20232209实验四《Python程序设计》实验报告
20232209 2024-2025-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2322
姓名: 吴易阳
学号:20232209
实验教师:王志强
实验日期:2025年5月14日
必修/选修: 公选课
一、实验内容
【1】实验内容概述:
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
(1)编写从社交网络爬取数据,实现可视化舆情监控或者情感分析。
(2)利用公开数据集,开展图像分类、恶意软件检测等。
(3)利用Python库,基于OCR技术实现自动化提取图片中数据,并填入excel中。
(4)爬取天气数据,实现自动化微信提醒。
(5)利用爬虫,实现自动化下载网站视频、文件等。
(6)编写小游戏:坦克大战、贪吃蛇、扫雷等等。
注:在Windows/Linux系统上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
【2】本实验聚焦内容:
(1)编写从社交网络爬取数据,实现自动化提取数据,并填入excel中。
(2)利用python实现爬取天气数据、电影热搜以及音乐榜单。
(3)利用爬虫实现自动化提取网站照片,实现可视化舆情监控。
二、 实验过程及结果
(一)爬虫+可视化
1.项目介绍
本python代码用于爬取静态网页中全年天气数据生成csv文件,并实现数据可视化绘制天气轮播图,用于直观展示全年天气数据的变化
2.抓取全年天气数据部分
2.1 导入包
import requests
from lxml import etree
import csv
- requests:模拟浏览器进行网络请求
- etree:进行数据预处理
- csv:写入csv文件
2.2 定义函数获取网页中的天气数据
def getWeather(url):
weather_info = [] # 新建一个列表,将爬取的每月数据放进去
# 请求头信息:浏览器版本型号,接收数据的编码格式
headers = {
# 必填,不填拿不到数据
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0'
}
# 请求 接收到了响应数据
resp = requests.get(url, headers=headers)
# 数据预处理
resp_html = etree.HTML(resp.text)
# xpath提取所有数据
resp_list = resp_html.xpath("//ul[@class='thrui']/li")
# for循环迭代遍历
for li in resp_list:
day_weather_info = {}
# 日期
day_weather_info['date_time'] = li.xpath("./div[1]/text()")[0].split(' ')[0]
# 最高气温 (包含摄氏度符号)
high = li.xpath("./div[2]/text()")[0]
day_weather_info['high'] = high[:high.find('℃')]
# 最低气温
low = li.xpath("./div[3]/text()")[0]
day_weather_info['low'] = low[:low.find('℃')]
# 天气
day_weather_info['weather'] = li.xpath("./div[4]/text()")[0]
weather_info.append(day_weather_info)
return weather_info
参数传入的是要爬取网页的路由:
def getWeather(url):
headers为请求头信息,用来模拟浏览器环境来发起请求,如果不是浏览器发起请求,则会被网页发现为爬虫者,所以这一块必加。
headers = {
# 必填,不填拿不到数据
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0'
}
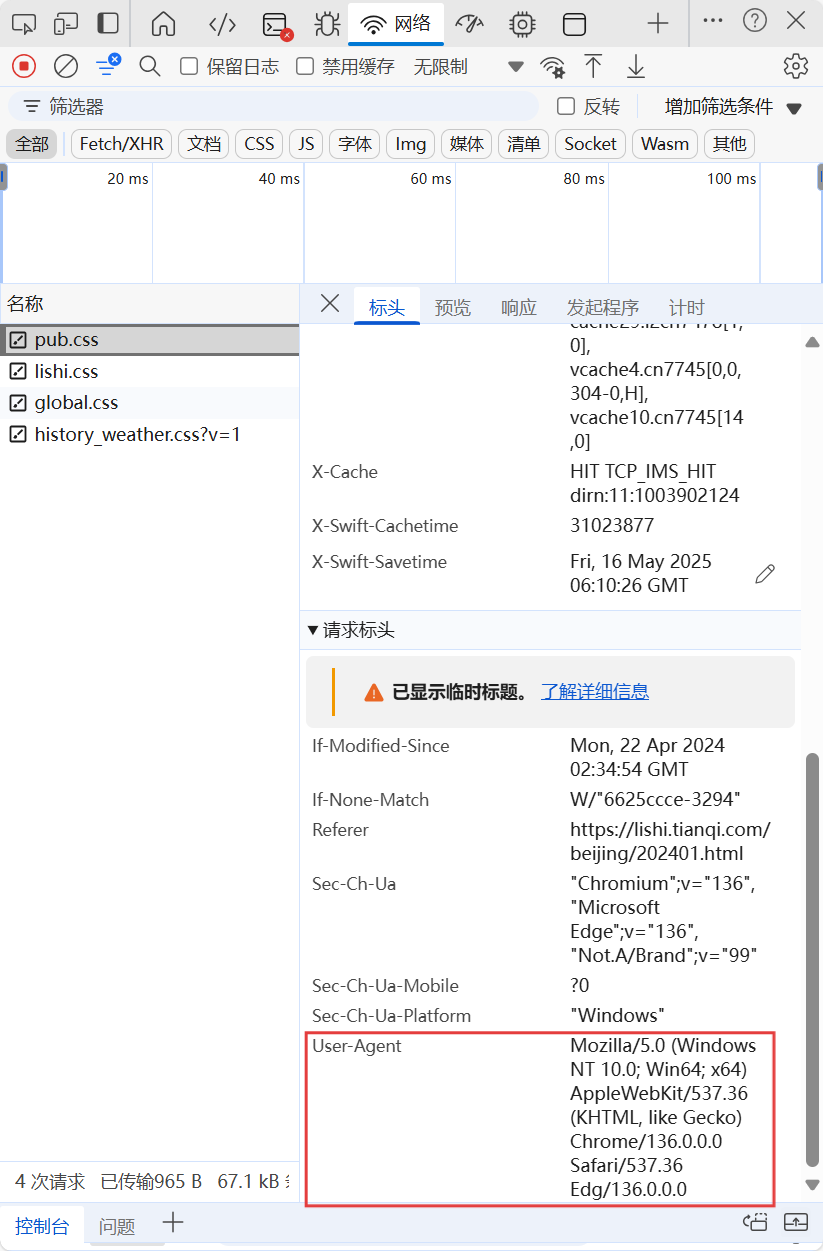
那么如何来获取到本机中浏览器的请求头信息呢,可以按照如下操作来获取:打开浏览器,访问任意网站,右键点击页面 → 检查,切换到 Network(网络) 点击一个请求→ 在右侧找到 Headers(标头)。
向下滚动到 Request Headers(请求标头) 部分,复制完整的 User-Agent 值。
# 请求 接收到了响应数据
resp = requests.get(url, headers=headers)
# 数据预处理
resp_html = etree.HTML(resp.text)
# xpath提取所有数据
resp_list = resp_html.xpath("//ul[@class='thrui']/li")
- requests.get()向目标URL发送HTTP GET请求,获取服务器的响应数据
- etree.HTML()将HTML内容解析为一个结构化的Element对象。
- 使用xpath()方法和XPath表达式提取所有包含天气数据的<li>元素。
观察要爬取的网页数据如下:
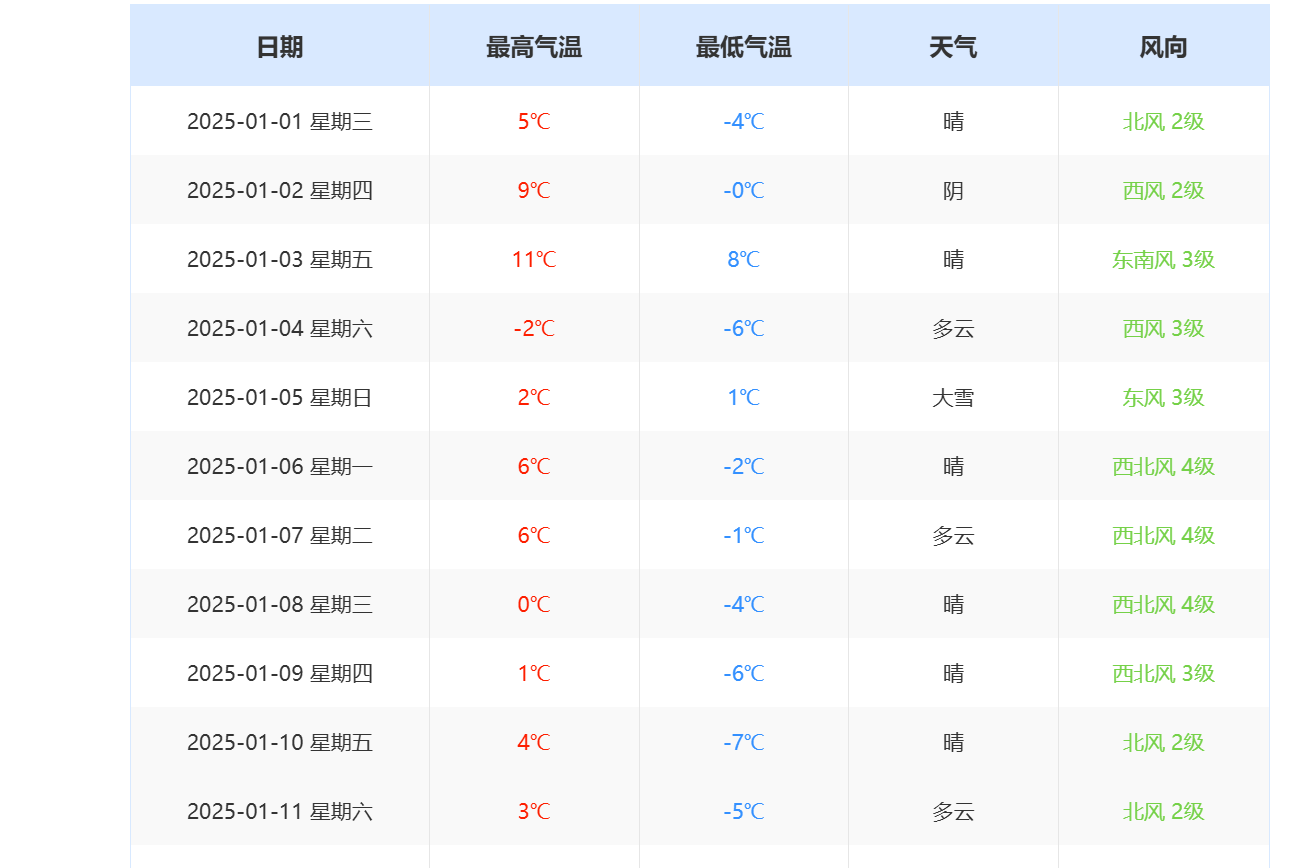
故下面代码通过xpath来筛选出日期、最高气温、最低气温和天气这几条信息:
# for循环迭代遍历
for li in resp_list:
day_weather_info = {}
# 日期
day_weather_info['date_time'] = li.xpath("./div[1]/text()")[0].split(' ')[0]
# 最高气温 (包含摄氏度符号)
high = li.xpath("./div[2]/text()")[0]
day_weather_info['high'] = high[:high.find('℃')]
# 最低气温
low = li.xpath("./div[3]/text()")[0]
day_weather_info['low'] = low[:low.find('℃')]
# 天气
day_weather_info['weather'] = li.xpath("./div[4]/text()")[0]
weather_info.append(day_weather_info)
return weather_info
2.3 获取网页中一年的城市天气数据
weathers = []
# for循环生成有顺序的1-12
for month in range(1, 13):
# 获取某一月的天气信息
# 三元表达式
weather_time = '2022' + ('0' + str(month) if month < 10 else str(month))
print(weather_time)
url = f'https://lishi.tianqi.com/changsha/{weather_time}.html'
# 爬虫获取这个月的天气信息
weather = getWeather(url)
# 存到列表中
weathers.append(weather)
print(weathers)
由于要爬取一整年的数据,故通过for month in range(1, 13):遍历整年数据
观察要爬取的页面的URL如下
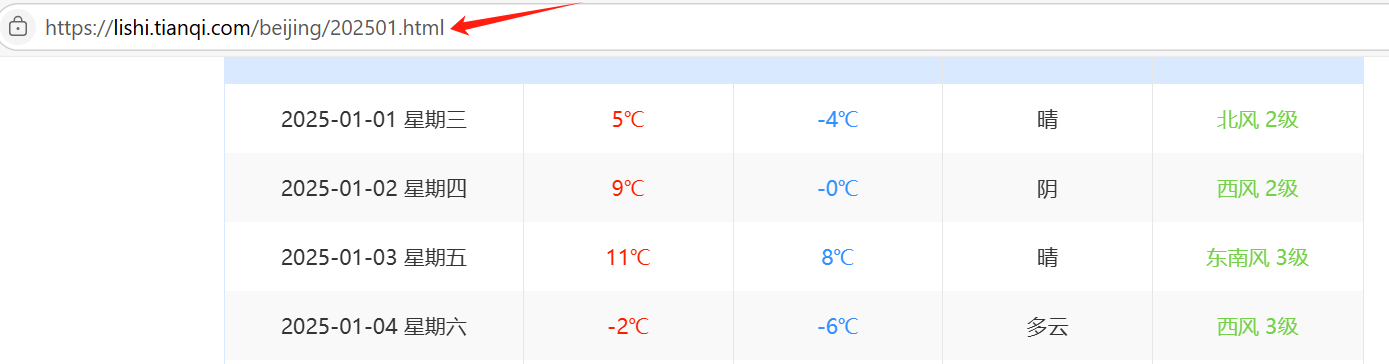
