mysql进阶学习三之mycat读写分离和分库分表
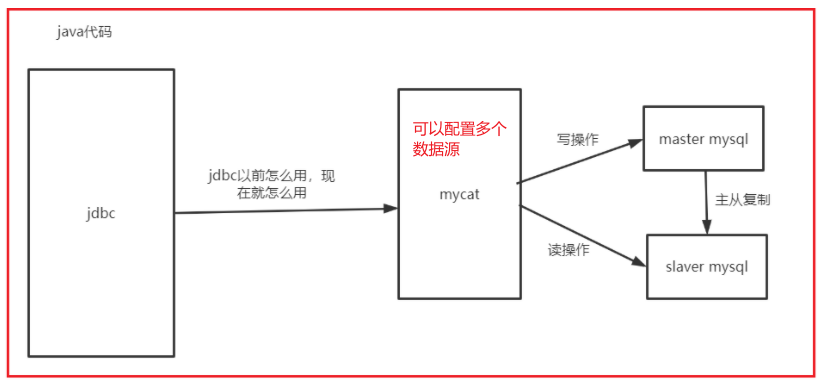
前面已经配置了mysql的主从复制,其实很容易,主节点写入了数据,从节点进行同步,所以写操作使用主节点,读操作使用从节点,这样就有效降低了数据库的压力
但是我们用java程序不可能去连接多个数据源,执行sql的时候还要判断是使用主节点还是从节点,所以使用mycat,一端对java提供一个统一的接口,另外一端可以连接多个数据源,最好是我们可以跟以前一样连接数据库一样,让使用者感觉不到mycat的存在;
mycat就是实现了这些功能,把连接多个数据库的操作交给了mycat,在mycat中配置哪个节点是读,哪个是写,在执行sql的时候就会自动的去连接该节点;
还有一点,mycat是国人使用java开发并开源了的,启动mycat需要jdk环境
1.mycat安装
本来是想用linux版的mycat的,由于云服务器只有一台,在服务器上没法链接上本地的mysql,就是用了windows版的mycat,用法和配置文件和linux版的都是一样的;
自行下载对应的版本,这里下载的是1.6.7.4版本,解压之后的目录:
2. mycat的配置
首先我们修改一下mycat的用户名和密码,在安装目录/conf/server.xml中

然后需要配置一下schema.xml:
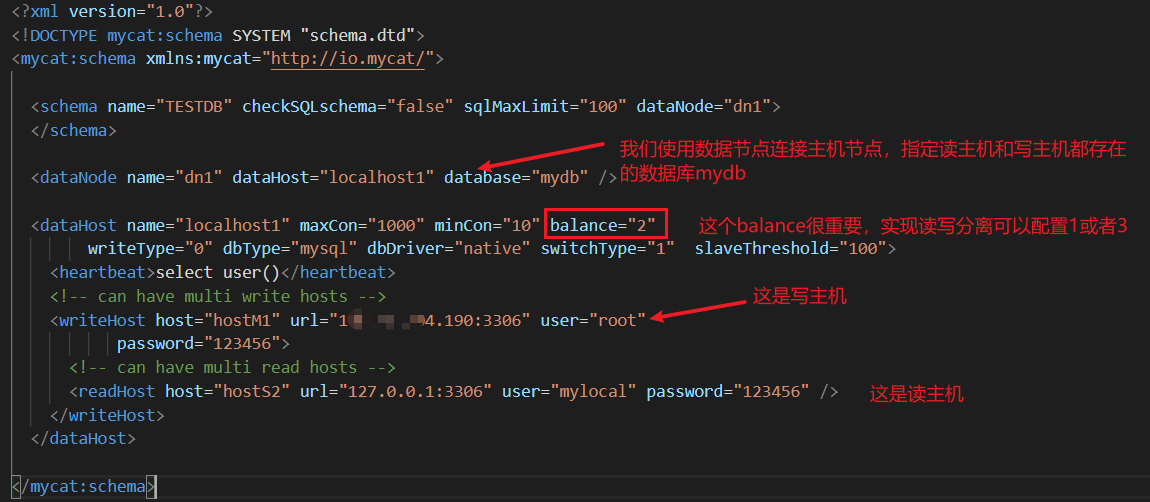
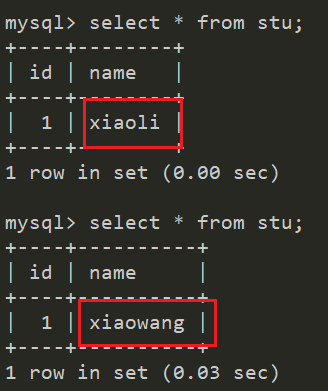
我这里测试用的是balance="2",将主节点和从节点中mydb数据库stu表中相同id的数据改成不一样的,然后去连接mycat查询该表数据,每次查询都不一样
