


剪枝(pruning)是决策树学习算法对付"过拟合"的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得"太好"了,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。
决策树叶剪枝的基本策略有"预剪枝"(prepruning)和"后剪枝"(postpruning)。预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。
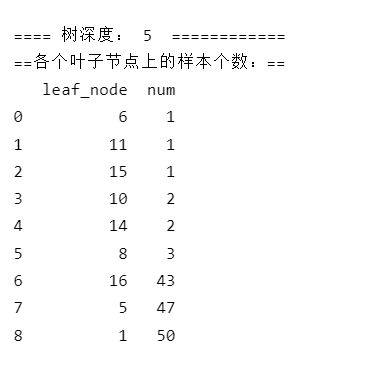
首先是默认的树:
点击查看代码
from sklearn.datasets import load_iris
from sklearn import tree
import numpy as np
import pandas as pd
#--------数据加载-----------------------------------
iris = load_iris() # 加载数据
X = iris.data
y = iris.target
#-------用最优参数训练模型------------------
clf = tree.DecisionTreeClassifier(random_state=0)
clf = clf.fit(X, y)
depth = clf.get_depth()
leaf_node = clf.apply(X)
#-----观察各个叶子节点上的样本个数---------
df = pd.DataFrame({"leaf_node":leaf_node,"num":np.ones(len(leaf_node)).astype(int)})
df = df.groupby(["leaf_node"]).sum().reset_index(drop=False)
df = df.sort_values(by='num').reset_index(drop=True)
print("\n==== 树深度:",depth," ============")
print("==各个叶子节点上的样本个数:==")
print(df)
使用参数限制节点生长
最少叶片限制在5 :
点击查看代码
#-------用新调整的参数训练模型------------------
clf = tree.DecisionTreeClassifier(random_state=0,min_samples_leaf=5)
clf = clf.fit(X, y)
depth = clf.get_depth()
leaf_node = clf.apply(X)
#-----观察各个叶子节点上的样本个数---------
df = pd.DataFrame({"leaf_node":leaf_node,"num":np.ones(len(leaf_node)).astype(int)})
df = df.groupby(["leaf_node"]).sum().reset_index(drop=False)
df = df.sort_values(by='num').reset_index(drop=True)
print("\n==== 树深度:",depth," ============")
print("==各个叶子节点上的样本个数:==")
print(df)

深度限制在4:
点击查看代码
#-------用新调整的参数训练模型------------------
clf = tree.DecisionTreeClassifier(random_state=0,max_depth=4)
clf = clf.fit(X, y)
depth = clf.get_depth()
leaf_node = clf.apply(X)
#-----观察各个叶子节点上的样本个数---------
df = pd.DataFrame({"leaf_node":leaf_node,"num":np.ones(len(leaf_node)).astype(int)})
df = df.groupby(["leaf_node"]).sum().reset_index(drop=False)
df = df.sort_values(by='num').reset_index(drop=True)
print("\n==== 树深度:",depth," ============")
print("==各个叶子节点上的样本个数:==")
print(df)

节点分枝最小样本个数限制在4:
点击查看代码
#-------用新调整的参数训练模型------------------
clf = tree.DecisionTreeClassifier(random_state=0,min_samples_split=5)
clf = clf.fit(X, y)
depth = clf.get_depth()
leaf_node = clf.apply(X)
#-----观察各个叶子节点上的样本个数---------
df = pd.DataFrame({"leaf_node":leaf_node,"num":np.ones(len(leaf_node)).astype(int)})
df = df.groupby(["leaf_node"]).sum().reset_index(drop=False)
df = df.sort_values(by='num').reset_index(drop=True)
print("\n==== 树深度:",depth," ============")
print("==各个叶子节点上的样本个数:==")
print(df)

可以发现对最大深度、节点的最小样本数参数的调整都可以实现剪枝的操作
