


进入python的世界_day11_python基础——函数之参数、名称空间
一、位置参数
-
位置形参
函数定义阶段(函数定义第一行)括号内从左往右,依次填写变量名
-
位置实参
函数调用阶段括号内从左往右,依次填写传入的数据值
""" 1.位置形参与位置实参在函数调用时, 按照位置一一对应绑定 2.多一个不行少一个也不行(后面会讲优化,但是也是先设置好形参的内容) 3.格式越简单的越靠前 格式越复杂的越靠后 """ -
关键字实参
函数调用阶段,指定数据值绑定给形参名
!!!关键字实参要跟在位置实参后面
例如: a = 666 b = 777 def test(x, y): print(x, y) test(x = a, y =b) >>>666 777 _________________ test(x = a, 111) >>> SyntaxError: positional argument follows keyword argument!
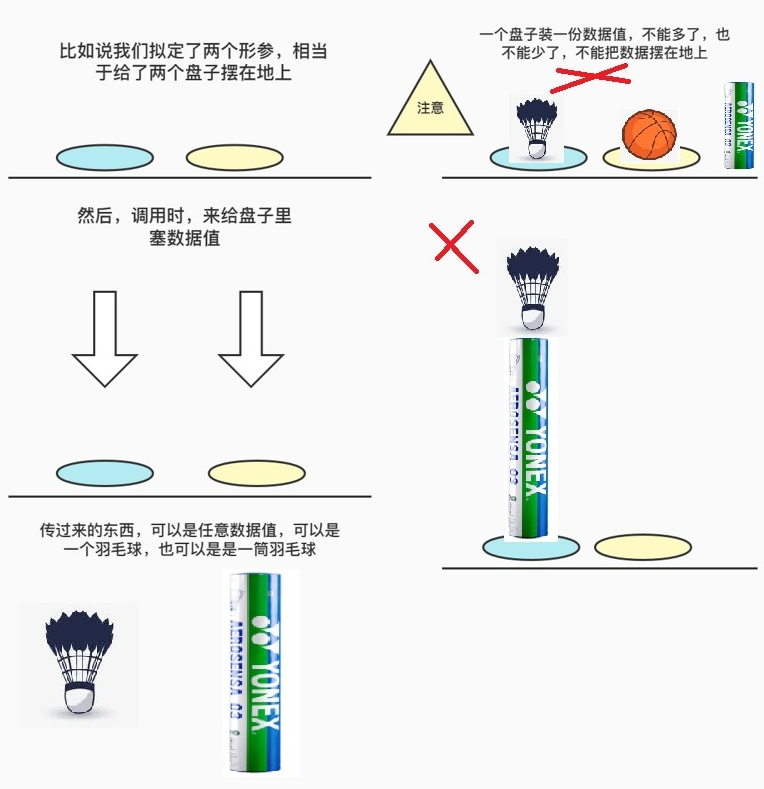
二、默认参数
-
含义
函数定义阶段赋值某变量名值为啥啥啥,这样就定下了这个值的默认数据值,如果后续接受实参时对面没说该值为他他他,那就默认值为啥啥啥
-
演示
例: def info(name, age, city='changsha'): print('%s %s %s' % (name, age, city)) info('nike', 18) >>> nike 18 changsha ———————————————————— info('nike', 18, 'beijing') # 用pycharm时,代码栏上方小光标会提醒 >>> nike 18 beijing -
注意
同样得遵循位置形参优先原则、越简单越靠前原则
三、可变长参数
上述方法传参时都得小心翼翼,一个不留神个数对不上就报错,就很麻 烦,所以有没有办法让函数接受不管多少位置参数或者关键字参数都可以运行
-
可变长形参
-
单一个*
把除开位置参数一一对应的数据值后剩下的数据值打包成一个元组赋值给*后面带的变量名
例1: def fun(*c): print(c) fun(111222) >>> (111222,) # 以前讲过,元组内部就算只有一个数据,也推荐加, ______ fun(111222,666) >>> (111222, 666) ______________________ 例2: def fun(a, b, *c): print(a, b, c) fun(666,777,888) >>> 666 777 (888,) ______ fun(666, 777, 888, 999, ['嘿嘿嘿!', 111]) >>> 666 777 (888, 999, ['嘿嘿嘿!', 111]) # 位置参数的个数对应后剩下的都是*c的-
双* ——**
把除开关键字参数一一对应的数据值后剩下的数据值打包成一个字典赋值给**后面的变量名
