zookeeper部署、redis单机、cluster部署
PV-PVC与zookeeper
-
zk简介:对服务进行注册与状态检测
服务端通过api向zk注册自己的服务地址,消费者中定义zk的地址,从zk中请求服务端的地址,拿到地址后去访问服务端
- 选举
选举机制:刚开始,只有一台,选举不成功(过半主机存活,票数才有效)
2起来了,此时选举有效,第一次选举时,没有zxid,一般按myid进行,谁的myid大,谁是leader ,所以一般是2或者是3为leader 1一般不是leader
即 三台机器几乎同时起来,3是leader 2比3先起来,2是leader 3比2先起来,3是leader

- 部署
# 若要以集群的方式进行部署 1、固定有几个节点,可直接在构建镜像的时候,在配置文件写死其余zk实例信息 2、不固定节点,可后面部署的时候,在yaml文件中传递变量 3、或在docker镜像构建时启动时指定entrypoint脚本作为容器启动命令(本次做法)
构建镜像
主要定义dockerfile中的entrypoint,在其中定义一个entrypoint.sh脚本,用于初始化zookeeper角色
FROM 192.168.157.101/magedu/slim_java:8 ENV ZK_VERSION 3.4.14 ADD repositories /etc/apk/repositories # Download Zookeeper COPY zookeeper-3.4.14.tar.gz /tmp/zk.tgz COPY zookeeper-3.4.14.tar.gz.asc /tmp/zk.tgz.asc COPY KEYS /tmp/KEYS RUN apk add --no-cache --virtual .build-deps \ ca-certificates \ gnupg \ tar \ wget && \ # # Install dependencies apk add --no-cache \ bash && \ # # # Verify the signature export GNUPGHOME="$(mktemp -d)" && \ gpg -q --batch --import /tmp/KEYS && \ gpg -q --batch --no-auto-key-retrieve --verify /tmp/zk.tgz.asc /tmp/zk.tgz && \ # # Set up directories # mkdir -p /zookeeper/data /zookeeper/wal /zookeeper/log && \ # # Install tar -x -C /zookeeper --strip-components=1 --no-same-owner -f /tmp/zk.tgz && \ # # Slim down cd /zookeeper && \ cp dist-maven/zookeeper-${ZK_VERSION}.jar . && \ rm -rf \ *.txt \ *.xml \ bin/README.txt \ bin/*.cmd \ conf/* \ contrib \ dist-maven \ docs \ lib/*.txt \ lib/cobertura \ lib/jdiff \ recipes \ src \ zookeeper-*.asc \ zookeeper-*.md5 \ zookeeper-*.sha1 && \ # # Clean up apk del .build-deps && \ rm -rf /tmp/* "$GNUPGHOME" COPY conf /zookeeper/conf/ COPY bin/zkReady.sh /zookeeper/bin/ COPY entrypoint.sh / ENV PATH=/zookeeper/bin:${PATH} \ ZOO_LOG_DIR=/zookeeper/log \ ZOO_LOG4J_PROP="INFO, CONSOLE, ROLLINGFILE" \ JMXPORT=9010 ENTRYPOINT [ "/entrypoint.sh" ] CMD [ "zkServer.sh", "start-foreground" ] EXPOSE 2181 2888 3888 9010
- zk配置文件
tickTime=2000 ##投票周期/ms(或者说是心跳检测) initLimit=10 ##初始化尝试次数,10次,就是首次初始化时间为20s syncLimit=5 ## 副本同步次数 5次,当5个两秒钟还没进行同步,就认为实例宕机 dataDir=/zookeeper/data #数据目录 dataLogDir=/zookeeper/wal #日志目录 #snapCount=100000 #保存多少快照 autopurge.purgeInterval=1 clientPort=2181
zk的包,配置文件需要自己获取,构建镜像
创建pv-pvc
创建pv
--- apiVersion: v1 kind: PersistentVolume metadata: name: zookeeper-datadir-pv-1 spec: capacity: storage: 20Gi accessModes: - ReadWriteOnce nfs: server: 192.168.157.19 path: /data/k8sdata/magedu/zookeeper-datadir-1 --- apiVersion: v1 kind: PersistentVolume metadata: name: zookeeper-datadir-pv-2 spec: capacity: storage: 20Gi accessModes: - ReadWriteOnce nfs: server: 192.168.157.19 path: /data/k8sdata/magedu/zookeeper-datadir-2 --- apiVersion: v1 kind: PersistentVolume metadata: name: zookeeper-datadir-pv-3 spec: capacity: storage: 20Gi accessModes: - ReadWriteOnce nfs: server: 192.168.157.19 path: /data/k8sdata/magedu/zookeeper-datadir-3
创建pvc
--- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: zookeeper-datadir-pvc-1 namespace: magedu spec: accessModes: - ReadWriteOnce volumeName: zookeeper-datadir-pv-1 resources: requests: storage: 10Gi --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: zookeeper-datadir-pvc-2 namespace: magedu spec: accessModes: - ReadWriteOnce volumeName: zookeeper-datadir-pv-2 resources: requests: storage: 10Gi --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: zookeeper-datadir-pvc-3 namespace: magedu spec: accessModes: - ReadWriteOnce volumeName: zookeeper-datadir-pv-3 resources: requests: storage: 10Gi
