
kubernetes 知识点
1.管理、控制pod
1.1.ReplicationController
复制控制: 确保有设定数量的pod复本在运行,通过标签选择器来关联pod ,标签改变,pod脱离replicationController控制,rc 会为新标签创建设定数量的pod,不管pod死亡,或者修改标签脱离rc控制,rc始终会保证当前选择的标签pod有设定数量的复本在运行。如果节点故障,则在其它节点启动。
-
pod健康检查探针
- http get 返回状态码2XX 3XX则健康
- tcp端口,正常链接则健康
- exec在容器内执行命令,检查返回值为0 则健康
-
修改pod模板
只会影响新创建的pod ,新创建的pod将使用新模板,而已有的不受影响,可能通过些机制平滑升级应用,
1.2.ReplicaSet
ReplicationController 的改进版,最终完全取代ReplicationController
改进特性:
- 多标签选择
- 只匹配标签key,不管值 类似 key1=*
- 多标签组合匹配
1.3.DaemonSet
每节点运行一个pod , 或者特定的部分节点,每节点运行一个pod ,比如日志收集,资源监视此类应用*
1.4.job
运行一个任务,任务完成所即终止,此类pod用job控制
Cronjob 定时任务pod,和linux crontab用法类似
2.客户端与pod的通信
2.1.服务
服务是一种为一组功能相同的pod提供单一不变接入点(比如IP端口)的资源,当服务存在后,他的IP和端口不会变,客户能过服务的接入点访问到该服务后端任一pod.
2.2 集群内接入点(集群IP)
- 环境变量: kubernetes 将服务接入点IP信息生成环境变量,注入到之后创建的客户端pod中
- K8S内部DNS服务: 通过服务名称访问,但端口号仍然要通过环境变量获取
2.3 外部客户端访问pod
-
nodeport 方式: 每节点开一个端口,映射到后端pod,不一定是本节点上的pod,也可能是其它节点的pod, 考虑单节点负载及故障可能, 集群之外还需要负载均衡器, 指向所有节点.
-
负载均衡器, 此方式只能支持k8s的云环境使用, 会自动创建负载均衡器.
-
Ingress 七层,比如可以用nginx实现,可以根据url路径转发。前两种方式都的4层,端口转发,每服务需要一个公网IP
3.存储
3.1 常用卷类型
-
**emptyDir **
一个空目录,生命周期和Pod相同,用于一个Pod中的容器共享文件,当删除pod时内容丢失。
-
hostPath
持久存储,访问pod所在节点主机上的文件系统,
-
NFS
持久存储,集群共享,可作为应用数据存储,共享网络文件系统
-
云磁盘,像AWS EBS
持久存储,集群共享,可作为应用数据存储,共享网络文件系统
共享磁盘
-
persistentVolumeClaim
一种使用预置或者动态配置的持久存储类型
- NFS
- 云磁盘
- FC
- iscisi
3.2 存储与POD的解耦
-
系统管理员配置持久卷,即PV
-
用户定义pod是指定持久卷声明,而不用关心底层存储的具体细节
4 配置应用程序
4.1 ConfigMap
向程序(pod中的容器)传递参数两种方式,两种方式本质上都是传递一个变量的值,配置文件也是一种方式,但太重量级了,相当于硬编码到程序中,每次修改配置文件要重新构建镜像加载(一般要重启),或者要将配置文件挂载到容器,配置文件中敏感信息暴露。
- 命令行参数
- 环境变量
以上两种方式,将配置信息硬编码到的pod的yaml定义中了
- ConfigMap解耦配置信息和pod的定义文件,在pod中引用ConfigMap的键值即可.