故通过以下方式来筛选月份,由于月份小于10时前面要加0,故增加条件语句来选择 weather_time = '2024' + ('0' + str(month) if month < 10 else str(month))
之后调用getWeather(url)函数来获取网页中的数据,并将数据增加到列表weathers中
2.4 将获取到的数据写入weather.csv文件中
# 数据写入(一次性写入)
with open("weather.csv", "w", newline='') as csvfile:
writer = csv.writer(csvfile)
# 先写入列名:columns_name 日期 最高气温 最低气温 天气
writer.writerow(["日期", "最高气温", "最低气温", '天气'])
# 一次写入多行用writerows(写入的数据类型是列表,一个列表对应一行)
list_year = []
for month_weather in weathers:
for day_weather_dict in month_weather:
list_year.append(list(day_weather_dict.values()))
writer.writerows(list_year)
- 打开或创建csv文件
![]()
with open()是Python中用于打开文件的上下文管理器,它会自动处理文件的打开和关闭操作。
"weather.csv"是文件名,表示要创建或打开一个名为weather.csv的文件。
"w"表示以写入模式打开文件,如果文件已经存在,会清空文件内容;如果文件不存在,则创建新文件。
newline=''用于避免在写入CSV文件时出现多余的空行问题,特别是在不同操作系统中换行符处理不同。 - 创建CSV写入器对象
![]()
csv.writer()是Python中csv模块的一个类,用于将数据写入CSV文件。
writer是一个CSV写入器对象,通过它可以方便地将数据写入到CSV文件中。 - 写入列名
![]()
writer.writerow()是CSV写入器对象的一个方法,用于写入一行数据。
这里的参数是一个列表["日期", "最高气温", "最低气温", '天气'],表示CSV文件的列名。
这行代码会在CSV文件的第一行写入这四个列名,方便后续查看和分析数据时理解每一列的含义。 - 准备写入的数据
![]()
list_year是一个空列表,用于存储所有天气数据。
外层循环for month_weather in weathers遍历weathers列表,weathers列表中存储的是每个月的天气数据。
内层循环for day_weather_dict in month_weather遍历每个月的天气数据,day_weather_dict是一个字典,表示某一天的天气信息。
list(day_weather_dict.values())将字典的值提取出来并转换为列表
list_year.append()将这个列表添加到list_year中。
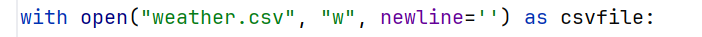



2.5 csv文件结果
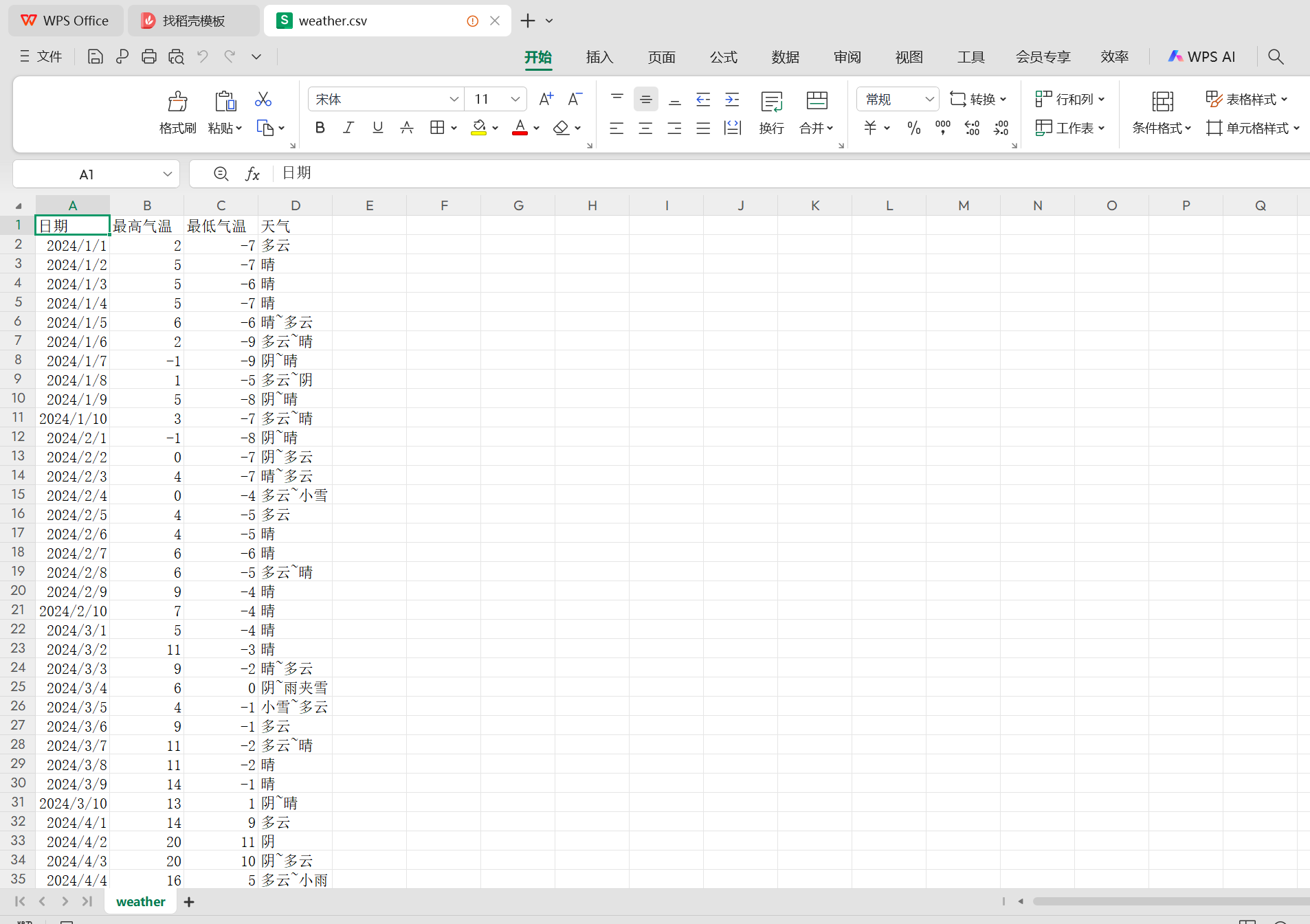
2.6 爬取数据部分源码
#-*- coding: utf-8 -*-
import requests # 模拟浏览器进行网络请求
from lxml import etree # 进行数据预处理
import csv # 写入csv文件
def getWeather(url):
weather_info = [] # 新建一个列表,将爬取的每月数据放进去
# 请求头信息:浏览器版本型号,接收数据的编码格式
headers = {
# 必填,不填拿不到数据
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0'
}
# 请求 接收到了响应数据
resp = requests.get(url, headers=headers)
# 数据预处理
resp_html = etree.HTML(resp.text)
# xpath提取所有数据
resp_list = resp_html.xpath("//ul[@class='thrui']/li")
# for循环迭代遍历
for li in resp_list:
day_weather_info = {}
# 日期
day_weather_info['date_time'] = li.xpath("./div[1]/text()")[0].split(' ')[0]
# 最高气温 (包含摄氏度符号)
high = li.xpath("./div[2]/text()")[0]
day_weather_info['high'] = high[:high.find('℃')]
# 最低气温
low = li.xpath("./div[3]/text()")[0]
day_weather_info['low'] = low[:low.find('℃')]
# 天气
day_weather_info['weather'] = li.xpath("./div[4]/text()")[0]
weather_info.append(day_weather_info)
return weather_info
weathers = []
# for循环生成有顺序的1-12
for month in range(1, 13):
# 获取某一月的天气信息
# 三元表达式
weather_time = '2024' + ('0' + str(month) if month < 10 else str(month))
print(weather_time)
url = f'https://lishi.tianqi.com/beijing/{weather_time}.html'
# 爬虫获取这个月的天气信息
weather = getWeather(url)
# 存到列表中
weathers.append(weather)
print(weathers)
# 数据写入(一次性写入)
with open("weather.csv", "w", newline='') as csvfile:
writer = csv.writer(csvfile)
# 先写入列名:columns_name 日期 最高气温 最低气温 天气
writer.writerow(["日期", "最高气温", "最低气温", '天气'])
# 一次写入多行用writerows(写入的数据类型是列表,一个列表对应一行)
list_year = []
for month_weather in weathers:
for day_weather_dict in month_weather:
list_year.append(list(day_weather_dict.values()))
writer.writerows(list_year)
3.利用pandas库绘制天气轮播图
3.1 导入包
import requests # 模拟浏览器进行网络请求
from lxml import etree # 进行数据预处理
import csv # 写入csv文件
- pandas: 用于数据处理和分析。
- pyecharts: 一个用于生成Echarts图表的Python库,这里我们导入options(图表配置项)和三种图表:饼图(Pie)、柱状图(Bar)和时间线(Timeline)
3.2读取数据
df = pd.read_csv('weather.csv', encoding='gb18030')
