
Java集合详解
内容:
1、List相关
2、Set相关
3、Collection总结
4、Map相关
5、其他
1、List相关
(1)List集合存储数据的结构
List接口下有很多个集合,它们存储元素所采用的结构方式是不同的,这样就导致了这些集合有它们各自的特点,
在不同的环境下进行使用。数据存储的常用结构有:堆栈、队列、数组、链表
堆栈(栈)的特点:
- 先进后出
- 栈的入口和出口都是栈的顶端位置
- 压栈(压入元素)、弹栈(弹出元素)
队列的特点:
- 先进先出
- 队列的入口、出口各占一侧
数组的特点:
- 查找元素快(通过索引,可以快速访问指定位置的元素)
- 增删元素慢(需要移动元素)
链表的特点:
- 多个节点之间,通过地址进行连接
- 查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素
- 增删元素快:只需修改连接下个元素的地址
(2)List接口的特点及其实现类
List接口的特点:
- 有下标
- 有序的(存和取的顺序一致)
- 可重复
List接口实现类:ArrayList、LinkedList、Vector
- ArrayList:底层采用数组结构,查询快,增删慢 =》线程不安全
- LinkedList:底层采用链表结构,查询慢,增删快 =》线程不安全
- Vector:底层采用数组结构,查询快,增删慢 =》线程安全
List接口的方法:
- 增:add(E e) add(int index, E e)
- 删:remove(Object obj) remove(int index)
- 改:set(int index, E e)
- 查:get(int index)
- 其他方法:size()、clear()、contains(Object obj)、toArray()、iterator()、isEmpty()
实现类中的方法:
- ArrayList:方法基本和List中定义的一模一样
- LinkedList:除了和List接口中一样的方法之外,还有一些特有的方法
(3)LinkedList集合
LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合。实际开发中对一个集合元素的添加与删除
经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法。如下图

LinkedList是List的子类,List中的方法LinkedList都是可以使用,这里就不做详细介绍,我们只需要了解LinkedList的特有方法即可。
在开发时,LinkedList集合也可以作为堆栈,队列的结构使用
使用实例:
1 public class useLinkedList { 2 public static void main(String[] args) { 3 LinkedList<String> link = new LinkedList<String>(); 4 // 添加元素 5 link.addFirst("abc1"); 6 link.addFirst("abc2"); 7 link.addFirst("abc3"); 8 // 获取元素 9 System.out.println(link.getFirst()); // abc3 10 System.out.println(link.getLast()); // abc1 11 // 删除元素 12 System.out.println(link.removeFirst()); // abc3 13 System.out.println(link.removeLast()); // abc1 14 15 while (!link.isEmpty()) { // 判断集合是否为空 16 System.out.println(link.pop()); // 弹出集合中的栈顶元素 17 // abc2 18 } 19 } 20 }
2、Set相关
(1)Set接口的特点及其实现类
Set接口的特点:
- 无下标
- 无序的(无序是指存和取的顺序不一定一致,LinkedHashSet和TreeSet除外)
- 不可重复
Set接口实现类:HashSet、LinkedHashSet、TreeSet
- HashSet:底层采用哈希表结构,查询快,增删快,无序的
- LinkedHashSet:底层采用链表+哈希表结构,查询快,增删快,有序的
- TreeSet:底层采用红黑树结构,查询快,增删快, 有序的
Set接口的方法:没有特有方法,基本和父接口Collection类一模一样
实现类中的方法:实现类中的方法基本和Set一模一样
(2)哈希相关
对象的哈希值:任何对象都有一个哈希值,哈希值是对象的一个数字表示
对象的字符串表示:toString方法,默认表示格式:包名.类名@地址值(这里的地址值实际上是哈希值的16进制)
如何获取对象的哈希值 =》hashCode方法(默认按地址值计算)
什么是哈希表:
哈希表底层使用的也是数组机制,数组中也存放对象,而这些对象往数组中存放时的位置比较特殊,当需要把这些
对象给数组中存放时,那么会根据这些对象的特有数据结合相应的算法,计算出这个对象在数组中的位置,然后把
这个对象存放在数组中。而这样的数组就称为哈希数组,即就是哈希表
hashCode方法和equals方法:
当向哈希表中存放元素时,需要根据元素的特有数据结合相应的算法,这个算法就是Object类中的hashCode方法。
在给哈希表中存放对象时,会调用对象的hashCode方法,算出对象在表中的存放位置,这里需要注意,如果两个对象
