Django——on_delete, orm查询 queryset对象方法,,django与ajax
on_delete
orm查询 queryset对象的方法
all():查询所有的结果
示例:
publisher = models.Publisher.objects.all() #查询所有的出版社信息
get():
publisher = models.Publisher.objects.get(id = 1) # get查询数据不存在时会保错
filter():
publisher = models.Publisher.objects.filter(id = 1) #不存在的时候返回一个空的Queryset 不会报错
publisher = models.Publisher.objects.filter(id = 1)[0] #就算查询的结果只有一个 返回的也是一个Queryset 列表 要用索引的方式取出第一个元素
exclude():
publisher = models.Publisher.objects.exclude(id = 1) #排除掉id等于1的数据
values():
publisher = models.Publisher.objects.values("name","type") #返回一个Queryset对象 里面全是字典 为空的话 默认查出所有数据
values_list():
publisher = models.Publisher.objects.values_list("name") # 返回一个Queryset对象 里面全是列表为空的话 默认查出所有数据
order_by():
publisher = models.Publisher.objects.all().order_by("time") #根据xxx排序
reverse(): #反转
publisher = models.Publisher.objects.all().order_by("time") .reverse() #只能对有序的Queryset 进行反转
count(): 返回Queryset中对象的数量
publisher = models.Publisher.objects.all().count()
frist(): 返回Queryset中第一个对象
publisher = models.Publisher.objects.all().frist()
last():返回Queryset中最后一个对象
publisher = models.Publisher.objects.all().last()
exists(): 查询表中是否有数据 有就返回True 没有就是Falsepublisher = models.Publisher.objects.exists()
contains ——双下划线 模糊匹配
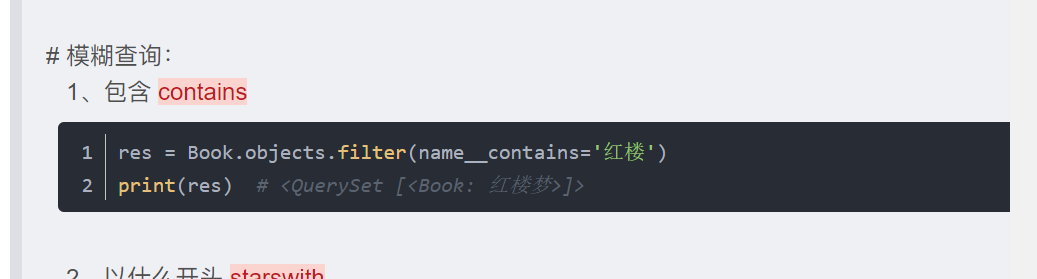
包含某个字符,xx__icontains: i 忽略大小写。
日期类型:xx__year、xx___month、xx__day—————————————————————————————————————————————————————————————————————————————————————————————————————————————————
——基于双下划线的链表查
-一次查询,连表操作
——正向和反向
放在 ForeignKey,OneToOneField,ManyToManyFiled的
-related_name='books': 双下划线连表查询,反向查询按表名小写---》用来替换表名小写
publish_books_name
-related_query_name ='books' :基于对象跨表查询, 反向查询--》用来替换表名小写
publish.book_set.all( )
publish.books.all( )
——聚合查询
aggregate()是QuerySet 的一个终止子句,也就是说在写QuerySet查询语句时aggregate()后面不能再有其他查询语句,因为aggregate()会返回一个键值对的字典,不再是QuerySet 对象
聚合函数: AVG,Count,Max,Min,Sum
使用
select name, price,avg(‘price’)as_price_avg from book;
book.objexts.all( ).aggregate( Avg( 'price'))
select name,price,avg( 'price') as averge_price from book;
book.object.all( ).aggregate( avg_price=Avg('price'),min_price=Min( 'price'))
——分组查询 --分组后通常会用聚合-- anntate用来分组和聚合
annotate:
filter在 annotate前:表示过滤, where条件
values在annotate前:表示分组的字段,如果不写表示按整个表分组
fileter在 annotate后:表示 having条件
values在annotate后,表示取字段---》只能取分组字段和聚合函数字段
分组的目的:把相同特征的分成一组,分成一组后一般用来:统计总条数,统计平均数,求最大值
统计每一本书作者个数
book.objects.all( ).balues( 'id').annotate(authour_num=count('authors')).values( 'name,'author_num'')
统计每一个出版社的最便宜的书---按出版社
publish.objects.all().values('id').annotate(min_price=Min('book_price')).values('name,''min_price')