- 使用pandas的read_csv函数读取名为weather.csv的文件,并指定编码为gb18030(一种支持中文的编码格式)
3.3数据处理
# datatime Series DataFrame 日期格式的数据类型 month
df['日期'] = df['日期'].apply(lambda x: pd.to_datetime(x))
# 新建一列月份数据(将日期中的月份month 一项单独拿取出来)
df['month'] = df['日期'].dt.month
- df['日期'].apply(lambda x: pd.to_datetime(x)): 将“日期”列中的每个元素转换为pandas的datetime对象。
- df['日期'].dt.month: 从datetime对象中提取月份(1到12),并赋值给新列month。
3.4数据聚合
# DataFrame GroupBy聚合对象 分组和统计的 size()能够计算分组的大小
df_agg = df.groupby(['month','天气']).size().reset_index()
# 设置下这3列的列名
df_agg.columns = ['month','tianqi','count']
- groupby(['month','天气']): 按照月份和天气进行分组。
- .size(): 计算每个组的大小(该月该天气出现的天数)。
- .reset_index(): 将分组后的结果转换回DataFrame格式。默认情况下,groupby操作后会产生一个多级索引,reset_index将其变为普通列。
- 将聚合后的DataFrame的列名重命名为['month','tianqi','count'],分别代表月份、天气和出现次数。
3.5创建时间轮播图
# 画图
# 实例化一个时间序列的对象
timeline = Timeline()
# 播放参数:设置时间间隔 1s 单位是:ms(毫秒)
timeline.add_schema(play_interval=1000) # 单位是:ms(毫秒)
3.6循环生成每个月份的柱状图并添加到时间线
# 循环遍历df_agg['month']里的唯一值
for month in df_agg['month'].unique():
data = (
df_agg[df_agg['month']==month][['tianqi','count']]
.sort_values(by='count',ascending=True)
.values.tolist()
)
# print(data)
# 绘制柱状图
bar = Bar()
# x轴是天气名称
bar.add_xaxis([x[0] for x in data])
# y轴是出现次数
bar.add_yaxis('',[x[1] for x in data])
# 让柱状图横着放
bar.reversal_axis()
# 将计数标签放置在图形右边
bar.set_series_opts(label_opts=opts.LabelOpts(position='right'))
# 设置下图表的名称
bar.set_global_opts(title_opts=opts.TitleOpts(title='北京2024年每月天气变化 '))
# 将设置好的bar对象放置到时间轮播图当中,并且标签选择月份 格式为: 数字月
timeline.add(bar, f'{month}月')
3.6.1循环处理每个月的数据
for month in df_agg['month'].unique():
- 循环遍历数据中存在的所有唯一月份值(1-12月)
- 对每个月份单独处理,创建一个相应的图表
3.6.2准备当月数据
data = (
df_agg[df_agg['month']==month][['tianqi','count']]
.sort_values(by='count',ascending=True)
.values.tolist()
)
- 筛选当月数据:df_agg[df_agg['month']==month] 选择当前月份的所有行
- 选择特定列:[['tianqi','count']] 保留天气类型和出现次数两列
- 排序:.sort_values(by='count',ascending=True) 按天气出现次数升序排序
- 转换为列表:.values.tolist() 将数据转换为列表格式 - 输出示例:[['多云', 8], ['晴', 10], ['雨', 15]]
3.6.3创建柱状图对象
bar = Bar()
- 实例化一个柱状图对象
- 为当前月份创建新图表
3.6.4设置X轴数据(天气类型)
bar.add_xaxis([x[0] for x in data])
- X轴使用天气类型:[x[0] for x in data]
- 例如:['多云','晴','雨']
- 使用列表推导式提取列表中每个元素的第一个值(天气类型)
3.6.5设置Y轴数据(出现次数)
bar.add_yaxis('',[x[1] for x in data])
- Y轴使用天气出现的天数:[x[1] for x in data]例如:[8, 10, 15]
- 使用列表推导式提取列表中每个元素的第二个值(出现次数)
- 空字符串''表示该数据系列没有名称(不在图例中显示)
3.6.6将柱状图横向显示
bar.reversal_axis()
- 将柱状图从垂直方向转为水平方向
- 效果:天气类型在Y轴垂直显示,数值在X轴水平表示
- 优势:长文本(天气类型名称)在垂直方向阅读更清晰
3.6.7设置标签显示位置
bar.set_series_opts(label_opts=opts.LabelOpts(position='right'))
- 将数值标签显示在每个柱形条的右侧
- 视觉效果:多云 ████████ 8天
- position='right'确保标签不会遮挡条形的视觉表达
3.6.8设置图表标题
bar.set_global_opts(title_opts=opts.TitleOpts(title='北京2024年每月天气变化'))
- 设置图表主标题为"北京2024年每月天气变化"
3.6.9将图表添加到时间轮播中
timeline.add(bar, f'{month}月')
- 将当前创建的柱状图添加到时间轮播组件中
- 设置该时间点的标签为"X月"格式(例如"1月","2月")
- 时间轮播会根据月份顺序自动排列这些图表
3.7生成HTML文件
# 将设置好的图表保存为'weathers.html'文件
timeline.render('weathers1.html')
- 最终将完整的时间轮播图生成为HTML文件weathers1.html
- HTML文件是独立交互式图表,可直接在浏览器中打开使用
3.8生成的HTML文件展示结果
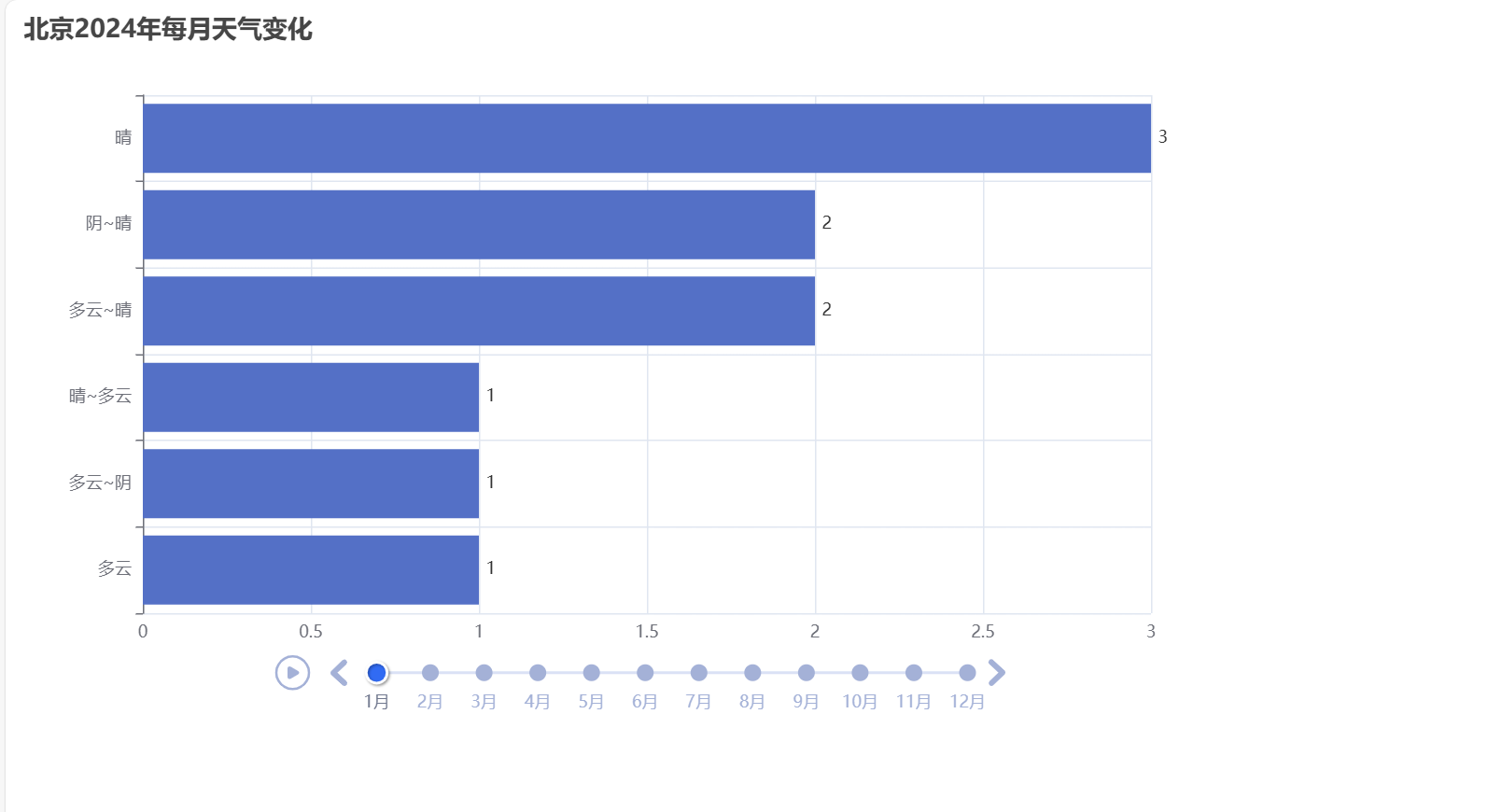
3.9完整的轮播图展示代码
#-*- coding: utf-8 -*-
# 数据分析 读取 处理 存储
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Pie ,Bar,Timeline
# 用pandas.read_csv()读取指定的excel文件,选择编码格式gb18030(gb18030范围比)
df = pd.read_csv('weather.csv', encoding='gb18030')