hashCode方法算出结果一样,这样现象称为哈希冲突,这时会调用equals方法,比较这两个对象是不是同一个对象,
如果equals方法返回true,那么就不会把第二个对象存放在哈希表中,如果返回false,就会把这个值存放在哈希表中。
1 public class StringHashCodeDemo { 2 public static void main(String[] args) { 3 String s1 = new String("abc"); 4 String s2 = new String("abc"); 5 6 System.out.println(s1==s2); // false 7 System.out.println(s1.hashCode()==s2.hashCode()); // true 8 System.out.println(s1.equals(s2)); // true 9 10 } 11 }
注意:String类重写了hashCode方法,按照自己的方式计算(只要字符串内容一样哈希值一定相同)
总结:保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义
的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
哈希表结构判断元素是否重复的原理:
hashCode():先判断新元素的哈希值是否和旧元素哈希值相同,如果都不相同直接判断不重复,添加
equals():再调用新元素和哈希值相同的旧元素的equals方法,如果返回true判定重复元素,不添加,否则添加(不重复)
(3)Set使用实例
1 public class HashSetDemo { 2 3 public static void main(String[] args) { 4 // 创建HashSet对象 5 HashSet<String> hs = new HashSet<String>(); 6 // 给集合中添加自定义对象 7 hs.add("zhangsan"); 8 hs.add("lisi"); 9 hs.add("wangwu"); 10 hs.add("zhangsan"); 11 System.out.println(hs); 12 // 判断是否含有某个元素 13 System.out.println(hs.contains("lisi")); // true 14 // 取出集合中的每个元素 15 Iterator<String> it = hs.iterator(); 16 while (it.hasNext()) { 17 String s = it.next(); 18 System.out.println(s); 19 } 20 } 21 }
3、Collection总结
(1)Collection
Collection分类:
- List 可以存储重复元素,有序的(元素存取顺序),有索引 =》ArrayList、LinkedList
- Set 不能存储重复元素,无序的(元素存取顺序,LinkedHashSet是有序的),无索引 =》HashSet、LinkedHashSet
Collection方法:
- boolean add(Object e) 把给定的对象添加到当前集合中
- void clear() 清空集合中所有的元素
- boolean remove(Object o) 把给定的对象在当前集合中删除
- boolean contains(Object o) 判断当前集合中是否包含给定的对象
- boolean isEmpty() 判断当前集合是否为空
- Iterator iterator() 迭代器,用来遍历集合中的元素的
- int size() 返回集合中元素的个数
- Object[] toArray() 把集合中的元素,存储到数组中
- Iterator : 迭代器
- Object next() 返回迭代的下一个元素
- boolean hasNext() 如果仍有元素可以迭代,则返回 true。
(2)List和Set
List与Set集合的区别:
- List是一个有序的集合(元素存与取的顺序相同),可以存储重复的元素
- Set是一个无序的集合(元素存与取的顺序可能不同),不能存储重复的元素
List集合中的特有方法(下标):
- void add(int index, Object element) 将指定的元素,添加到该集合中的指定位置上
- Object get(int index)返回集合中指定位置的元素
- Object remove(int index) 移除列表中指定位置的元素, 返回的是被移除的元素
- Object set(int index, Object element)用指定元素替换集合中指定位置的元素,返回值的更新前的元素
List和Set的实现类:
ArrayList:
底层数据结构是数组,查询快,增删慢
线程不安全,效率高
LinkedList:
底层数据结构是链表,查询慢,增删快
线程不安全,效率高
Vector:
底层数据结构是数组,查询快,增删慢
线程安全,效率不高
HashSet:
元素唯一不能重复
底层结构是 哈希表结构
元素的存与取的顺序不能保证一致
LinkedHashSet:
元素唯一不能重复
底层结构是 链表结构+哈希表结构
元素的存与取的顺序一致
(3)Set中元素的唯一性
如何保证元素的唯一的:重写hashCode() 与 equals()方法
