
20211210王宇轩《Python程序设计》实验四 Python综合实践实验报告
课程: 《Python程序设计》
班级: 2112
姓名: 王宇轩
学号: 20211210
实验教师: 王志强
实验日期: 2022年5月28日
必修/选修: 公选课
一.实验内容
1.Python综合应用:
爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
2.灵感来源:
作为一个网络小说骨灰级爱好者,当老师最后一次课用爬虫爬取天气时,我就已经按耐不住要去爬取网络小说,一来是对学习成果的检验,二来符合自己的兴趣,做起来兴致更高,能更好地完成目标。
3.主要内容:
用爬虫爬取网页上的小说,并下载到D盘。
二、实验过程及结果
爬取网站:顶点小说
1、先查找搜索时的规律:
搜索圣墟时网站为:https://www.118book.com/book/80/,代号80
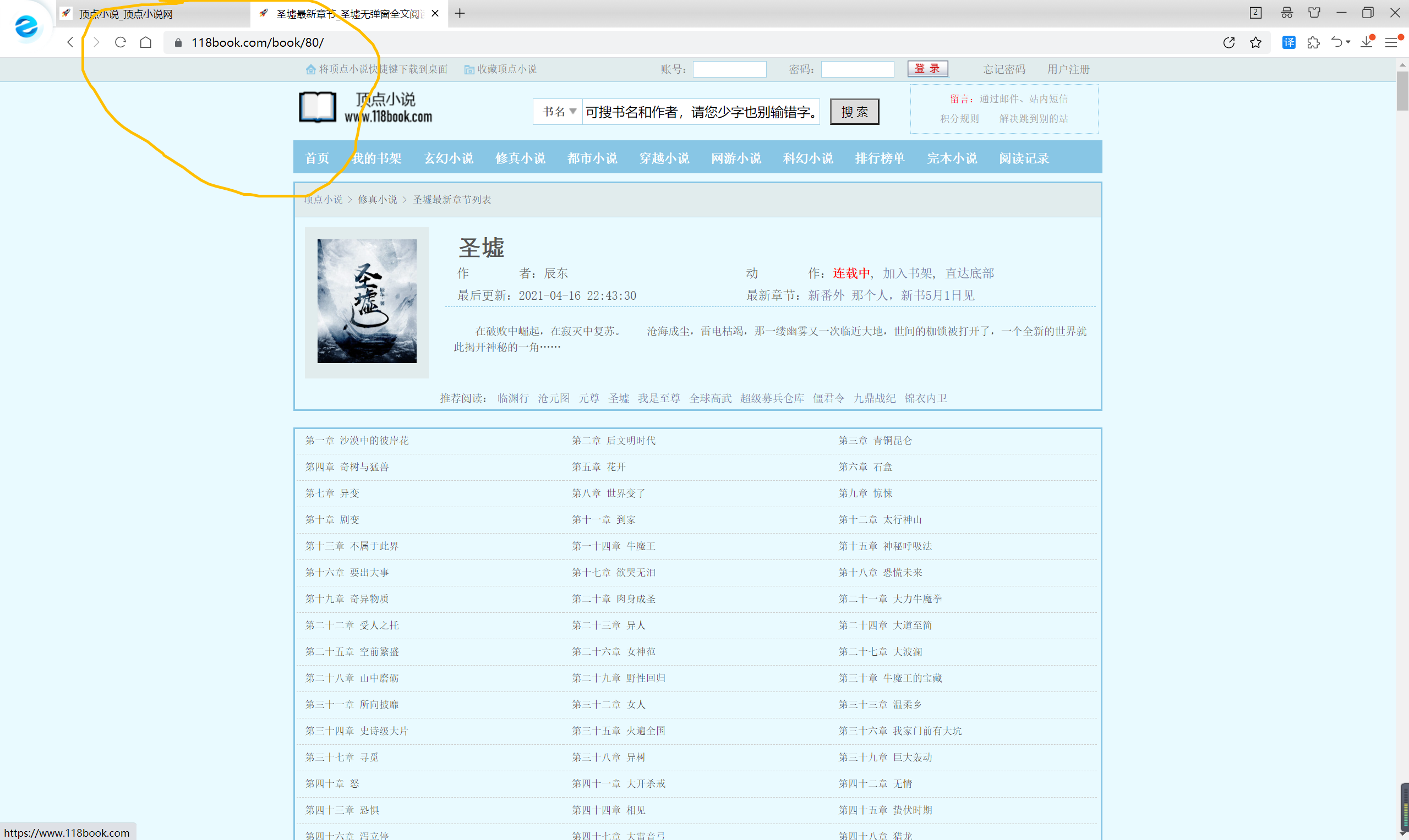
搜索斗破苍穹时网站为:https://www.118book.com/book/609/,代号609

可以得出每一个数字都代表一本书,因此可以使用循环获取某个范围内的所有书名
2、查看网页源代码(F12,Ctrl+R),查找书名位置,从以下图片可以看出,书名位于id为info的div标签中的h1

3、建立一个字典bookNames,来存放书名以及对应的编号
代码如下:

