

LLM-02 大模型 本地部署运行 ChatGLM3-6B(13GB) 双卡2070Super8GB 环境配置 单机多卡 基于LLM-01章节 继续乘风破浪 为大模型微调做准备 原创
官方介绍
ChatGLM3-6B 是 ChatGLM 系列最新一代的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的预训练模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
机器情况
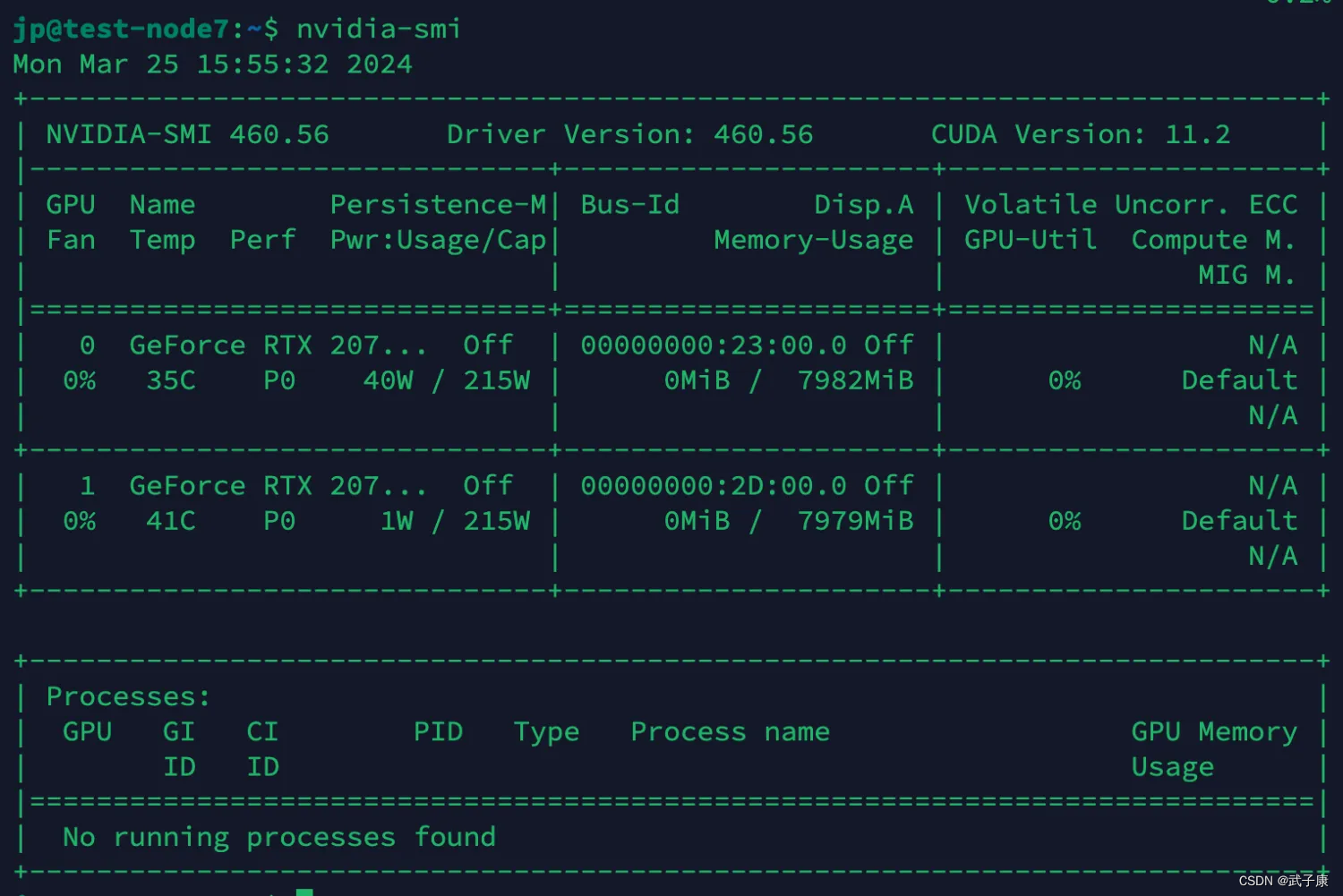
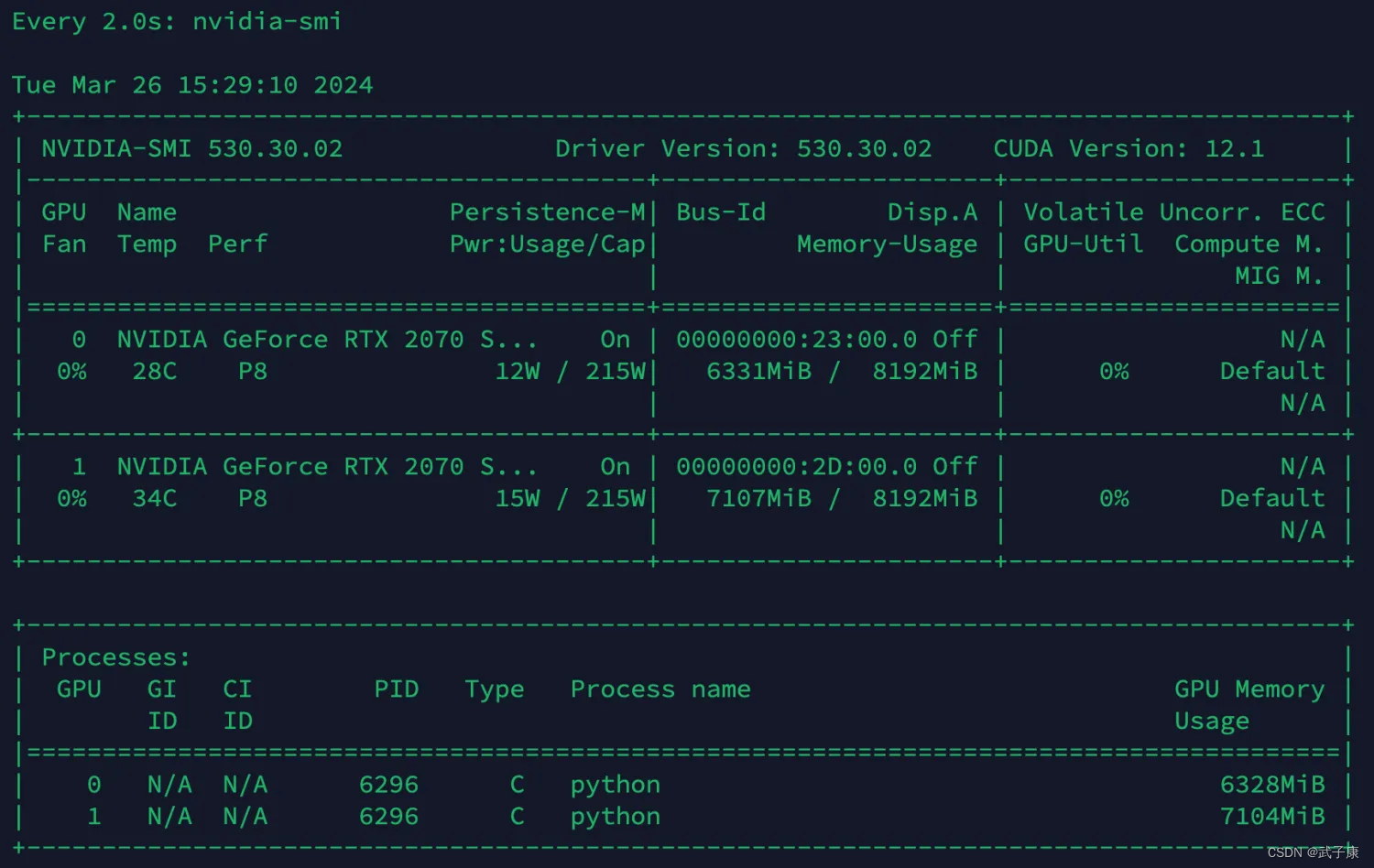
由于单卡的内存是不够的,这里使用的是 双卡。
最终大约占用14GB的显存。
项目地址
至于模型的下载,可以查看 上一章节 LLM-01 大模型 ChatGLM2-6b(4GB) 的教程
# Github 项目地址
https://github.com/THUDM/ChatGLM3

# 下载模型
git clone https://huggingface.co/THUDM/chatglm3-6b

环境配置
这一章节有些重复,但是为了大家的方便,这里再放一次上次的内容。
由于很多不同的项目队python版本的要求不同,同时对版本的要求也不同,所以你需要配置一个独立的环境。
这里你可以选择 Conda,也可以选择pyenv,或者docker。我选的方案是:pyenv
自动完成安装Pyenv
