


C语言II博客作业01
作业头
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/CST2020-4 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/CST2020-4/homework/11772 |
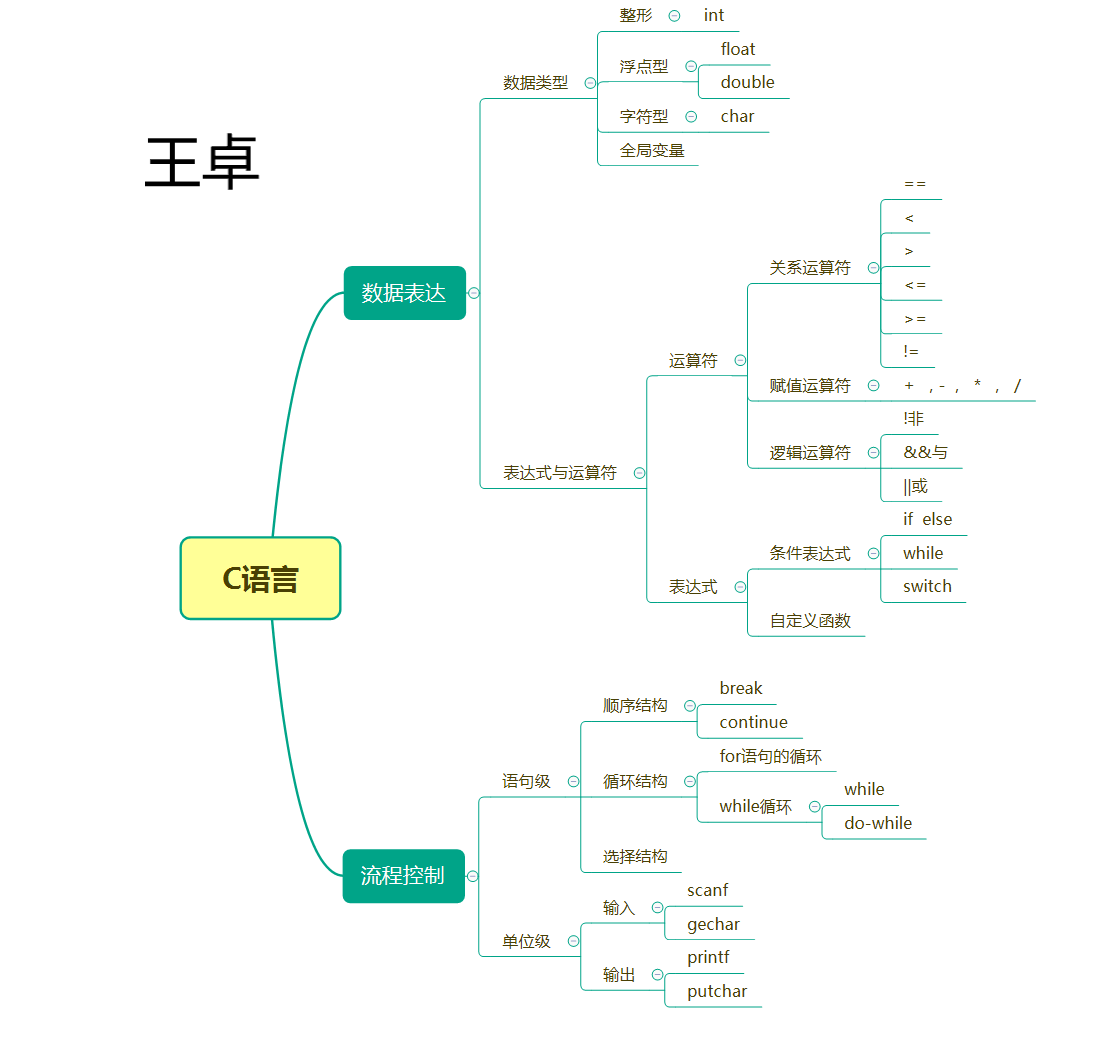
| 这个作业的目标 | < 回顾数据类型和表达式,第12章 文件 |
| 学号 | <20209044> |
本周作业
2.1 题目:给定一个十进制正整数N,写下从1开始,到N的所有整数,然后数一下其中出现的所有“1”的个数。
例如:
N=2,写下1,2。这样只出现了1个”1“。
N=12,我们会写下1,2,3,4,5,6,7,8,9,10,11,12。这样,1的个数是5。
问题是:
1.写出一个函数f(N),返回1到N之间出现的”1“的个数,比如f(12)=5;
2.满足条件”f(N)=N“的最大的N是多少?
要求:
1.贴出代码图片,写出解题思路,列出测试数据(5分)
2.给出不同测试数据的运算时间,如果你的运算时间不变,说明你的测试数据不够大!(5分)
3.思考针对足够大的数据,如何减少运算时间,并给出在原有算法基础上的改进算法和改进思路。(10分)
判断有几个1.
实验代码截图

