

2017-2018-1 20179205《Linux内核原理与设计》第七周作业
《Linux内核原理与设计》第七周作业
视频学习及操作分析
创建一个新进程在内核中的执行过程 fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;函数返回了两次,即在父进程子进程中各返回一次。通过复制当前进程可以创建一个新的进程。Linux通过复制父进程来创建一个新进程,那么这就给我们理解这一个过程提供一个想象的框架:
·复制一个PCB——task_struct
1.err = arch_dup_task_struct(tsk, orig);``
·要给新进程分配一个新的内核堆栈
1.ti = alloc_thread_info_node(tsk, node);
2.tsk->stack = ti;
3.setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
要修改复制过来的进程数据,比如pid、进程链表等等都要改改吧,见copy_process内部。
从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回,那它在系统调用处理过程中的哪里开始执行的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process
1. *childregs = *current_pt_regs(); //复制内核堆栈
2.childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因!
3.
4. p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
5. p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
int copy_thread(unsigned long clone_flags, unsigned long sp,
unsigned long arg, struct task_struct *p)
{
struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err;
p->thread.sp = (unsigned long) childregs;
p->thread.sp0 = (unsigned long) (childregs+1);
memset(p->thread.ptrace_bps, 0, sizeof(p->thread.ptrace_bps));
if (unlikely(p->flags & PF_KTHREAD)) {
/* kernel thread */
memset(childregs, 0, sizeof(struct pt_regs));
p->thread.ip = (unsigned long) ret_from_kernel_thread; //如果创建的是内核线程,则从ret_from_kernel_thread开始执行
task_user_gs(p) = __KERNEL_STACK_CANARY;
childregs->ds = __USER_DS;
childregs->es = __USER_DS;
childregs->fs = __KERNEL_PERCPU;
childregs->bx = sp; /* function */
childregs->bp = arg;
childregs->orig_ax = -1;
childregs->cs = __KERNEL_CS | get_kernel_rpl();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
p->thread.io_bitmap_ptr = NULL;
return 0;
}
*childregs = *current_pt_regs();//拷贝已有内核堆栈数据和制定新进程的第一条指令地址
childregs->ax = 0; //子进的程返回值是0
...
p->thread.ip = (unsigned long) ret_from_fork;//ip指向 ret_from_fork,子进程从此处开始执行
task_user_gs(p) = get_user_gs(current_pt_regs());
...
return err;
使用GDB跟踪创建新进程的过程
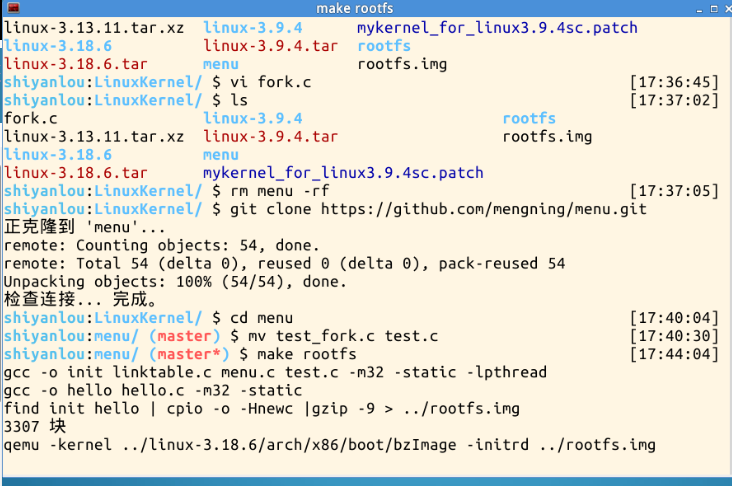