# datatime Series DataFrame 日期格式的数据类型 month
df['日期'] = df['日期'].apply(lambda x: pd.to_datetime(x))
# 新建一列月份数据(将日期中的月份month 一项单独拿取出来)
df['month'] = df['日期'].dt.month
# DataFrame GroupBy聚合对象 分组和统计的 size()能够计算分组的大小
df_agg = df.groupby(['month','天气']).size().reset_index()
# 设置下这3列的列名
df_agg.columns = ['month','tianqi','count']
# 画图
# 实例化一个时间序列的对象
timeline = Timeline()
# 播放参数:设置时间间隔 1s 单位是:ms(毫秒)
timeline.add_schema(play_interval=1000) # 单位是:ms(毫秒)
# 循环遍历df_agg['month']里的唯一值
for month in df_agg['month'].unique():
data = (
df_agg[df_agg['month']==month][['tianqi','count']]
.sort_values(by='count',ascending=True)
.values.tolist()
)
# print(data)
# 绘制柱状图
bar = Bar()
# x轴是天气名称
bar.add_xaxis([x[0] for x in data])
# y轴是出现次数
bar.add_yaxis('',[x[1] for x in data])
# 让柱状图横着放
bar.reversal_axis()
# 将计数标签放置在图形右边
bar.set_series_opts(label_opts=opts.LabelOpts(position='right'))
# 设置下图表的名称
bar.set_global_opts(title_opts=opts.TitleOpts(title='北京2024年每月天气变化 '))
# 将设置好的bar对象放置到时间轮播图当中,并且标签选择月份 格式为: 数字月
timeline.add(bar, f'{month}月')
# 将设置好的图表保存为'weathers.html'文件
timeline.render('weathers1.html')
4.完整结果视频展示
(二)利用大模型进行文档查重
1.项目简介
本查重系统主要是针对我们大创的竞赛管理系统进行设计,通过Python调用大模型设计一个带查重功能的服务器,
再在我们通过Vue3+SpringBoot3搭建的系统中调用该Python功能的API来实现文件查重的功能,在其中增加了输出相同小组成员数和小组成员的名称来更好地判断项目的重复性。
2.实现过程
2.1 导入包
import torch
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import re
import jieba
import os
import itertools
from docx import Document
import concurrent.futures
from concurrent.futures import ThreadPoolExecutor # 添加这行
import tempfile
from flask import Flask, request, jsonify, send_file
from flask_cors import CORS
- torch:是PyTorch库的核心模块,提供了张量、数学运算、数据类型转换、随机数生成线性代数运算、自动微分、存储和序列化、多GPU支持、神经网络层与优化器等功能。
- Numpy:是Python中一个强大的科学计算库,主要用于处理多维数组和矩阵运算。它提供了大量的数学函数库,支持数组运算、线性代数、随机数生成等功能
- sentence - transformers:主要用于获取文本的语义向量表示。它基于预训练的 transformers 模型(如 BERT),能够将文本转换为固定长度的向量,这些向量能够捕捉文本的语义信息。
- sklearn.metrics.pairwise:其中的 cosine - similarity 函数用于计算两个向量之间的余弦相似度。余弦相似度是衡量文本向量之间相似程度的一种常用方法,它通过计算向量之间的夹角余弦值来反映向量在语义空间中的接近程度。在文本匹配、推荐系统等场景中,可以利用它来判断文本之间的相似性,本系统就采用该方法来计算文本相似度。
- re:是 Python 的正则表达式库。它可以用于文本的模式匹配、替换等操作。例如,在文本预处理阶段,可以使用正则表达式去除文本中的无用字符(如标点符号、特殊符号等),或者提取特定格式的内容(如日期、电话号码等)。
- jieba:是一个中文文本处理库,主要用于中文分词。它可以将连续的中文文本切分成一个个有意义的词汇单元,这对于后续的文本分析(如词频统计、关键词提取等)和自然语言处理任务(如文本分类、情感分析等)是基础且重要的步骤。
- os:主要用于操作系统的交互,如文件和目录的操作。可以获取文件路径、创建目录、读取文件内容等。在处理文件读取和写入任务时,它提供了与操作系统兼容的接口,方便程序在不同的操作系统环境下对文件系统进行操作。
- itertools:提供了一系列用于创建迭代器的工具函数。它可以帮助用户高效地处理迭代操作,如生成排列组合、笛卡尔积等。在处理数据集的组合运算或者循环操作时,可以利用 itertools 来简化代码和提高效率。
- docx:是用于操作 Word 文档的库。可以通过它读取 Word 文档的内容(包括文本、表格等)、修改文档内容或者创建新的 Word 文档。在需要处理 Word 文档格式的文本数据时非常有用,例如从 Word 文档中提取文本用于后续的文本处理任务。
- concurrent.futures:提供了高层次的并行编程接口。它允许用户以异步的方式执行任务,通过线程池(ThreadPoolExecutor)或进程池来实现任务的并行处理。这可以提高程序的执行效率,特别是在处理大量独立任务或者耗时的 I/O 操作时。
- tempfile:用于生成临时文件和目录。在程序运行过程中,如果需要临时存储一些数据(如中间结果等)但不想保存到正式的文件系统中,可以使用 tempfile 来创建临时文件,程序结束后这些临时文件会自动被清理。
- flask:是一个轻量级的 Python Web 框架。可以用于构建 Web 服务,接收客户端的请求并返回响应。在这里,它用于搭建一个后端服务来处理文本相关的请求,比如接收用户上传的文档、返回文本处理结果等,并且通过路由和视图函数来定义服务的接口,本项目中就通过该框架来提供API。
- flask_cors:主要用于解决跨域问题。在 Web 开发中,当前端和后端服务不在同一个域下时,浏览器会阻止跨域请求。flask_cors 可以为 Flask 应用添加跨域资源共享(CORS)支持,使得前端应用能够正常地与后端服务进行通信,接收和发送数据。
2.2 配置参数
# ================ 配置参数 ================
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
SUPPORTED_EXT = ['.txt', '.docx']
BATCH_SIZE = 32
MAX_SEQ_LENGTH = 100 # 增大模型最大序列长度(根据所选模型支持的最大值调整)
