

mysql函数


group_concat
create DATABASE mydb4;
use mydb4;
create table emp(
emp_id int primary key auto_increment comment '编号',
emp_name char(20) not null default '' comment '姓名',
salary decimal(10,2) not null default 0 comment '工资',
department char(20) not null default '' comment
'部门');
insert into emp(emp_name,salary,department) values('张晶晶',5000,'财务部'),('王飞飞',5800,'财务部'),('赵刚',6200,'财务部'),('刘小贝',5700,'人事部'),('王大鹏',6700,'人事部');
-- 将所有员工的名字合并成一行
select group_concat(emp_name) from emp;
-- 指定分隔符合并
-- 指定排序方式和分隔符
select department,group_concat(emp_name order by salary desc separator ';') from emp group by department;

-- 数学函数
select abs(-10);#绝对值
select ceil(1.1);
select ceil(1.0);#向上取整
select floor(1.1);
select floor(1.9);#向下取整
-- 去列表最大值
select greatest(1,2,3);
-- 求列表最小值
select least(1,2,3);

-- 取模
select mod(5,2);
-- 取x的y次方
select power(2,3);

-- 取随机数
select rand();
select floor(rand() * 100);
-- 小数四舍五入取整
select round(3.5415);
select round(3.5415,3);#四舍五入保留三位小数
-- 将小数截取到指定位数
select truncate(3.1415,3);

-- 字符串函数
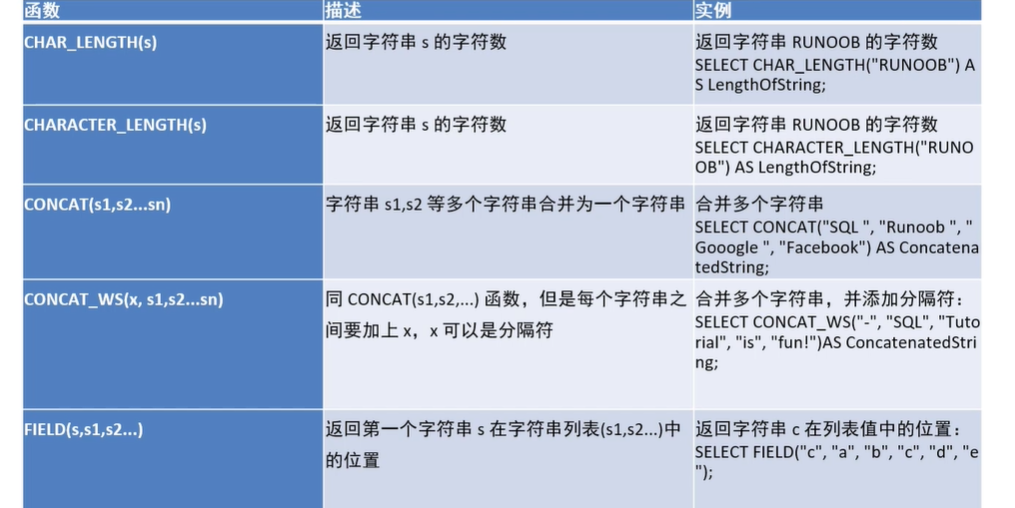
-- 获取字符串个数
select char_length('hello');
select char_length('你好吗');#返回5
-- length取长度,返回单位字节
select char_length('你好吗');#返回9
-- 实现字符串合并
select concat('hello','world');
-- 指定分隔符进行字符串合并
select concat_ws('-','helllo','world');
-- 返回字符串在列表中第一次位置
select field('aaa','bbb','aaa');
-- 去除字符串左边空格
select ltrim(' aaaa ')
select rtrim(' aaaa ')#右
select trim(' aaaa ')#两边
-- 字符串截取
select mid('helloworld',2,3);
-- 获取字符串a在b中出现的位置
select position('abc' in 'helloabcworld');#先看到那个返回那个
-- 字符串替换
select replace('helloaaaaaa','aaa','bbb');
-- 字符串反转
select reverse('hello');

