

|
论文名和编号 |
摘要/引言 |
相关背景和工作 |
论文方法/模型 |
实验(数据集)及 分析(一些具体数据) |
未来工作/不足 |
是否有源码 |
|||
|
问题 |
原因 |
解决思路 |
优势 |
|
|
|
|
|
|
|
基于词向量的学术语义搜索研究 编号:1000-5463(2016)03-0053-06 |
1.词向量由于词的语义生成文档的语义并不像直观地看起来那样简单。直接用简单的线性相加的方式会丢失词语间的上下文信息。 |
1. |
1. 基于词向量的语义搜索模型。利用 词向量化技术,从大量的语料库中进行训练,学习每 个词的向量化表示。之后由词的向量计算出文档的 向量,由此就可以计算出文档与文档之间、文档与查 询词之间的语义距离,从而实现精准的语义搜索。 |
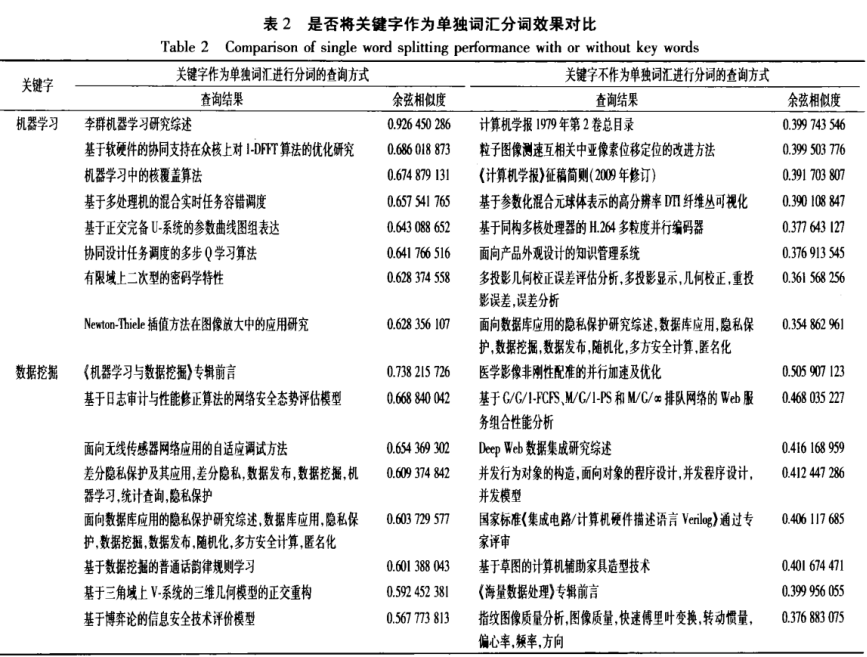
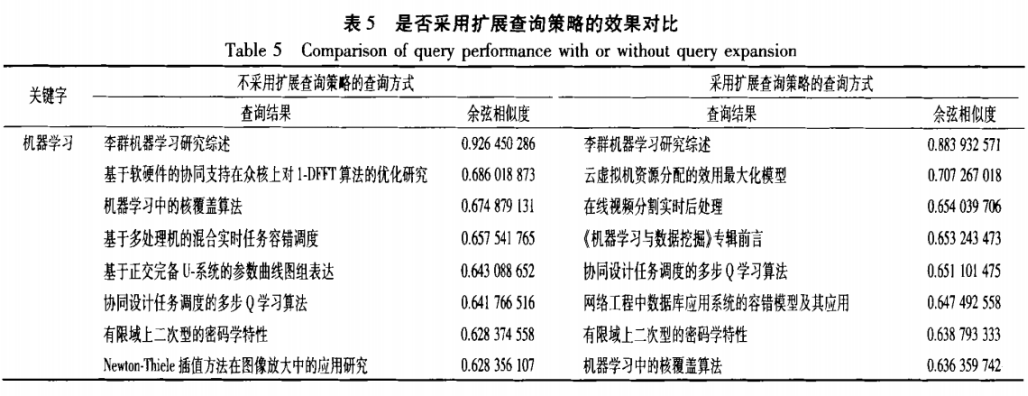
1.针对学术搜索的实际情况,提出了利用题目+关键词来训练语义向量,并将关键词作为完整词汇加入到分词组件的用户自定义词典中;利用随机映射的方法,提高了在向量空间中查找最相关文档的效率,并进行语义查询。 |
1.深度机器学习技术取得了长足进步,因此出现了新的语义计算方法,如word2vec、Glove等。 2.词向量技术在2个方面取得了巨大的进步:相比于LSA挖掘的概念,词向量技术计算出的词的语义向量包含了线性语义特征,可以捕获词的语法及语义的线性相似度;词向量利用深度机器学习技术,可以在大型的语料库里进行训练,利用的数据量越大,得到的模型越精确。 |
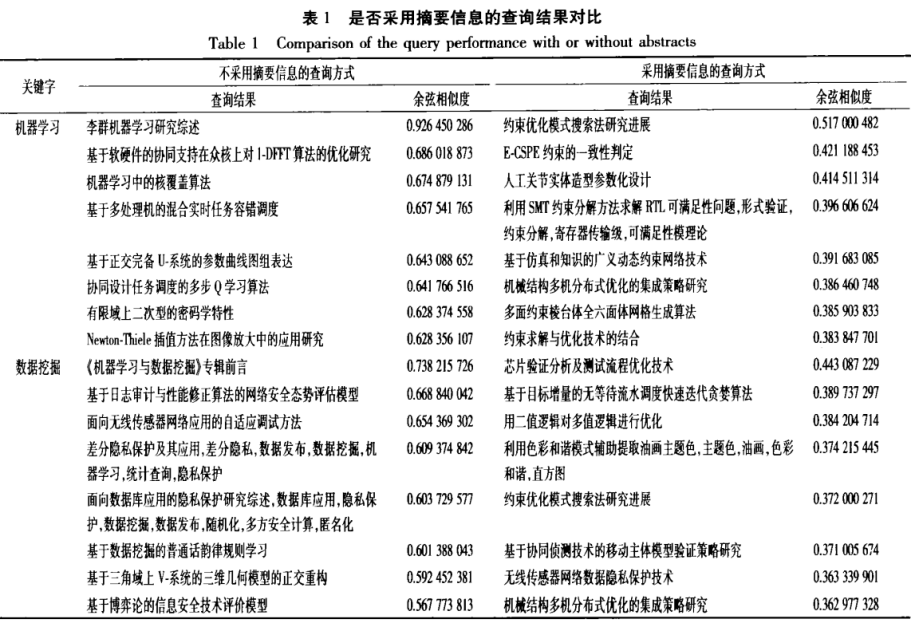