想测试读写分离,这里设置为1或者3
balance="0": 不开启读写分离,读操作和写操作都是用的writeHost;
balance="1": 开启读写分离,这种情况是存在多主多从的时候,一个主节点提供写操作,其他的主节点和所有从节点提供负载均衡的读操作
balance="2": 读操作随机读选择主节点和从节点
balance="3": 开启读写分离,写操作使用写主机(主节点也就是写主机,从节点是读主机),读操作使用读主机
3. mycat启动
进入mycat安装目录下的bin目录,两种方式:
(1)前台启动,可以看到启动情况:./mycat.bat console
(2)后台启动: ./mycat.bat start

连接mycat,就跟连接mysql一样,打开cmd,mysql -umycat -p123456 -h 127.0.0.1 -P 8066 //注意端口是8066端口
使用mycat向stu表插入一条数据,然后将主节点和从节点数据数据改成不一样的,你再去读几次,可以看到是随机的,说明我们mycat配置的没问题;
还是说一句,想测试读写分离的,记得把schema.xml中设置为balance="1"或者balance="3"
4 数据分片
数据分片也就是俗话说的分库分表
4.1 分库
当一个数据库中的数据太多了,效率也就低了,我们需要将后续插入A主机中mydb数据库中表tab1的数据,都插入到B主机中mydb数据库tab1表中,除此之外,还需要将A主机中的tab1中的数据迁移到B主机中
至于数据迁移工具,可以看看这个老哥博客,写得挺不错的
schema.xml文件
