
【攻防世界】奇怪的TTL字段
⭕、知识点
8比特前2比特提取并组合/二进制数据保存/图片二进制文件隐写/图片拼接/QR识别
一、题目
给了一个TTL文本

二、解题
1、观察文件内容,有如下特征
- 都小于255
- 存在大于127的TTL值
- 仅有63、127、191、255
2、推理
综合上面的特征,排除ASCII码
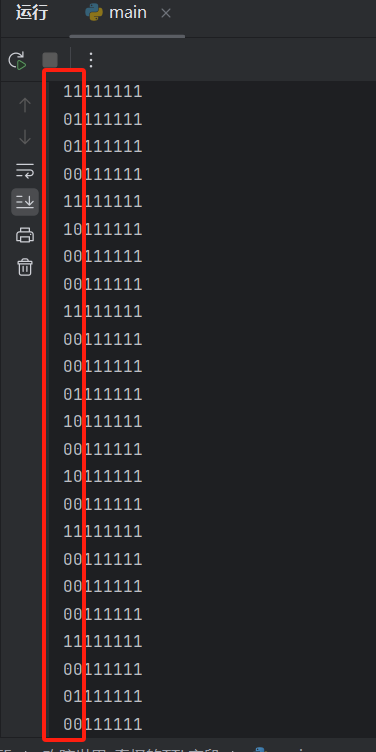
3、转为二进制输出一遍看看,发现所有数据的后六位都是1,仅有前2位不同,如果有数据就是隐藏在这前两位中
result = ""
with open("ttl.txt", "r") as f:
for line in f:
print(bin(int(line[4:].strip()))[2:].zfill(8))
4、编写脚本把所有的ttl前两位提取并组合
import textwrap
result = ""
with open("ttl.txt", "r") as f:
for line in f:
result += bin(int(line[4:].strip()))[2:].zfill(8)[0:2]
print(len(result))
words = textwrap.wrap(result, width=8)