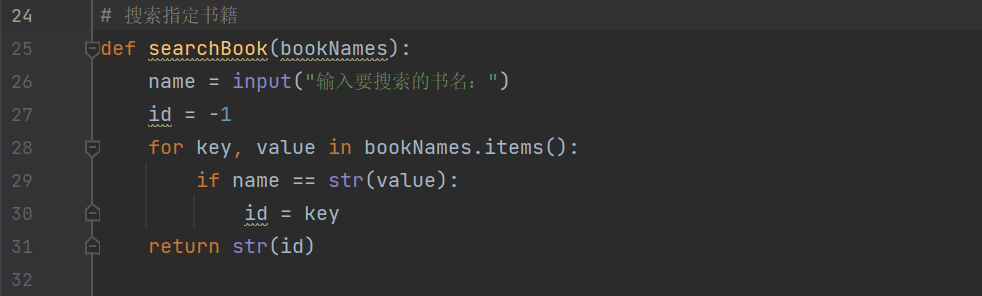
4.搜索指定书名
搜索书名是在bookNames字典中查找,如果存在返回书籍的编号,否则返回-1。注: 循环中value的类型是 'bs4.element.NavigableString,而name的类型是String,比较是否相等时要进行类型转换,否则一直返回-1
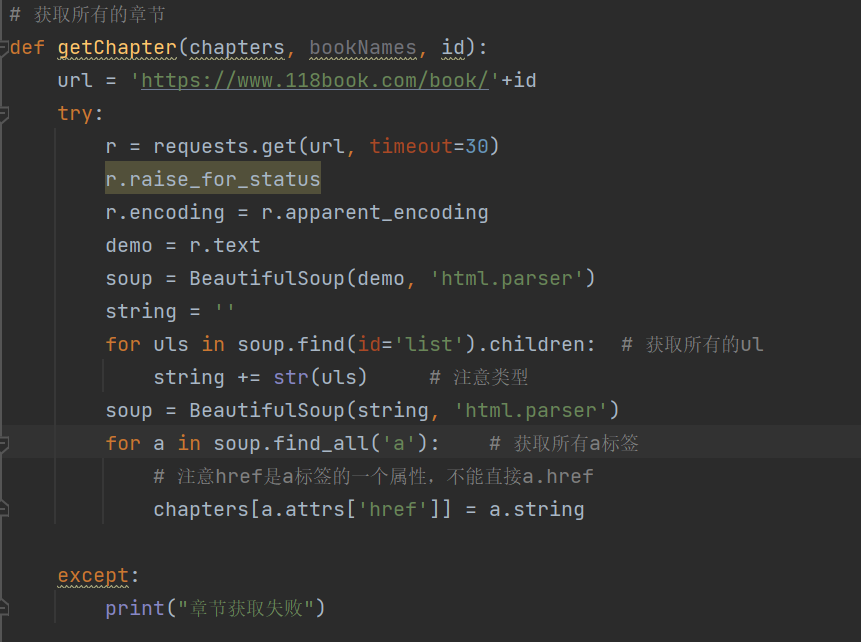
5. 获取书籍的章节目录
(1)该方法要获取书籍的章节目录以及每一章节对应的网址,并将其保存,为之后的书籍下载做准备这一部分应该是最重要的地方
(2)分析网页源码

从网页源码中可以看出,每一个class为_chapter中包含3个小章节,所有要获取所有的class为_chapter的ul,然后再遍历其中的子节点
注: 这里有关问题class是python的关键字,不能在这里使用只能先获取id为list的div,然后在获取ul
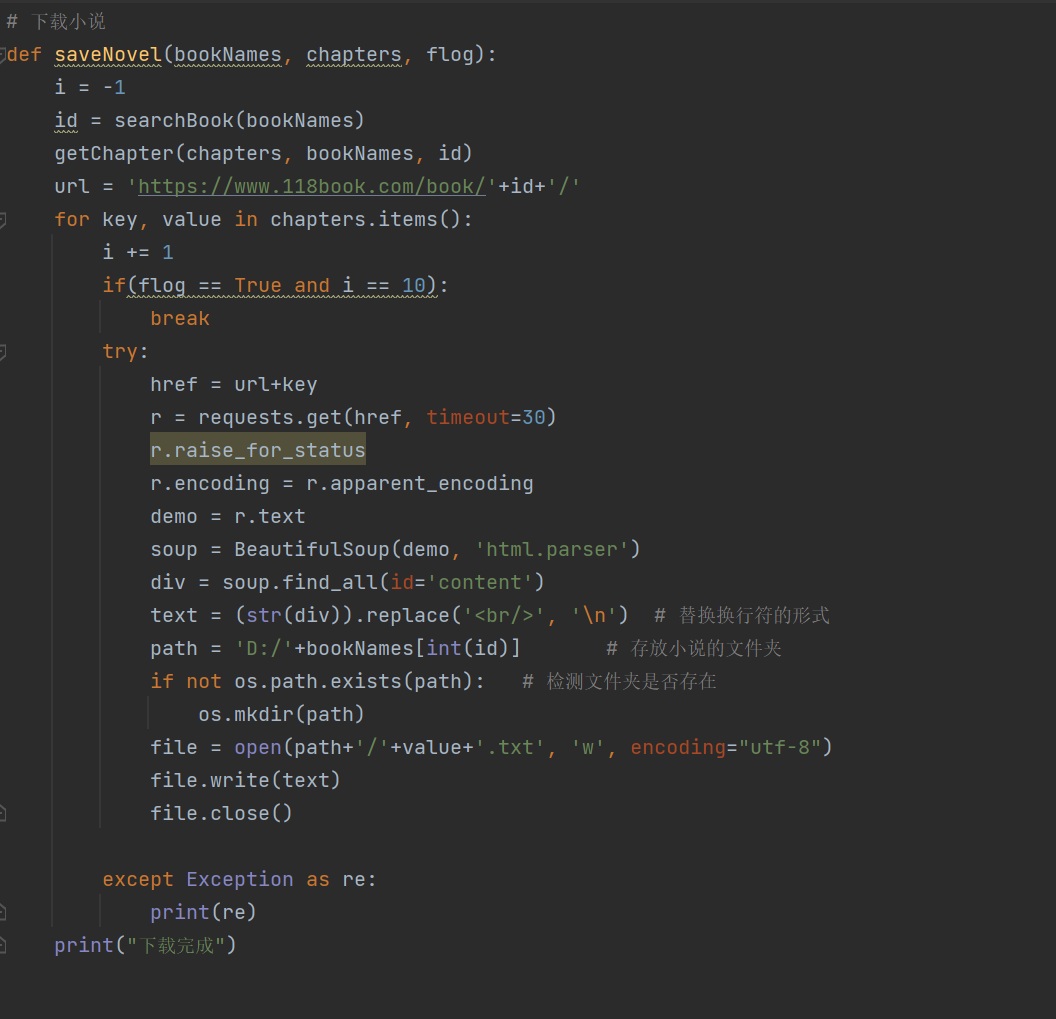
6.下载小说
(1)最后一个阶段将小说保存的本地,想法是小说名作为文件名,每一章节都是一个单独的以章节名为命名的txt文件
(2)随便打开一个章节,可以得到网址,例如:https://www.118book.com/book/609/59043.html,可以得出规律只需要在https://www.118book.com/book/609/拼接上对应的编号即可打开每一章节
