

Exploring Simple Siamese Representation Learning【阅读笔记】
arxiv上23号新放出的何凯明大神的新作。针对Siamese Network中的collapsing问题进行了分析,并指出,目前避免这个问题的一些方法:负样本,大batch,momentum encoder其实都是不必要的。在避免collapsing问题中,stop-gradient操作非常重要,同时他的重要性说明了他可能解决的是另一个潜在的优化问题。
Siamese Network是近年来自监督/无监督任务中非常常用的网络,他是应用于两个或更多输入的一个权值共享的网络,是比较两个实体天然的工具。目前的大部分方法都是用一个图像的两种augmentation作为输入,在不同的条件下来最大化他们的相似度。但是Siamese Network会遇到的一个问题是,他的解可能会collapse至一个常量。目前常用的解决这个问题的方法有:Contrastive Learning,引入负样本,负样本会把constant 输出排除到解空间以外;Clustering;momentum encoder。
在本文中作者就指出,一个简单的Siamese 网络不需要以上方法也可以有效避免collapsing问题,并且不依赖于large-batch训练。作者将他们的方法称为“SimSiam”,并指出其中的stop-gradient操作才是在避免collapsing中非常重要的。这可能是由于有一个潜在的优化问题被解决了。作者推测实际上这里有两组变量,SimSiam实际上是在交替优化每一组变量。
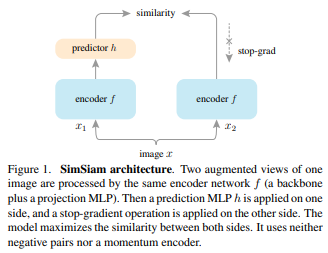

SimSiam和其他很多方法(SimCLR,SwAV,BYOL)都有联系,这应该是这些相关方法有效的关键原因。Siamese网络在建模不变性时引入了归纳偏置(inductive bias,或者说是先验)。这里的不变性(invariance)指的时同一个概念的两个观测应该产生相同结果。这其实和卷积是类似的。卷积实际上是一个成功的归纳偏置,他是通过在建模变换不变性时使用权值共享。而共享权值的Siamese网络则是针对更加复杂的变换(比如,augmentation)建模不变性。
Method
SimSiam结构如图1,输入是$x$的两个随机增强后的views $x_1, x_2$。通过一个包含一个主干网络(如ResNet)的encoder网络$f$和一个projection MLP head$h$。$f$在两个view之间是共享权值的,$h$的作用则是将一个view的输出变换到可以和另一个view匹配。
两个输出向量记为$p_1$和$z_2$,我们需要最小化他们的负余弦相似度:$D(p_1, z_2)=-\frac{p_1}{||p_1||_2}\cdot\frac{z_2}{||z_2||_2}$。如果考虑两个view的对称,在此基础上构造一个对称的loss:$L=\frac{1}{2}D(p_1, z_2)+\frac{1}{2}D(p_2, z_1)$,最小值是-1.
本文中非常重要的一个部分是stop-gradient操作:$D(p_1, stopgrad(z_2))$。这表示在这一项中$z_2$被视为一个常数。同样的,有$L=\frac{1}{2}D(p_1, stopgrad(z_2))+\frac{1}{2}D(p_2, stopgrad(z_1))$
网络设计部分这里就不详细介绍了。实验部分在ImageNet上进行无监督预训练得到表征,再用表征训练一个有监督线性分类器,用分类器的准确率来说明这些表征的质量。
Empirical Study
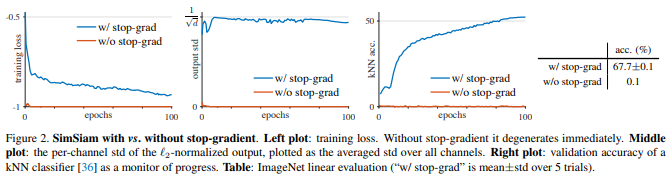
首先来看stop-gradient的作用。在没有stop-gradient的情况下,optimizer很快找到了一个退化的解并达到了loss的最小值-1.为了说明这个退化是collapsing造成的,作者研究了L2规范化后的输出的std。如果输出collapse成了一个常数向量,那么输出在每个channel上的std都会是0,正如图2中展示的那样。
这说明collapsing solutions是存在的,并且单靠网络结构(如predictor,BN,l2-norm)来预防是不够的。stop-gradient的有效性说明,可能有另外一个优化问题被潜在解决了。作者在之后针对这一问题提出了一个假设并加以验证。
此外作者还对Predictor,Batch_Size,BN,SimilarityFunc,Symmetrization的作用进行了研究。

