ApacheFlink简介
对无界数据集的连续处理
在我们详细介绍Flink之前,让我们从更高的层面上回顾处理数据时可能遇到的数据集的类型以及您可以选择处理的执行模型的类型。这两个想法经常被混淆,清楚地区分它们是有用的。
首先,两种类型的数据集
- 无界:连续追加的无限数据集
- 有界:有限的,不变的数据集
传统上被认为是有限或“批量”数据的许多实际数据集实际上是无界数据集。无论数据是存储在HDFS上的目录序列还是像Apache Kafka这样的基于日志的系统中,都是如此。
无界数据集的例子包括但不限于:
- 最终用户与移动或Web应用程序进行交互
- 物理传感器提供测量
- 金融市场
- 机器日志数据
其次,有两种执行模式
- 流式传输:只要数据正在生成,就会连续执行的处理
- 批处理:在有限的时间内执行处理并运行完成,完成后释放计算资源
尽管不一定是最佳的,但可以用任何一种类型的执行模型来处理任一类型的数据集。例如,尽管在窗口化,状态管理和无序数据方面存在潜在的问题,批处理执行早已应用于无界数据集。
Flink依赖流式执行模型,这是一个直观的适合处理无界数据集的模型:流式执行是连续处理连续产生的数据。数据集类型与执行模型类型之间的对齐在准确性和性能方面提供了许多优点。
特点:为什么Flink?
Flink是一个分布式流处理的开源框架:
- 提供准确的结果,即使在无序或迟到数据的情况下也是如此
- 是有状态和容错的,可以在保持一次性应用程序状态的同时无缝地从故障中恢复
- 大规模执行,在数千个节点上运行,具有非常好的吞吐量和延迟特性
此前,我们讨论了将数据集的类型(有界还是无界)与执行模型的类型(批量与流媒体)进行对齐。下面列出的许多Flink功能 - 状态管理,无序数据的处理,灵活的窗口 - 对于在无界数据集上计算精确的结果非常重要,并且由Flink的流式执行模型来实现。
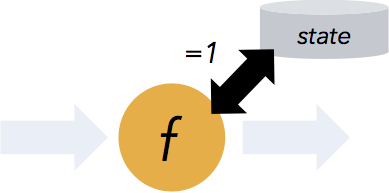
- Flink保证有状态计算的一次语义。“有状态的”意味着应用程序可以维护一段时间内已经处理的数据的汇总或汇总,并且Flink的检查点设置机制在发生故障时确保应用程序状态的一次语义。
- Flink支持流处理和窗口事件时间语义。事件时间可以轻松计算事件到达顺序不正确,事件可能延迟到达的流的精确结果。
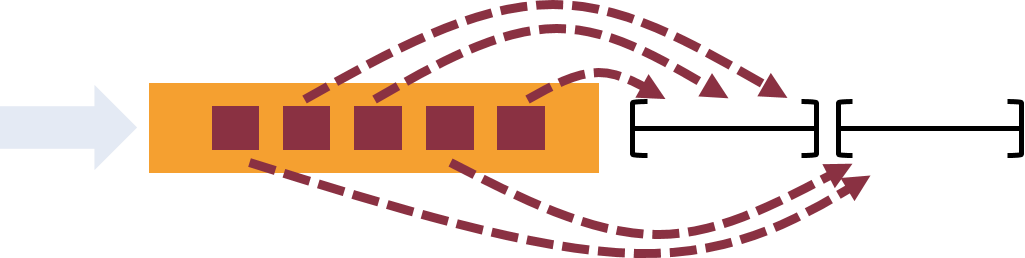
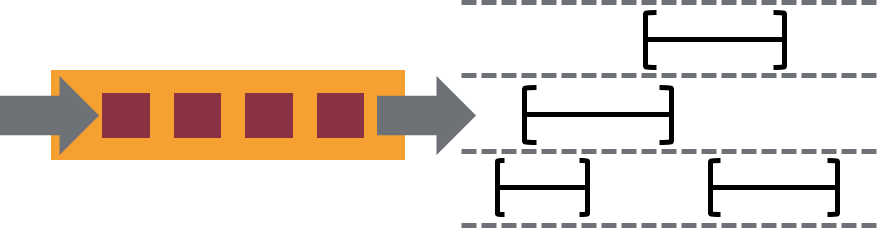
