
OO第一单元表达式求导总结
(一)基于度量来分析自己的程序结构
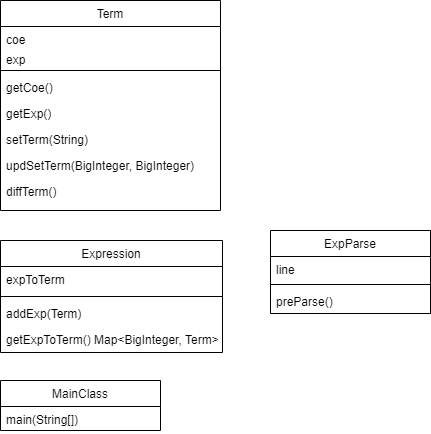
第一次作业
需求:处理幂函数的求导
程序架构:
-
![]()
-
ExpParse对读入的表达式进行预处理
-
Term存幂函数
-
Expression实现合并同类项
第二次作业
需求:系数+幂+三角函数+允许嵌套
程序架构:
-
![]()
-
ExpParse对读入表达式进行预处理
-
Parse作为递归下降解释器
-
ExpTree类为表达式树的节点类型 包含Factor和Operator两个属性
-
Factor类实现了因子的统一接口

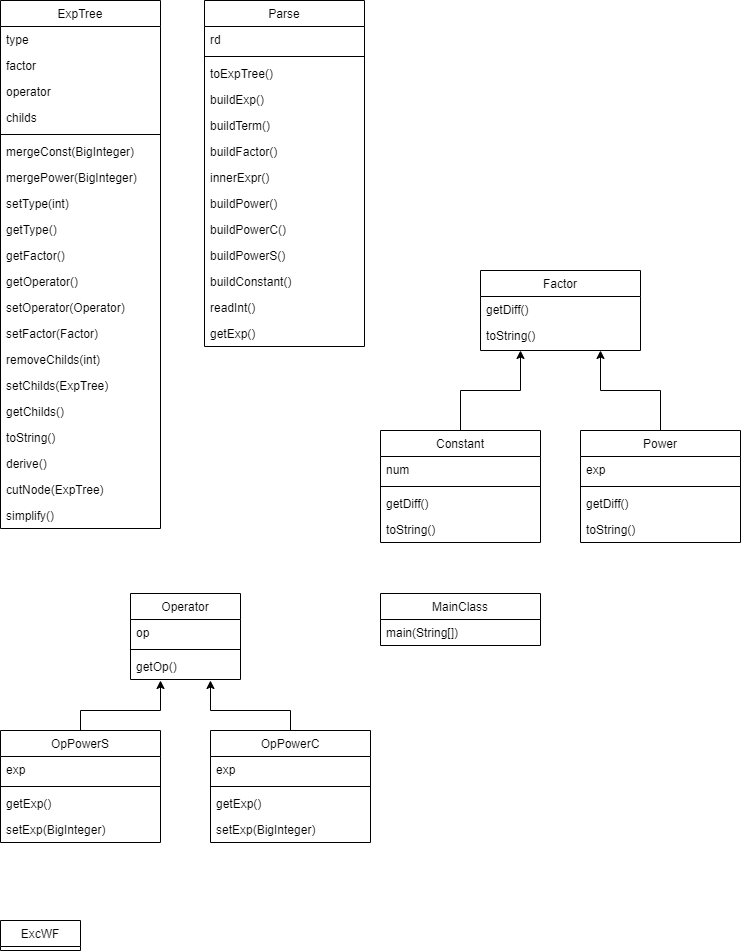
第三次作业
需求:判断WF+系数+幂+三角函数+允许嵌套
程序架构:
-
![]()
-
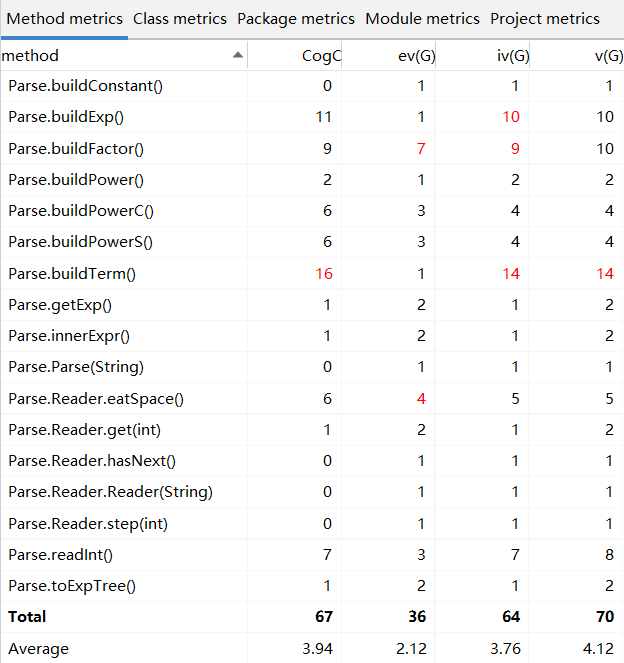
Parse使用递归下降方法判断WF并建树
-
![]()
-
buildExp(),buildFactor(),buildTerm()三者存在难以避免的较多的互相调用关系故耦合度较高
-
buildTerm()依题意存在较多独立路径条数
-
-
ExpTree类是表达式树的节点类型
-
![]()
-
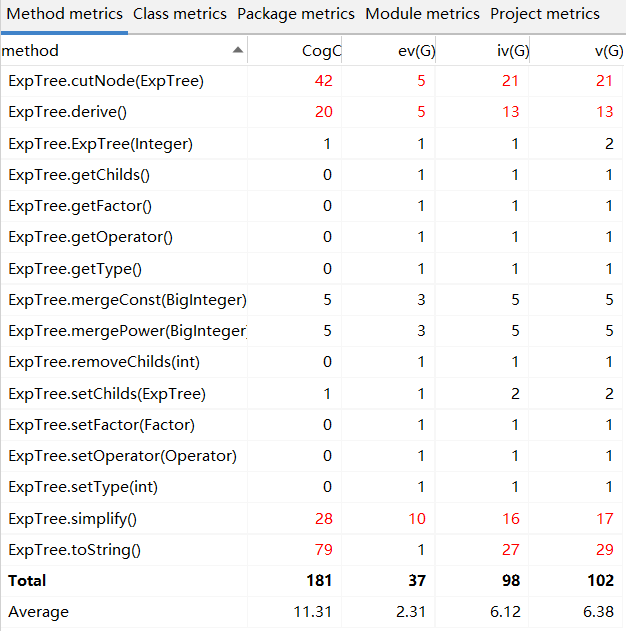
derive(),toString()方法都具有极高的复杂度,原因是没有考虑到Operator类可以实现求导和toString方法,并作统一接口在这三个函数中调用
-
cutNode()方法直接借鉴了数据结构中的剪树操作,是纯粹的面向过程写法故复杂度很高,更改同上述两方法
-
simplify()方法最后没有使用,故不作讨论
-
-
Factor和Operator仍然作为ExpTree的两个属性
-
OpPowerS和OpPowerC由于允许了三角函数的嵌套,此次作为单目运算符,统一继承了Operator
(二)分析自己程序的bug
第一次作业
写码过程中的自测:
-
第一次作业我选择首先对表达式进行符号预处理,即将三个或两个连续的+-替换为+或-,这一部分没有逻辑的话bug会很多
-
解析每一项的时候要注意前面+-号的处理,bug因人而异
-
由于我求系数和指数的方法设计的问题,在处理0作为系数或指数的数据时会出现0作为除数的报错
-
