第七章 查找 学习小结
一、本章思维导图(线性表、树表、散列表)
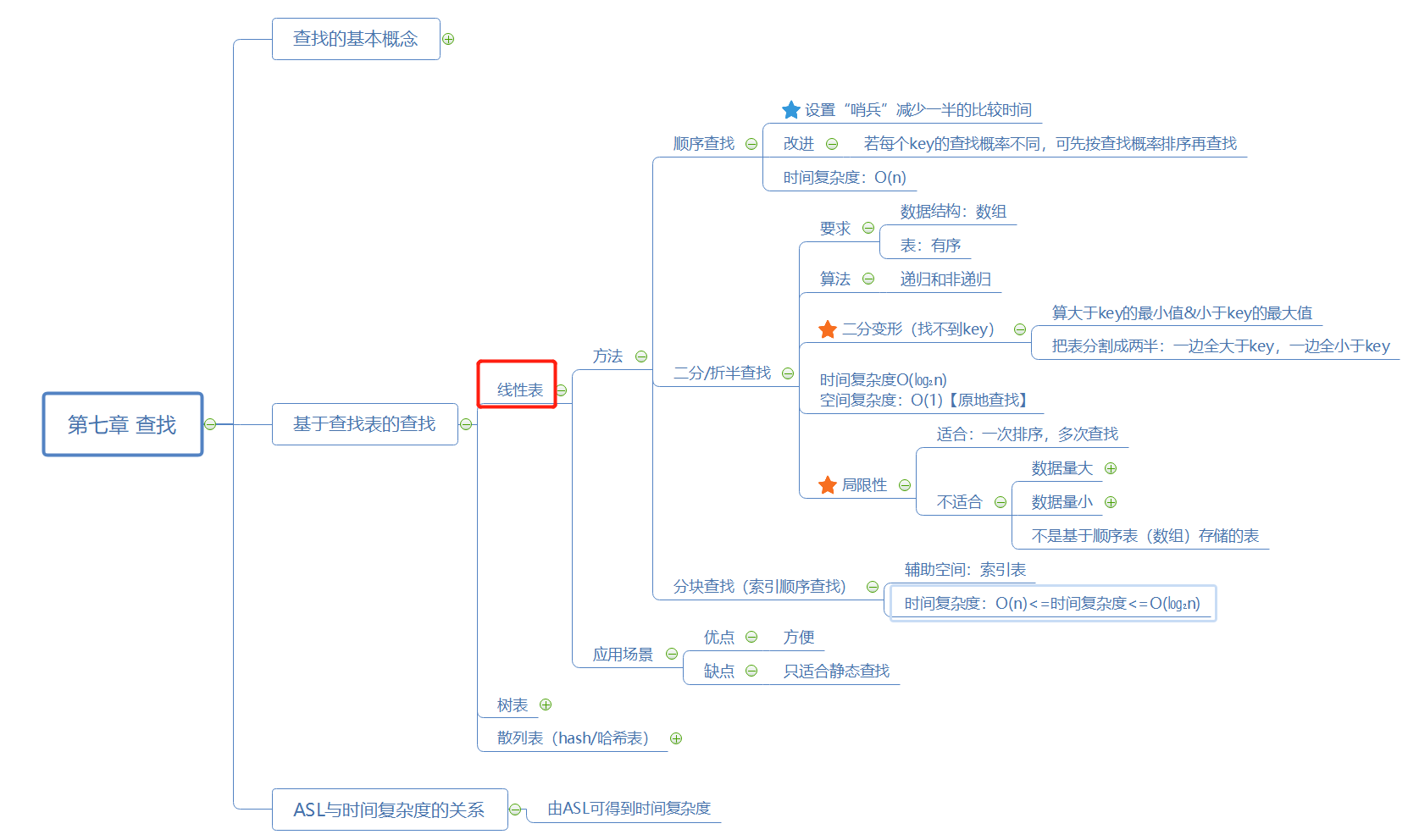
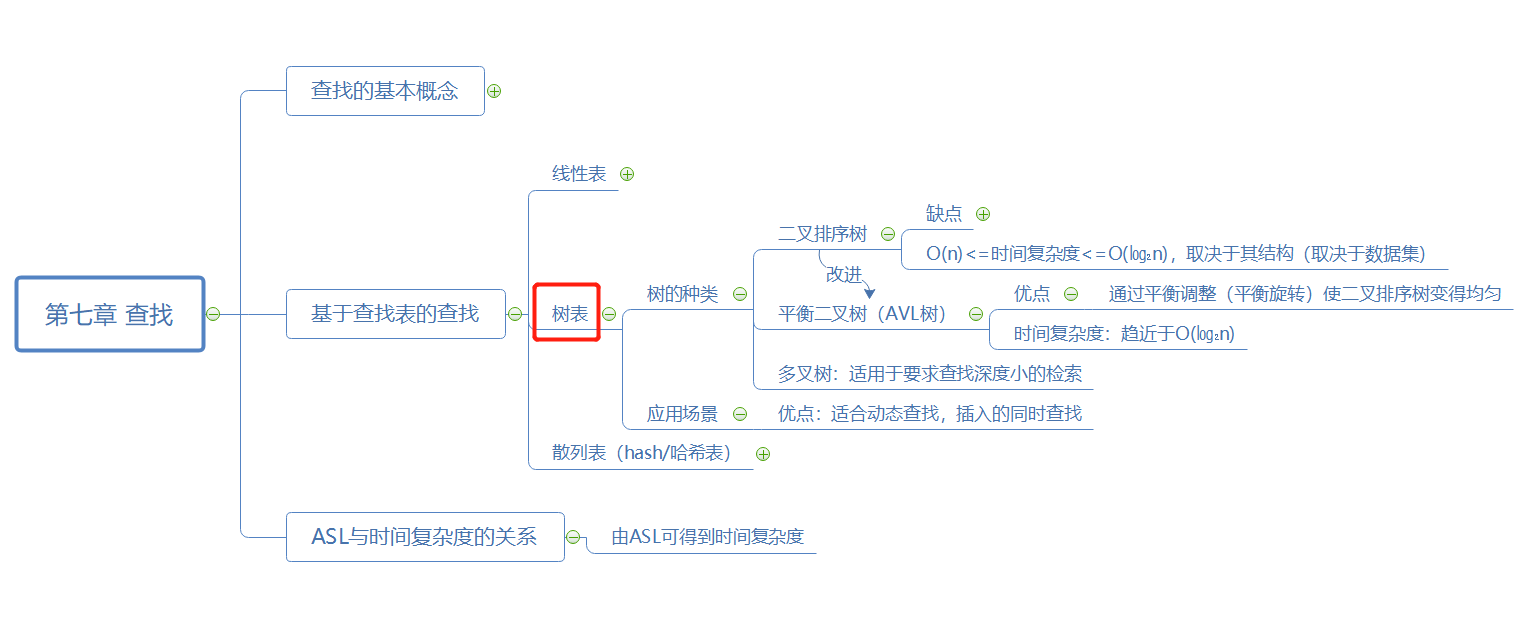
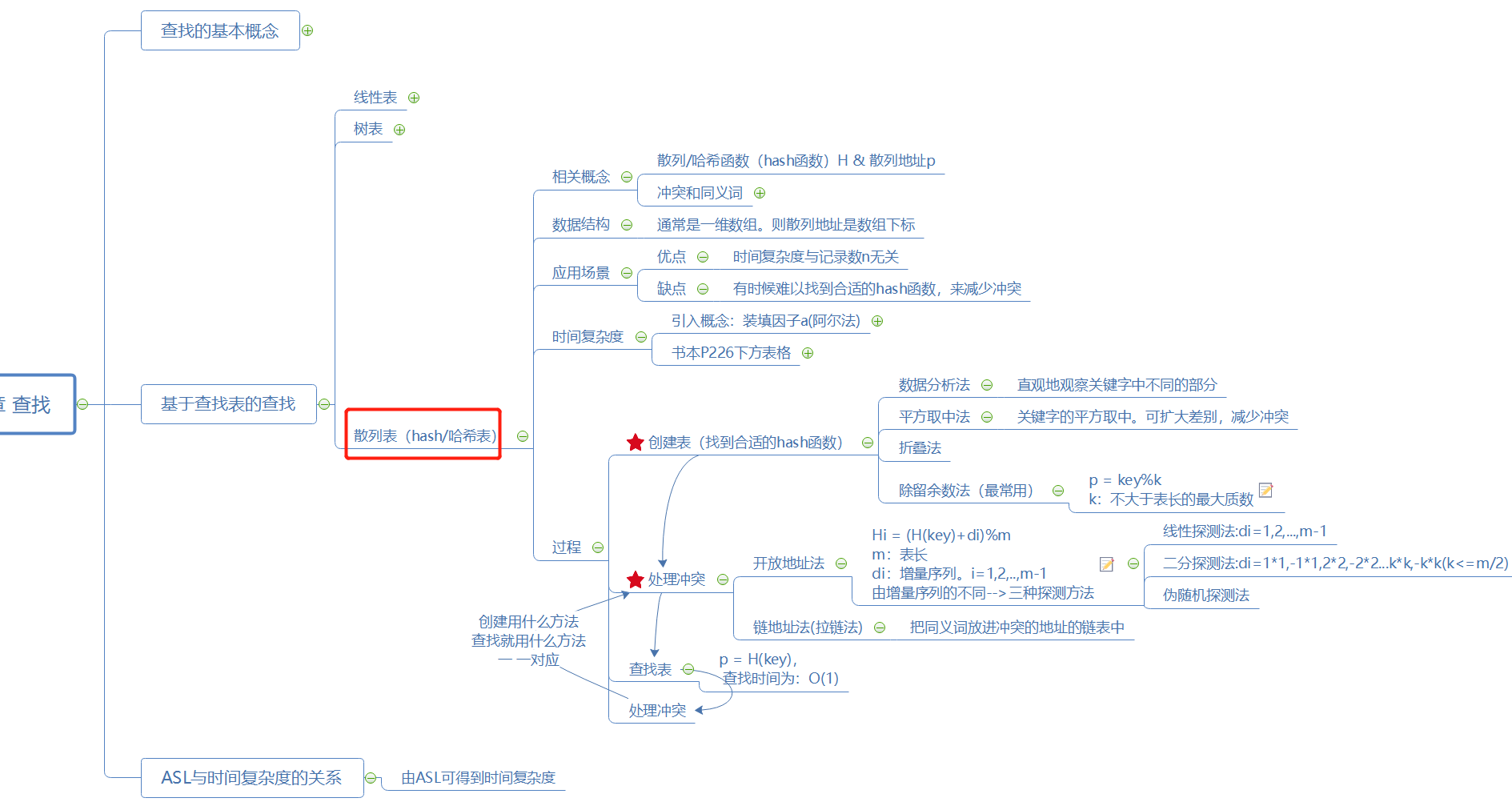
二、PTA实践及作业
1、链接:
【二分查找变形】https://pintia.cn/problem-sets/1271388011789213696/problems/1271388161957871616
【Hashing】https://pintia.cn/problem-sets/1271616578372419584/problems/1271616790973308946
2、【二分查找变形(面试)】
变形方向:
1)算大于key的最小值、小于key的最大值
2)形成分割线,一边全部大于key值,一边全部小于key值
3、【Hashing】