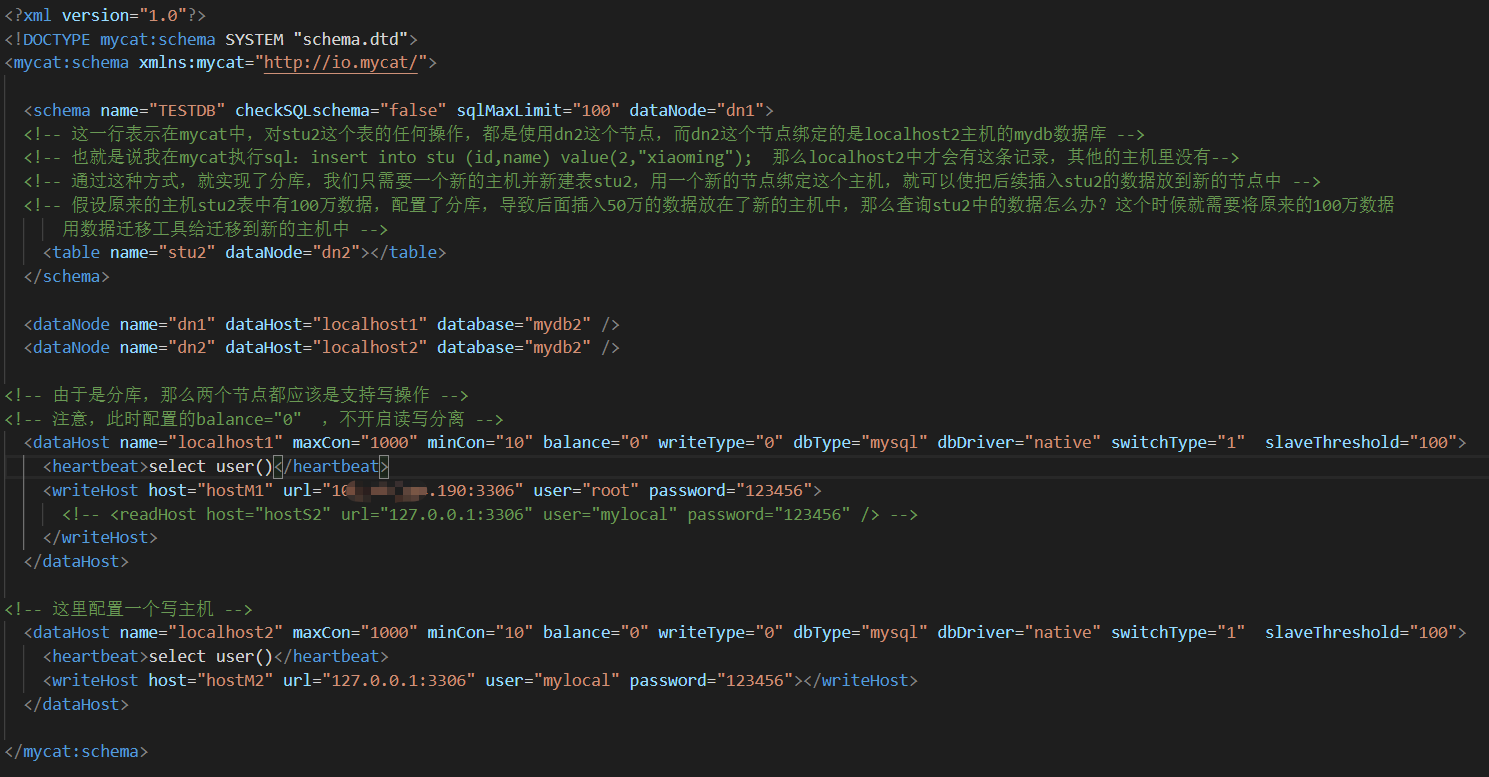
然后测试在mycat中只要是对stu2表的任何操作,都是使用的是第二个主机,从而实现了分库
4.2 分表
分库:X主机中A数据库中有表tab1,tab2,tab3,由于每个表数据都很多,根据分析可以将tab1拿出来,放到Y主机中A数据库下,使得以后所有对tab1的所有操作都是来访问Y主机
分表:X主机A数据库中有表tab4,但是这个tab4中数据有一千万条,我们将这个表用一定的方法,分成两份,分别放到当前主机中和Y主机中A数据库表tab4
不管分库还是分表,都要配合数据迁移工具才能实现的!
首先配置schema.xml文件
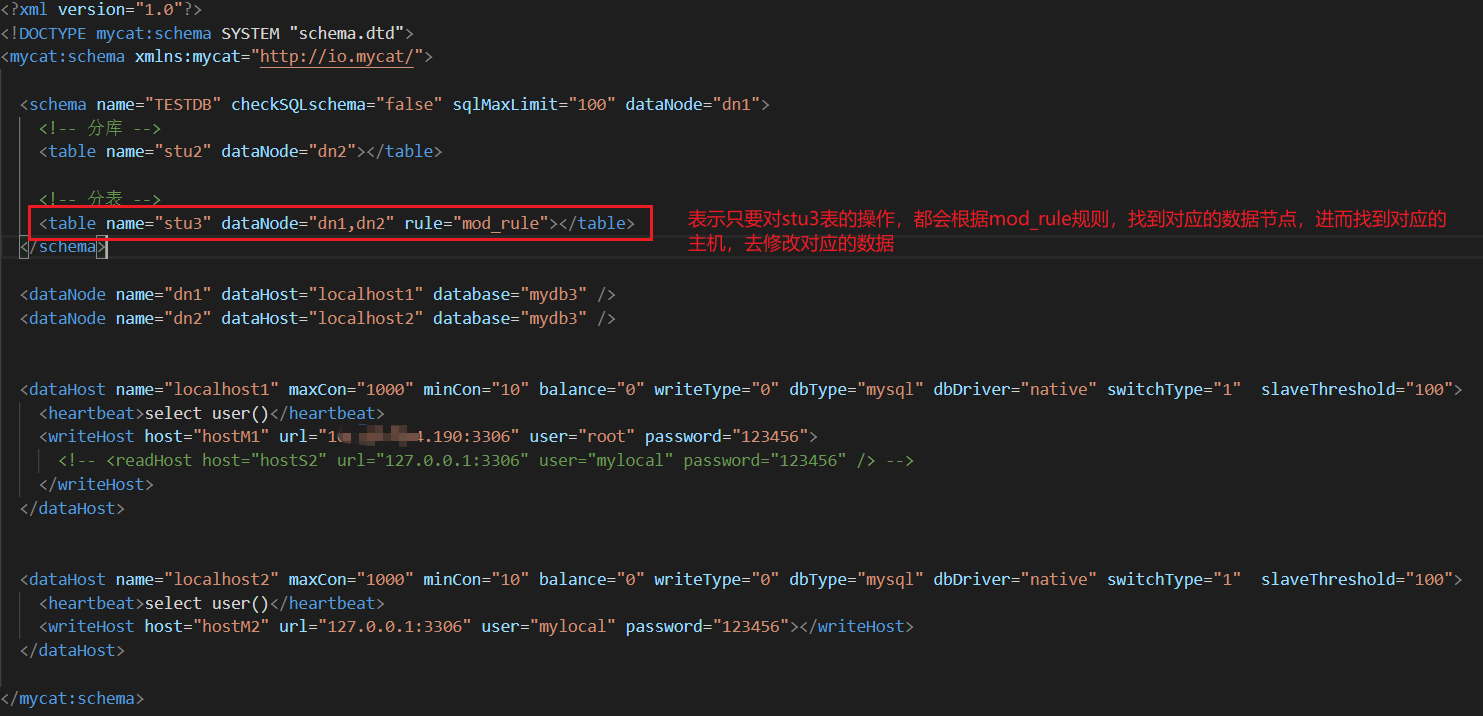
然后配置rule.xml,这种规则其实很好立理解,就是取余,在mycat中向stu3中插入数据,会根据id对2进行取余,得到的结果肯定是0或者1,当等于0时就放在一台主机中,等于1就放在另外一个主机中,这个跟redis集群放入数据一样;

4.3 测试
我们在mycat中执行以下6条sql:
insert into stu3 (id,name) values(1,"jack01"); insert into stu3 (id,name) values(2,"jack02"); insert into stu3 (id,name) values(3,"jack03"); insert into stu3 (id,name) values(4,"jack04"); insert into stu3 (id,name) values(5,"jack05"); insert into stu3 (id,name) values(6,"jack06");
