mysql进阶学习一之知识点总结
环境:centos7+mysql5.7
1 mysql5.7的安装
这里使用yum安装,参考这个老哥的博客 ,反正我安装的时候一言难尽,重装了好几次,哎,平常自己玩的都是用的docker...
装好了记得根据上面的博客去初始化密码哦!
2 mysql的逻辑架构
mysql底层就是经过下面这几部分,我们要知道,执行引擎才是真正干活的;
可以发现这里运行了缓存,首先在缓存中取数据,缓存中能命中就直接从缓存中去,缓存中存数据是sql语句为键,实际的数据为值
例如:select name from stu where id = 1; 和select name from stu where id <2 and id>0 ,虽然两条sql在我们看来是一样的,但是不会命中缓存,因为sql不一样
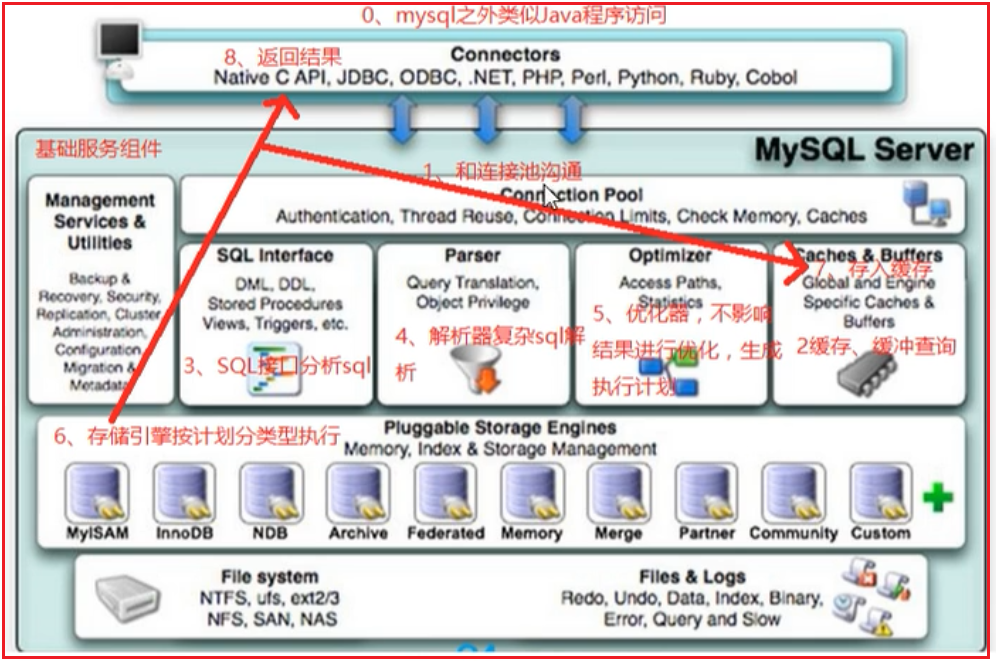
在上图中第5步中的优化器Optimizer,会对我们执行的sql进行优化,例如我们写的sql格式如下:
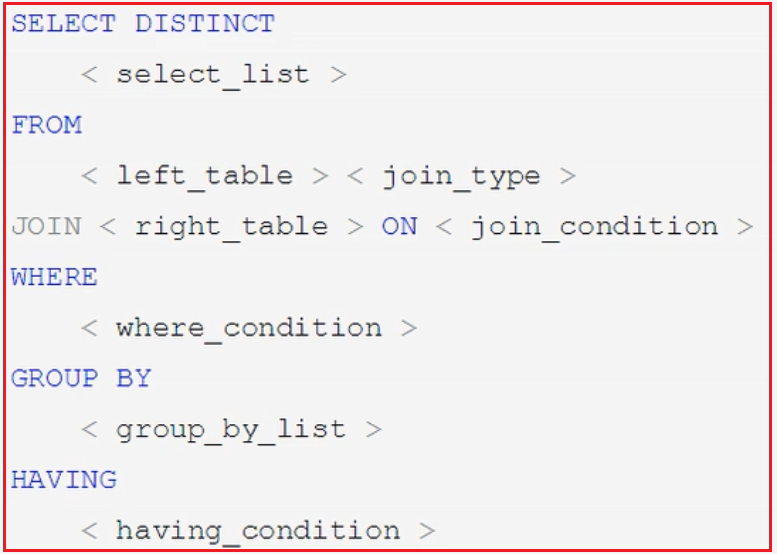
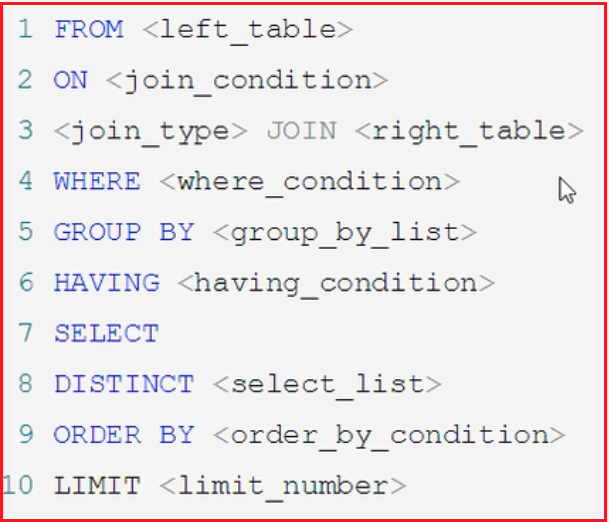
然后在优化器中可能就变成了下面这种(每次的优化都有可能不一样)
可以看看mysql中有几种执行引擎:show engines;
默认的就是Innodb,从下面可以看到这个引擎支持事务,行锁和外键,一般还会说MyISAM的特点,就是不支持事务,不支持行锁(只支持表锁),不支持外键;
两个引擎还有一个不同就是,MyISAM只缓存索引,而InnoDb缓存索引和实际的数据;