部署zookeeper
- 编排文件
3个deployment3个svc 通过每个实例的环境变量中的MYID,确认自己的myid号, 通过 SERVERS 确认有集群中有实例的server名 通过dockerfile中的entrypoint脚本将server.MYID=SERVERS:2888:3888集群信息写入配置文件中
apiVersion: v1 kind: Service metadata: name: zookeeper namespace: magedu spec: ports: - name: client port: 2181 selector: app: zookeeper --- apiVersion: v1 kind: Service metadata: name: zookeeper1 namespace: magedu spec: type: NodePort ports: - name: client port: 2181 nodePort: 32181 - name: followers port: 2888 - name: election port: 3888 selector: app: zookeeper server-id: "1" --- apiVersion: v1 kind: Service metadata: name: zookeeper2 namespace: magedu spec: type: NodePort ports: - name: client port: 2181 nodePort: 32182 - name: followers port: 2888 - name: election port: 3888 selector: app: zookeeper server-id: "2" --- apiVersion: v1 kind: Service metadata: name: zookeeper3 namespace: magedu spec: type: NodePort ports: - name: client port: 2181 nodePort: 32183 - name: followers port: 2888 - name: election port: 3888 selector: app: zookeeper server-id: "3" --- kind: Deployment #apiVersion: extensions/v1beta1 apiVersion: apps/v1 metadata: name: zookeeper1 namespace: magedu spec: replicas: 1 selector: matchLabels: app: zookeeper template: metadata: labels: app: zookeeper server-id: "1" spec: volumes: - name: data emptyDir: {} - name: wal emptyDir: medium: Memory containers: - name: server image: 192.168.157.101/magedu/zookeeper:v3.4.14 imagePullPolicy: Always env: - name: MYID value: "1" - name: SERVERS value: "zookeeper1,zookeeper2,zookeeper3" - name: JVMFLAGS value: "-Xmx2G" ports: - containerPort: 2181 - containerPort: 2888 - containerPort: 3888 volumeMounts: - mountPath: "/zookeeper/data" name: zookeeper-datadir-pvc-1 volumes: - name: zookeeper-datadir-pvc-1 persistentVolumeClaim: claimName: zookeeper-datadir-pvc-1 --- kind: Deployment #apiVersion: extensions/v1beta1 apiVersion: apps/v1 metadata: name: zookeeper2 namespace: magedu spec: replicas: 1 selector: matchLabels: app: zookeeper template: metadata: labels: app: zookeeper server-id: "2" spec: volumes: - name: data emptyDir: {} - name: wal emptyDir: medium: Memory containers: - name: server image: 192.168.157.101/magedu/zookeeper:v3.4.14 imagePullPolicy: Always env: - name: MYID value: "2" - name: SERVERS value: "zookeeper1,zookeeper2,zookeeper3" - name: JVMFLAGS value: "-Xmx2G" ports: - containerPort: 2181 - containerPort: 2888 - containerPort: 3888 volumeMounts: - mountPath: "/zookeeper/data" name: zookeeper-datadir-pvc-2 volumes: - name: zookeeper-datadir-pvc-2 persistentVolumeClaim: claimName: zookeeper-datadir-pvc-2 --- kind: Deployment #apiVersion: extensions/v1beta1 apiVersion: apps/v1 metadata: name: zookeeper3 namespace: magedu spec: replicas: 1 selector: matchLabels: app: zookeeper template: metadata: labels: app: zookeeper server-id: "3" spec: volumes: - name: data emptyDir: {} - name: wal emptyDir: medium: Memory containers: - name: server image: 192.168.157.101/magedu/zookeeper:v3.4.14 imagePullPolicy: Always env: - name: MYID value: "3" - name: SERVERS value: "zookeeper1,zookeeper2,zookeeper3" - name: JVMFLAGS value: "-Xmx2G" ports: - containerPort: 2181 - containerPort: 2888 - containerPort: 3888 volumeMounts: - mountPath: "/zookeeper/data" name: zookeeper-datadir-pvc-3 volumes: - name: zookeeper-datadir-pvc-3 persistentVolumeClaim: claimName: zookeeper-datadir-pvc-3
kubectl apply -f zookeeper.yaml
查看状态
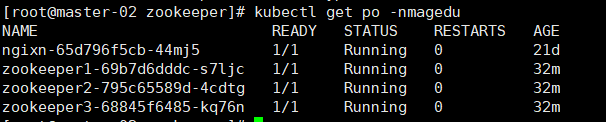
进去容器查看角色
- 进入zk1

