其中,utf8mb4_bin是一种排序规则,它区分大小写,按照二进制编码进行排序。
在MySQL数据库中,排序规则是指用于比较和排序文本数据的规则。如果不指定排序规则,MySQL默认使用utf8mb4_general_ci排序规则,它不区分大小写,忽略了一些特殊字符的差异,可能会导致一些不符合预期的排序结果。
因此,为了避免这种情况,需要在创建数据库、表或列时指定排序规则。在MySQL 5.5.3及以上版本中,推荐使用utf8mb4_bin排序规则,以保证排序的准确性和一致性。
1.5 建表的建议
-
指定字符集和排序规则:推荐使用utf8mb4字符集和utf8mb4_bin排序规则。
-
选择合适的数据类型:数据的实际需求选择合适的数据类型,避免浪费存储空间和影响查询效率。例如,对于较小的整数可以使用TINYINT或SMALLINT类型,对于较大的整数可以使用BIGINT类型。
-
添加索引:在表中添加索引可以提高查询效率,但也会增加写入数据的时间和空间开销。应该根据实际需求选择合适的索引类型和字段,避免过多或不必要的索引。
-
设计合理的表结构:在设计表结构时,应该遵循范式设计原则,尽量避免冗余和重复的数据,以提高数据的存储效率和查询效率。
二、表操作
对于表中记录的操作当然是增删改查,当然查询是贯穿在所有指令中的,也就删表删库操作不需要
1. INSERT
--插入包含字符串类型的值,需要使用单引号将其括起来
--插入日期类型的值,需要使用日期函数将其转换为日期类型
--插入的数据中包含自增长列,可以使用 NULL 值或者不指定该列的值,MySQL 会自动为该列生成一个唯一的值
INSERT INTO table_name (column1, column1, column1, ...) VALUES (value1, value1, value1, ...);
2. UPDATE
--UPDATE 语句可能会影响到多行数据,需要确保更新的条件正确,否则可能会导致更新错误的数据
UPDATE table_name SET column1=value1, column2=value2, ... WHERE condition;
3. DELETE
--可能会影响到多行数据,需要确保删除的条件正确,否则可能会导致删除错误的数据
DELETE FROM table_name WHERE condition;
4. DROP
DROP 语句用于删除数据库、表或索引,而DELETE是删除数据表中记录
--删除数据库
DROP DATABASE 数据库名;
--删除表
DROP TABLE 表名;
--删除索引
DROP INDEX 索引名 ON 表名;
5. TRUNCATE
--用于删除表中的所有数据,但保留表的结构,其本质是先删除表,再执行当前的建表语句
--TRUNCATE 比 DELETE 语句更快,因为它不会通过binlog日志记录删除的每一行,而是直接删除整个表
--因此 TRUNCATE 语句无法回滚,因此需要确保清空数据的操作是正确的
TRUNCATE TABLE 表名;
6. ALTER
ALTER 语句用于修改表的结构,包括添加、修改和删除列,修改列的数据类型、长度、默认值等。
-- 表中新增列
ALTER TABLE `表名` ADD COLUMN `列名` varchar(256) NOT NULL COMMENT 'xxxx';
-- 表中删除列
ALTER TABLE `表名` DROP COLUMN `列名`;
-- 表中字段相关属性修改
ALTER TABLE `表名` MODIFY `列名` varchar(256) NOT NULL COMMENT 'xxxx';
-- 表中列名修改
ALTER TABLE `表名` CHANGE `旧列名` `新列名` varchar(256) NOT NULL COMMENT 'xxxx';
索引相关:
-- 表中新增索引
ALTER TABLE `表名` ADD INDEX `索引名` (`列名1`,`列名2`)
-- 表中新增唯一索引
ALTER TABLE `表名` ADD UNIQUE KEY `索引名` (`列名1`,`列名2`)
-- 删除已有索引
ALTER TABLE `表名` DROP INDEX `索引名`;
三、单表查询
3.1 常规查询
--多列查询
SELECT column1, column2, ... FROM table_name WHERE condition;
--空值查询
--不能使用=运算符判断一个值是否等于NULL,因为在MySQL中,NULL不是一个值,而是一个特殊的标记,表示缺少值,而应该使用IS NULL运算符。
SELECT column1, column2, ... FROM table_name WHERE column_name IS NULL;
--通配符*
--表中所有列查询,除非你确实需要表中的每个列,否则最好别使用*通配符。