(4)contains
ArrayList的contains方法:
调用时,会使用传入的元素的equals方法依次与集合中的旧元素所比较,从而根据返回的布尔值判断
是否有重复元素。此时,当ArrayList存放自定义类型时,由于自定义类型在未重写equals方法前,判断是否重复的依据是地址值,
所以如果想根据内容判断是否为重复元素,需要重写元素的equals方法
HashSet的contains方法:
与add方法同理,先判断哈希值再使用equals方法判断,只要旧元素和判断的元素的哈希值相同并且equals方法为true才判定包含
4、Map相关
(1)Map集合的特点
- Map集合和Collection集合没有继承关系,所以不能直接用迭代器
- Collection集合每一个元素都是单独存在,而Map集合中的每一个元素都是成对存在
- Map<K, V> 两个泛型,K代表键的类型,V代表值的类型,K和V必须是引用类型
- 在Map集合的元素中键是唯一的,值是可以重复的
(2)Map接口常用集合概述(实现类)
通过查看Map接口描述,看到Map有多个子类,这里我们主要讲解常用的HashMap集合、LinkedHashMap集合:
HashMap<K,V>:存储数据采用的哈希表结构,元素的存取顺序不能保证一致。由于要保证键的唯一、不重复,
需要重写键的hashCode()方法、equals()方法。
LinkedHashMap<K,V>:HashMap下有个子类LinkedHashMap,存储数据采用的哈希表结构+链表结构。通过链表结构
可以保证元素的存取顺序一致;通过哈希表结构可以保证的键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
注:
- 当给HashMap中存放自定义对象时,如果自定义对象作为key存在,这时要保证对象唯一,必须复写对象的hashCode和equals方法
- 如果要保证map中存放的key和取出的顺序一致,可以使用LinkedHashMap集合来存放
(3)Map接口中的常用方法

1 public class HashMapDemo { 2 public static void main(String[] args) { 3 // 创建Map对象 4 Map<String, String> map = new HashMap<String, String>(); 5 // 给map中添加元素 6 map.put("星期一", "Monday"); 7 map.put("星期日", "Sunday"); 8 System.out.println(map); // {星期日=Sunday, 星期一=Monday} 9 10 // 当给Map中添加元素,会返回key对应的原来的value值,若key没有对应的值,返回null 11 System.out.println(map.put("星期一", "Mon")); // Monday 12 System.out.println(map); // {星期日=Sunday, 星期一=Mon} 13 14 // 根据指定的key获取对应的value 15 String en = map.get("星期日"); 16 System.out.println(en); // Sunday 17 18 // 根据key删除元素,会返回key对应的value值 19 String value = map.remove("星期日"); 20 System.out.println(value); // Sunday 21 System.out.println(map); // {星期一=Mon} 22 } 23 }
(4)Map集合遍历方式
键找值方式:即通过元素中的键,获取键所对应的值
- KeySet():获取Map集合中的所有键
- get(Object key):通过指定的键从map集合中找出相应的值
1 for(String key:map.keySet()){ 2 System.out.println(key + " = " + map.get(key)); 3 }
EntrySet方式(键值对方式):
在Map类设计时,提供了一个嵌套接口:Entry。Entry将键值对的对应关系封装成了对象。即键值对对象,这样我们在遍历Map集合时,
就可以从每一个键值对(Entry)对象中获取对应的键与对应的值:
1 Set<Map.Entry<String, String>> entrySet = map.entrySet(); 2 for (Map.Entry<String, String> entry : entrySet) { 3 Stringkey = entry.getKey(); 4 String value = entry.getValue(); 5 System.out.println(key+"....."+value); 6 } 7 8 // 上面的代码也可以简化成这样: 9 for (Map.Entry<String, String> entry : map.entrySet()) { 10 Stringkey = entry.getKey(); 11 String value = entry.getValue(); 12 System.out.println(key+"....."+value); 13 }
(5)LinkedHashMap
HashMap保证成对元素唯一,并且查询速度很快,可是成对元素存放进去是没有顺序的,那么我们要保证有序,还要速度快怎么办呢?