print(words)
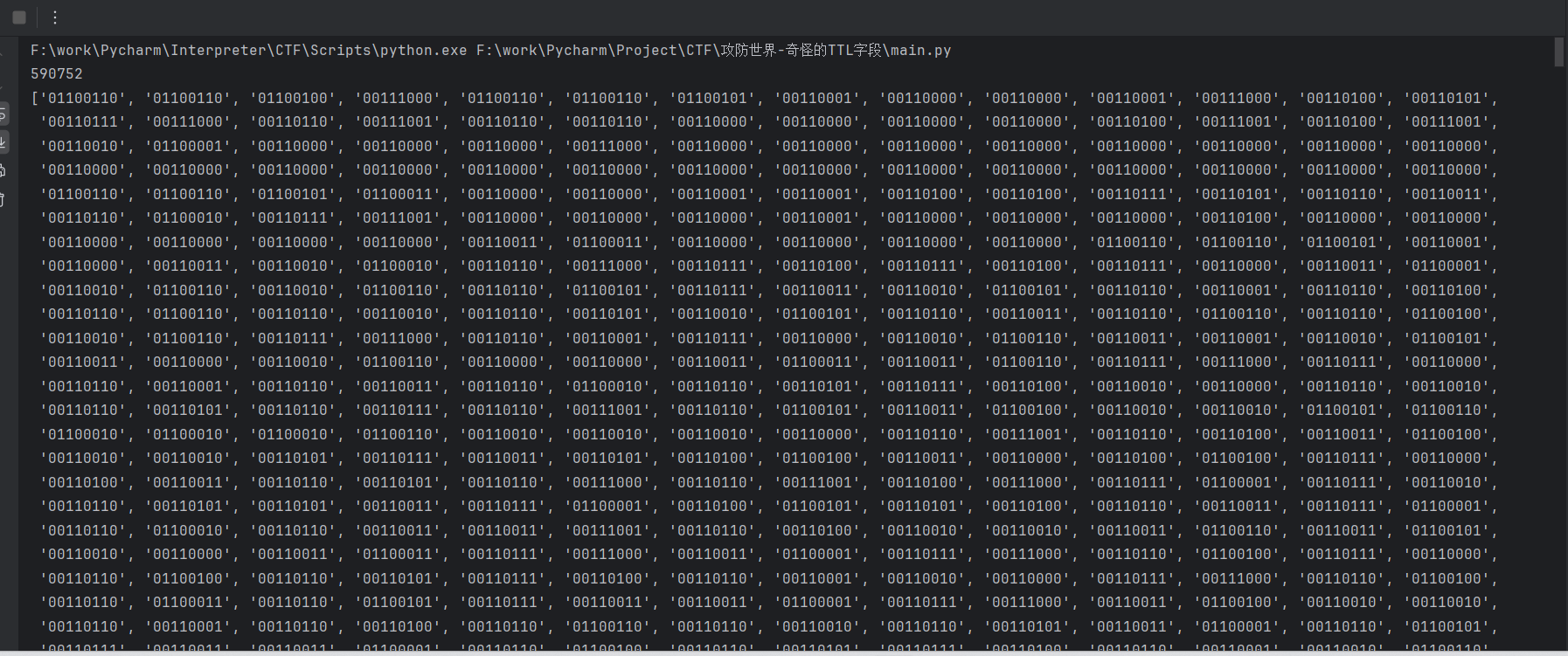
发现总比特为8的倍数,并且以8比特为一组分组后,最高位都为0,可能是ASCII字符
5、把得到的二进制数按8bit为一组转化为ASCII码打印
继续对4的代码进行补充
result = ""
for word in words:
result += chr(int(word, 2))
print(result)
运行结果:

看到ffd8ff开头,立刻联想到jpg文件头,猜测这一串数据应该是一张图片的十六进制数据
6、补充脚本,把十六进制数据保存为图片
with open("result.jpg", "wb") as f:
f.write(bytes.fromhex(result))
得到一块二维码碎片:D

7、那其他部分呢,把这张图片用binwalk扫描一下发现还有隐藏图片!
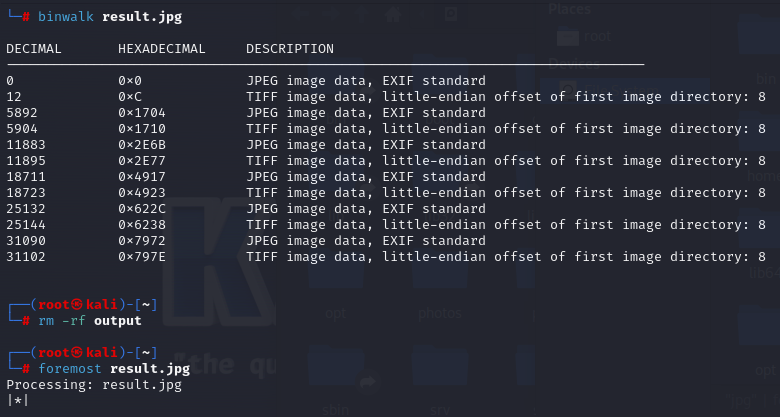
foremost提取一下,得到:

(这里的图片名称是我自己改的,方便后续用脚本合并)
8、编写脚本合并图片
from PIL import Image
import numpy as np
img1 = np.array(Image.open("jpg/1.jpg"))
