
rabbitmq使用 - - - -消费者||生产者
是消息队列
MQ(Message Quene) : 消息队列,是典型的生产者和消费者模型,生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。 因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,轻松的实现系统间**解耦**。 消息队列也可称作:**消息中间件** 消息队列就是基础数据结构中的“先进先出”的一种数据机构。 想一下,生活中买东西,需要排队,先排的人先买消费,就是典型的"先进先出"

# 1 应用解耦-->分布式架构中服务和服务之间的桥梁 以电商应用为例,有订单系统、库存系统、物流系统、支付系统。 用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障,都会造成下单操作异常。 当转变成基于消息队列的方式后,系统间调用的问题会减少很多,比如物流系统因为发生故障,需要几分钟来修复。 在这几分钟的时间里,物流系统要处理的内存被缓存在消息队列中,用户的下单操作可以正常完成。 当物流系统恢复后,继续处理订单信息即可,中单用户感受不到物流系统的故障。提升系统的可用性 # 2 流量削峰---》大并发的秒杀场景 如果订单系统最多能处理一万次订单,这个处理能力应付正常时段的下单时绰绰有余,正常时段我们下单一秒后就能返回结果。 但是在高峰期,如果有两万次下单操作系统是处理不了的,只能限制订单超过一万后不允许用户下单。 使用消息队列做缓冲,我们可以取消这个限制,把一秒内下的订单分散成一段时间来处理,这时有些用户可能在下单十几秒后才能收到下单成功的操作,但是比不能下单的体验要好 # 3 消息分发--》发布订阅 多个服务对数据感兴趣,只需要监听同一类消息即可处理,就是典型的观察者模式,又叫发布订阅 例如A产生数据,B对数据感兴趣。如果没有消息的队列A每次处理完需要调用一下B服务。过了一段时间C对数据也感性,A就需要改代码,调用B服务,调用C服务。只要有服务需要,A服务都要改动代码。很不方便。 有了消息队列后,A只管发送一次消息,B对消息感兴趣,只需要监听消息。C感兴趣,C也去监听消息。A服务作为基础服务完全不需要有改动 # 4 异步消息--》异步调用后结果的查询,使用消息队列做缓冲 有些服务间调用是异步的,例如A调用B,B需要花费很长时间执行,但是A需要知道B什么时候可以执行完,以前一般有两种方式,A过一段时间去调用B的查询api查询。或者A提供一个callback api,B执行完之后调用api通知A服务。这两种方式都不是很优雅 使用消息队列,可以很方便解决这个问题,A调用B服务后,只需要监听B处理完成的消息,当B处理完成后,会发送一条消息给MQ,MQ会将此消息转发给A服务。 这样A服务既不用循环调用B的查询api,也不用提供callback api。同样B服务也不用做这些操作。A服务还能及时的得到异步处理成功的消息
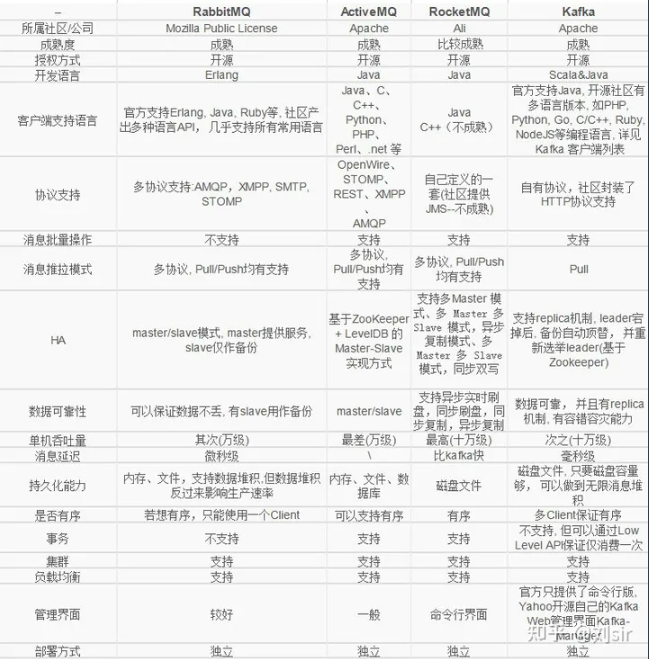
Kafka在于分布式架构,RabbitMQ基于AMQP协议来实现,RocketMQ/思路来源于kafka,改成了主从结构,在事务性可靠性方面做了优化。 广泛来说,电商、金融等对事务性要求很高的,可以考虑RabbitMQ和RocketMQ, 对性能要求高的可考虑Kafka
对数据安全性要求高,使用rabbitmq
基于AMQP协议,erlang语言开发,是部署最广泛的开源消息中间件,是最受欢迎的开源消息中间件之一。
AMQP 协议advanced message queuing protocol
在2003年时被提出,最早用于解决金融领不同平台之间的消息传递交互问题。
AMQP是一种协议,是一个进程间传递**异步消息的网络协议**
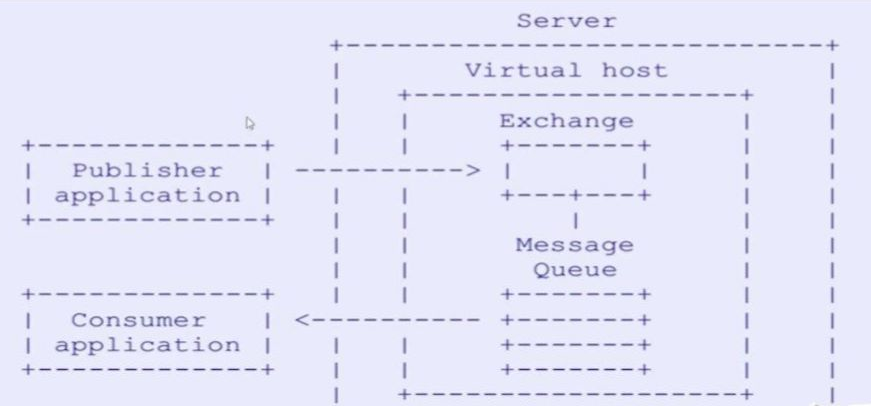
# Broker: 消息中间件,AMQP实体 接收和分发消息的应用,RabbitMQ 的服务就是一个Message Broker # Virtual host: 虚拟主机 出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似于网络中的namespace概念 当多个不同的用户使用同一个RabbitMQ server提供的服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange/queue # Connection: 连接 publisher/consumer和broker之间的TCP连接 断开连接的操作只会在client端进行,Broker不会断开连接,除非出现网络故障或broker服务出现问题 # Channel: 通道 如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也较低 Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id帮助客户端和message broker识别channel,所以channel之间是完全隔离的。 Channel作为轻量级的Connection极大减少了操作系统建立TCP connection的开销。 # Exchange: 交换机 message到达broker的第一站,根据分发规则,匹配查询表中的routing key,分发消息到queue中去。 常用的类型有: ''' 1【direct (point-to-point)-点对点模式】点对点模式Message中的routing key如果和Binding中的binding key一致,Direct exchange则将message发到对应的queue中 2【topic (publish-subscribe)-发布-订阅模式】根据routing key,及通配规则,Topic exchange将分发到目标queue中 3【fanout (multicast)-多播模式】每个发到Fanout类型Exchange的message都会分到所有绑定的queue上去。 ''' # Queue: 队列 消息最终被送到这里等待consumer取走 一个message可以被同时拷贝到多个queue中 # Binding: 绑定 exchange和queue之间的虚拟连接,binding中可以包含routing key Binding信息被保存到exchange中的查询表中,用于message的分发依据
# erlang 解释型语言--》要运行rabbitmq,必须要有erlang的解释器环境 # Linux 安装 # win安装 -erlang 安装包:https://github.com/erlang/otp/releases/download/OTP-26.2.3/otp_win64_26.2.3.exe -rabbitmq安装包:https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.13.0/rabbitmq-server-3.13.0.exe # centos 上使用docker运行 # 安装好Docker,执行下面命令 docker pull rabbitmq:3.13-management docker run -di --name rabbitmq -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin -p 15672:15672 -p 5672:5672 rabbitmq:3.13-management # 浏览器访问:(15672:web 管理页面,浏览器访问;5672:提交消息使用的端口) http://10.0.0.111:15672 # 输入用户名:admin 密码:admin ,进入到管理控制台
https://www.rabbitmq.com/tutorials
# 安装python 操作rabbitmq的模块 pip3 install pika --upgrade # 补充: celery python界的异步框架-->其实就是对消息队列的封装 airflow