在HashMap下面有一个子类LinkedHashMap,它是链表和哈希表组合的一个数据存储结构,它可以保证有序
1 import java.util.*; 2 import java.util.Map.Entry; 3 4 public class LinkedHashMapDemo { 5 public static void main(String[] args) { 6 Map<String, String> map = new LinkedHashMap<String, String>(); 7 8 map.put("1", "a"); 9 map.put("2", "b"); 10 map.put("3", "c"); 11 12 for (Entry<String, String> entry : map.entrySet()) { 13 System.out.println(entry.getKey() + " " + entry.getValue()); 14 } 15 // 输出结果: 16 // 1 a 17 // 2 b 18 // 3 c 19 } 20 }
5、其他
(1)Properties类介绍
Properties类表示了一个持久的属性集。Properties可保存在流中或从流中加载。属性列表中每个键及其对应值都是一个字符串。
特点:
- 是Hashtable的子类,map集合中的方法都可以用
- 该集合没有泛型。键值都是字符串
- 是一个可以持久化的属性集。键值可以存储到集合中,也可以存储到持久化设备上。键值的来源也可以是持久化设备。
- 有和流技术相结合的方法。
特有的方法:
- public String getProperty(String key) 功能就是Map中的get方法
- public Object setProperty(String key, String value) 功能就是Map中的put方法
- public Set<String> stringPropertyNames() 返回此属性列表中的键集(Map中的KeySet方法)
和流技术结合的方法:
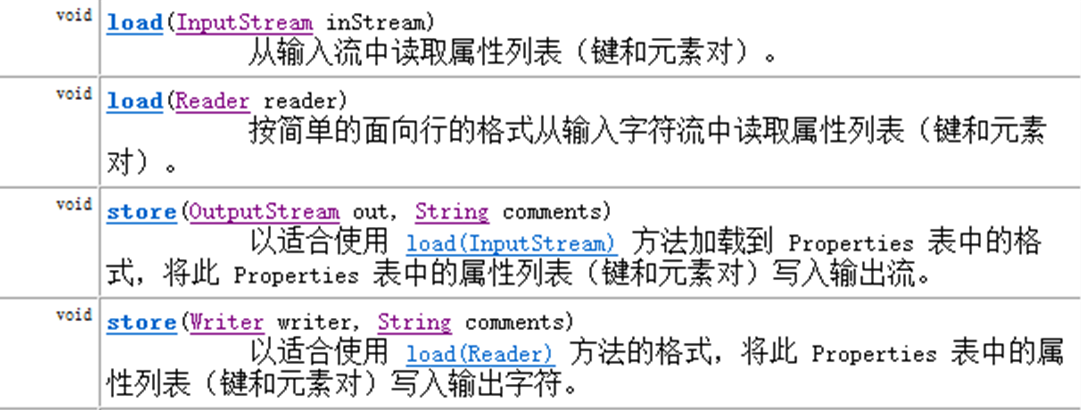
- store方法:保存数据到文件
- load方法:加载数据
1 import java.io.*; 2 import java.util.Properties; 3 4 public class PropertiesDemo { 5 public static void main(String[] args) throws IOException { 6 // 创建对象 7 Properties ps = new Properties(); 8 // 添加数据 9 ps.setProperty("test", "18"); 10 ps.setProperty("test2", "16"); 11 ps.setProperty("test3", "18"); 12 // 讲ps的数据持久化到文件中 13 ps.store(new FileWriter("test.properties"), "author is wyb"); 14 15 Properties t = new Properties(); 16 // 从文件中读取数据到t中 17 t.load(new FileReader("test.properties")); 18 // 遍历 19 for (String key : t.stringPropertyNames()) { 20 System.out.println(key + " = " + t.getProperty(key)); 21 } 22 } 23 }
(2)可变参数
1 public class ParamDemo { 2 public static void main(String[] args) { 3 int[] arr = {21,89,32}; 4 int sum = add(arr); 5 System.out.println(sum); 6 sum = add(21, 89, 32); // 可变参数调用形式(可以传任意多个参数) 7 System.out.println(sum); 8 9 } 10 11 //JDK1.5之后写法 12 public static int add(int...arr){ 13 int sum = 0; 14 for (int i = 0; i < arr.length; i++) { 15 sum += arr[i]; 16 } 17 return sum; 18 } 19 20 //原始写法 21 /* 22 public static int add(int[] arr) { 23 int sum = 0; 24 for (int i = 0; i < arr.length; i++) { 25 sum += arr[i]; 26 } 27 return sum; 28 } 29 */ 30 }
(3)Collections介绍
Collections是集合工具类(不能实例化),用来对集合进行操作。部分方法如下:

1 // 排序: 2 // 排序前元素list集合元素 [33,11,77,55] 3 Collections.sort( list ); 4 // 排序后元素list集合元素 [11,33,55,77] 5 6 // 打乱顺序: 7 // list集合元素 [11,33,55,77] 8 Collections.shuffle( list ); 9 // 使用shuffle方法后,集合中的元素就会被打乱,每次执行该方法,集合中存储的元素位置都会随机打乱

 浙公网安备 33010602011771号
浙公网安备 33010602011771号