GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution【阅读笔记】
CVPR21 有被后面的视觉效果惊艳到。
现在利用GAN的SR方法主要可以分为两类:
1. 利用adversarial loss。 这种情况下generator要同时捕捉自然图像的特点,又要保留gt的特征。这就限制了generator估计真实图像流型的能力,导致结果出现artifacts和不自然的纹理。
2. GAN inversion。这种方法比较典型的就是PULSE。利用一个预训练的GAN,对其生成过程进行invert,相当于是在学得的自然图像流型上寻找一个corrupt后与LR最为接近的。这种方法的问题在于低维的latent code及图像空间中的constraints不足以guide复原过程。同时是以一种迭代式的方式进行,比较消耗时间。
本文提出的方法是一种新的利用GAN的方法,有一些类似第二种方法。使用一个预训练的GAN,找到一个最佳的latent vector进行重建。只不过寻找这个vector的过程用一个encoder进行学习。这样,捕捉自然图像的特点这个任务和保留gt的特征这个任务就分开了。
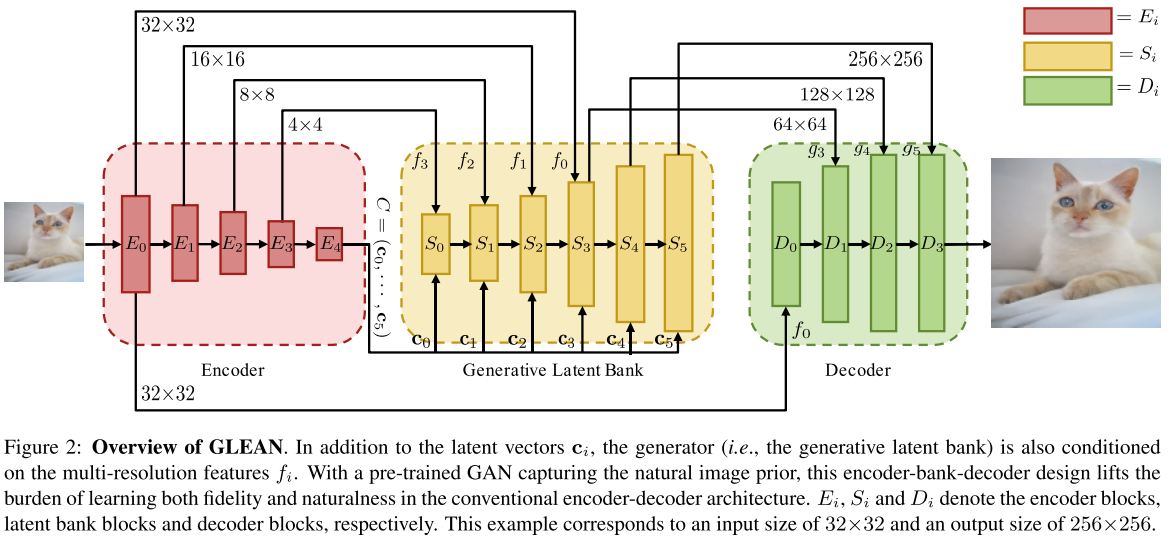
中间黄色部分的Generative Latent Bank是一个预训练的StyleGAN。区别在于,这里的输入是多个multi-resolution的特征,作为StyleGAN的condition。输出不直接由GAN进行,而是由decoder进行。
下面直接通过几个实验结果说明为什么这么设计:
- multi-resolution encoder:

如果只guided by 低维vector,空间信息无法被很好保留,网络只能恢复一些全局属性(如头发颜色,pose),细节的恢复并不好。随着更细的特征被传入,输出更加接近gt,图像质量也更好。这说明卷积特征对于恢复细节和局部结构都非常重要,只有latent vector是不够的。
- lantent bank:

去掉了中间的bank,逐步地将特征传给decoder。由于缺少先验信息,网络要同时生成真实细节和保留gt的特征,使得output在结构和纹理上都存在flaws。
- decoder:

去掉decoder后虽然输出还不错但仍存在一些细小的artifacts。decoder可以使网络以一种coarse-to-fine的方式整合信息,细节更为自然。同时,从encoder到decoder的multi-scale skip connection强化了encoder中捕捉到的空间信息特征,使得latent bank可以更专注于细节的生成。

实际上本文的方法在某种程度上和RefSR也有所关联,都利用了额外的HR图像作为imagery dictionary。但本文的方法不依赖于特定的component或是图片,dictionary的size和多样性都更大,也不需要进行复杂的global matching,component detection/selection等操作。

本文的方法还有一个额外的应用:Image Retouching,可以用来作为一个image retouching tool 消除一些artifacts

 浙公网安备 33010602011771号
浙公网安备 33010602011771号