然后我们就可以分别在两台主机中各看到三条数据:
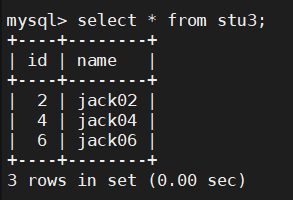

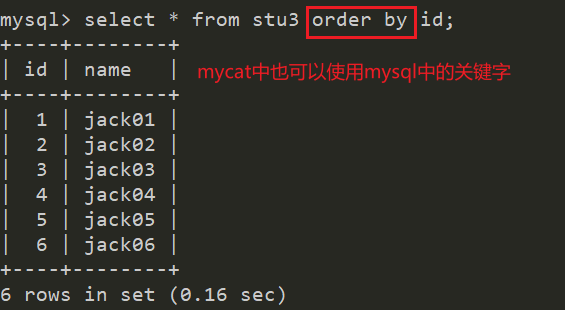
然后我们在mycat中查询所有的数据,可以看到id没有经过排序,只是将主机A中的stu3的数据+主机B中stu3中的数据,所以使用mycat查询分表之后的数据,就是将所有该表所在的主机中数据都查出来,然后再进行拼接;

4.4 关联表分表
举个例子:现在我们是对stu3表进行分表,但是现在有个addr表记录这每个用户的具体住址,stu3和addr是一对一,两个表通过s_id关联
在查询addr表的时候肯定会根据s_id查询用户姓名,那么分表肯定需要相同的规则进行分,比如将stu3表中id=1的数据分到A主机中,那么addr表中id=2的数据也就要分到A主机中,不然跨主机做连表查询就太麻烦了

我们需要在schema.xml中进行配置,这样配置了之后每次向addr表中插入数据的时候,会根据s_id找到对应的stu3表中记录是在哪个主机上,就把addr数据也放在那个主机上
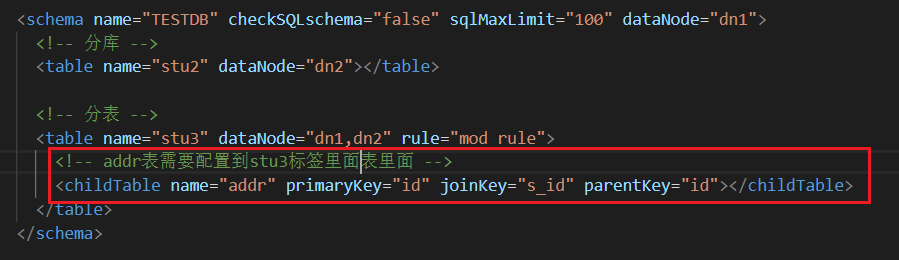
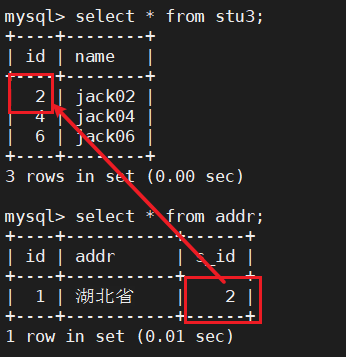
测试了一下,是可以的,这样的话可以保证有关联的表即使分表也会相应的分到同一个主机中,去连表查询的时候效率会高点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号