- 除了数据驱动的窗口,Flink还支持基于时间,计数或会话的灵活窗口。Windows可以通过灵活的触发条件进行定制,以支持复杂的流模式。Flink的窗口可以模拟数据创建环境的实际情况。
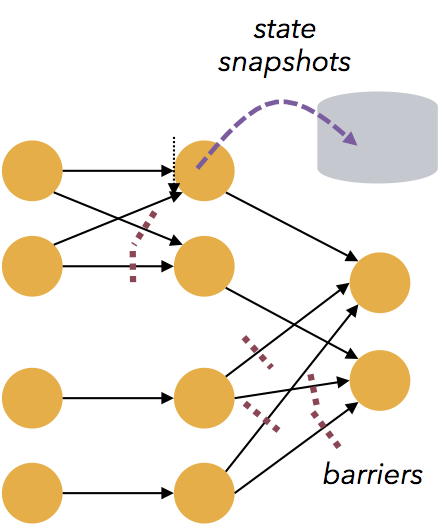
- Flink的容错功能是轻量级的,可以让系统保持高吞吐率,同时提供一次性一致性保证。Flink从零数据丢失的故障恢复,而可靠性和延迟之间的折衷可以忽略不计。
- Flink能够提供高吞吐量和低延迟(快速处理大量数据)。下面的图表显示了Apache Flink和Apache Storm的性能,完成了需要流式数据混洗的分布式项目计数任务。
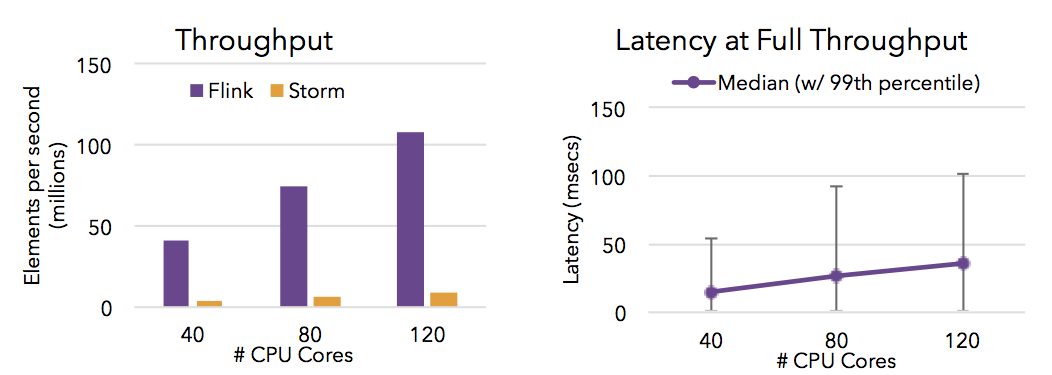
- Flink的保存点提供了一个状态版本管理机制,可以更新应用程序或重新处理历史数据,而且不会丢失状态,停机时间最短。
- Flink设计用于在数千个节点的大型集群上运行,除了独立集群模式之外,Flink还提供对YARN和Mesos的支持。
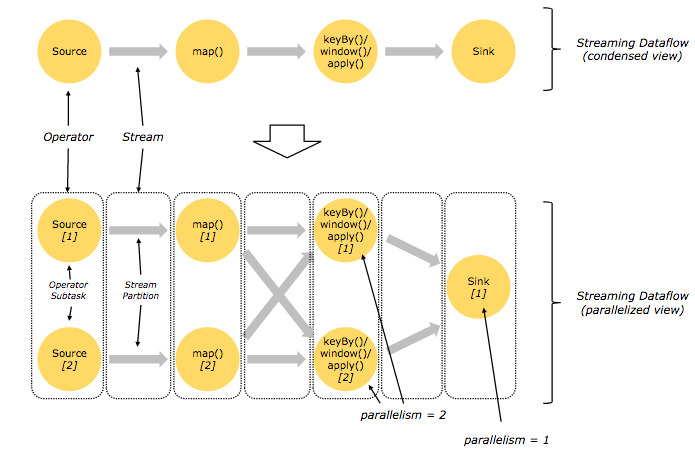
Flink,流模型和有界数据集
如果您已经查看过Flink的文档,您可能已经注意到用于处理无界数据的DataStream API以及用于处理有界数据的DataSet API。
在本文前面,我们介绍了流式执行模型(“连续执行的处理,一次一个事件”),直观地适用于无界数据集。那么有界数据集如何与流处理范例相关?
在Flink的情况下,这种关系是相当自然的。一个有界数据集可以简单地看作一个无界特例,所以我们可以将上面所有的流式概念应用到有限数据上。
这正是Flink的DataSet API的行为。有界数据集在Flink内部作为“有限流”进行处理,Flink如何管理有界数据集和无界数据集只有一些细微差异。
所以可以使用Flink来处理有界数据和无界数据,这两个API在相同的分布式流式执行引擎上运行 - 一个简单而强大的体系结构。
“什么”:从下往上闪烁
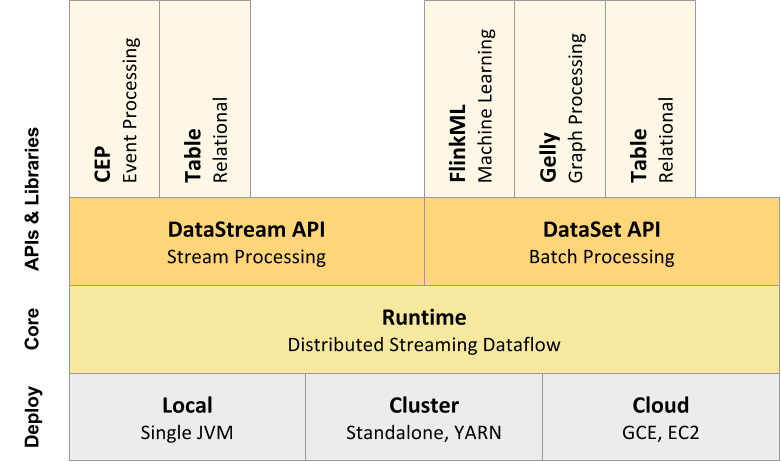
部署模式
Flink可以运行在云环境中,也可以在内部环境中运行,也可以运行在独立的集群上,也可以运行在YARN或Mesos管理的集群上。
运行
Flink的核心是分布式流式数据流引擎,意味着数据一次处理而不是一系列批处理,这是一个重要的区别,因为这是Flink的许多弹性和性能特征.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号