I 重要代码:
1)判断是否为素数(质数),若不是,则要找到大于m值(某个值)的最小素数。注意1不是素数,2是最小素数。
2)创建哈希表,如何判断某个key能否插入表中
II 我犯的错误:
1)处理冲突的公式弄错。应该是 Hi = (H(key)+di)%m(m是表长),而不是 Hi = (key+di)%m
2)判断是否是素数及找到大于m值的最小质数时,忽略了1不是素数,2是最小素数的问题。
3)在判断某个key能否插入表中时,最初的思路是如果di (即j*j) 大于等于原来的H(key),那就跟第一轮(di < H(key)时)一样了(感觉上),于是用了:for( int j = 1; ; j++ ){ }永真循环 + if ( j*j >= H(key) )判断能否加入到表中,但是这个方法不行。
问题在于我不知道 j 应该到什么时候终止才能不遗不漏,我也没大胆猜测,后来百度了一下,看到判断条件是 j <= m,似懂非懂,感觉好像 j >=m 之后才是重复的一轮,而不是 j*j > H(key)【上面的】。
4)优化了一些地方。
一开始:存好数据再输出下标-----改进:边判断边输出,第一轮输入先输出一个下标,后面输入先输出空格后下标。减少了代码量。
三、其他收获
1、准确率和召回率(Precision & Recall)
解释:
准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。
其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;
召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
1. 正确率 = 提取出的正确信息条数 / 提取出的信息条数
2. 召回率 = 提取出的正确信息条数 / 样本中的信息条数
2、顺序查找中“哨兵”的使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号