# 自动完成安装
curl https://pyenv.run | bash
需要配置一下环境变量
Bash
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
ZSH
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc
echo '[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc
echo 'eval "$(pyenv init -)"' >> ~/.zshrc
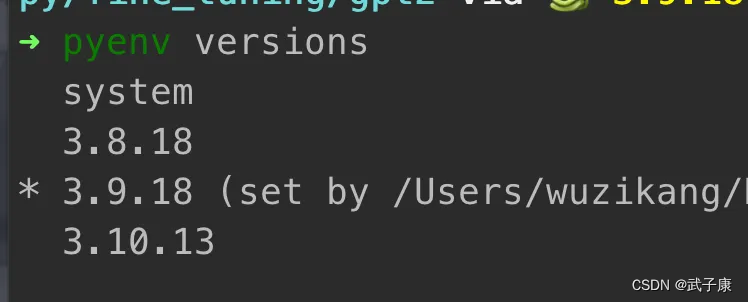
查看pyenv
# 查看当前系统中的Python情况
pyenv versions
使用pyenv
# Python版本
pyenv local 3.10
# 独立环境
python -m venv env
# 切换环境
source env/bin/active
# cd 到项目目录
# 安装Python库 pip install - requirements.txt
依赖安装
先开启一个独立的环境,避免造成影响
# Python版本
pyenv local 3.10
# 独立环境
python -m venv env
# 切换环境
source env/bin/active
# cd 到项目目录
# 安装Python库 pip install - requirements.txt
pip install protobuf transformers==4.30.2 cpm_kernels torch>=2.0 gradio mdtex2html sentencepiece accelerate