publish.objects.annotate(MinPrice=Min('book_price'))
查询每一个书籍的名称,以及对应的作者个数--》按书分
book.objects.all( ).values('id').annotate(count_publish=Count('authors')).value('name','count_publish')
查询每一个以红开头 书籍的名称,以及对应的作者个数--按书分
book.objects.all( ).filter('name=startwith='红')values('id').annotate(count_publish=Count('authors')).value('name','count_publish')
查询每一个以红开头 书籍的名称,以及对应的作者个数大于3的记录--按书分
book.objects.all( ).filter('name=startwith='红')values('id').annotate(count_publish=Count('authors')).filter(count_publish_gt=3).value('name','count_publish')
——F查询与Q查询
F查询:拿到某个 字段在表中的具体的值
查询评论数大于收藏数的书籍
from django.db.models import F
book.objects.filter(评论数_gt=F('收藏夹'))
让所有图书价格+1
book.objects.all( ).update(price=F('price')+1)
Q查询: 为了组成 与 或 非 条件
与条件:and条件。在filter中直接写
book.objects.filter(authors_name='xxx',price=100)
或条件:
book.objects.filter(Q(authors_name='xxx')|Q(authors_name='justin'))
非条件:book.objects.filter(Q(name='红楼梦'))
复杂逻辑: 名字为红楼梦并且价格大于100 或者id大于2
book.objects.filter((Q(name='红楼梦')&Q(price_gt=100))|Q(nide_gt=2)
——其他字段和字段参数
字段参数;ORM字段参数
null用于表示某个字段可以为空。
unique 如果设置为unique=True 则该字段在此表中必须是唯一的 。
db_index如果db_index=True 则代表着为此字段设置索引。
default为该字段设置默认值。
DateField和DateTimeField
- auto_now_add=True:新增会把当前时间存入
- default=datatime.datatime.now
- auto_now=True,每次更新数据记录的时候会更新该字段
# verbose_name 提示,该字段的作用
# blank Admin中是否允许用户输入为空
# editable Admin中是否可以编辑
# help_text Admin中该字段的提示信息
choices Admin中显示选择框的内容,用不变动的数据放在内存中从而避免跨表操作
get_字段名_display()
# error_messages
# validators
ForeignKey 属性
# to设置要关联的表
# to_field 设置要关联的表的字段
# related_name 反向操作时,使用的字段名,用于代替原反向查询时的’表名_set’。
# related_query_name 反向查询操作时,使用的连接前缀,用于替换表名
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
models.CASCADE删除关联数据,与之关联也删除 models.DO_NOTHING 删除关联数据,引发错误IntegrityError models.PROTECT 删除关联数据,引发错误ProtectedError models.SET_NULL删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空) models.SET_DEFAULT删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值)
models.SET
删除关联数据,
a. 与之关联的值设置为指定值,设置:models.SET(值)
b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)
# db_constraint---》企业一般都设置为False
是否在数据库中创建外键约束,默认为True
db_constraint=False 在数据库中不建立外键约束
虽然不建立数据库外键约束---》但是orm查询,继续用
ManyToManyField 用于表示多对多的关联关系。在数据库中通过第三张表来建立关联关系
# to 设置要关联的表,中间是有个中间表的,区别于一对多
related_name 同ForeignKey字段。 related_query_name 同ForeignKey字段
through
在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系。
但我们也可以手动创建第三张表来管理多对多关系,此时就需要通过through来指定第三张表的表名。
# through_fields设置关联的字段。
# db_table 默认创建第三张表时,数据库中表的名称
中间表创建方式
-自动生成:用不到through 和 through_fields
authors=models.ManyToManyField(to='Author',db_table='中间表表名')