import pika # 1 拿到链接 # 无密码链接 # connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.0.0.111',port=5672)) # 有密码链接 credentials = pika.PlainCredentials("admin", "admin") connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.0.0.111', port=5672, credentials=credentials)) # ACCESS_REFUSED channel = connection.channel() # 2 创建并声明管道的名字 channel.queue_declare(queue='hello') # 3 向管道中发送消息 # exchange 先写空 # routing_key:把发送的消息路由到哪个队列中--》hello # body:发送的消息是什么 channel.basic_publish(exchange='', routing_key='hello', body='Hello World 888') print("Sent 'Hello World!'") # 关闭 connection.close()
import pika # 1 链接 credentials = pika.PlainCredentials("admin", "admin") connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.0.0.111', port=5672, credentials=credentials)) channel = connection.channel() # 2 创建并声明queue---》有可能它先运行--》如果不写这句---》queue没有--》就会报错 # 这个即便写多次,也只会创建一个queue channel.queue_declare(queue='hello') def callback(ch, method, properties, body): print(f" [x] Received {body}") # 消费者监听:hello 这个queue,只要queue中有消息,就会触发on_message_callback对应的函数的执行 # auto_ack 自动确认,为了保证数据不丢失 channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() # 卡在这
# 等消息消费完--再确认---》服务端再删除
ch.basic_ack(delivery_tag=method.delivery_tag)
import pika # 1 拿到链接 credentials = pika.PlainCredentials("admin", "admin") connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.0.0.111', port=5672, credentials=credentials)) channel = connection.channel() channel.queue_declare(queue='hello1') channel.basic_publish(exchange='', routing_key='hello1', body='Hello World 888') print("Sent 'Hello World!'") # 关闭 connection.close()
import pika credentials = pika.PlainCredentials("admin", "admin") connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.0.0.111', port=5672, credentials=credentials)) channel = connection.channel() channel.queue_declare(queue='hello1') def callback(ch, method, properties, body): print(f" [x] Received {body}") # 消费呢,还没消费完--》程序崩了--->之前在消息队列中得消息---》没了 # 真正消费完再确认 ch.basic_ack(delivery_tag=method.delivery_tag) # 消费者监听:hello 这个queue,只要queue中有消息,就会触发on_message_callback对应的函数的执行 # auto_ack 自动确认,为了保证数据不丢失,只要拿到消息---》通知服务端,消息拿到了删除 channel.basic_consume(queue='hello1', on_message_callback=callback, auto_ack=False) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() # 卡在这

 浙公网安备 33010602011771号
浙公网安备 33010602011771号