# 克隆过的话可忽略
# git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
pip install -r requirements.txt
启动项目
我这边的全路径为:/home/jp/wzk/chatglm3-6b-project/ChatGLM3/basic_demo 可供你参考
# 修改文件内容
vim web_demo_gradio.py
# 修改 MODEL_PATH (web_demo_gradio.py中)
MODEL_PATH = os.environ.get('MODEL_PATH', '/home/jp/wzk/chatglm3-6b-project/chatglm3-6b')
# 运行服务
python web_demo_gradio.py
此时发现,我们已经是多卡模式启动了

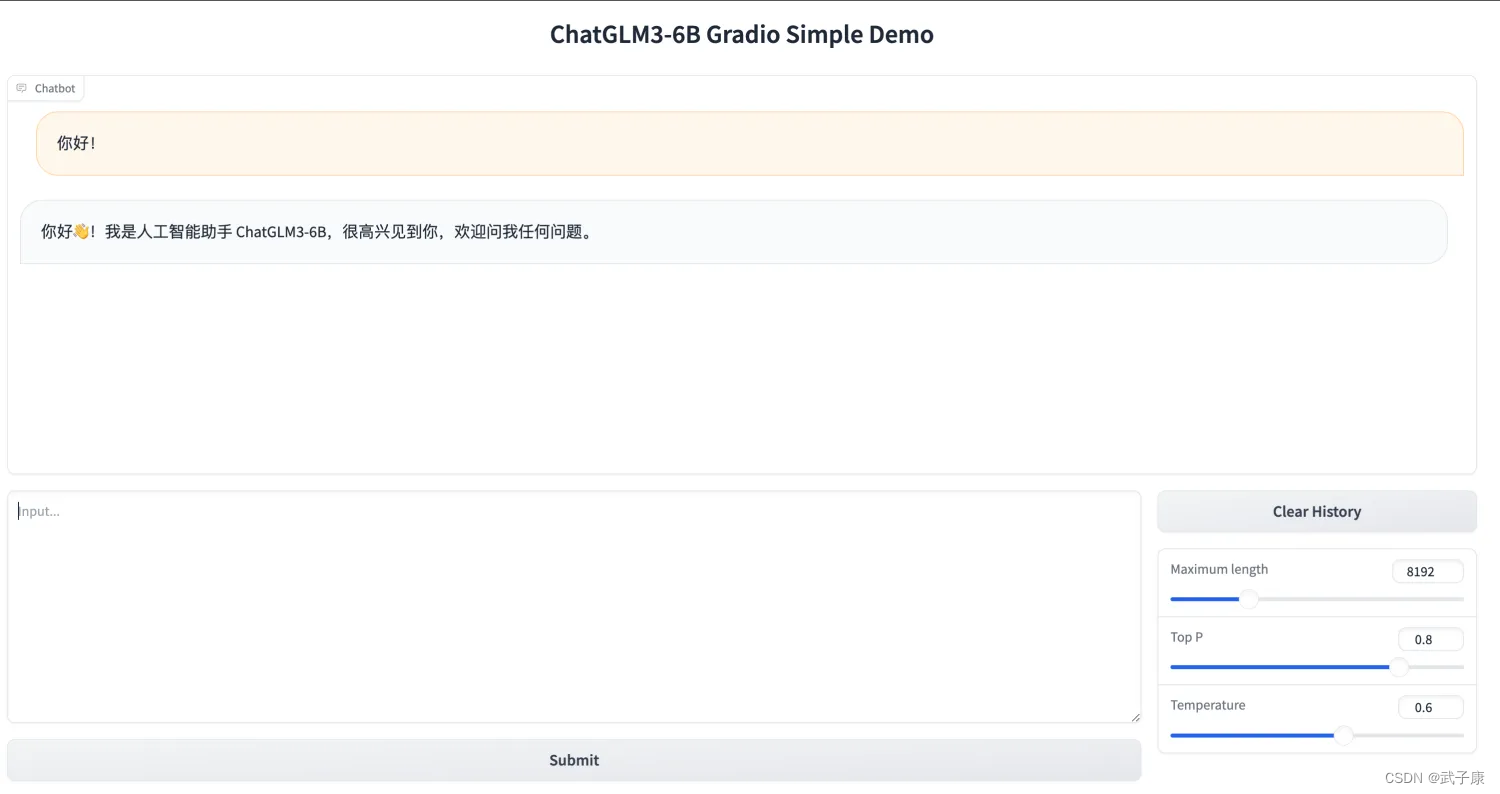
访问服务
访问当前的地址http://xxx:7870,即可看到如下的页面。
多卡启动
需要安装依赖库:
pip install accelerate
直接启动项目,内部已经自动帮你封装好了:
我们可以观察到:卡0占用了6.3GB,卡1占用了7.1GB,已经顺利的运行起13GB的模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号