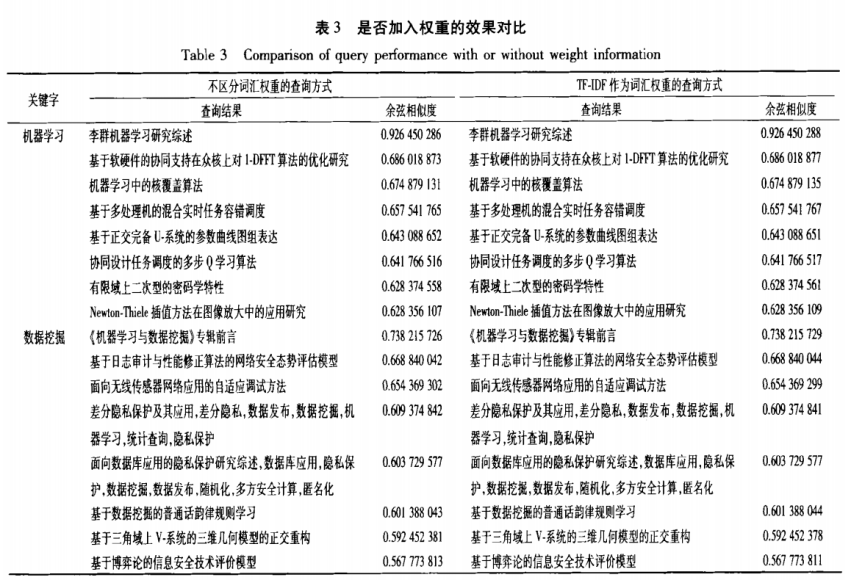
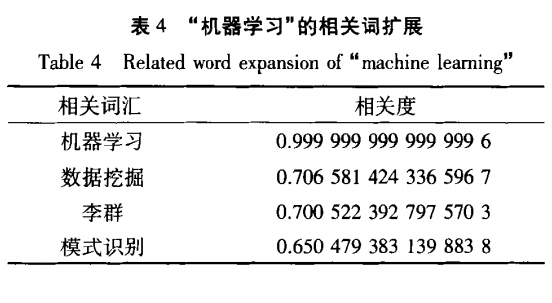
1.基于词向量的语义搜索模型,利用词向量化技术,从大量的语料库中进行训练,学习每个词的向量化表示,之后由词的向量计算出文档的向量,由此计算出文档与文档之间、文档与查询词之间的语义距离,从而实现精准的语义搜索。 2.算法一:基于词向量的学术论文语义搜索: 第1步:抽取出论文标题即关键字,形成语料库。 第2步:将抽取出的关键字加入分词组建的用户自定义字典中,对语料库中的论文数据进行分词。 第3步:将分词后的数据调用Glove进行训练,得到每个词的语义向量库。 第4步:对用户输入的查询进行相关词扩展,选出相似度大于设定值的最相近词汇,组成新的查询。 第5步:计算新查询的向量,在语义向量库中查询与其最相关的文档并返回。 为提高相关文档的查询效率,使其适用于大规模的文档库中,利用随即映射的方法,在大规模向量空间中快速查询最相关文档。在向量空间中随机生成一条分隔线,将向量空间分成不同的2个子空间,如此多次进行随机分割,空间的划分方法就生成了一颗随机树,再在随机数中定位查询目标向量所在的划分区域,在这些区域中查找与之最相关的文档。由于在向量空间中相近的点极大可能落在随机树的同一个划分区域中,所以如果进行多次随机划分,生成的多个随机树的查询结果的并集将会覆盖到完整的最相关文档的绝大部分。 |
|
1.进一步讨论如何有效的利用摘要信息,进一步丰富论文的语义。 |
无 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号