选哪儿网动态字体映射案例
案例:选哪儿网动态字体,字体映射案例。
地址:https://www.xuannaer.com/zhaopaigua
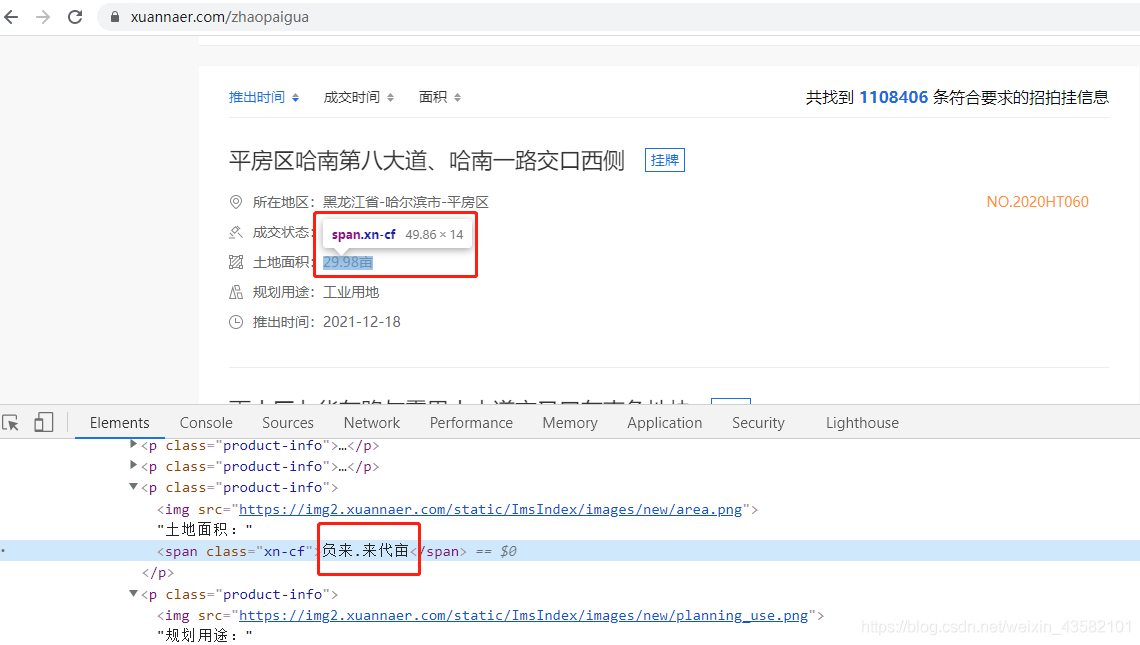
- 页面上的土地面积数字使用了字符来映射了,这里通过接口看到在返回前每次都请求了一个woff文件地址,该文件中有自定义的字体
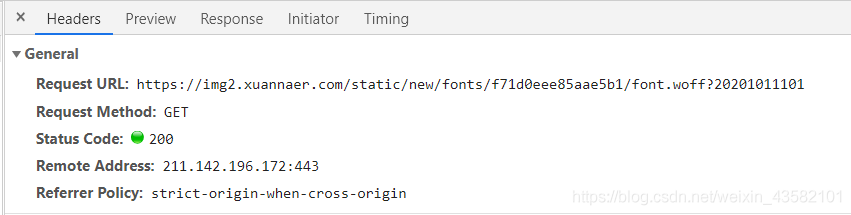
- woff文件地址可以在html中匹配出来。

我们保存一份woff文件下载到本地来分析下。
- 下载后使用python的 fontTools 库,把woff文件转成xml。
from fontTools.ttLib import TTFont
font = TTFont('zhaopaigua.woff')
font.saveXML('zhaopaigua.xml')
打开xml文件查看,每个人定义的规则可能存放在不同的标签中,有的可能在extraNames标签,有的可能在cmap 等,需要我们找一下。
观察了一下,在cmap中的cmap_format_4下

