
2026UniCTF-Misc总裁四比特,这能玩?
⭕、知识点
1、图片二进制文件隐写
2、Nibble算法
3、PNG文件格式的理解
一、题目
比特.zip,解压后是一张PNG图片
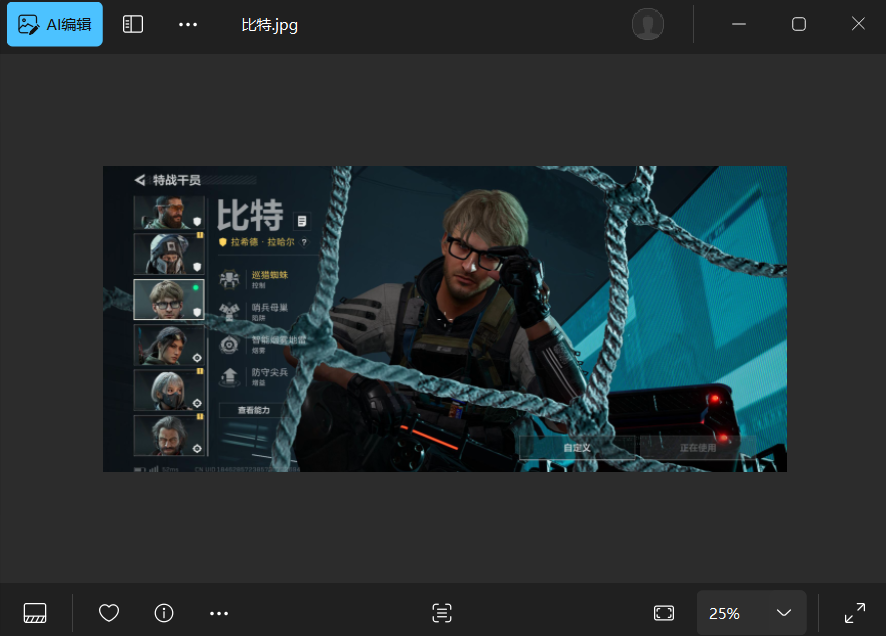
二、解题
1、查看压缩包备注,没有东西
2、foremost提取出2个图片
仔细观察一下两个图片一模一样,二进制数据也一样,大小都一样,排除盲水印
3、在比特.jpg、提取出来的2个png图片都进行flag、CTF、Uni字段的搜索,无果
4、尝试了strings、zsteg、stegsolver都没有发现隐写
5、SilentEye也没有提取出东西
6、查看图片属性没有备注信息
7、把3个图片都丢进010仔细看了一下,没有任何发现,除了能看到比特.jpg末尾是2张被提取出来的图片
8、没招了,,第二天接着想,回头看了一下有没有没利用上的信息,就是那个题目自带的比特,还特地去问了一下玩三角洲的朋友,没有啥收获
9、关键:题目总裁四比特,是不是和四比特有关系。先计算一下每个文件的大小
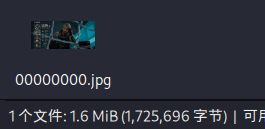
- foremost分离出的头部段比特.jpg,大小1725696字节
![image]()
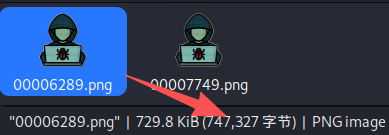
- 两个一样的png图片都是747327字节
![image]()
- 原比特.jpg大小4715004字节
![image]()
既然分离出的看起来有用的图片都没有找到有用的信息,是不是有用的信息还藏在剩余的没有被利用的部分?
巧了,剩下的冗余数据为1494654字节,恰好是2个png图片的大小之和


10、瞬间有了思路,结合题目名称四比特,应该是这两部分数据在某固定的4比特有所不同,直接上脚本
with open("比特.jpg","rb") as f:
data = f.read()
print(len(data))
data_seg1 = data[:1725696]
with open("data_seg1.jpg","wb") as f:
f.write(data_seg1)
print(len(data_seg1))
len_seg2_and_seg3 = len(data[1725696:])
print(len_seg2_and_seg3)
len_seg2 = len_seg3 = len_seg2_and_seg3 //2
print(len_seg2)
data_seg2 = data[1725696:1725696+len_seg2]
data_seg3 = data[1725696+len_seg2:]
print(len(data_seg2))
print(len(data_seg3))
print(data_seg2.hex()[:100])
print(data_seg3.hex()[:100])
seg2_high_bytes = []
for i in data_seg2:
seg2_high_bytes.append(i >> 4)
print(len(seg2_high_bytes))
print(seg2_high_bytes[:100])
分别打印seg1、seg2前100个字节

惊奇的发现,果然每个字节的高4位不同,而低四位相同。
11、把冗余段数据每个字节高四位提取并重组,得到一个新文件,而且稍微观察一下就知道前几个字节是504B,zip压缩包无疑。
续上面的代码
result = []
for i in range(0,len(seg2_high_bytes)-1,2):
result.append(((seg2_high_bytes[i]<<4)|(seg2_high_bytes[i+1])).to_bytes())
result = b''.join(result)
# print(result)
with open("data_seg3.zip","wb") as f:
f.write(result)
12、得到压缩包并解压得到一张图片:嘉豪。 我直接释怀的撕了😂

13、查看图片备注没有信息,丢尽foremost提取又出现一个压缩包,解压得到flag

三、答案
UniCTF{Y0u_4r3_4_6r347_h4ck3r_!}
四、总结
脑洞是真大,后来了解了一下是有一种算法叫Nibble,也是按4比特为1单位进行处理数据的,如果提前了解,应该会更容易想到这个解题思路吧。
梭哈工具都用不上的时候,真得回归二进制数据仔细分析了,而文件的大小也有可能成为突破点!
PNG图片格式详解参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号