img2 = np.array(Image.open("jpg/2.jpg"))
img3 = np.array(Image.open("jpg/3.jpg"))
img4 = np.array(Image.open("jpg/4.jpg"))
img5 = np.array(Image.open("jpg/5.jpg"))
img6 = np.array(Image.open("jpg/6.jpg"))
top_img = np.hstack([img1,img2,img3])
button_img = np.hstack([img4,img5,img6])
cq_img = np.vstack([top_img,button_img])
Image.fromarray(cq_img).show()
得到完整的二维码
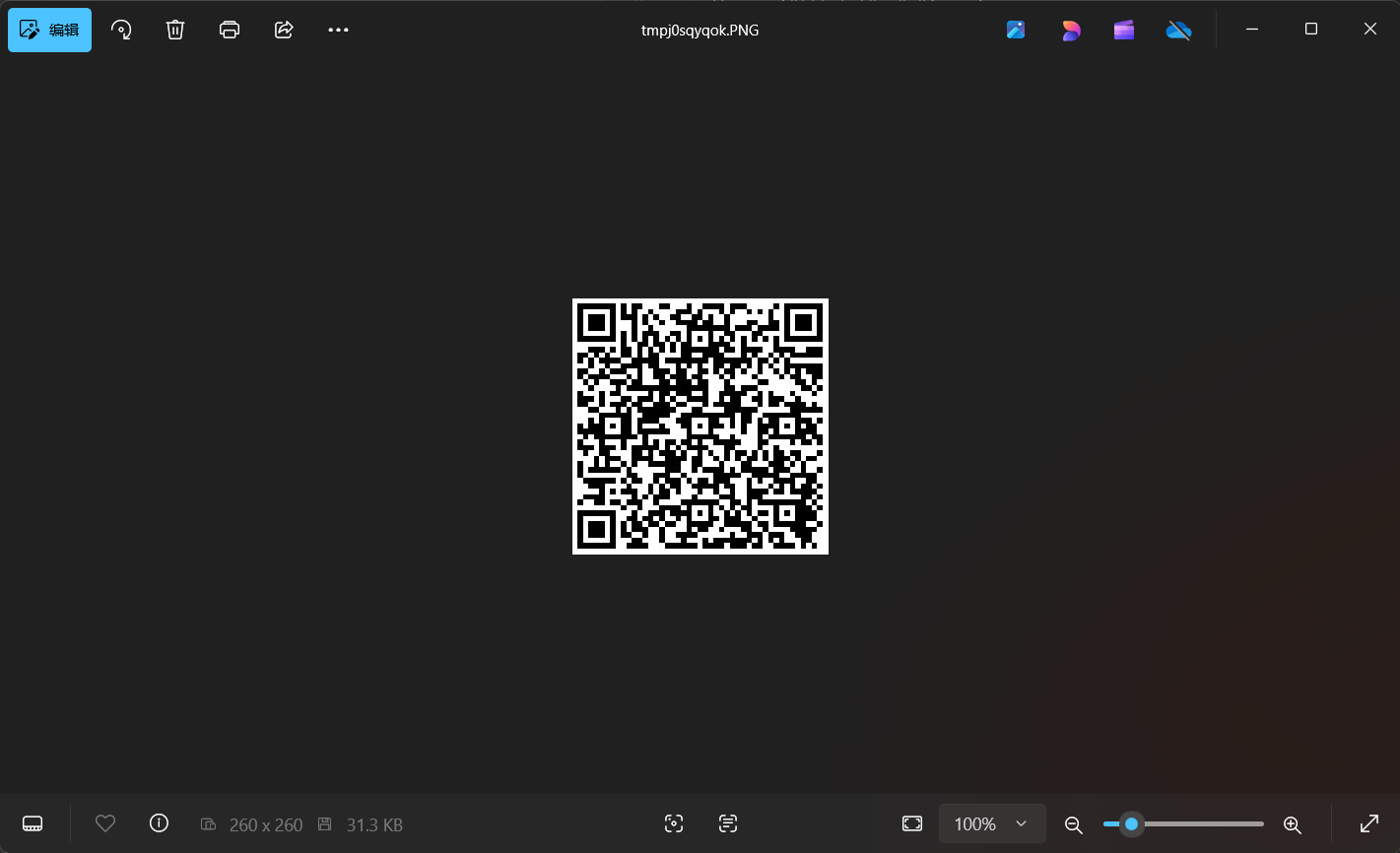
9、扫描识别二维码得到以下内容
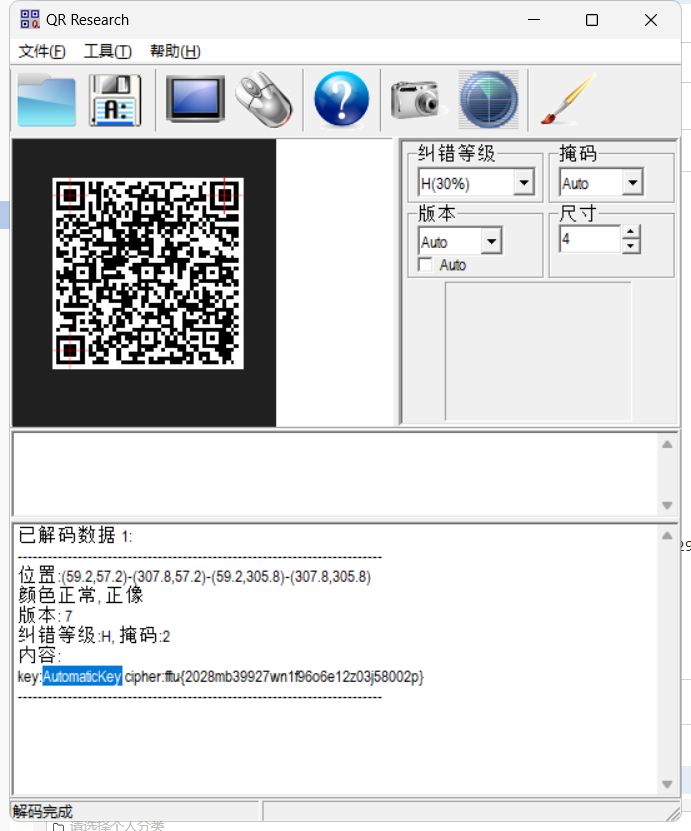
内容:
key:AutomaticKey cipher:fftu{2028mb39927wn1f96o6e12z03j58002p}