-- 返回字符串后几个字符
select right('hello',3);
-- 字符串比较
select strcmp('hello','world');#-1表示hello小,先用h和w比,如果相同直接比第二个,只是比字符串在字典的顺序
-- 字符串截取
select substr('hello',2,3);select substring('hello',2,3);#从第二个字符开始截取,截取三个字符
-- 将小写转大写
select ucase('hello');
select upper('hello');
-- 将大写转小写
select lcase('hello');
select lower('hello');

use test1;
-- 日期函数
-- 获取时间戳(毫秒值)
select unix_timestamp();
-- 将一个字符串转为毫秒值
select unix_timestamp('2021-12-21 08:08:08');
-- 将毫秒值转为指定格式日期
select from_unixtime(1640045288,'%y-%m-%d %h:%I:%S')
-- 获取当前日期年月日
select curdate();
select current_date();
-- 获取当前的时分秒
select current_time();
select curtime();
-- 获取年月日时分秒
select current_timestamp();
-- 从日期字符串中获取年月日
select date('2022-12-12 12:34:56');
-- 获取日期之间的差值
select datediff('2021-12-23','2008-02-01');
select datediff(current_date(),'2008-02-01');

-- 获取时间差值(秒级)
select timediff('12:33:23','22:22:22');
-- 日期格式化
select date_format('2021_1-1 1:1:1','%Y-%M-%D %H:%I%S');
-- 将字符串转为日期
select str_to_date('2021-12-12 12:12:12','%Y-%M-%D %H:%I%S');
-- 对日期加减法
select date_sub('2021-10-01',interval 2 day);#减两天
-- 将日期进行加法
select date_add('2021-10-01',interval 2 day);#+两天
select date_add('2021-10-01',interval 2 month);#+两月

-- 从日期中获取小时
select extract(hour from '2021-12-12 12:12:12');
select extract(year from '2021-12-12 12:12:12');
select extract(month from '2021-12-12 12:12:12');
-- 获取给定日期所在月的最后一天
select last_day('2021-08-13');
-- 获取指定年份的第几天
select makedate('2021',53);
-- 根据日期获取年月日 时分秒
select year('2021-12-12 12:12:12');
select month('2021-12-12 12:12:12');
select minute('2021-12-12 12:12:12');
select quarter('2021-12-12 12:12:12');#获取季度

-- 根据日期获取信息
select monthnama('2021-12-13 11:12:13');获取月份
select dayname('2021-12-13 11:12:13');获取洲际
select dayofmonth('2021-12-13 11:12:13');当月的第几天
select dayofweek('2021-12-13 11:12:13');
select dayofyear('2021-12-13 11:12:13');以年的第几天

select week('2021-12-13 11:12:13');
select yearweek('2021-12-13');
select now();

-- 控制流函数
select if(5>3,'dayu','xiaoyu');
use mydb3;
select *,if(score >=85,'a','c') flag from score;
-- ifnull
select ifnull(null,0);
use test1;
select *,ifnull(comm,0) comm_falg from emp;
-- isnull
select isnull(5);
select ifnull(null);
-- nullif
select nullif(12,12);
select nullif(12,13);

-- case when 语句
select
case 5
when 1 then '你好'
when 2 then 'hello'
when 5 then 'dui'
else
'qita'
end as info;
select
case
when 3>2 then '你好'
when 2<1 then 'hello'
when 5>4 then 'dui'
else
'qita'
end as info;
create database mydb4;
use mydb4;
-- 创建订单表
create table orders(
oid int primary key,#订单id
price double,#订单价格
payType int#支付类型(2:支付宝3:银行卡)
);
insert into orders values(1,1200,1);
insert into orders values(2,1000,2);
insert into orders values(3,200,3);
insert into orders values(4,3000,1);
-- 方式一
select *,
case payType
when 1 then 'wechat'
when 2 then 'alipal'
when 5 then 'loongka'
else
'qitazhifu'
end as payTypestr
from orders;
-- 方式二
select *,
case payType
when payType=1 then 'wechat'
when payType=2 then 'alipal'
when payType=3 then 'loongka'
else
'qitazhifu'
end as payTypestr
from orders;