(3)查看源代码,获取小说内容所在的标签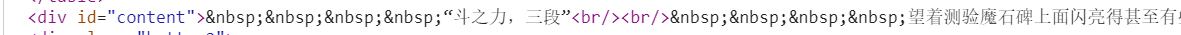
从源代码中可以看出只需要获得id为content的div标签即可
7.找到自己想看的小说地址(作为老书虫的我找了几本曾经熬夜爆肝的小说)

8.完整代码
import requests from bs4 import BeautifulSoup import bs4 import os # 获取书库 def getBookName(bookNames, number): for i in number: url = 'https://www.118book.com/book/'+str(i) try: r = requests.get(url, timeout=30) r.raise_for_status r.encoding = r.apparent_encoding demo = r.text soup = BeautifulSoup(demo, 'html.parser') for tag in soup.find(id='info').children: if(tag.name == 'h1'): bookNames[i] = tag.string except: print("爬取失败") # 搜索指定书籍 def searchBook(bookNames): name = input("输入要搜索的书名:") id = -1 for key, value in bookNames.items(): if name == str(value): id = key return str(id) # 获取所有的章节 def getChapter(chapters, bookNames, id): url = 'https://www.118book.com/book/'+id try: r = requests.get(url, timeout=30) r.raise_for_status r.encoding = r.apparent_encoding demo = r.text soup = BeautifulSoup(demo, 'html.parser') string = '' for uls in soup.find(id='list').children: # 获取所有的ul string += str(uls) # 注意类型 soup = BeautifulSoup(string, 'html.parser') for a in soup.find_all('a'): # 获取所有a标签 # 注意href是a标签的一个属性,不能直接a.href chapters[a.attrs['href']] = a.string except: print("章节获取失败") # 下载小说 def saveNovel(bookNames, chapters, flog): i = -1 