

在线学习和在线凸优化(online learning and online convex optimization)—基础介绍1
Posted on 2018-08-31 14:59 wzd321 阅读(5435) 评论(0) 收藏 举报开启一个在线学习和在线凸优化框架专题学习:
1.首先介绍在线学习的相关概念
在线学习是在一系列连续的回合(rounds)中进行的;
在回合,学习机(learner)被给一个question:
(一个向量,即为特征向量),
为从instance domain:
采样得到的。学习机给出一个预测值:
,然后得到正确的答案:
,
从target domain:
采样得到,定义损失函数为
。在大多数情况下,
在
中,但是,允许学习者从更大的集合中选择预测有时很方便,我们用D表示prediction domain。下图展示了在线学习框架:

2在线学习考虑的两个限制
第一个限制特别适合于在线分类的情况:
我们假设所有的answer都是由一些target mapping生成的:,
取自固定集合,称为假设类,由H表示,这是学习者已知的。由于这种对序列的限制,我们称之为realizable case,学习者应该尽可能少犯错误,假设
和问题的顺序可以由对手来选择。对于在线学习算法A,我们用
表示A在一系列用
标记的例子上可能犯的最大错误数。我们再次强调
和问题的顺序可以由对手来选择。
的上界称为mistake bound,我们将研究如何设计
最小的算法。
第二个限制是relaxation of the realizable assumption:
我们不再假设所有答案都是由产生,但是我们要求学习机与来自H最好的固定预测器竞争。这被算法的regret所捕获,regret度量了回顾过去,学习机有多“抱歉”没有遵循一些假设
的预测。形式上,算法相对于
的regret当在一系列T实例上运行时定义为:
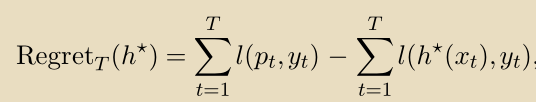
算法相对于假设类H的regret是:
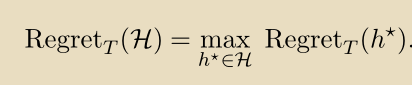
学习机的目标是相对于H具有尽可能低的regret。我们有时会对“low regret”算法感到满意,我们认为与轮数T呈次线性增长,其意味着当T变为无穷大时,学习机的平均损失与H中最佳假设的平均损失之间的差异趋于零。
次线性增长:
3.在线学习算法的使用例子
(1)在线回归

(2)专家建议预测

(3)在线排名(推荐系统)


未完,待续。。。。。。
下一节我们将从一个在线分类的例子说起。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号