由于x**1可能会省略为x,我单独计数了x的个数,这里要注意x位于string.length-3之后会报地址越界访问的异常,建议提前处理
公测和强测:无
互测:
-
多个符号处理存在问题,如-+,-+-
可能存在的bug:
-
笔误,可以多次检查测试分支条件进行规避
-
BigInteger类调用了Integer方法
第二次作业
写码过程中的自测:无
公测:
-
sin(x)和cos(x)的求导方法直接写错,低级错误导致一个点都没过且浪费了一次提交机会和评测机资源
强测和互测:无
可能存在的bug:
-
无法处理过多层嵌套的括号
-
过度优化导致的WF
第三次作业
写码过程中的自测:
-
sin(expr)**exp的求导方法再次写错,又是一次低级错误
-
优化表达式树即剪树时最开始没有对节点被剪掉后的剩余数目进行讨论,仍然是逻辑不清就会有很多bug
-
无法处理空串/表达式前后空格,增加特判
公测:
-
没有认真读题:题目中对空串和指数绝对值不能超过50这两点增加了限制,但我最开始没有处理
-
输出结果不符合格式要求:混淆了项和因子的概念,最开始少了一条判断条件
强测和互测:
-
没有考虑到x**2是以因子的形式存于树中,不会额外加上括号,这里曾经删过一次但是最后优化的时候以为能够处理就又加了回来(问题有两点:理解得不够深刻&&分支条件犯懒未做充分测试)
可能存在的bug:
-
过度优化导致的WF
-
输出格式错误
以上三次作业公测、强测、互测的bug都不难改,只是增加了几处判断条件,故不涉及改变方法前后复杂度变化的问题
(三)分析自己发现别人程序bug所采用的策略
参考了往年学长学姐hack他人的策略,要分为黑盒测试和白盒测试。
-
黑盒部分:数据机和照猫画虎搭出的评测机
-
正常的数据
-
长数据卡正则爆栈 多层括号嵌套卡TLE
-
变换符号数量位置组合方式卡符号处理
-
在所有合法的位置出现0和爆int型的大数卡边界情况
-
-
白盒部分:直接阅读代码找可能出现bug的点,例如
-
笔误
-
针对各个分支条件测试(尤其是优化的部分)
-
考虑是否存在数组越界和指针指空的情况
-
检查长正则(推荐网站https://regexper.com/)
-
更一般的还有:考虑BigInteger类型是否调用了int类型的方法、考虑**替换为^是否会出问题等等
-
(四)重构经历总结
主要分两个部分:从第一次作业到第二次作业的大跨度、以及完成第三次作业后的复盘。
从第一次作业到第二次作业的大跨度