那什么时候会使用MyISAM引擎呢?其实就是mysql自带的一些表会用这个引擎,因为不需要高并发嘛,一般也是管理员去修改一下,所以锁住整张表也无所谓;

3.性能
项目中mysql使用时间长了之后, 性能会下降,sql的执行时间变长,一般有几个原因
(1)sql中关联的表太多:比如有太多的join,我们需要对sql进行优化
(2)没有充分的利用索引: 看情况去建立索引
(3)数据量太多:sql的优化已经到了极致,数据量太多就需要进行分库分表
(4)mysql服务器参数调优:这个一般也不会去修改,主要是调整my.cnf文件
对sql进行优化,一般就是添加索引,我们一些情况需要添加索引:
(1)频繁的作为查询条件的字段
(2)与其他表作为关联的字段
(3)建立组合索引优于单键索引
(4) 排序语句中的字段加索引,因为索引是已经排序好了的,可以极大的提高排序速度
(5)分组的字段,因为group by是先做的order by,然后再进行的分组
不应该创建索引的字段:
(1)表的记录太少了
(2)经常进行增删改的字段,因为也需要对索引进行相应的操作
(3)where条件中用不到的字段
(4)区分度不高的字段,比如性别
4 explain查看执行计划
在mysql的逻辑架构图中的第5步会调用优化器Optimizer会生成执行计划,然后执行引擎就是根据这个执行计划去执行sql的;
explain命令就是查看这个执行计划的,用法就是sxplain+sql语句,示例: explain select * from stu where id = 0
我们可以根据执行计划看到:
(1)表的读取顺序
(2) 操作表的操作类型
(3)索引的使用情况
(4)表之间的引用
(5)每张表有多少行数据被查询
...