- 进入zk2

- 进入zk3

其中:zk1、zk2为follower,zk3为leader
测试leader选举
过程(注意,若被删除的pod启动太快,可能不会有选举过程,可以尝试把harbor停掉,镜像拉取策略设为Always,这样就拉不到镜像,pod被删除后无法重建。):
1、删除pod
kubectl delete po zookeeper3-68845f6485-kq76n -nmagedu
2、切换角色(进去zk3看是否还是leader)

3、查看zk2实例(变为leader)

为什么2变为leader?
因为此时zookeeper内没有数据,当没有数据时,以myid大的为leader zk2实例myid为2,所以zk2为新的leader
PV-PVC与Redis
- 在redis中同时开了RDB快照模式和AOF模式,当redis宕机重启后,会以哪个为标准恢复数据(谁的优先级高)
答:AOF模式优先级高,因为aof的数据相比于rdb更为完整。若没有达到触发快照的条件,那时出现了宕机,那么将会丢失数据,这些数据是无法被恢复的,但是AOF会将每条数据记录在数据日志中,以aof为基准进行数据恢复更为安全和可靠
aof模式参数简介
- 开启aof模式
在redis中,默认是使用rdb快照模式,没有开启aof
设置appendonly on
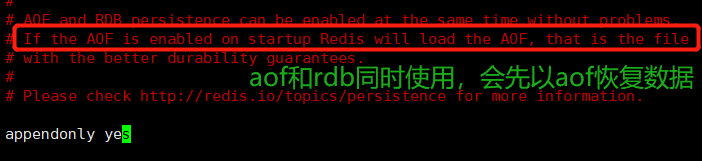
- aof默认文件名