- DEVICE:含义: 用于指定程序运行时使用的硬件设备。'cuda' 表示使用 NVIDIA GPU 进行加速(如果可用),'cpu' 表示使用中央处理器。在深度学习任务中,使用 GPU 可以显著加速模型的训练和推理过程。此参数会根据系统是否支持 CUDA 自动选择设备。
- SUPPORTED_EXT: 定义程序支持处理的文件扩展名列表。['.txt', '.docx'] 表示支持文本文件和 Word 文档。程序会根据此列表过滤文件夹中的文件,只处理支持的文件类型。
- BATCH_SIZE: 定义模型处理文本时的批量大小。32 表示每次处理 32 条文本数据。批量处理可以提高效率,但过大的批量可能增加内存占用。需要根据硬件资源(如显存大小)进行调整。
- MAX_SEQ_LENGTH:定义模型处理文本时的最大序列长度。100 表示文本会被截断或填充到 100 个字符。限制输入文本长度可以防止过长文本导致的内存问题,并确保模型处理效率。
2.3 文本初始化处理类
class OptimizedTextProcessor:
"""优化版文本处理器"""
def __init__(self):
self.stopwords = self._load_stopwords()
jieba.initialize()
def _load_stopwords(self):
try:
with open('data/stopwords.txt', 'r', encoding='utf-8') as f:
return set(line.strip() for line in f)
except FileNotFoundError:
return {'的', '了', '在', '是', '和', '就', '也', '都', '这'}
def fast_segment(self, text):
with ThreadPoolExecutor() as executor:
chunks = [text[i:i + 10000] for i in range(0, len(text), 10000)]
results = executor.map(jieba.lcut, chunks)
words = list(itertools.chain(*results))
return [w for w in words if w not in self.stopwords and len(w) > 1]
def clean_text(self, text):
# 增强清洗规则:仅保留中文字符和空格(原规则保留了字母数字)
text = re.sub(r'[^\u4e00-\u9fa5\s]', '', text) # 去除所有非中文字符和标点
return re.sub(r'\s+', ' ', text).strip() # 合并连续空格
定义一个文本初始化处理的类,里面包含以下函数:
- __init__ :
作用:构造函数,初始化 OptimizedTextProcessor 类的实例。
执行操作:加载停用词列表(通过调用 _load_stopwords 方法)。初始化 jieba 分词器(调用 jieba.initialize())。 - _load_stopwords :
作用:加载停用词集合。
执行操作:从文件 'data/stopwords.txt' 中读取停用词,每行一个停用词,这里面我在stopwords.txt中写入大量停用词。如果文件不存在,则返回一个默认的停用词集合(包含一些常见的中文助词等)。
![]()
- fast_segment :
作用:快速对文本进行分词处理。
执行操作:将长文本分割成多个小块(每块长度为10000字符)。使用线程池并行地对每个小块进行 jieba 分词(调用 jieba.lcut)。将分词结果合并成一个列表,并移除停用词和长度小于等于1的词。 - clean_text :
作用:清洗文本数据。
执行操作:使用正则表达式移除所有非中文字符和非字母数字字符(只保留中文、字母、数字和空格)。合并连续的空格,并去除首尾的空格。
2.4 相似度检测类
class FastBertSimilarity:
"""高效相似度计算引擎"""
def __init__(self, model_path=r'C:\Users\asus\Desktop\总文件夹\大学相关\大二下\wyy_-python_-experiment\第四次实验\AIxm\same\model\paraphrase-multilingual-MiniLM-L12-v2'):
self.processor = OptimizedTextProcessor()
self.model = SentenceTransformer(model_path, device=DEVICE)
self.model.max_seq_length = MAX_SEQ_LENGTH
def _get_embeddings_batch(self, texts):
return self.model.encode(
texts,
batch_size=BATCH_SIZE,
show_progress_bar=False,
convert_to_numpy=True,
normalize_embeddings=True
)
def process_files(self, folder_path, output_file=None):
file_contents = self._parallel_load_files(folder_path)
if len(file_contents) < 2:
raise ValueError("需要至少2个文件进行比对")
filenames, texts = zip(*file_contents.items())
embeddings = self._get_embeddings_batch(texts)
sim_matrix = cosine_similarity(embeddings)
results = []
indices = np.triu_indices_from(sim_matrix, k=1)
for i, j in zip(*indices):
# 将numpy类型转换为Python原生float
similarity = float(np.around(sim_matrix[i, j], 4))
results.append({
"file1": filenames[i],
"file2": filenames[j],
"similarity": similarity # 使用原生float
})
results.sort(key=lambda x: x["similarity"], reverse=True)
if output_file:
self._save_results(results, output_file)
return results
def _parallel_load_files(self, folder_path):
"""并行加载文件夹中的所有文件内容"""
file_contents = {}
with ThreadPoolExecutor() as executor:
# 获取所有支持的文件
files = [
f for f in os.listdir(folder_path)
if any(f.lower().endswith(ext) for ext in SUPPORTED_EXT)
]
# 并行处理每个文件
futures = {
executor.submit(self._process_single_file, os.path.join(folder_path, f)): f