4.2 Secret
与ConfigMap类似,用来保存敏感配置信息
kubernetes通过仅仅将Secret分发到需要访问Secret的pod所在节点的机器来保障其安全性,另外Secret只会存储在节点的内存中,永不写入物理存储
5 升级应用
5.1 升级应用的三种策略
-
直接升级
删除旧应用,启动新应用
-
蓝绿发布
部署同样多的新应用节点,旧应用不动(需要2倍的服务器资源),确定新应用OK,将流量切换到新应用
-
滚动发布
升级小部分,用户新旧应用同时访问,根据新应用效果决定逐步升级旧应用节点,直到所有节点到升级完,或者新应用出现问题回滚,对线上应用影响较小
-
金丝雀发布/灰度发布
只升级1台节点,流量不让用户访问,而由测试人员对新版本进行线上测试,如果没问题,将少量流量切换到这个新版应用,确认没问题,逐步升级旧节点,将流程切换到新节点,直到升级完成。
5.2 K8s对应用升级的方式
5.2.1 kubectl rolling-update
升级过程由kubectl控制,而不是master进程,存在一定的风险,通过创建新旧Replicationcontroller ,添加pod标签,控制删除旧pod数量,创建新版pod的方式实现
5.2.2 Deployment
声明式升级应用,只需修改Deployment中的pod资源模板,kubernetes会自动将实际系统督导员收敛为资源中定义的状态, Deployment仍然是调用ReplicaSet控制pod,是比ReplicaSet更高阶的资源。
引入了控制升级过程中的一些功能特性,比如,暂停升级,控制升级速率,回滚。
6 有状态应用管理 StatefulSet
- 状态pod: 重启后主机名,IP ,主机名,存储等等资源保持不变。
- 每pod实例有自己的固定单独存储
- 保障集群中只有一个pod实例,而不能重复
- 节点故障,不会自动新建pod 替代,需要手动删除Pod
7 kubernetes 网络
-
kubernetes 自己并不实现网络,只明确了支持kubernets的网络要求
-
kubernetes网络需求集中在集群中pod互访,和多复本应用如何通过统一入口对集群内其它应用和集群外提供服务
7.1 kubernetes 网络要求
- 所有pod的ip地址不能重叠: 因为他们在一个集群内,之间经常有通信需求
- 所有pod都可直接通过ip访问其它pod , pod看到的自身ip 和其它pod访问自己的ip是同一个,也就是说,pod网络之间不能有NAT设备,是一个扁平网络
7.2 kubernetes网络实现方法
-
直接路由,将每一个节点看作一个路由器,该节点上的Pod网络即为连接在路由器上的网络。
- 可以直接使用静态路由表
- 使用动态路由协议,所有节点安装支持动态路由协议的软件
-
使用类似隧道的概念(使用较多),像 GRE , VXLAN之类,由插件实现,将pod网络数据封闭到节点网络数据之上
常用插件
-
flanne
-
Calico
-
Romana
-
8 kubernetes 架构
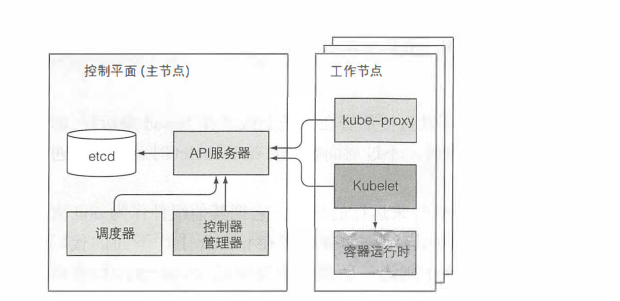
8.1 集群通信机制
- 所有组件(包括kubectl客户端)只和Api server通信,
- 所有组件只通过Api读写etcd数据库
- 所有集群数据都只能通过Apiserver存入eted数据库
- Apiserver不会做任何数据缓存
- 组件在api注册需要监听的资源,当资源变动时Apiserver会主动通知注册监听的组件
8.2 各组件作用
-
controller-manager控制资源管理
-
scheduler 负责调度pod到节点
-
kubelet负责Pod在节点上的一切工作
-
kuber-prox负责Pod访问接口管理,提供服务节点,主要更改iptables规则实现
8.3 集群高可用
- Apiserver可部署多台,多台可同时工作,互相之间不需要感知对方的存在,因为apiserver不缓存任何数据,数据全部在etcd中,前端加负载均衡。
- etcd本身就是分布式架构,原生支持多节点,一般为 3个或5个或7个即可。
- scheduler controller-manager 可同时部署多个,但是同一时间只有一个在工作,leader选举通过 etcd中某一键值实现乐观锁即可,其它待命,leader失效后,其它节点即会接替。
9. 安全控制
支持基于http token ,证书,其它认证
RBCA: 赋予角色权限,将角色绑定到账户,使用账户拥有角色的权限,可以进行精确的权限控制,资源路径的读写控制等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号