- aof持久化策略
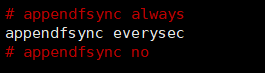
三种模式: 1、always:每次写入都执行fsync,保证写入磁盘中(类似mysql全同步)效率很低 2、everysec:每秒同步一次数据到磁盘中 3、no:不执行fsync,由操作系统保证同步到磁盘中,效率最高,速度快,但是丢数据风险大
- no-appendfsync-on-rewrite
当redis进行bgrewriteaof和往aof文件中写数据时,会造成磁盘竞争,当redis进行bgrewriteaof时,会对磁盘有大量的操作,会对写aof文件出现阻塞的情况,此时就能使用no-appendfsync-on-rewrite参数 no-appendfsync-on-rewrite设为yes 即相当于appendfsync设为no,说明写入redis的新数据没有直接写入磁盘,而是暂存缓冲区,因此不会造成阻塞。linux操作系统的默认操作下,最多丢失30s的数据。 no-appendfsync-on-rewrite设为no,即允许出现磁盘竞争,此时数据是最安全的,不用担心丢失数据,但是会出现磁盘阻塞的情况
- bgrewriteaof重写原理
当redis写入命令时是一条一条写入如 a1时刻写入 a b c 三条数据 a2时刻写入 d e f 三条数据 那么当恢复数据的时候,就是通过两条命令进行数据恢复 但是进行了bgrewriteaof重写后 如a3时刻进行bgrewriteaof重写,命令就会变成 a3时刻 a b c d e f 合并成一条命令 这样,在会大大节省aof文件的大小,并且加快数据恢复的速度 或者: a1时刻:set a b c d a2时刻:delete c b a3时刻进行bgrewriteaof重写 重写结束后aof日志为: set a d 直接将数据中已经没有的数据不进行恢复。或将已经修改的数据,按最新的值恢复。
即:会将已经不存在的值去除,减少命令执行次数
- auto-aof-rewrite-percentage
默认值为100。aof自动重写配置,当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日志文件进行重写。
当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程
- auto-aof-rewrite-min-size
设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写
- aof-load-truncated
重启可能发生在redis所在的主机操作系统宕机后,尤其在ext4文件系统没有加上data=ordered选项,aof文件可能在尾部是不完整的 yes:导入尽可能多的数据 no:选择让redis退出,用户必须手动redis-check-aof修复AOF文件才可以。 默认值为 yes。
构建redis镜像
- dockerfile
FROM 192.168.157.101/library/magedu-centos-base:7.9.2009 MAINTAINER zhangshijie "zhangshijie@magedu.net" ADD redis-4.0.14.tar.gz /usr/local/src RUN ln -sv /usr/local/src/redis-4.0.14 /usr/local/redis && cd /usr/local/redis && make && cp src/redis-cli /usr/sbin/ && cp src/redis-server /usr/sbin/ && mkdir -pv /data/redis-data ADD redis.conf /usr/local/redis/redis.conf ADD run_redis.sh /usr/local/redis/run_redis.sh EXPOSE 6379 CMD ["/usr/local/redis/run_redis.sh"]
- run_redis.sh
#!/bin/bash /usr/sbin/redis-server /usr/local/redis/redis.conf tail -f /etc/hosts
部署单机redis
创建pv-pvc
- 创建pv
apiVersion: v1 kind: PersistentVolume metadata: name: redis-datadir-pv-1 namespace: magedu spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce nfs: path: /data/k8sdata/magedu/redis-datadir-1 server: 192.168.157.19
- 创建pvc
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: redis-datadir-pvc-1 namespace: magedu spec: volumeName: redis-datadir-pv-1 accessModes: - ReadWriteOnce resources: requests: storage: 10Gi