有字符 0x\d 和 *#\d ,这个0x\d 其实是字符,可以使用chr来转换。

这么看来 0x\d 和 *#\d 是存在某种对应关系的。先把他们以k-v形式保存下。
cmap = re.findall('<map code="(.*?)" name="(.*?)"/>',document,re.S)
item = {}
for node in cmap:
item[node[1]] = chr(eval(node[0]))
接下来要来观察下 *#\d ,这个自定义格式字符的存在意义了。
观察了一会儿文件没看出来,那么使用 FontCreator打开,可以看到有很多字符,每个头上都有一个 uni\d。
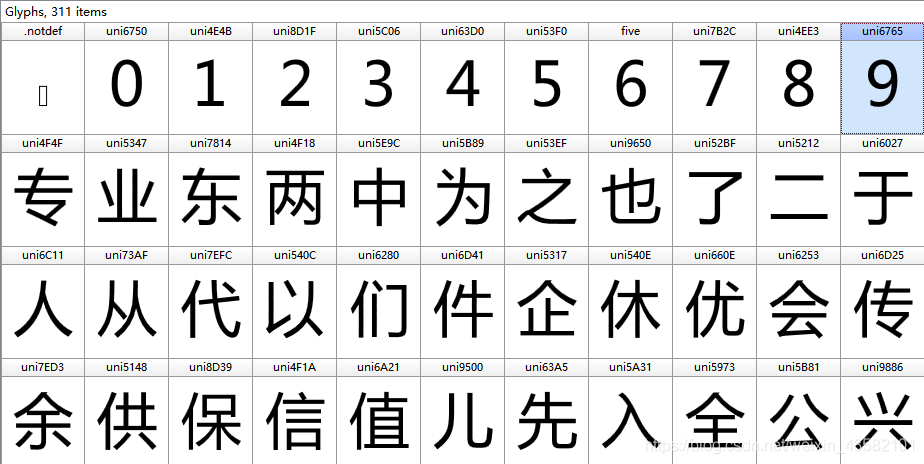
uni\d 后面的数字,比如 6765,是和xml文件中 0x6765 一致的。
另外 chr(0x6765)的值 是字符 “来”。还有 uni6765对应的真实数字是9
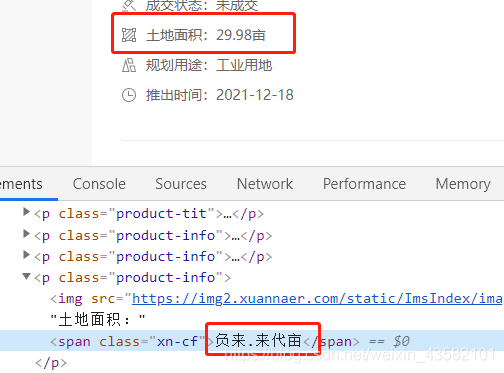
这么一来,我们再到xml文件中找规律。
0x6765对应的name是#8,#8在Glyph0rder标签的id正好是10。

再根据工具的排序进行对比。

就是Glyph0rder标签id对应的name(*#\d),是映射在map标签中的0x\d。Glyph0rder标签id 等于0-9的真实数字+1.
提取代码如下:
# -*- coding: utf-8 -*-
# Author: Lx
import requests
import re
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'origin': 'https://www.xuannaer.com',
'referer': 'https://www.xuannaer.com/',
'sec-fetch-dest': 'font',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site'
}
doc = requests.get('https://www.xuannaer.com/zhaopaigua',headers=headers).text
woff = re.findall('https://img2.xuannaer.com/static/new/fonts/\w{16}/font.woff\?\d{11}',doc,re.S)[0]
print(woff)
woff_bytes = requests.get(woff,headers=headers,allow_redirects=True)
with open('zhaopaigua.woff','wb') as f:
f.write(woff_bytes.content)
from fontTools.ttLib import TTFont
font = TTFont('zhaopaigua.woff')
font.saveXML('zhaopaigua.xml')
f = open('zhaopaigua.xml','r',encoding='utf-8')
document = f.read()
f.close()
cmap = re.findall('<map code="(.*?)" name="(.*?)"/>',document,re.S)
item = {}
for node in cmap:
item[node[1]] = chr(eval(node[0]))
GlyphID = re.findall('<GlyphID id="(\d+)" name="(.*?)"/>',document,re.S)[1:]
#print(item)
# 只要数字 取0-9 前10个元素
result = {}
for li in GlyphID[:10]:
num = int(li[0])-1 # 正确的数字
result[item[li[1]]]=num
print(result)
输出结果: {‘材’: 0, ‘之’: 1, ‘负’: 2, ‘将’: 3, ‘提’: 4, ‘台’: 5, ‘5’: 6, ‘第’: 7, ‘代’: 8, ‘来’: 9}
然后把页面中的土地面积换成字典的v值即可。
另外:TTFont中有针对标签进行解析的方法,但是这里没有使用到这些,我就直接用正则提取元素。
from fontTools.ttLib import TTFont
font = TTFont('zhaopaigua.woff')
font.saveXML('zhaopaigua.xml')
#print(font.keys())
# 获取getGlyphOrder节点的name值,返回为列表
#print(font.getGlyphOrder())
# 获取hmtx节点的name值,返回为列表
#print(font.getGlyphNames())
# 获取cmap节点code与name值映射, 返回为字典
#print(font.getBestCmap())
# 获取glyf节点TTGlyph字体xy坐标信息
#print(font['glyf']['*#135'].coordinates)
#获取glyf节点TTGlyph字体xMin,yMin,xMax,yMax坐标信息:
#print(font['glyf']['*'].xMin)
#print(font['glyf']['*'].yMin)
#print(font['glyf']['*'].xMax)
#print(font['glyf']['*'].yMax)
本文来自博客园,作者:愺様,转载请注明原文链接:https://www.cnblogs.com/wyh0923/p/14346120.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号