

进入python的世界_day20_python基础——正则表达式、re模块
一、正则表达式
- 简介
一种独立的技术,主要是为了按照设置的规则来匹配字符串,所有编程语言都可以用,爬虫用的最多。
一个好用的正则小网址
www.tool.chinaz.com/regex
二、正则表达式——字符组
- [...] 用来表示一组字符,可以缩写 ,默认或的关系
eg : [1,2,3,4,5] >>>[1-5]
注意 :每一个元素都会比,比到找到就匹配到
三、正则表达式——量词
1.介绍
量词不能单独出现,并且只影响左贴着的表达式
2.常用量词
| 量词形式 | 描述 |
|---|---|
| * | 匹配0个或者多个的表达式 |
| + | 匹配要么一次要么全要 |
| ? | 作为量词意义不大,主要用于非贪婪 |
| 精确匹配n个前面跟着的表达式(类似计数,数目到了才匹配) | |
| 匹配n到m个前面跟着的表达式 | |
| 匹配n到无穷个前面跟着的表达式 |
四、正则表达式———特殊符号
| 特殊符号形式 | 描述 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母、数字、下划线 |
| \W | 匹配非字母、数字、下划线 |
| \s | 匹配任意空白字符 (同理\S匹配任意非空字符) |
| \d | 匹配数字等价与[0-9] |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾 |
| a | b | 匹配a或者b |
| ( ) | 给正则表达式分组 |
| [^] | [^abc]匹配除了a,b,c之外的字符 |
比如腾讯QQ号:
[1-9]([0-9]{5,11})
意思前面一位,后面五位或者11位,最长12位
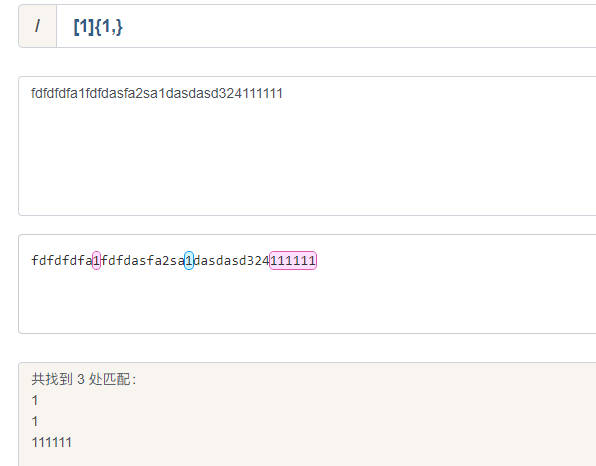
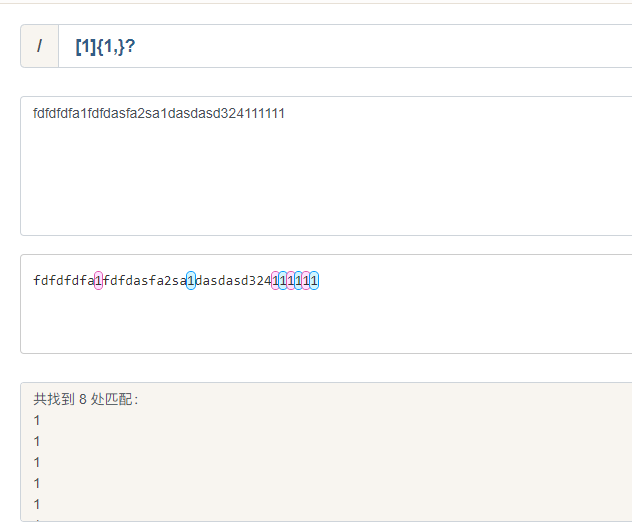
五、贪婪匹配与非贪婪匹配
- 量词默认都是贪婪匹配,如果要非贪婪,要在量词后跟一个英文问号
六、转义符
"""斜杠与字母的组合有时候有特殊含义"""
\n 不识别 因为默认是换行符
\\n 取消特殊身份,匹配的是文本\n
\\\\n 匹配的是文本\\n
ps:如果是在python中使用 还可以在字符串前面加r取消转义
七、re模块
import re
1.re.findall('正则','数据')
# 匹配字母、数字、下划线
print(re.findall('\w','aAbc123_*()-='))
# ['a', 'A', 'b', 'c', '1', '2', '3', '_']
# 匹配字符串的开头
print(re.findall('^hua','hua alex ikun'))
# ['hua']
2.re.finditer()
# 类似迭代器对象,造工厂,节省内存空间
3.re.search()
# 只找到符合的就停止,要看结果的话要用.group打印
4.re.match()
# 只看待找对象的开头,有就匹配一个,无就返回none
5.xx = re.compile()
# 把某一个正则赋值给一个变量,可以应对日后的频繁使用该正则
6.re.sub('正则','替换','数据','个数')
7.re.subn()
# 同上,返回元组,并告诉替换了几次
补充:
1.分组优先
()内容默认是优先展示的
可以加?:
(?:)这样就取消优先展示
2.分组别名
res = re.search('www.(?P<content>baidu|oldboy)(? P<hei>.com)', 'www.oldboy.com')
print(res.group()) # www.oldboy.com
print(res.group('content')) # oldboy
print(res.group(0)) # www.oldboy.com
print(res.group(1)) # oldboy
print(res.group(2)) # .com
print(res.group('hei')) # .com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号