部署
kind: Deployment #apiVersion: extensions/v1beta1 apiVersion: apps/v1 metadata: labels: app: devops-redis name: deploy-devops-redis namespace: magedu spec: replicas: 1 selector: matchLabels: app: devops-redis template: metadata: labels: app: devops-redis spec: containers: - name: redis-container image: 192.168.157.101/magedu/redis:v4.0.14 imagePullPolicy: Always volumeMounts: - mountPath: "/data/redis-data/" name: redis-datadir volumes: - name: redis-datadir persistentVolumeClaim: claimName: redis-datadir-pvc-1 --- kind: Service apiVersion: v1 metadata: labels: app: devops-redis name: srv-devops-redis namespace: magedu spec: type: NodePort ports: - name: http port: 6379 targetPort: 6379 # nodePort: 36379 selector: app: devops-redis sessionAffinity: ClientIP sessionAffinityConfig: clientIP: timeoutSeconds: 10800
kubectl apply -f redis.yaml
测试
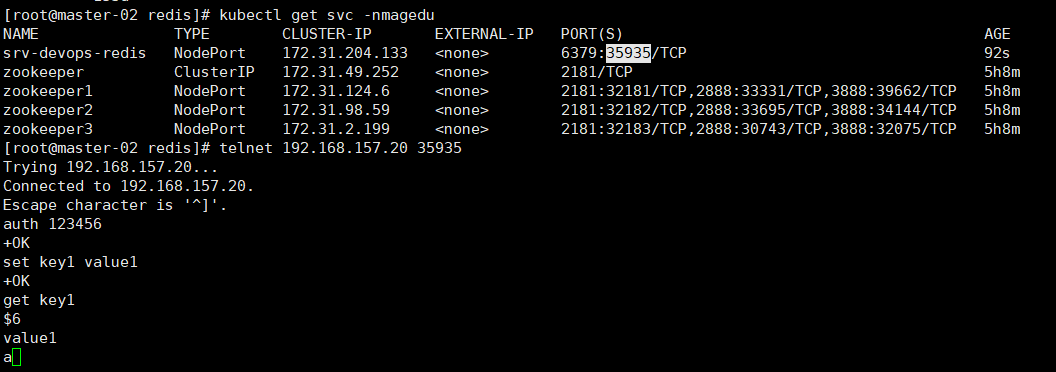
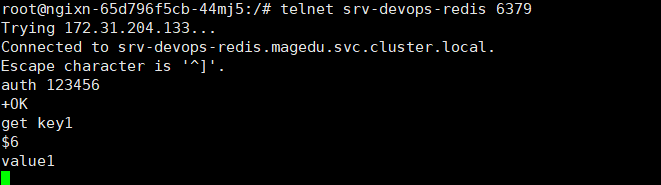
redis单机部署完毕并可正常使用
- 删除实例,重新访问svc,看数据是否能够恢复(数据已恢复)
PV-PVC与Redis Cluster
- 注意
redis cluster模式 一、槽位计算 1、在多分片节点中,将16384个槽位,均匀分布到多个分片节点中 2、存数据时,将key做crc16(key),然后和16384进行取模,得出槽位值(0-16383之间) 3、根据计算得出的槽位值,找到相对应的分片节点的主节点,存储到相应槽位上 4、如果客户端当时连接的节点不是将来要存储的分片节点,分片集群会将客户端连接切换至真正存储节点进行数据存储 二、读写都在主上,备只提供数据备份,当主宕机时,从节点变为主节点
- 创建流程
1、创建PV-PVC 2、部署redis cluster 3、初始化redis cluster 4、验证redis cluster 5、验证redis cluster高可用性
- 初始化命令
1、 3、4版本的使用redis-trib.rb进行集群初始化 2、 5+版本使用redis-cli进行初始化 两个命令参数是相同的
创建pv
- 在nfs服务器上
mkdir -p /data/k8sdata/magedu/redis{0,1,2,3,4,5}
- 创建pv
apiVersion: v1 kind: PersistentVolume metadata: name: redis-cluster-pv0 spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce nfs: server: 192.168.157.19 path: /data/k8sdata/magedu/redis0 --- apiVersion: v1 kind: PersistentVolume metadata: name: redis-cluster-pv1 spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce nfs: server: 192.168.157.19 path: /data/k8sdata/magedu/redis1 --- apiVersion: v1 kind: PersistentVolume metadata: name: redis-cluster-pv2 spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce nfs: server: 192.168.157.19 path: /data/k8sdata/magedu/redis2 --- apiVersion: v1 kind: PersistentVolume metadata: name: redis-cluster-pv3 spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce nfs: server: 192.168.157.19 path: /data/k8sdata/magedu/redis3 --- apiVersion: v1 kind: PersistentVolume metadata: name: redis-cluster-pv4 spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce nfs: server: 192.168.157.19 path: /data/k8sdata/magedu/redis4 --- apiVersion: v1 kind: PersistentVolume metadata: name: redis-cluster-pv5 spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce nfs: server: 192.168.157.19 path: /data/k8sdata/magedu/redis5
创建pvc
-
pvc在sts中能直接创建,有pvc模板,可以不用手动创建
前提:集群中已经创建好了pv或者可以动态创建pv - pvc模板名
模板名-sts名-创建顺序序号
生成绑定规则为:第一个pod对应第一个pvc
创建configmap
- redis.conf
appendonly yes cluster-enabled yes ## 集群模式需要检查这个参数,需要打开 cluster-config-file /var/lib/redis/nodes.conf cluster-node-timeout 5000 dir /var/lib/redis port 6379
- 创建configmap
kubectl create cm redis-conf --from-file=./redis.conf -nmagedu