手动创建中间表,使用through指定
# 三张表都要手动创建--》3个类--》3个表模型---》
# 什么情况会使用手动创建?----中间表如果有多的字段,都是手动创建
# authors=models.ManyToManyField(to='Author',through='booktoauthor', through_fields=('当前表--》到中间表的外键关系','剩下的写在第二个位置'))
自动创建中间表,有快捷操作
-add
-remove
-set
-clear
-手动创建中间表---》中间表我们自己能拿到--》这些快捷操作,就没了
- 纯手动创建中间表,不使用ManyToManyField关联
# 不会在book或author表中加 ManyToManyField 字段了
在表中都可以定义要给内部类
class Author(models.Model):
name = models.CharField(max_length=32)
class Meta: #元信息
db_table
index_together
unique_together
ordering # 默认按id排序
1 ajax:异步Javascript和XML
2 作用:Javascript语言与服务器(django)进行异步交互,传输的数据为XML(当然,传输的数据不只是XML,现在更多使用json数据)
3 同步交互,异步交互
同步交互:js发送出请求---》直到请求回来---》页面不能操作,不能点击
异步交互:js发出请求---》等待请求回来的过程中--->页面可以随意继续操作
4 使用:使用了jq帮咱们封装的方法 ajax ,名字跟ajax相同 $.ajax
5 真正的ajax原生,需要使用js操作,jq的ajax方法是对原生js的封装,方便咱们使用
-前后端混合项目中,我们通常使用jq的ajax实现 js和后端异步交互
-jq操作dom
-jq发ajax请求
-前后端分离项目中,我们会使用另一个第三方库,实现 js和后端异步交互(axios)
-只想发送ajax请求---》只用来发ajax请求的库
6 计算 + 小案例
-编码格式是 :urlencoded
7 上传文件
-编码格式:form-data
8 Jaon格式
$.ajax({
url: '/demo01/',
method: 'post',
contentType: 'application/json',
data: JSON.stringify({name: 'lqz', age: 19}), // 把对象转成字符串形式,json格式字符串
success: function (data) {
console.log(data)
}
})
存在浏览器上的键值对,就是cookie
cookie哪里来的?---》服务端返回的--》放在响应头的cookie中---》浏览器会自动取出来--》放到cookie中
再次向cookie所在的域发送请求,它会自动携带当时存的cookie
存在于服务端的键值对,称之为session
{'11111':{name:lqz},'22222':{name:zs}}
cookie在django中使用
—————————————————————————————————————————————————————————————————————
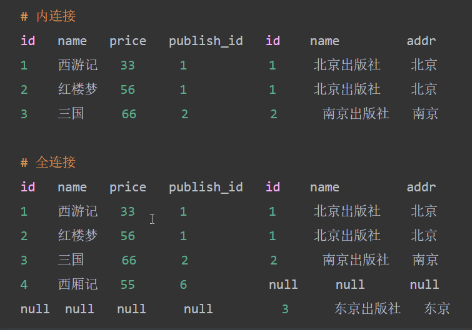
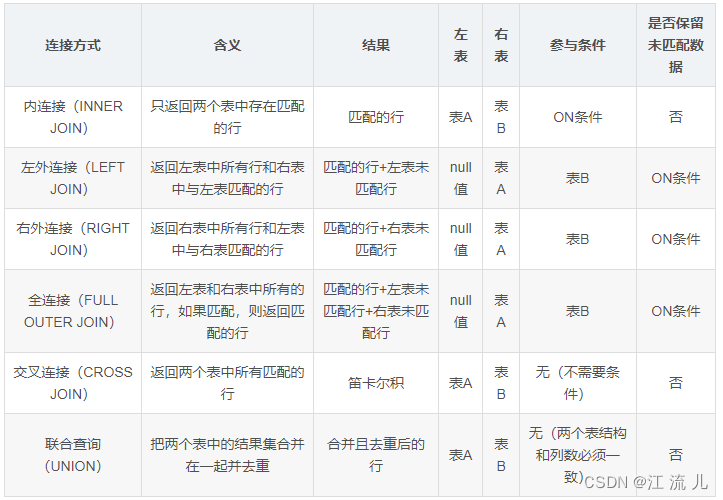
连表有哪几种连接方式:
mysql不接受 全连接 所以需要 union
内连接、外连接(左连接、右连接、全连接)、交叉连接
内连接(等值,不等,自然)
连表的目的: 查询 连表的依据是:表和表之间需关系
例如
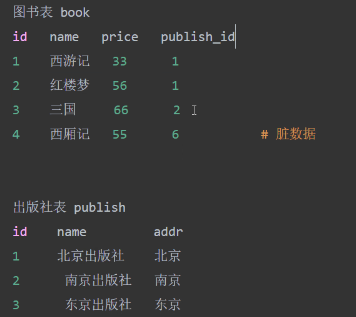
select * from book left join publish on book.publish_id =publish.id;
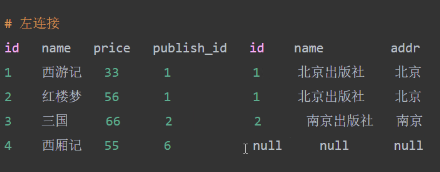
select * from book right join publish on book.publish_id= publish.id;
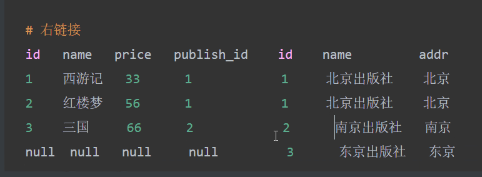
内连接:select * from book inner join publish on book.publish_id =publish.id
全连接 (Mysql 不支持)
select * from book left join publish on book.publish_id =publish.id
union
select * from book right join publish on book.publish_id =publish.id;
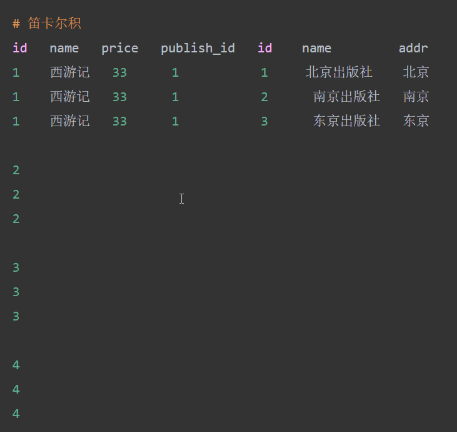
笛卡尔积:(sql是笛卡尔积后,过滤条件是select * from book,publish where book.publish_id =publish.id;)
因为数据太多加限定条件,
登录和注册
# 注册功能(邮箱和用户名头像)
注册使用ajax注册,能够上传头像---》上传的头像保存到media文件夹下
浏览器中能访问
用户名不能重复---》ajax--》输入框光标失去焦点---》就去后端校验用户名是否存在,如果存在,把输入框情况,并弹出alert 说用户名不能重复
$('#id_json').blur(function(){
$("#three").val('')
alert()
})
# 登录功能---》ajax登录
既可以用邮箱登录,又可以用用户名登录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号