例1: def fun(**c): print(c) fun(age = 11) >>> {'age': 11} ______ fun(age = 11, name = 'nike', hooby = 'music') >>> {'age': 11, 'name': 'nike', 'hooby': 'music'} _________________ 例2: def fun(a, b, **c): print(a, b, c) fun() >>> 报错!说没有东西填入a b位置 ——————— fun('happy', 'fun', age = 11, name = 'nike', hooby = 'music') >>> happy fun {'age': 11, 'name': 'nike', 'hooby': 'music'}-
既用*又用**
怎么传位置参数数据值和关键字参数数据值都不影响函数运行
例: def fun(*a, **c): print(a,c) fun(11, 22, 33) # 不给关键字参数数据值就没东西给**c >>> (11, 22, 33) {} ____________ fun(11, 22, 33,name = 'nike', hobby = ['song', 'dance','rap']) >>> (11, 22, 33) {'name': 'nike', 'hobby': ['song', 'dance', 'rap']}-
推荐星号后面的变量名命名
在设置可变长形参 *与**时,后面的变量名其实写啥都行,但是推荐使
用args 和kwargs,pycharm也会智能的提醒,tab快捷按下就可以打全了
像上面的def fun(*a, *c) 最推荐的写法
>>def fun(*args, **kwargs)
-
-
可变长实参
-
实参中单一个*
会将列表、元组内的元素打散成位置参数的形式一一传值,字典会取K拿,集合会随机拿数据
例1: def fun(a, b, c): print(a, b, c) fun([11,22,33]) >>> 报错 #按照位置参数给的数据值数量不对,列表被看成一个数据值 —————————— fun(*[11,22,33]) >>> 11 22 33 __________ fun(11,22,*[11,22,33]) >>> 报错 #给多了,给了五个数据值,量不对 ———————————————————————————— 例2: def fun2(x, *args): print(x, args) new_list1 = [11, 22, 33, 44, 55] fun2(*new_list1) # 相当于fun2(11, 22, 33, 44, 55) >>> 11 (22, 33, 44, 55)-
实参中两个*
会将字典内的键值对打散成关键字(所以得留意关键字要对上!不然报错)参数传入,集合不能用,元组也不能用
例1: def fun3(a, b, c): print(a, b, c) dict1 = {'name':'nike','pwd':666,'city':'changsha'} fun3(**dict1) >>> 报错!! 因为a 和name键对不上 —————————————————— def fun3(name, pwd, city): print(name, pwd, city) dict1 = {'name':'nike','pwd':666,'city':'changsha'} fun3(**dict1) #相当于(name ='nike',pwd = 666,city = 'changsha') >>> nike 666 changsha -