下面中框框中是比较重要的字段,要明白其中的含义才能更好的分析,想知道每个字段详细意思的,看看这个老哥的博客

5 索引失效
有的时候一些不规范的sql写法会导致明明新建了sql,但是没有走索引,常见的有这么几种情况:
(1)没有遵循最左匹配原则,比如索引是(a,b,c),但是你只使用了b,或者(b,c)
(2)对索引列使用了!=进行判断,xxx where age != 10
(3)使用了is not null ,xxx where age is not null
(4)like模糊查询时百分号在前面, xxx where age like '%8'
(5)字符串不加引号,比如xxx where name = 1 ,name建立了索引,而且那么是varchar类型的,此时索引会失效
(6)对索引列使用函数计算了 ,例如xxx where max(age) > 10
6 关联查询优化
(1)a left join b : a是驱动表,a会全部扫描,b是被驱动表,b可以走索引
所以做连表查询的时候,数据少的做驱动表,数据多的建立索引,作为被驱动表,简称小表驱动大表
(2)a inner join b: mysql自己会将结果集小的作为驱动表,大的作为被驱动表
(3)子查询不要作为驱动表,可能用不到索引
(4)能关联的就直接关联查询,不要用子查询
7. 子查询优化
不要使用not in 或者not exists,使用改写sql写法,改成xxx a left join b on xxx is null,这样会走索引
8 排序分组优化
(1)(a,b)是索引,xxx where a = 1 order by b会走索引
(2)尽量使用索引字段进行排序,必须要有limit关键字才会走索引
(3)order by a desc,b asc : 一个降序,一个升序不会走索引
(4)order by a desc,desc : 走索引
9. 覆盖索引
select a,b from xxx
刚好(a,b)是索引,所以这个sql就会走索引查询数据直接返回,不会进行回表
10 mysql主从复制
原理如下:
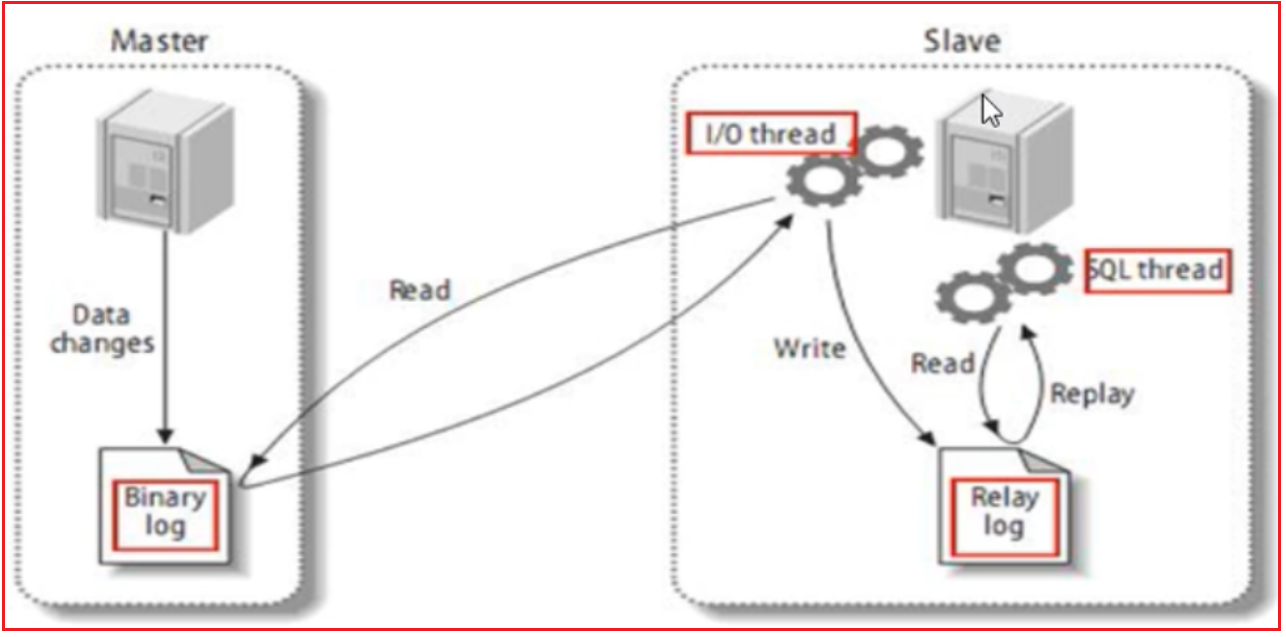
分三步:
1.主节点master将增删改的sql记录到二进制日志文件(binary log)中
2.从节点slave的io线程将主节点的二进制日志文件拷贝到自己的中继日志文件(Replay log)中
3. 从节点又启动一个sql线程去读取中继日志,执行sql
一般主从节点是在不同的服务器中,可以知道主从节点经过了多次io操作,所以主从复制会有延迟的效果,比如你往数据库中插入一条数据,然后你去查询却查不到

 浙公网安备 33010602011771号
浙公网安备 33010602011771号