--虽然使用通配符可能会使你自己省事,不用明确列出所需列,但检索不需要的列通常会降低检索和应用程序的性能。
SELECT * FROM table_name WHERE condition;
--DISTINCT关键字只能用于查询语句中的第一个SELECT关键字之后,不能用于子查询中
SELECT DISTINCT column1, column2, ... FROM table_name WHERE condition;
--LIMIT关键字用于限制查询结果的行数,可以指定查询结果的起始位置和行数,以下的sql指定返回从查询结果的第10行开始之后的100条记录,即11~110
SELECT column1 FROM table_name WHERE condition LIMIT 10, 100;
--ORDER BY关键字默认按照升序排序,可以使用DESC关键字指定降序排序
--尽量避免使用SELECT *,选择需要的字段进行查询并排序
--使用LIMIT,它必须位于ORDER BY之后
SELECT column1, column2, ... FROM table_name WHERE condition ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
--AND和OR
--在处理OR操作符前,优先处理AND操作符,所以想优先处理OR的话,使用圆括号明确地分组相应的操作符
SELECT column1, column2, ... FROM table_name WHERE (condition1 OR condition2) AND condition3;
3.2 分组查询
MySQL 的分组查询是指对表中的数据按照指定的列进行分组,通常还会对每个分组进行聚合计算,返回每个分组的计算结果。常用的聚合函数包括 COUNT、SUM、AVG、MAX、MIN 等。
--aggregate_function为聚合函数包括 COUNT、SUM、AVG、MAX、MIN 等
--HAVING 子句用于对分组后的结果进行筛选,
SELECT column1, column2, ..., aggregate_function(column)
FROM table_name
WHERE condition
GROUP BY column1, column2, ...
HAVING condition
ORDER BY column1, column2, ... ASC|DESC;
-
WHERE 关键字用于在查询之前对表中的数据进行筛选,它可以用于过滤行,只返回符合条件的行。WHERE 关键字只能用于对列进行筛选,不能用于对聚合结果进行筛选。
-
HAVING 关键字用于在查询之后对分组结果进行筛选,它可以用于过滤组,只返回符合条件的组。HAVING 关键字只能用于对聚合结果进行筛选,不能用于对列进行筛选。
因此,WHERE 关键字用于过滤行,HAVING 关键字用于过滤组,它们的作用范围不同。
查询案例说明:
一个学生表 student_info,包含 id、name、age 和 score 四个字段,我们想要统计每个年龄段的学生人数和平均分数,并只返回平均分数大于 80 分的年龄段
SELECT age, COUNT(*) AS count, AVG(score) AS avg_score
FROM student_info
GROUP BY age
HAVING AVG(score) > 80;
常用聚合函数
下面是常用的聚合函数及其作用:
- COUNT(column):统计指定列的行数,如果不指定列,则统计所有行的行数。
- SUM(column):计算指定列的总和。
- AVG(column):计算指定列的平均值。
- MAX(column):计算指定列的最大值。
- MIN(column):计算指定列的最小值。
聚合函数只能用于数值类型的列,如果对非数值类型的列使用聚合函数,会返回错误。
聚合函数还可以与 DISTINCT 关键字一起使用,用于统计不重复的值。例如,COUNT(DISTINCT column) 表示统计指定列中不重复的值的个数。
四、多表联合查询
- 多表联合的查询其sql远比单表复杂的多,毕竟从一维上升到了多维,但如果梳理清楚各表之间的联系,再将相关sql进行分解,其本质也就是单表查询之间通过表间字段的关联进行联合查询,当表的数量、相关字段和关联关系不断增加时,联合查询的复杂度也会同步增加。
- 单表查询中的所有操作都可在多表查询中使用
4.1 子查询
- 子查询本质也就是将一个查询结果作为另一个查询的条件,表现在sql语句中就是一个SQL语句中嵌套另一个SQL语句。
- 子查询可以嵌套多层,可以用于SELECT、UPDATE、DELETE、INSERT等语句中。
- 子查询的语句可以在sql语句的多处地方使用,如SELECT、FROM、WHERE、HAVING中
1. 在SELECT语句中使用子查询