由于第一次作业需求非常简单,刚开始也没有着重考虑面向对象的核心思想,在需求变化后,我的第二次作业经历了规模巨大的重构。
支持嵌套:
-
存储:从仅仅记录了coe和exp的图Expression转换为建立表达式树ExpTree
-
读入:从正则匹配到递归下降
-
求导:从单一的求导方法到对不同的类实现不同的求导方法(可进一步实现统一的接口或继承自同一类改写方法)
优化:
-
将生成结果和优化分离成较为独立的两部分,优先保证正确性
完成第三次作业后的复盘
由于第三次作业相较于第二次作业只是细节上需要加以审查和改动,就并没有投入精力重构,但我的代码架构非常糟糕。
-
首先是没有认识到Factor Operator ExpTree三者存在的关系。Factor和Operator都是表达式树的节点类型,可以很自然地想到它们都是ExpTree的子类,采用枚举类型的方式来写,但是我并没有认识到这一点,选择把它们作为ExpTree节点的属性。
-
其次ExpTree内部的toString()方法写得非常的臃肿,纯粹是面向过程的写法,我需要知道这一节点是什么,然后决定针对这一节点用什么样的输出,事实上面向对象的思想是使用特化的方法,不关心节点的具体类型,而是我知道这里是一个节点,调用它输出的方法,无论它是加法、乘法、sin或者cos类型,都已经实现过它的输出。derive()方法同理。
-
没有使用函数的自觉,解决checkstyle的60行方法行数限制主要依赖括号换行,if else嵌套的逻辑非常混乱,可以说是因为懒惰牺牲可读性和代码篇幅的典范。事实上,调用函数完成大部分处理写法上码量小、易于修改、可读性更好;清晰的if else逻辑更易于debug和分析自己代码的逻辑结构。
-
get()和set()的使用上存在严重的问题,我的get set的方法内部没有任何检查,无法防止非法的参数,正确的做法是加入检查或者在此次作业里更换为枚举类型。
-
最后是设计思路的问题,解释器并不是第一单元作业的核心问题,求导才是,如何针对求导设计对象,如何让解释器适配于设计好的对象,这才是合理的思考顺序,而我却本末倒置,在没有设计类和求导方法的情况下纠结于解释器。
(五)心得体会
-
-
纵然写码重构过程异常艰难,强测出现问题非常难过,复盘代码结构极其糟糕,但是收获无疑是巨大的。
-
往者不可谏,来者犹可追。共勉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号