四、名称空间
-
介绍
变量值创建时占用内存空间的一块地,在给这个内存空间绑定给一个变量名时内存空间中又会占用一块地放变量名(带绑定关系),存放变量名(带绑定关系)的地儿就是名称空间
-
名称空间的分类
-
内置名称空间
>>>python解释器已经定义好了的,直接拿着就可以用,我们没法对这块名称空间动手改动,作用范围为解释器级别的全局
-
全局名称空间
>>>打开一个py文件,在该py文件内顶格编写的代码(运行后)都存进全局名称空间,作用范围为该py文件全局
!!!注意,该空间只能适用于该py文件,创建另外的py文件不适用
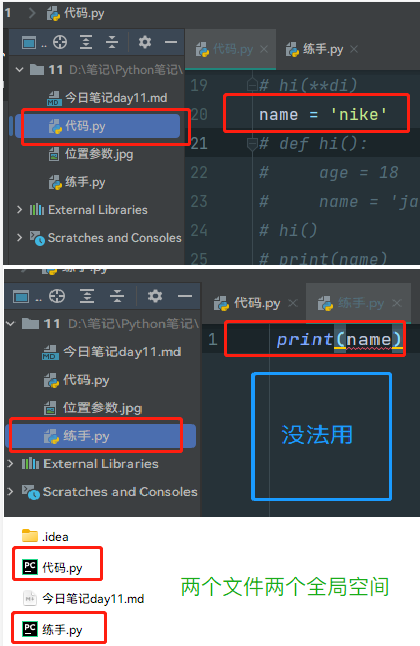
-
局部名称空间
>>>函数体代码运行后产生的都是局部名称空间,作用范围为该函数体
-
-
名称空间的存活周期(好理解)
-
内置名称空间
python解释器启动与关闭而创建和销毁
-
全局名称空间
随着py文件的运行与结束而创建和销毁
-
局部名称空间
随着函数体代码的执行与结束而创建和销毁
-
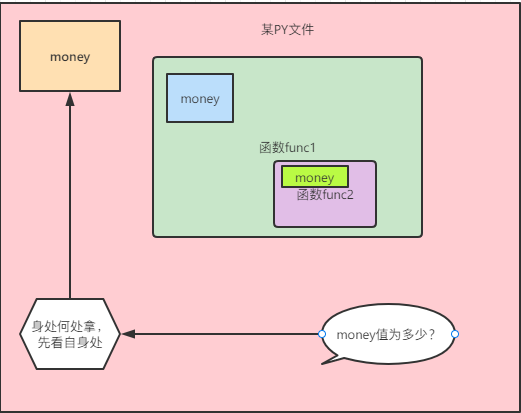
五、名字查找顺序
-
一个原则
身在何处,何处为最先查找顺序,然后按小到大往外查序
-
两个不能
1.局部名称空间独立,不能互相串门 ,每层级相同名称变量名独立存在
2.每层名称空间中没有给名称赋值前,不能对该名称进行操作
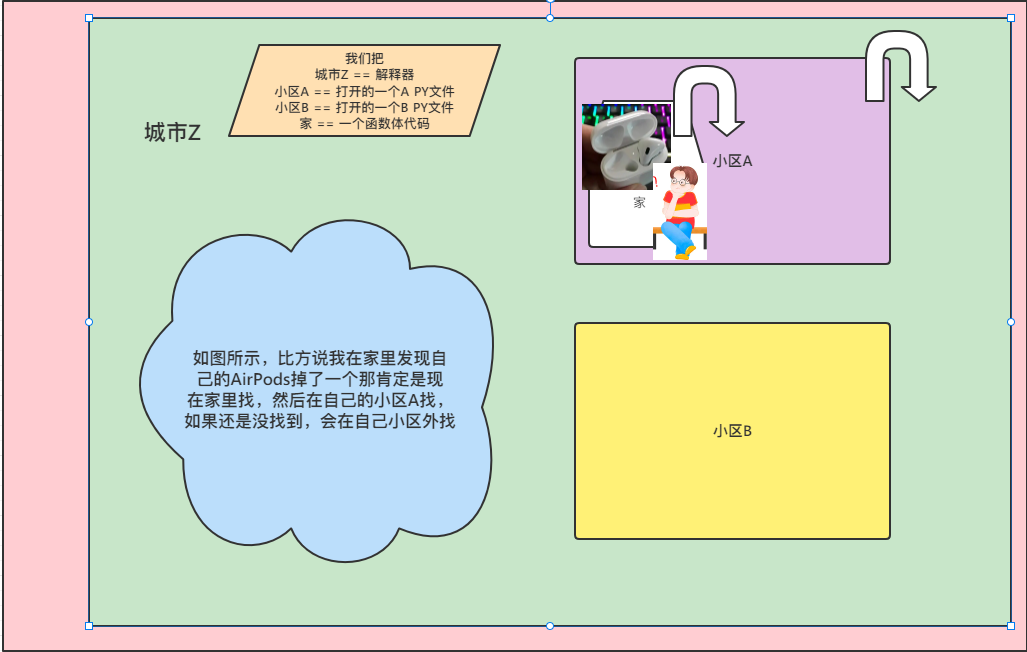
!!!上图逻辑其实不合理如果是在小区内发现airpods掉了,直接默认不在家里找(比如说出门上班时还没掉下班回来在小区内发现掉了这种意思)
六、作业
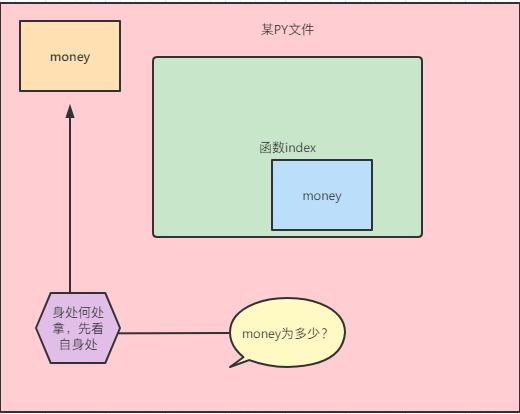
1.判断下列money的值是多少并说明理由 思考如何修改而不是新增绑定关系(这个要用破界函数,明天会学)
money = 100
def index():
money = 666
print(money)
——————————————————————————————
money = 100
def func1():
money = 666
def func2():
money = 888
func2()
print(money)
七、补充两个函数嵌套实例
例1:
def max(x,y):
return x if x > y else y
def max4(a,b,c,d):
res1=max(a,b)
res2=max(res1,c)
res3=max(res2,d)
return res3
print(max4(1,2,3,4))
>>>
4 # 可以理一下得到4这个结果的原理 一步步来
例2:
max=1
def f1():
max=2
def f2():
max=3
print(max)
f2()
f1()
print(max)
>>>
3
1 # 为什么两个结果?想一下 代码倒数第二行,说明执行了一次函数f1(),执行过程中,又套用了一次f2()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号