如果去掉Predictor,表现会非常差,不论loss是对称的还是非对称的。这里的表现差并不是collapsing造成的,因为训练并没有收敛,loss始终很高。这说明predictor应该要能够适应表征,这样的效果才好。同时作者还发现,如果训练h时lr不减小,得到的表现会更好。作者推测这是因为h应该要与最新的表征相适应,在表征还没有完全训练好之前没有必要强迫h收敛。
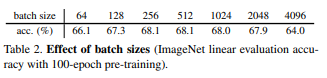
本文的方法适用于非常各种batch-size。虽然在batch过大时,标准的SGD optimizer表现不好。作者认为一个specialized optimizer可能可以缓解这个问题,但是并不能解决collapsing问题。

当去掉了所有的BN层时,表现虽然很差,但是并不会造成collapse。这里表现差可能是由于优化上的困难。总得来说,BN如果使用得当对于优化是有帮助的,这和其他监督学习场景下的结论一致。但是并没有证据表明BN可以帮助避免collapsing问题。
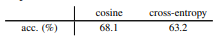

如果将D改为:$D(p_1, z_2)=-softmax(z_2)\dot logsoftmax(p_1)$,他也能收敛到一个合理的结果并没有collapsing。这说明避免collapsing的发生不是余弦相似度造成的。同样,loss的对称性也不是避免collapsing的原因。对称实际上是对每一个图片多进行了一次预测,可以提升准确率。
Hypothesis
通过前面的实验,作者分析了避免collapsing问题的关键在于stop-gradient,并推测这里有另外的一个潜在优化问题。他推测SimSiam实际上是一个类似于Expectation-Maximization(EM)的算法。他隐含两组变量,解决两个潜在的子问题。而stop-gradient的作用正是引入额外的一组变量。
考虑这样一个损失函数:$L(\theta, \eta)=\mathbb{E}_{x,\mathcal{T}}[||\mathcal{F}_\theta(\mathcal{T}(x))-\eta_x||^2_2]$, $\mathcal{T}$是augmentation,$\mathcal{F}$是以$\theta$为参数的网络。这里使用MSE,实际上和L2规范化后的余弦先四度是等价的。这里暂时先不考虑predictor。在这条式子中引入了一组新的变量$\eta$,$\eta_x$是图像$x$的表征。考虑最小化$L(\theta, \eta)$,那么这个式子就和k-means聚类非常相似。$\theta$相当于聚类中心,是encoder的一个可学习参数。$\eta_x$相当于样本$x$的assignment 向量(在k-means中是one-hot向量)。那么同样类似k-means,也可以alternating算法来解决这个优化问题,固定一组变量解决另一组变量。即在一下两个子问题中交替:
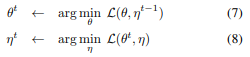
求解$\theta$时,$\eta^{t-1}$时常量,需要用stop-gradient让梯度不反向传播。求解$\eta$时,相当于是对于每一个图像$x$,最小化$\mathbb{E}_{\mathcal{T}}[||\mathcal{F}_\theta^t(\mathcal{T}(x))-\eta_x||^2_2]$.
接下来考虑加入predictor $h$。$h$的优化目标是最小化$\mathbb{E}_z[||h(z_1)-z_2||^2_2]$.他的解为:$h(z_1)=\mathbb{E}_z[z_2]=\mathbb{E}_\mathcal{T}[f(\mathcal{T}(x))]$,这就类似于上面的式(9)。predictor$h$的作用就相当于尝试学习预测这个期望。
而作者推测,SimSiam实际上是在一次SGD update中在式(7)和(8)交替。作者进行实验,让式(7)在k次SGD更新一次。首先与计算全部k个SGD step所需的$\eta_x$,再进行k次SGD更新$\theta$。得到如下结果。这说明SimSiam确实式alternating optimization的一个特例。之后实验证实了predictor的作用确实式估计$\mathbb{E}_\mathcal{T}[\cdot]$,这里就不详细介绍了。

Comparisons

在一些任务上的比较就不详细讲了,这里主要介绍一些和其他Siamese结构相关的工作的比较。SimSiam可以看作是其他的工作去掉某些部分。
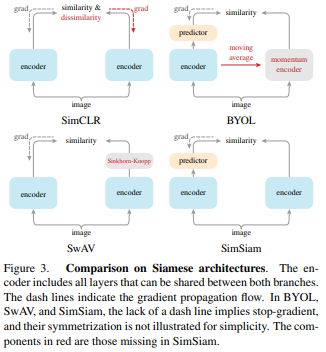
SimCLR without negatives:SimCLR是通过负样本来避免collapsing问题的。如果给SimCLR加入predictor和stop-grad,可以看到表现并没有提升。这是因为predictor和stop-grad实际上解决的是另一个优化问题,和对比学习不同,因此添加这些额外的部分并不一定有帮助。

SwAV without online clustering:由于SwAV本身就是基于聚类的方法,去掉stop-grad会造成发散

BYOL without the momentum encoder:momentoum encoder虽然可以提升表现,但并不能解决collapsing问题。此外,momentum encoder可能可以提供一个更smooth的$\eta$
感觉这篇文章还是非常insightful的。说明目前方法中,Siamese结构应该是他们有效性的关键,Siamese网络是建模不变性的一个很好的工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号