id = searchBook(bookNames) getChapter(chapters, bookNames, id) url = 'https://www.118book.com/book/'+id+'/' for key, value in chapters.items(): i += 1 if(flog == True and i == 10): break try: href = url+key r = requests.get(href, timeout=30) r.raise_for_status r.encoding = r.apparent_encoding demo = r.text soup = BeautifulSoup(demo, 'html.parser') div = soup.find_all(id='content') text = (str(div)).replace('<br/>', '\n') # 替换换行符的形式 path = 'D:/'+bookNames[int(id)] # 存放小说的文件夹 if not os.path.exists(path): # 检测文件夹是否存在 os.mkdir(path) file = open(path+'/'+value+'.txt', 'w', encoding="utf-8") file.write(text) file.close() except Exception as re: print(re) print("下载完成") bookNames = {} # 存储获取的所有书名 chapters = {} # 存储指定小说的章节 getBookName(bookNames, [80,84,609,2849,23519]) print(bookNames) saveNovel(bookNames, chapters, True)
9.程序运行截屏

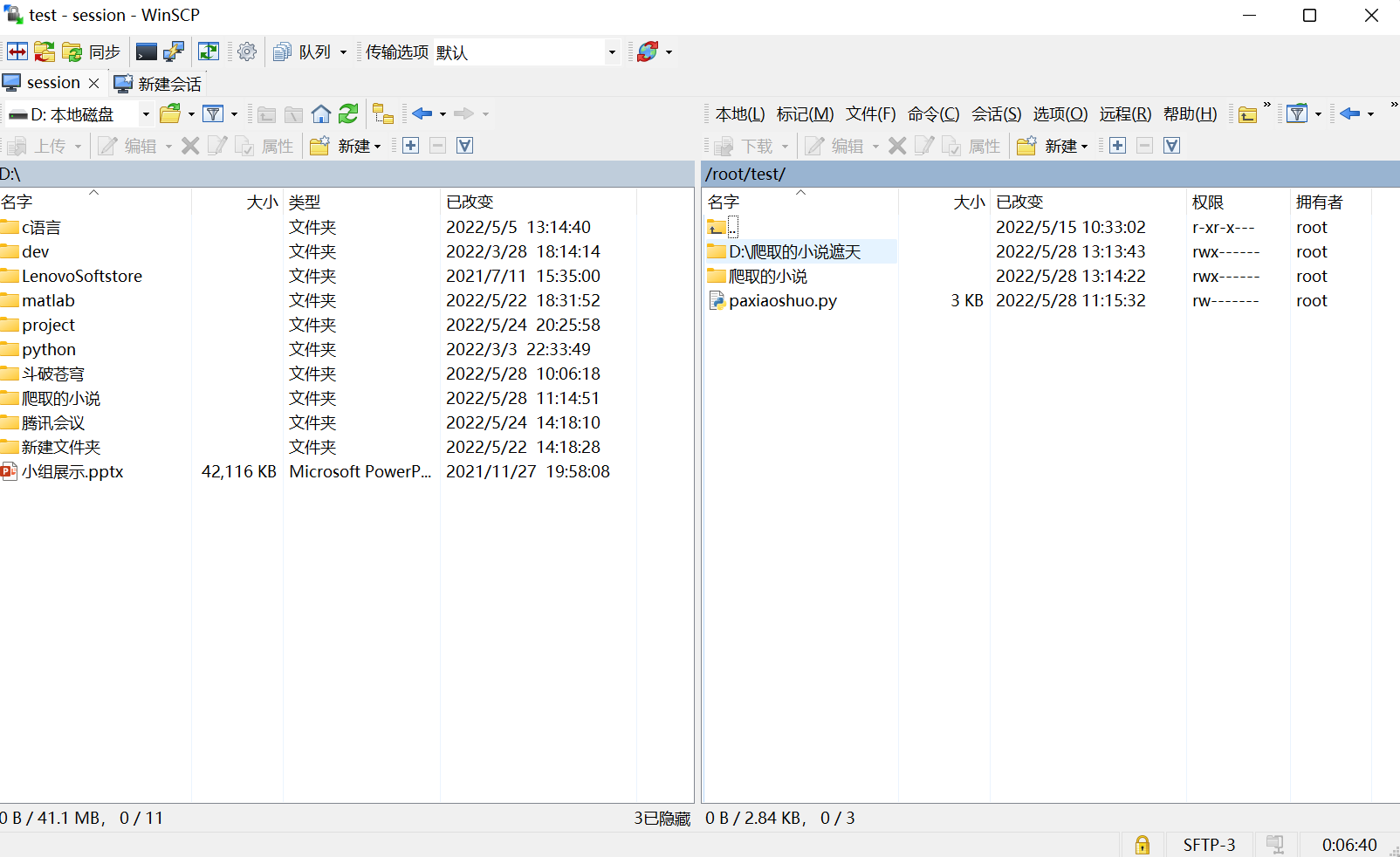
10.查看D盘是否下载成功
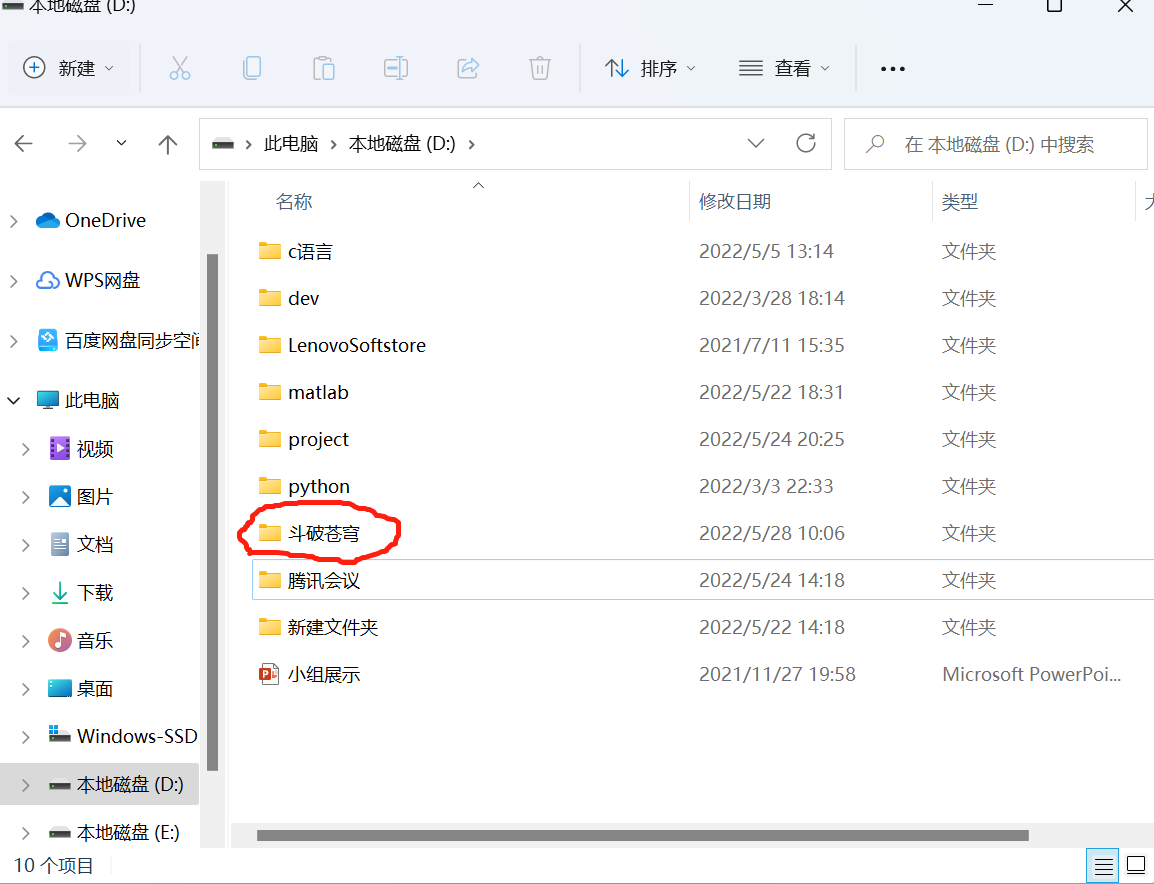
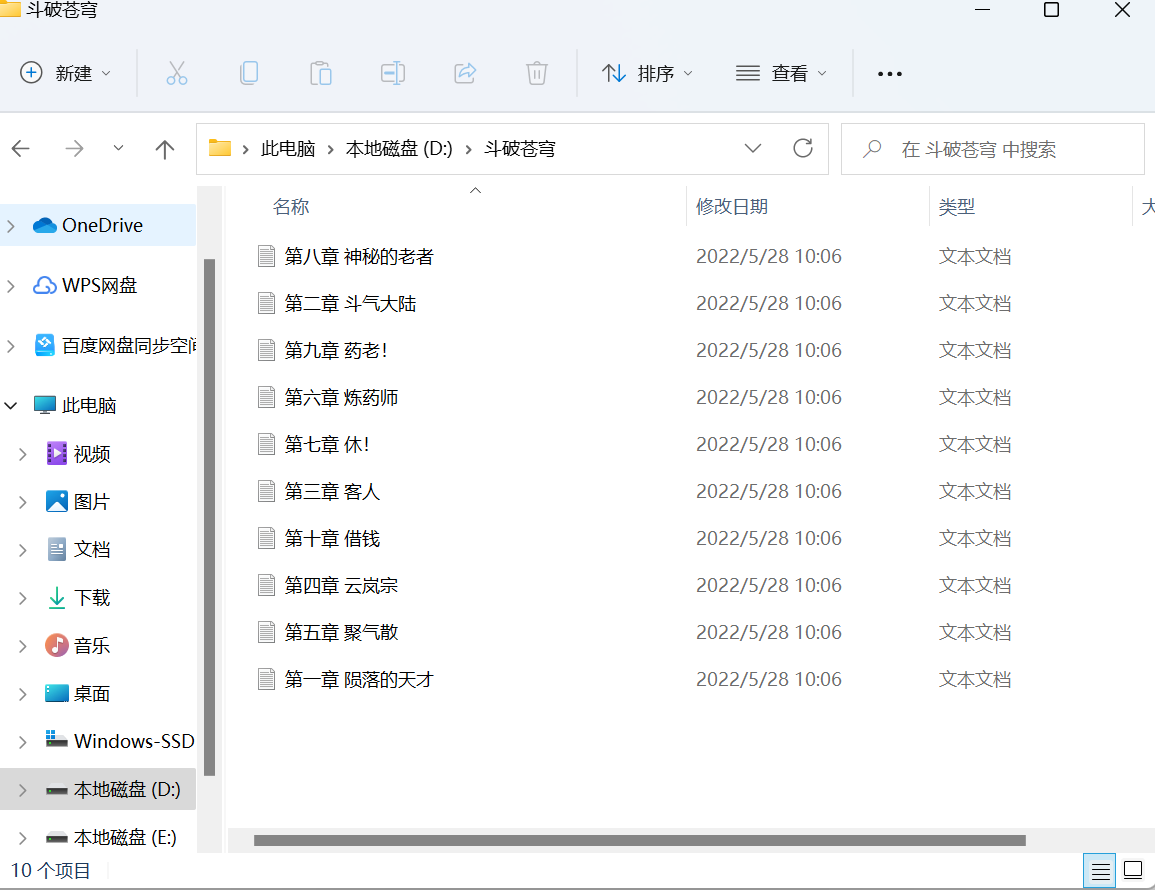

总体上基本完成预期任务,就是章节名有点乱,期待以后能够改进。
三、上传ESC服务器
恰好这学期程序设计课也需要用华为云提交实验报告,我也就省去再买服务器的过程,并且之前C语言实验报告要求用用putty,我积累了一定经验,而上python课时听王老师说用putty也可以,所以以下使用putty。
复制ip地址并上传。
登陆成功
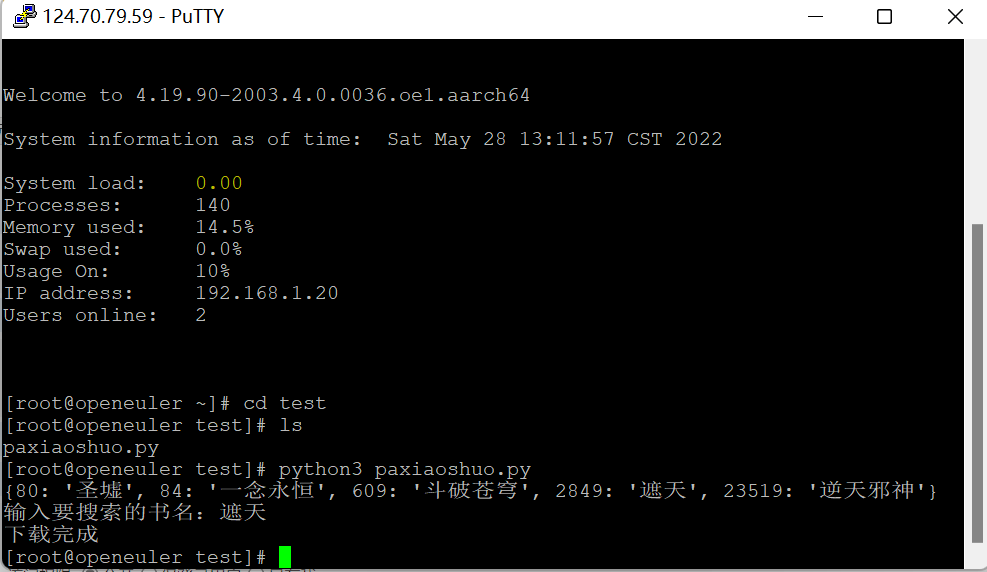
爬取成功
检查

四、遇到的问题
- 问题1.基础知识不牢固。
- 问题1解决方案:CSDN查找资料恶补(血泪史)
- 问题2:文件无法在服务器上用python2运行。
- 问题2解决方案:安装python3后用python3来运行。