可以看到执行结果如上,输入fork输出了一个父进程一个子进程。接下来要使用gdb来跟踪调试进程创建过程,所以需要设置断点。若执行成功,那么可以分别在sys_clone,do_fork,dup_task_struct,copy_process,copy_thread,ret_from_fork这几处设置断点,这是执行一个fork可以看到停在Fork a new process处。按c继续执行:
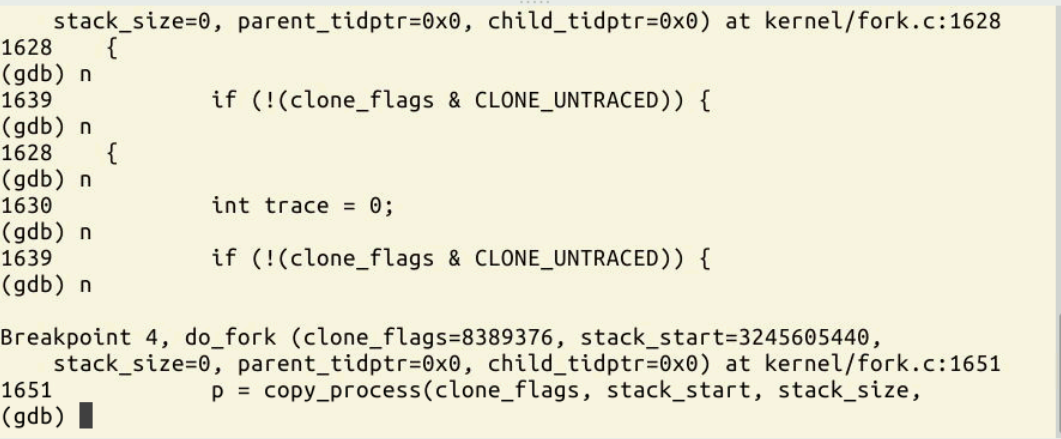
下面出现了copy_process
task_struct结构关系
struct task_stuct数据结构和庞大,linux进程的状态操作与操作系统原理中的描述状态似乎有所不同,比如TASK_RUNNING既可以表示就绪状态也可以表示运行状态。
问题与分析
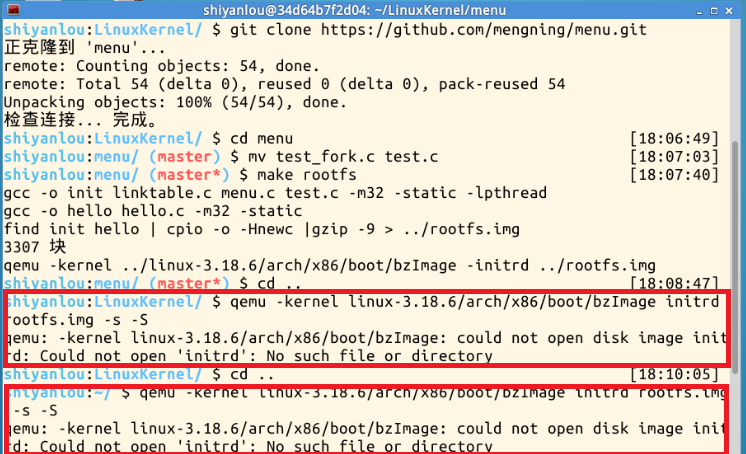
在实验过程中出现了打不开'initrd'的情况,反复在LinuxKernel和menu目录下尝试几次,结果失败,上网未查到答案,没有解决。
教材十一章、十二章学习
1、时间管理在内核中占有很重要的地位,内核中有大量的函数都是基于时间驱动的。事实上内核必须在硬件的帮助之下节拍才能计算和管理时间。硬件为内核提供了一个系统定时器用来计算流逝的时间。系统定时器以某种频率自行触发(也称为“射中” 或 “击中” 时钟中断),该频率可以通过编程预定,称作节拍率。(内核连续两次时钟中断的间隔时间称为节拍,它等于节拍率分之一)当时钟中断发生时,内核就通过一种特殊的中断处理程序对其进行处理。
2、利用时间中断周期执行的工作:
更新系统运行时间;跟新实际时间;在smp系统中均衡调度各处理器的运行列队;检查当前进程是否用尽了时间片,如果用尽则重新进行调度;运行超时的动态定时器;更新资源消耗和处理器时间的统计值。
3、系统定时器的频率(节拍率)是静态预处理定义的。HZ越高的优势:内核定时器以更高的频度和准确度执行;提高运行的精度;对资源消耗和系统运行时间等的测量有更精细的解析度;进程抢占更准确。劣势:节拍率越高,时钟中断程序占用处理器时间越多;并且频繁打乱处理器cache并增加耗电。无时钟OS可以根据系统的空闲程度动态改变频率;全局变量jiffies 用来计算自系统启动以来产生的节拍总数,启动时内核将该初始变量设置为0 ,然后每次时钟中断处理程序会增加这个值.
4、时钟中断处理程序:
就是每次发生时钟中断后,需要执行的程序,类似于中断处理程序,已经注册到内核中了,这个程序一般会完成以下的一些工作:获得 xtime_lock 锁,以便对访问 jiffies_64 和墙上时间 xtime 进行保护;需要时应答或重新设置系统时钟;周期性的使用墙上时间更新实时时钟;调用系统结构无关的时钟例程: tick_periodic()。
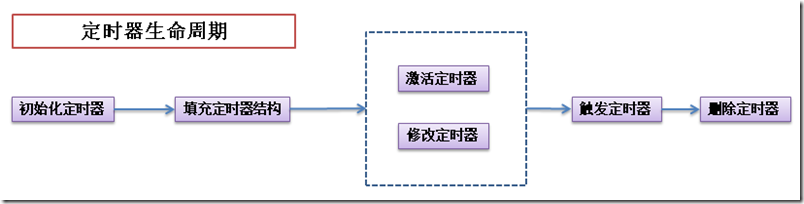
5、定时器并不周期运行,动态定时器就是不断的创建和撤销,它的生命周期一般会经历一下几个步骤:
6、内存最基本的管理是页,同时按照内存地址的大小,大致分为3个区;页是内存管理的最小单元,但是并不是所有的页对于内核都一样,内核将内存按地址的顺序分成了不同的区,有的硬件只能访问有专门的区。一般DMA使用的页物理内存<16MB,分配ZONE_DMA区内存;正常可寻址的页物理内存16~896MB,分配ZONE_NORMAL区内存;动态映射的页物理内存>896MB,分配ZONE_HIGHMEM区内存。linux中的高速缓存是用所谓 slab 层来实现的,slab层即为内核中管理高速缓存的机制。与单CPU环境不同,SMP环境下的并行是真正的并行。单CPU环境是宏观并行,微观串行。真正并行时,会有更多的并发问题。按CPU来分配数据主要有2个优点:最直接的效果就是减少了对数据的锁,提高了系统的性能;由于每个CPU有自己的数据,所以处理器切换时可以大大减少缓存失效的几率。如果一个处理器操作某个数据,而这个数据在另一个处理器的缓存中时,那么存放这个数据的那个处理器必须清理或刷新自己的缓存。持续的缓存失效成为缓存抖动,对系统性能影响很大。
7、在众多的内存分配函数中,如何选择合适的内存分配函数很重要,下面总结了一些选择的原则:如果需要物理上连续的页,选择低级页分配器或者 kmalloc 函数;如果kmalloc分配是可以睡眠的,指定 GFP_KERNEL标志;如果kmalloc分配是不能睡眠的,指定 GFP_ATOMIC标志;如果不需要物理上连续的页,vmalloc函数;如果需要高端内存,alloc_pages 函数获取page的地址,在用kmap之类的函数进行映射;如果频繁撤销/创建教导的数据结构,建立slab高速缓存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号