
网络爬虫爬取微博热搜榜标题
安装相应所需的第三方库,在网页上找到微博热搜榜,用F12找到标题的位置:td-02
最终爬取结果: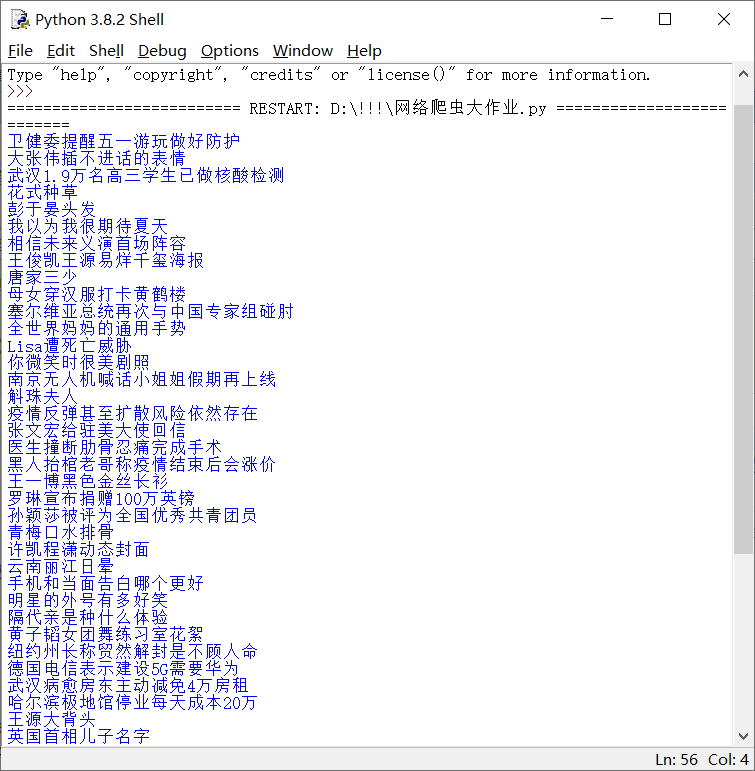
源代码:
import requests
from bs4 import BeautifulSoup
import bs4
url = "https://s.weibo.com/top/summary?cate=realtimehot"
def getHTMLText(url):
try:
kv={"User-Agent":"Mozilla/5.0"}
r = requests.get(url, headers=kv, timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "error"
html = getHTMLText(url)
soup=BeautifulSoup(html,'html.parser')
sou = soup.find_all("td",class_='td-02')
name = []
for x in sou:
print(x.a.string)
在最后附上漏了的第二次作业: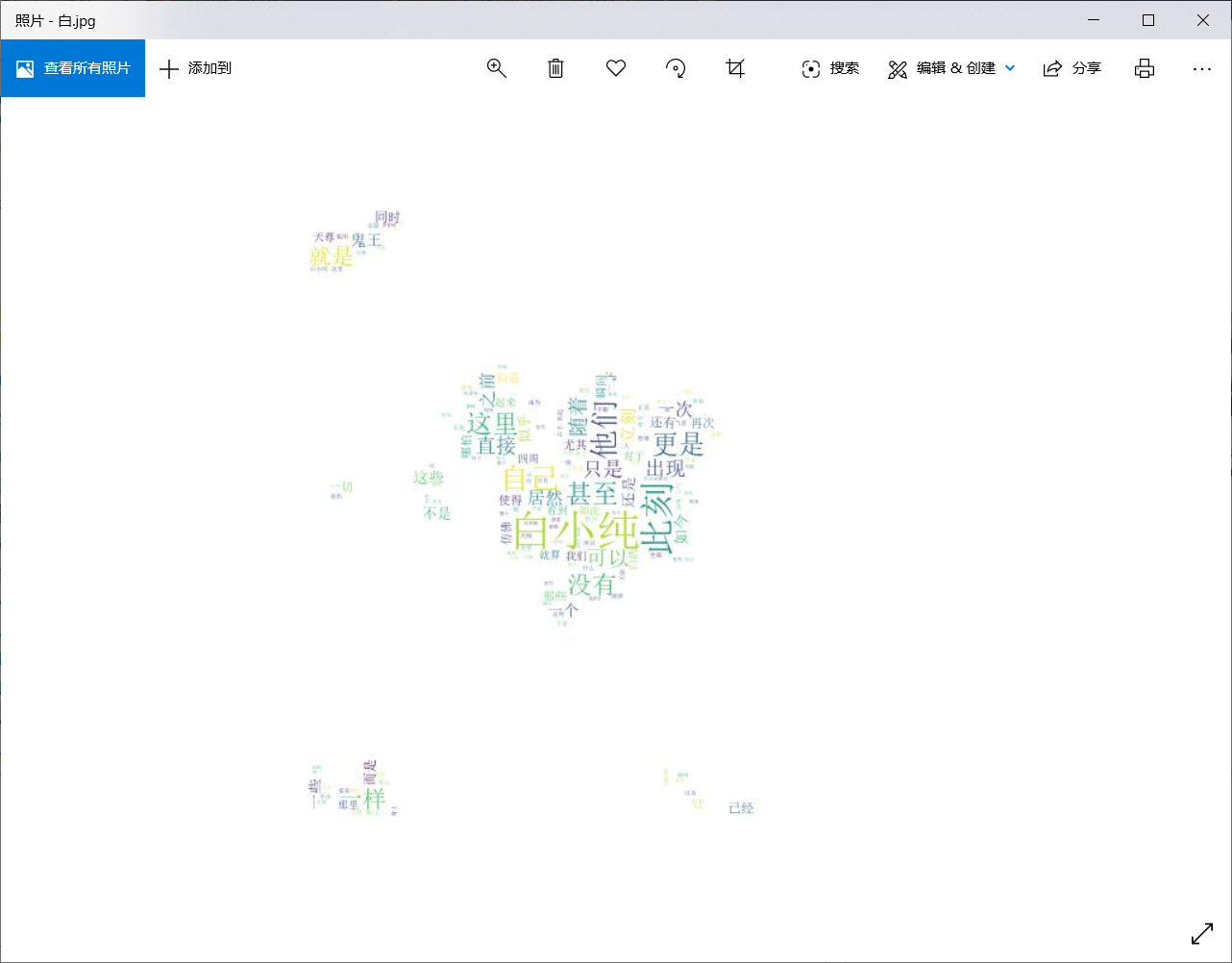 代码:
代码:
import jieba
import wordcloud
import imageio
m=imageio.imread('王冠.jfif')
#w=wordcloud.WordCloud(mask=m)
w=wordcloud.WordCloud(width=800,
height=600,
background_color='white',
font_path='simsun.ttc',
mask=m)
f=open('一念永恒.txt',encoding='utf-8')
txt=f.read()
txt1=jieba.lcut(txt)
s=" ".join(txt1)
w.generate(s)
w.to_file('白.jpg')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号