for f in files
}
# 收集结果
for future in concurrent.futures.as_completed(futures):
filename = futures[future]
try:
content = future.result()
if content: # 只保留有内容的文件
file_contents[filename] = content
except Exception as e:
print(f"处理文件 {filename} 时出错: {str(e)}")
return file_contents
def _process_single_file(self, file_path):
"""处理单个文件"""
filename = os.path.basename(file_path)
try:
if filename.endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
elif filename.endswith('.docx'):
doc = Document(file_path)
content = '\n'.join([para.text for para in doc.paragraphs])
else:
return None
return self.processor.clean_text(content) if content.strip() else None
except Exception as e:
print(f"读取文件 {filename} 失败: {str(e)}")
return None
# 在FastBertSimilarity类中添加方法
def analyze_group_members(self, file_contents):
member_sets = {}
for filename, content in file_contents.items():
# 提取小组成员(保持原有正则匹配逻辑)
match = re.search(r'小组成员[::]\s*((?:[\u4e00-\u9fa5]+\s*)+)', content)
if not match:
continue
members = set(m.strip() for m in match.group(1).split() if m.strip())
if len(members) < 2:
continue
member_sets[filename] = members
# 计算相同成员数量和具体名单
same_member_counts = []
filenames = list(member_sets.keys())
for i in range(len(filenames)):
for j in range(i + 1, len(filenames)):
file1 = filenames[i]
file2 = filenames[j]
common_members = member_sets[file1] & member_sets[file2]
same_count = len(common_members)
if same_count > 0:
same_member_counts.append({
"file1": file1,
"file2": file2,
"same_member_count": same_count,
"same_members": list(common_members) # 新增具体成员名单字段
})
return same_member_counts
- __init__:
作用:构造函数,用于初始化 FastBertSimilarity 类的实例。
执行操作:初始化一个 OptimizedTextProcessor 实例,用于文本处理。加载一个预训练的 BERT 模型(SentenceTransformer),并指定设备(CPU 或 GPU)。设置模型的最大序列长度。 - _get_embeddings_batch:
作用: 批量获取文本的嵌入向量。
执行操作:使用加载的 BERT 模型对输入文本进行编码。指定批量大小、隐藏进度条、输出为 NumPy 数组,并对嵌入向量进行归一化。 - process_files:
作用: 处理文件夹中的文件,计算文件之间的相似度。
执行操作:并行加载文件夹中的文件内容。如果文件数量少于2个,抛出异常。提取文件名和文本内容。生成文本的嵌入向量。计算嵌入向量之间的余弦相似度。返回文件对及其相似度的排序结果。 - _parallel_load_files:
作用: 并行加载文件夹中的所有文件内容。
执行操作:使用线程池并行处理每个文件。收集并返回文件内容。 - _process_single_file:
作用: 处理单个文件。
执行操作:根据文件扩展名读取文件内容。清洗文本内容并返回。 - analyze_group_members:
作用: 分析文件中提到的小组成员。
执行操作:提取文件中提到的小组成员。计算不同文件之间共享的小组成员数量。
2.5 Flask应用初始化
# ================ Flask应用初始化 ================
app = Flask(__name__)
CORS(app, resources={
r"/api/*": {
"origins": ["http://localhost:*", "http://127.0.0.1:*"],
"methods": ["GET", "POST", "OPTIONS"],
"allow_headers": ["Content-Type"]
}
})
analyzer = FastBertSimilarity()
这段代码的作用是初始化一个 Flask Web 应用,并配置其支持跨域请求,以便前端应用(例如运行在 http://localhost 或 http://127.0.0.1 上的 Web 页面)可以向后端 API 发送请求。
同时,它还创建了一个用于文本相似度分析的实例 analyzer,这个实例将在处理 API 请求时用于分析上传的文件并计算相似度。
2.6 启动服务处理POST请求
# ================ API路由 ================
@app.route('/')
def index():
return "文本相似度分析服务已启动,请使用/api/analyze接口"
# 修改analyze_documents路由中的方法调用
@app.route('/api/analyze', methods=['POST'])
def analyze_documents():
# 检查请求是否包含文件
if not request.files:
print("错误: 请求中未包含文件")
return jsonify({"code": 400, "msg": "未上传文件"}), 400
files = request.files.getlist('files')
if len(files) < 2:
return jsonify({"code": 400, "msg": "至少需要2个文件"}), 400
with tempfile.TemporaryDirectory() as temp_dir:
saved_files = []
for file in files:
if not file or file.filename == '':
continue
if not any(file.filename.lower().endswith(ext) for ext in SUPPORTED_EXT):