-- 窗口函数
insert into employee values('研发部','1006','黄忠','2021-11-03',4000);
insert into employee values('销售部','1007', '曹操','2021-11-01',2000);
CREATE TABLE employee(
dname varchar(20),#部门名
eid varchar(20),
ename varchar(20),
hiredate date,#入职日期
salary double#薪资
);
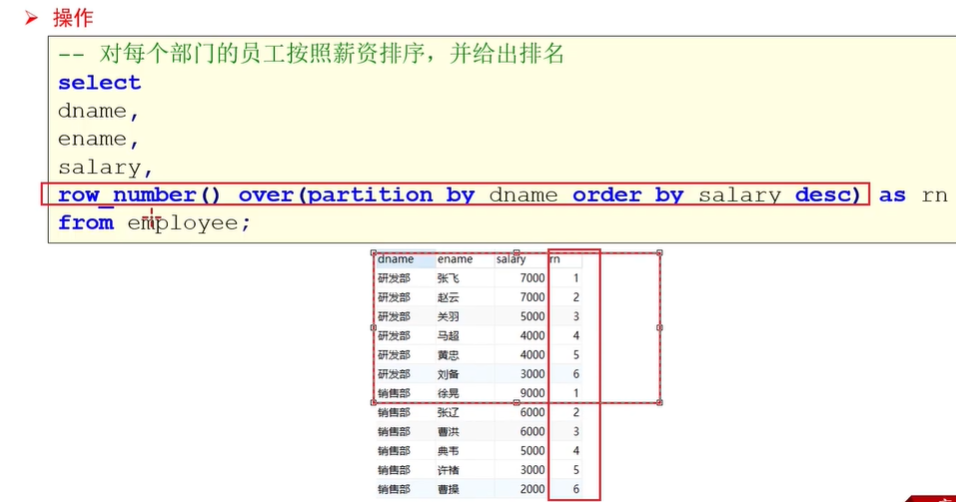
-- 对每个部门的员工安信资排序,并给出排名
select
dname,
ename,
salary,
row_number() over(partition by dname order by salary desc) as rn1,#不同组直接排名
rank() over(partition by dname order by salary desc) as rn2, #相同薪水同排名向下挤,占该占的位数
dense_rank() over(partition by dname order by salary desc) as rn3#相同薪水同排名占一位
from employee;
-- 求每个部门薪资排在前三名的员工,分组求topn
select
*
from
(
select
dname,
ename,
salary,
dense_rank() over(partition by dname order by salary desc) as rn3#相同薪水同排名占一位
from employee) t
where t.rn3 <=3;#mysql先执行from在执行where,最后执行select,,所以使用子查询
-- 对所有员工进行全局排序
-- 不加partition by 表示全局排序,感觉像是分组
select
dname,
ename,
salary,
dense_rank() over(order by salary desc) as rn3
from employee;
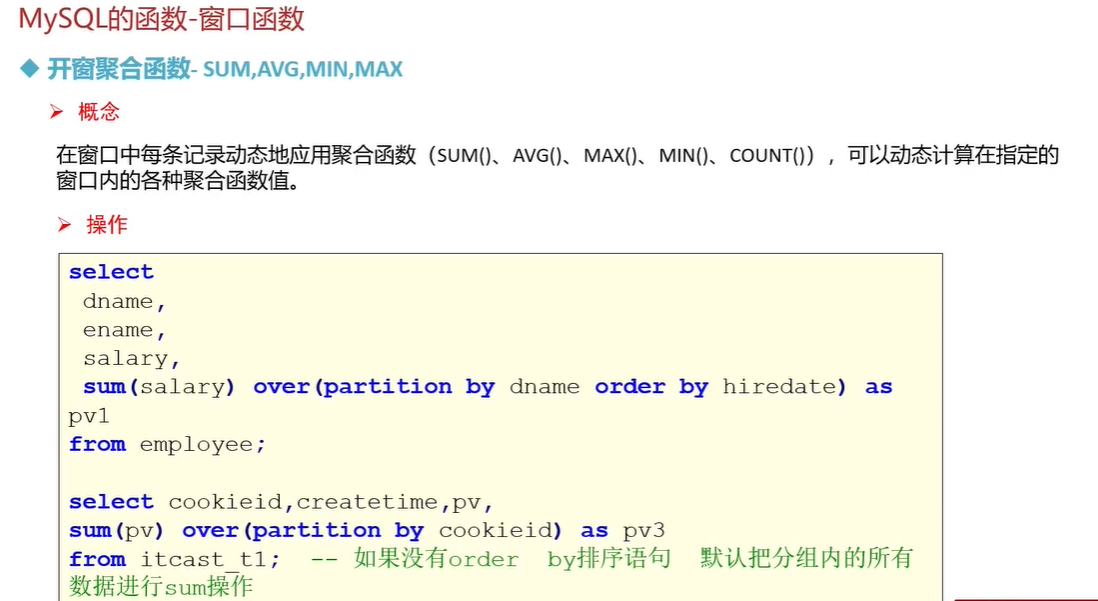
-- 开窗聚合函数
use mydb4;
select
dname,
ename,
salary,
sum(salary) over (partition by dname order by hiredate) as pv1
from employee;#累加
select
dname,
ename,
salary,
sum(salary) over (partition by dname) as c1 from employee;#如果没有order by语句,默认把分组中的所有数据一次性进行sum操作
select
dname,
ename,
salary,
sum(salary) over (partition by dname order by hiredate rows between unbounded preceding and current row) as pv1 from employee;#从开头到当前行相加
select
dname,
ename,
salary,
sum(salary) over (partition by dname order by hiredate rows between 3 and current row) as pv1 from employee;#从我的前三行到当前行相加,包括当前行
select
dname,
ename,
salary,
sum(salary) over (partition by dname order by hiredate rows between 3 preceding and 1 following) as pv1 from employee;#从现在的前三行到后一行
select
dname,
ename,
salary,
sum(salary) over (partition by dname order by hiredate rows between current row and unbounded following ) as pv1 from employee;#从当前行到最后