--SELECT语句中使用子查询时,子查询通常是作为一个列的值返回,必须确保它只返回一行结果,返回多行会报错
--所以这的column2仅仅是一个结果值附加在对table1查询到的column1之后
SELECT column1, (SELECT column2 FROM table2 WHERE table1.id = table2.id) AS column2 FROM table1;
2. 在FROM语句中使用子查询
--将子查询的结果作为一个虚拟表(或称为派生表)来使用,这也是平时常用的子查询
--在FROM中子查询时,必须给虚拟表指定一个别名,否则mysql会报错
SELECT column1, column2
FROM (SELECT column1, column2 FROM table1 WHERE column1 >= 10) AS t1;
3. 在WHERE语句中使用子查询
--根据子查询的结果来过滤数据,这里的子查询结果是你用来筛选数据的条件
--IN作为筛选条件时子查询可以返回多个结果,但>、<、=这些条件的话要注意子查询只能返回一个结果
SELECT column1, column2
FROM table1
WHERE column1 IN (SELECT column1 FROM table2 WHERE column2 = 'value');
4. 在HAVING语句中使用子查询
--和在WHERE中使用类似
SELECT column1, COUNT(column2) AS count
FROM table1
GROUP BY column1
HAVING COUNT(column2) > (SELECT AVG(count) FROM (SELECT COUNT(column2) AS count FROM table1 GROUP BY column1) AS t1);
5. 在INSERT语句中使用子查询
--子查询的结果集可以看成是一张虚拟表,自然也可以将其中的记录插入其他表,当然其字段类型肯定要符合插入表的要求
INSERT INTO table1 (column1, column2)
SELECT column1, column2 FROM table2 WHERE column1 >= 10;
4.2 联合查询
- MySQL的联合查询(UNION)是一种将多个SELECT语句的结果集合并成一个结果集的方法。
- 联合查询可以用于将多个表中的数据合并在一起,或者将同一表中的不同条件的数据合并在一起。
- 联合查询和子查询看上去都是对多个表的查询,但其实它们有各自适用的查询领域,如果需要将多个表或多个条件的查询结果合并在一起,可以使用联合查询;如果需要在一个查询中嵌套另一个查询来过滤、排序或聚合数据,可以使用子查询。
--将两个或多个 SELECT 语句的结果集合并成一个结果集,并去除重复的行
--两个 SELECT 语句的列数和数据类型必须相同
--UNION 操作符会对结果集进行排序和去重,因此可能会影响查询的性能
SELECT column1 FROM table1
UNION
SELECT column2 FROM table2
4.3 连接查询
- 其语法的关键字是
JOIN用于指定要连接的表,包括INNER JOIN、LEFT JOIN和RIGHT JOIN等,ON关键字用于指定连接条件
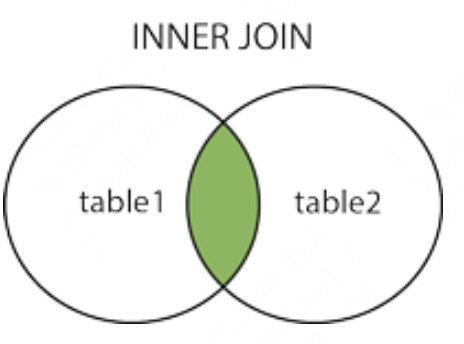
1. INNER JOIN
内连接,或等值连接:获取两个表中字段匹配关系的记录,是最常用的JOIN类型
--使用时也可以省略 INNER 使用 JOIN,效果一样
--它返回两个表中匹配的行,如果两个表中没有匹配的行,则不返回任何结果
--使用时,需要确保连接条件的正确性和唯一性,否则可能会导致查询结果不正确
SELECT column1 FROM table1 INNER JOIN table2 ON table1.column1 = table2.column2;
表现为两表的交集:
2. LEFT JOIN
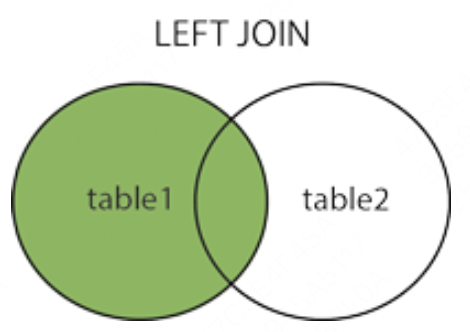
左连接:获取左表所有记录,即使右表没有对应匹配的记录
SELECT column1 FROM table1 LEFT JOIN table2 ON table1.column1 = table2.column2;
3. RIGHT JOIN
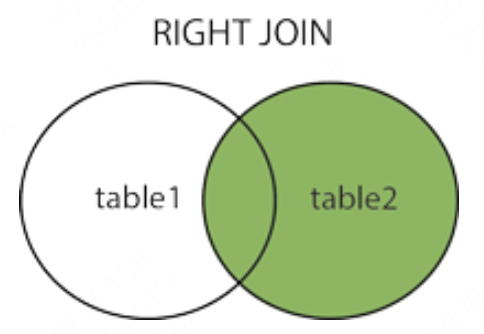
右连接: 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
SELECT column1 FROM table1 RIGHT JOIN table2 ON table1.column1 = table2.column2;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号