continue
try:
# 直接使用原始文件名,不进行secure_filename处理
filename = file.filename
file_path = os.path.join(temp_dir, filename)
file.save(file_path)
saved_files.append(filename)
print(f"成功保存文件: {filename}")
except Exception as e:
print(f"文件保存失败: {str(e)}")
continue
if len(saved_files) < 2:
return jsonify({"code": 400, "msg": "有效文件不足2个"}), 400
try:
# 读取文件内容
file_contents = {}
for filename in saved_files:
file_path = os.path.join(temp_dir, filename)
try:
if filename.endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
elif filename.endswith('.docx'):
doc = Document(file_path)
content = '\n'.join([para.text for para in doc.paragraphs])
if not content.strip():
continue
file_contents[filename] = content
except Exception as e:
print(f"文件处理错误: {filename}, 错误: {str(e)}")
continue
if len(file_contents) < 2:
return jsonify({"code": 400, "msg": "有效内容文件不足2个"}), 400
# 执行分析
results = analyzer.process_files(temp_dir)
member_results = analyzer.analyze_group_members(file_contents) # 使用正确的方法名
return jsonify({
"code": 200,
"message": "分析成功",
"data": {
"pairwise_results": results,
"member_results": member_results,
"summary": _generate_summary(results)
}
})
except Exception as e:
print(f"分析过程中发生错误: {str(e)}")
return jsonify({
"code": 500,
"message": f"分析失败: {str(e)}",
"data": None
}), 500
def _generate_summary(results):
similarities = [x["similarity"] for x in results if isinstance(x.get("similarity"), (float, int))]
if not similarities:
return {
"total_pairs": 0,
"max": 0.0,
"min": 0.0,
"average": 0.0
}
# 确保所有统计值都是原生Python类型
return {
"total_pairs": len(results),
"max": float(np.around(max(similarities), 4)),
"min": float(np.around(min(similarities), 4)),
"average": float(np.around(np.mean(similarities), 4))
}
# 修改process_files方法中的结果处理
def process_files(self, folder_path, output_file=None):
file_contents = self._parallel_load_files(folder_path)
if len(file_contents) < 2:
raise ValueError("需要至少2个文件进行比对")
filenames, texts = zip(*file_contents.items())
embeddings = self._get_embeddings_batch(texts)
sim_matrix = cosine_similarity(embeddings)
results = []
indices = np.triu_indices_from(sim_matrix, k=1)
for i, j in zip(*indices):
results.append({
"file1": filenames[i],
"file2": filenames[j],
"similarity": float(np.float64(round(sim_matrix[i][j], 4))) # 双重转换确保
})
results.sort(key=lambda x: x["similarity"], reverse=True)
if output_file:
self._save_results(results, output_file)
return results
def _process_single_file(self, file_path):
"""处理单个文件"""
filename = os.path.basename(file_path)
try:
if filename.endswith('.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
elif filename.endswith('.docx'):
doc = Document(file_path)
content = '\n'.join([para.text for para in doc.paragraphs])
else:
return None
return self.processor.clean_text(content) if content.strip() else None
except Exception as e:
print(f"读取文件 {filename} 失败: {str(e)}")
return None
def _parallel_load_files(self, folder_path):
"""并行加载文件夹中的所有文件内容"""
file_contents = {}
with ThreadPoolExecutor() as executor:
# 获取所有支持的文件
files = [
f for f in os.listdir(folder_path)
if any(f.lower().endswith(ext) for ext in SUPPORTED_EXT)
]
# 并行处理每个文件
futures = {
executor.submit(self._process_single_file, os.path.join(folder_path, f)): f
for f in files
}
# 收集结果
for future in concurrent.futures.as_completed(futures):