- 问题3:上传到putty运行时无法找不到爬取的小说。(本来保存到D盘)
- 问题3解决方案:修改源代码中的保存地址。(在D盘新建一个文件夹用来存放爬取的小说)
五、课程总结(完结撒花):
首先由衷感谢王老师这一学期的教导,老师讲课很有趣也很生动,常常在欢声笑语中就将知识点讲清楚。作为一个火影迷,我第一次看到老师微信头像就感觉很亲切,老师也像卡卡西一样帅气哈哈,爱阳光爱笑值得信赖。
然后谈一谈我的体会吧,刚开始为什么选python这门课呢,我当时想的是正好也要学C,不如选修选门python,到时候C和python双修岂不美哉(but理想很丰满,现实很骨感)。这学期的活动数目和课程难度都要超过上学期,静下心来学习很少,敲代码的时间更是少之又少。因为上学期自学了点C语言,刚开始学python的时候觉得好简单(请原谅当时无知的我),没有那么多条条框框,很符合人的习惯,用起来很便捷。还记得那个besti计算机,哈哈挺好玩也挺实用。不过到了期中那一段时间吧,课程难度提升上去,而我又是在上了一天课后身心俱疲的情况下来学python,有点跟不上老师的进度,下课又要忙着其他学科的复习,没有及时解决python课的疑问,导致我课堂上越听越迷茫,实验三在同学帮助下才勉强完成(ps:实验报告提交上去后不太甘心,又自己重做了遍实验三的服务器,还是挺有成就感的)。