10、观察内容发现一段类似flag格式的文本,猜测应该是某种替换加密方式,还有key,应该是类似维吉尼亚密码
AutoKey Cipher解密网址:https://www.wishingstarmoye.com/ctf/autokey
解密得到flag
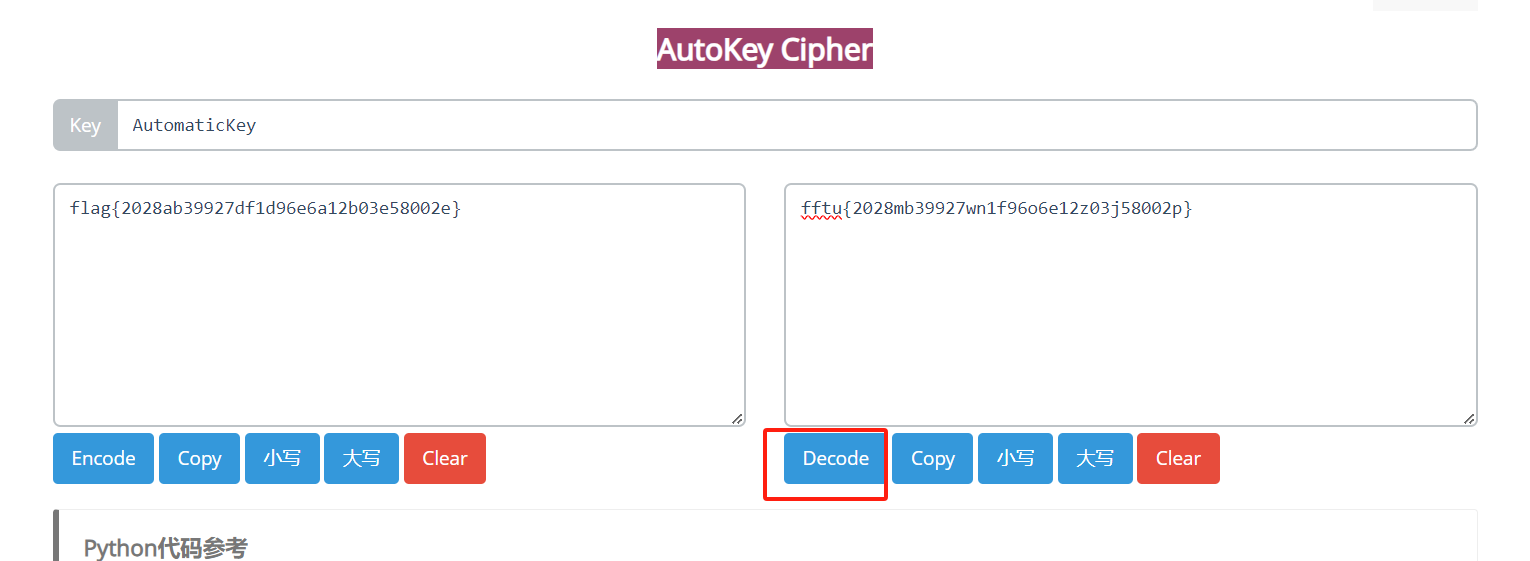
三、答案
flag{2028ab39927df1d96e6a12b03e58002e}
四、总结
1、本题为小于255十进制数字序列的分析提供了一种新的解题思路(前2bit)
2、学习到了使用np来进行图片合并

3、复习常见文件的文件头
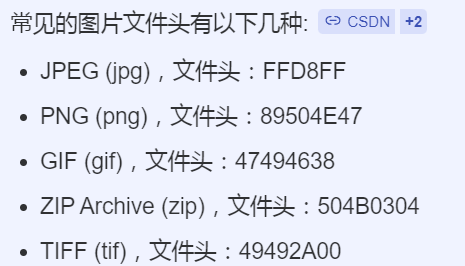
4、复习python里的一些常用函数,这里做个梳理
hex() #把十进制数转为十六进制数
bin() #把十进制数据转为二进制数据
int() #把二进制或者十六进制数转为十进制数
bytes() #把十进制数转为字节数据
bytes.fromhex() #把十六进制数转为字节数据
chr() #把十进制数转为ASCII字符
ord() #将一个字符转换为对应的 Unicode 编码(整数)值,与chr()互为逆操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号