filename = futures[future]
try:
content = future.result()
if content: # 只保留有内容的文件
file_contents[filename] = content
except Exception as e:
print(f"处理文件 {filename} 时出错: {str(e)}")
return file_contents
- index函数:
作用: 定义了 Flask 应用的根路由 /。
执行操作: 当用户访问应用的根 URL 时,返回一条提示消息,告知用户服务已启动,并引导用户使用 /api/analyze 接口进行文本相似度分析。 - analyze_documents函数:
作用: 定义了 /api/analyze 路由,用于处理文本相似度分析的 POST 请求。
执行操作:
检查请求是否包含文件:如果请求中没有文件,返回 400 错误。
检查文件数量:如果上传的文件少于 2 个,返回 400 错误。
保存文件:使用 tempfile.TemporaryDirectory 创建一个临时目录,用于存储上传的文件。遍历上传的文件,检查文件扩展名是否支持(.txt 或 .docx)。将文件保存到临时目录中。
检查有效文件数量:如果有效文件少于 2 个,返回 400 错误。
读取文件内容:遍历保存的文件,读取每个文件的内容。对于 .txt 文件,直接读取内容。对于 .docx 文件,使用 python-docx 库提取内容。
检查有效内容文件数量:如果有效内容文件少于 2 个,返回 400 错误。
调用 analyzer.process_files 方法计算文件之间的相似度。调用 analyzer.analyze_group_members 方法分析文件中的小组成员。并返回一个 JSON 响应,包含分析结果、小组成员分析结果和相似度摘要。 - _generate_summary函数:
作用: 生成相似度分析的摘要信息。
执行操作:提取相似度结果中的相似度值。如果没有相似度值,返回默认的摘要信息。计算相似度值的总数、最大值、最小值和平均值。返回包含这些统计信息的字典。 - process_files方法:
作用: 处理文件夹中的文件,计算文件之间的相似度。
执行操作:并行加载文件夹中的文件内容。如果文件数量少于 2 个,抛出异常。提取文件名和文本内容。生成文本的嵌入向量。计算嵌入向量之间的余弦相似度。返回文件对及其相似度的排序结果。 - _process_single_file方法:
作用: 处理单个文件,提取文件内容并进行清洗。
执行操作:根据文件扩展名读取文件内容。对于 .txt 文件,直接读取内容。对于 .docx 文件,使用 python-docx 库提取内容。清洗文本内容并返回。 - _parallel_load_files方法:
作用: 并行加载文件夹中的所有文件内容。
执行操作:使用线程池并行处理每个文件。收集并返回文件内容。
2.7 启动Flask服务
if __name__ == "__main__":
# 直接运行时启动Flask服务
app.run(host='0.0.0.0', port=5001, debug=True, threaded=True)
2.8 在springboot中引入该python功能
2.7.1 先添加依赖
<!-- 文件上传支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>commons-fileupload</groupId>
<artifactId>commons-fileupload</artifactId>
<version>1.5</version>
</dependency>
- spring-boot-starter-web
核心功能:
MVC框架支持:提供Spring Web MVC框架,处理HTTP请求
内置Servlet容器:默认包含Tomcat作为嵌入式服务器
REST API支持:帮助开发RESTful Web服务
Web基础功能:处理表单提交、参数绑定等
文件上传功能:
核心文件上传支持:通过MultipartFile接口处理文件上传
自动配置:Spring Boot会自动配置上传处理组件
文件大小限制:提供默认配置,也可以通过application.properties自定义
2.7.2 在application.yml文件中增加服务

之后就可在后端中调用此功能
3.完整结果视频展示
三、实验过程中遇到的问题和解决过程
【1】 爬取天气及可视化
- 问题1:刚开始的时候爬虫被浏览器拒绝了
- 问题1解决方案:增加浏览器请求头信息,模仿浏览器发起请求就通过了
![]()

【2】 文档相似度查找
- 问题1:前段代码乱码
- 问题1解决方案:当时的编码没有统一,导致最后出现乱码,统一后端和python中的代码均为UTF-8即正确
后端中:
python中:

四、其他(感悟、思考等)
【1】 实验感想与体会
本次实验我主要着重了两个方面的内容,一方面是python爬虫爬取网站上的数据并进行可视化的呈现,第二方面是将python的功能接入到我们B/S架构的系统中来增强我们项目系统的功能。
在做实验的时候我切身感受到爬虫功能的强大功能,几秒钟就可以将网上数据爬取下来并进行分析甚至可以进行可视化,其实我在大一的时候就一直想学习爬虫的相关方面知识,
但是当时一直觉得爬虫应该是一个非常难的事情,就没有敢去尝试,但这次做实验,跟着志强老师上课讲的一点点做,不会的地方去查阅相关方面的资料,真正自己一点点做下来的时候,
那份成就感真的无与伦比,自己以后也会对爬虫方面知识进行深入的学习。
第二方面就是用大模型做了一个文档相似度分析功能的python程序,并将其作为一个API供我们的采用vue3+springboot3框架搭成的系统使用,在这其中也遇到很多相连的问题,
最后通过问AI、查阅资料和问老师等方式终于成功,虽然中间改代码的时候真的超级崩溃,但最后前端系统中正确显示结果的时候真无比激动,遗憾的就是由于样本的数量不够,
所以没有去训练查重的大模型,功能还没有很完善,还有就是查重算法也没有很完善,有时候查重出来的相似度偏高,后续都会再完善。
本次实验我感觉也是对python课一整个学期学习内容的一次大的总结和应用,让我对整学期学习的python知识做一个实际的应用。原本我还想学习并做小游戏的相关方面内容,
但可惜自身时间安排出问题没有来得及去弄,只能等后面再去做相关方面知识的应用了。
【2】 全课总结
这学期能选上志强老师的python课真的是一个非常幸运的事。其实在大一的时候我就非常想选python课,首先是因为我在高中的时候学习过python(由于高考要考),对于python的基础语法掌握较好,
因此想要再深入学习python的相关方面知识,其次就是听闻志强老师不仅讲课循循善诱,而且人还很有耐心,对学生很好,问各种问题都会耐心解答,但很可惜大一的时候没有抢上,
这也是我大一的遗憾之一,好在大二的时候还是抢到了,即便我在大二的时候学分已经修够了,但是还是毫不犹豫的报了这门课。课程中的收获也非常非常多,志强老师讲解幽默深入浅出
从第一个人生苦短,我用python,到最后的爬虫技术,虽然感觉一周就一节课,但是学到的知识远远大于课时数,志强老师也给我们提供非常多的资料供我们在课后进行复习巩固和提高,
我感觉这门课真的给我打开了Python学习的大门,尤其是爬虫方面,后续我也会花时间与精力学习相关方面知识。
最后再次感谢与python公选课的相遇、与志强老师的相遇,受益匪浅、收获颇丰。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号