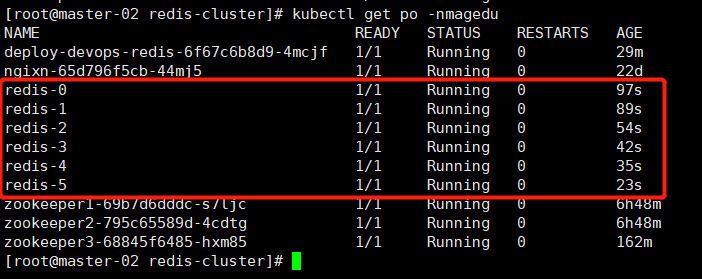
创建redis实例
apiVersion: v1 kind: Service metadata: name: redis namespace: magedu labels: app: redis spec: selector: app: redis appCluster: redis-cluster ports: - name: redis port: 6379 clusterIP: None --- apiVersion: v1 kind: Service metadata: name: redis-access namespace: magedu labels: app: redis spec: selector: app: redis appCluster: redis-cluster ports: - name: redis-access protocol: TCP port: 6379 targetPort: 6379 --- apiVersion: apps/v1 kind: StatefulSet metadata: name: redis namespace: magedu spec: serviceName: redis replicas: 6 selector: matchLabels: app: redis appCluster: redis-cluster template: metadata: labels: app: redis appCluster: redis-cluster spec: terminationGracePeriodSeconds: 20 affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - redis topologyKey: kubernetes.io/hostname containers: - name: redis image: 192.168.157.101/magedu/redis:4.0.14 command: - "redis-server" args: - "/etc/redis/redis.conf" - "--protected-mode" - "no" resources: limits: cpu: "500m" memory: "500Mi" requests: cpu: "500m" memory: "500Mi" ports: - containerPort: 6379 name: redis protocol: TCP - containerPort: 16379 name: cluster protocol: TCP volumeMounts: - name: conf mountPath: /etc/redis - name: data mountPath: /var/lib/redis volumes: - name: conf configMap: name: redis-conf items: - key: redis.conf path: redis.conf volumeClaimTemplates: - metadata: name: data namespace: magedu spec: accessModes: [ "ReadWriteOnce" ] resources: requests: storage: 5Gi
kubectl apply -f redis-cluster.yaml
初始化redis集群
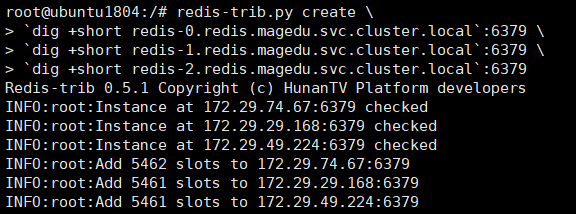
- 创建一个新容器来进行redis cluster初始化
## 运行容器 kubectl run -it ubuntu1804 --image=ubuntu:18.04 --restart=Never -n magedu bash ##基础环境准备 apt update apt install python2.7 python-pip redis-tools dnsutils iputils-ping net-tools pip install --upgrade pip pip install redis-trib==0.5.1 ## 初始化master redis-trib.py create \ `dig +short redis-0.redis.magedu.svc.cluster.local`:6379 \ `dig +short redis-1.redis.magedu.svc.cluster.local`:6379 \ `dig +short redis-2.redis.magedu.svc.cluster.local`:6379 ## redis3加入redis0 redis-trib.py replicate \ --master-addr `dig +short redis-0.redis.magedu.svc.cluster.local`:6379 \ --slave-addr `dig +short redis-3.redis.magedu.svc.cluster.local`:6379 ## redis4加入redis1 redis-trib.py replicate \ --master-addr `dig +short redis-1.redis.magedu.svc.cluster.local`:6379 \ --slave-addr `dig +short redis-4.redis.magedu.svc.cluster.local`:6379 ## redis5加入redis2 redis-trib.py replicate \ --master-addr `dig +short redis-2.redis.magedu.svc.cluster.local`:6379 \ --slave-addr `dig +short redis-5.redis.magedu.svc.cluster.local`:6379
- 初始化master
- redis-3加入redis-0

- redis-4加入redis1

- redis5加入redis2

验证redis cluster状态
- 进入redis-0
kubectl exec -it -nmagedu redis-0 bash
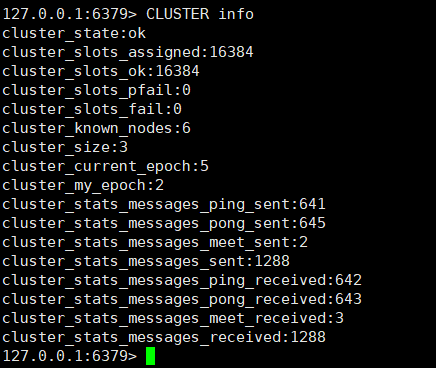
- 查看集群信息
cluster info
- 查看集群节点
cluster nodes

注意:
在其中一台redis中写数据,可能写不进去,因为做hash运算的时候,得出的槽位值不一定落在这个你进入的节点上
会提示你这个key的值应该会保存在哪个槽位
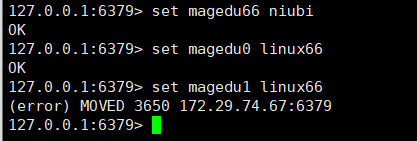
验证主从切换
- 删除redis-0
kubectl delete po -nmagedu redis-0
- 进入容器查看角色

主从自动切换,并且刚刚删除的pod自动将自己从宕机状态接入到成为master的redis3节点上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号