最后这次实验,个人感觉比前几次实验加起来难度难度还要大,一来是爬虫要和很多知识联系起来(类,标签,文件等等),而我在这些方面知识又有些欠缺,只好花时间看网课以及上CSDN上查找资料慢慢钻研;二来是要上传到ESC服务器上(本来以为和C语言上传到putty差不多(又一次年少无知),亲身实践时困难重重,而且这方面内容在网上也不容易找到专门的解决方法)。不过最后好在可以说天道酬勤吧(两个周六整天加上一些零碎时间),基本上完成了目标,我个人也比较满意,成就感也很足。做完这次实验后之后突然很想继续学习python,哈哈以前恨之愈切,如今爱之愈深。在自己成功爬取小说后,以及在看了其他同学的成果(如提醒体温打卡,照片墙,飞机大战等等五花八门),我这更加真切感受到python可以便捷我们的生活,而且这种便利也可以提供给他人,赠人玫瑰,手有余香。哈哈不多说了,暑假我还得搞YOLOv5对抗研究,这是用python实现的项目,希望到时候python手下留情(手动狗头)。
然后给老师提个小小的建议吧,老师的课讲的很好,水平很高,讲课内容如何精进如何更加富含逻辑以及如何更加通俗易懂,不是我这个初学者能想到的。我想给老师的建议是鼓励同学们在python微信大群中提出自己的疑问,让其他同学帮助解决问题。一方面可以缓解老师的压力(老师精力有限,有时候无法像学生给学生讲那么详细),二来也可以帮助同学们拓宽交际面,增进不同系同学的情谊(我个人认为还是挺有好处的)。
最后祝王老师工作更加顺心,课讲得越来越好,喜欢您的学生越来越多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号