-- 分布函数- CUME_DIST
-- 用途:分组内小于、等于当前rank值的行数 / 分组内总行数
-- 应用场景:查询小于等于当前薪资(salary)的比例
select
dname,ename,salary,
cume_dist() over(order by salary) as rn1,
cume_dist() over(partition by dname order by salary) as rn2
from employee;

select
dname,ename,salary,
rank() over(partition by dname order by salary desc) as rn2,
percent_rank() over(partition by dname order by salary desc) as rn1
from employee;
-- rn2第一行:(1-1)/(1-1)=0

-- 前后函数lag和lead
-- 用途:返回位于当前行的前n行(LAG(expr,n))或后n行(LEAD(expr,n))的expr的值
-- 应用场景:查询前1名同学的成绩和当前同学成绩的差值
use mydb4;
select
dname,ename,salary,
lag(hiredate,1,'2000-01-01') over(partition by dname order by hiredate) as time1,#把本行上一行的值放在time1,没有则为20000101,
lag(hiredate,2) over(partition by dname order by hiredate) as time2
from employee;
select
dname,ename,salary,
lead(hiredate,1,'2000-01-01') over(partition by dname order by hiredate) as time1,#把本行下一行的值放在time1,没有则为20000101,
lead(hiredate,2) over(partition by dname order by hiredate) as time2
from employee;

-- 头尾函数-FIRST_VALUE和LAST_VALUE
-- 用途:返回第一个(FIRST_VALUE(expr))或最后一个(LAST_VALUE(expr))expr的值
-- 应用场景:截止到当前,按照日期排序查询第1个入职和最后1个入职员工的薪资
select
dname,ename,salary,
first_value(salary) over(partition by dname order by hiredate) as first1,#按排序目前为止的第一个值给first
last_value(salary) over(partition by dname order by hiredate) as last2#按排序目前为止的最后一个给last,一般为他本身
from employee;

-- 其他函数-NTH_VALUE(expr, n)、NTILE(n)
-- NTH_VALUE(expr,n)用途:返回窗口中第n个expr的值。expr可以是表达式,也可以是列名
-- 应用场景:截止到当前薪资,显示每个员工的薪资中排名第2或者第3的薪资
select
dname,ename,salary,
nth_value(salary,2) over(partition by dname order by hiredate) as secondsalary,#按排序截止到当前第二的数给secondsalary
nth_value(salary,3) over(partition by dname order by hiredate) as thirdsalary2#按排序截止到当前第3的数给thirdsalary
from employee;

-- NTILE
-- 用途:将分区中的有序数据分为n个等级,记录等级数
-- 应用场景:将每个部门员工按照入职日期分成3组
select
dname,ename,salary,hiredate,
ntile(3) over(partition by dname order by hiredate) as thirdsalary2#按partitiion分组后按排序平均分为三个组
from employee;
-- 取出每个部门的第一组员工
select * from (select
dname,ename,salary,hiredate,
ntile(3) over(partition by dname order by hiredate) as nt
from employee)t where t.nt=1;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号