运行结果

文件内容

运行时间(


数据处理
数据表达:定义整型变量a,b.c.d.e.i,abci为函数中间值循环值,d为1的个数,n为用户输入的值。
数据处理:首先输入数据n。用for循环判断n的位数,再从n的个位数开始,往前判断有几个1,用一个大循环去表示1到n,每一位1的个数。
测试数据
| 输入数据 | 输出数据 | 数据说明 |
|---|---|---|
| 12 | 5 | 题目样例 |
| 1 | 1 | 个位数 |
| 10 | 2 | 十位数 |
| 111 | 36 | 全是一 |
| 200 | 160 | 更大的数 |
| 100 | 21 | 正常输入 |
满足条件”f(N)=N“的最大的N是多少?
实验代码截图

运行结果

自己简化了代码,但是算2到一千万的数时还是要等很久,估计在往上运算时间还要多,可能是自己技术不到位吧,电脑也有一定问题,就计算了别人的一个较大的值,应该1111111110吧。
2.3 用自己的语言回答两个问题,并给出所查阅资料的引用(10分)
1.什么是文件缓冲系统?工作原理如何?
答:就是一个存储空间,将数据输入到这个空间中,等到这个空间满了,就输送到磁盘一次性处理,这样可以减少磁盘读取次数,就减少了运行时间。下面是引用的资源:
C 语言所使用的磁盘文件系统有两大类:一类称为缓冲文件系统,又称为标准文件系统;另一类称为非缓冲文件系统。
缓冲文件系统的特点是系统自动地在内存区为每一个正在使用的文件开辟一个缓冲区。从磁盘向内存读入数据时,则一次从磁盘文件将一些数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送给接收变量;向磁盘文件输出数据时,先将数据送到内存中的缓冲区,装满缓冲区后才一起送到磁盘去。
用缓冲区可以一次读入一批数据,或输出一批数据,而不是执行一次输入或输出函数就去访问一次磁盘,这样做的目的是减少对磁盘的实际读写次数,因为每一次读写都要移动磁头并寻找磁道扇区,花费一定的时间。缓冲区的大小由各个具体的C 版本确定,一般为512 字节。
非缓冲文件系统不由系统自动设置缓冲区,而由用户自己根据需要设置。在传统的UNIX 系统下,用缓冲文件系统来处理文本文件,用非缓冲文件系统处理二进制文件。
1983 年ANSI C 标准决定不采用非缓冲文件系统,而只采用缓冲文件系统。即用缓冲文件系统处理文本文件,也用它来处理二进制文件。也就是将缓冲文件系统扩充为可以处理二进制文件。
一般把缓冲文件系统的输入输出称为标准输入输出(标准I/O),非缓冲文件系统的输入输出称为系统输入输出(系统I/O)。在C 语言中,没有输入输出语句,对文件的读写都是用库函数来实现的。
ANSI 规定了标准输入输出函数,用它们对文件进行读写。
2.什么是文本文件和二进制文件?
答:文本文件是按照字符来存储的,每个字符占一个字节,用DOS命令TYPE可显示文件的内容。 人们能看得懂文件内容。二进制文件是按二进制的编码方式来存放文件的,其内容无法看懂。文本文件是基于字符编码的文件,常见的编码有ASCII编码,UNICODE编码等等。二进制文件是基于值编码的文件,你可以根据具体应用,指定某个值是什么意思(这样一个过程,可以看作是自定义编码)下面是引用:
一、文本文件与二进制文件的定义
大家都知道计算机的存储在物理上是二进制的,所以文本文件与二进制文件的区别并不是物理上的,而是逻辑上的。这两者只是在编码层次上有差异。简单来说,文本文件是基于字符编码的文件,常见的编码有ASCII编码,UNICODE编码等等。二进制文件是基于值编码的文件,你可以根据具体应用,指定某个值是什么意思(这样一个过程,可以看作是自定义编码。
从上面可以看出文本文件基本上是定长编码的(也有非定长的编码如UTF-8)。而二进制文件可看成是变长编码的,因为是值编码嘛,多少个比特代表一个值,完全由你决定。大家可能对BMP文件比较熟悉,就拿它举例子吧,其头部是较为固定长度的文件头信息,前2字节用来记录文件为BMP格式,接下来的8个字节用来记录文件长度,再接下来的4字节用来记录bmp文件头的长度。
二、文本文件与二进制文件的存取
文本工具打开一个文件的过程是怎样的呢?拿记事本来说,它首先读取文件物理上所对应的二进制比特流,然后按照你所选择的解码方式来解释这个流,然后将解释结果显示出来。一般来说,你选取的解码方式会是ASCII码形式(ASCII码的一个字符是8个比特),接下来,它8个比特8个比特地来解释这个文件流。例如对于这么一个文件流"01000000_01000001_01000010_01000011"(下划线''_'',为了增强可读性手动添加的),第一个8比特''01000000''按ASCII码来解码的话,所对应的字符是字符''A'',同理其它3个8比特可分别解码为''BCD'',即这个文件流可解释成“ABCD”,然后记事本就将这个“ABCD”显示在屏幕上。
3学习总结
3.1学习进度条
| 周/日期 | 这周所花的时间 | 代码行 | 学到的知识点简介 | 目前比较迷惑的问题 |
|---|---|---|---|---|
| 03/01--03/07 | 18 | 360 | 回顾数据类型和表达式,学习文件的读取 | 文件的存储引用 |
3.2 累积代码行和博客字数(5分)

3.3 学习内容总结和感悟(5分)
3.31学习内容总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号