


MySQL Tips
MySQL中的一些Tips,个人总结或者整理自网络
不明白为什么MySQL的很多材料中总是喜欢把联合(复合)索引和覆盖索引放在一块说事?
1,联合索引是一种索引的类型,指创建索引的时候包含了多个字段。
2,覆盖索引是一种查询优化行为,索引结构本身就可以满足查询,无需回表,而不是一种索引。
3,联合索引和覆盖索引并没有任何必然关系,单个字段的索引也有可能会发生覆盖索引的情况。
MySQL中的filesort
"using filesort" means that the sort can't be performed with an index. 仅此而已,并不一定真的使用文件完成排序。
mysql无法利用索引完成的排序操作成为“文件排序” ,当需要排序,而又无法直接通过索引直接完成排序,需要额外的操作的时候发生using filesort。
filesort只能应用在单个表上,如果有多个表的数据需要排序,那么MySQL会先使用using temporary保存临时数据,然后再在临时表上使用filesort进行排序,最后输出结果。
last_query_cost
对比MySQL不同写法或者改变了索引对象之后SQL的效率的时候,似乎只能傻傻地看执行时间以及一个粗略的执行计划,呵呵。
IO、CPU、内存使用都看不到,而last_query_cost似乎也不一定靠得住。
last_query_cost的单位也不是page什么的,应该是一个综合代价的值。
The Last_query_cost value can be computed accurately only for simple “flat” queries, not complex queries such as those with subqueries or UNION.
For the latter, the value is set to 0.
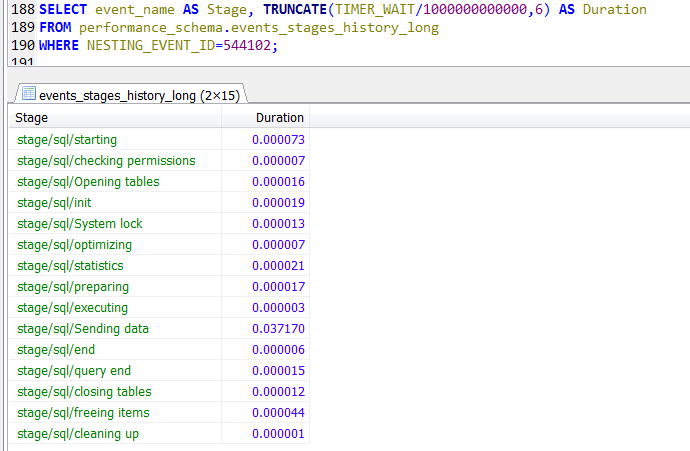
至于Profile或者performance_schema.events_stages_history_long 里面的信息,也就是看看sending data,也是一个综合资源消耗的时间结果。
Sending Data
Profile或者performance_schema.events_stages_history_long 中的Sending data
“Sending data”并不是单纯的发送数据,而是包括“收集 + 发送 数据”,说白了就是查询到结果返回的整个过程,MySQL里很多命名的东西都很有误导性,上面还在说filesort。
而performance_schema.events_stages_history_long中的绝大部分步骤,根本无法改变。
比如closing tables,cleaning up等等,本身就是查询引擎的一部分消耗,跟用户行为无关,用户也无法左右其时间消耗。
停止复制
reset slave 只是删除了master.onfo和reply_log.info文件,复制同步信息还在,reset slave all彻底地清除复制。
慢查询是否记录因阻塞造成超过long_query_time的查询?
经过测试,答案是不会。慢查询在计算“慢”的查询的时候,是只计算正常执行时间超出long_query_time的查询,而不计算阻塞的时间。
慢查询也不会因为超时或者其他原因造成的失败的查询。
补充:在SQL Server中,类似于用于记录慢查询的trace或者扩展事件,在记录“慢查询”的时候,是会把阻塞时间也算作“慢”之内的。
MySQL中的预读
如果一个extent中的被顺序读取的page超过或者等于该参数变量的,innodb将会异步的将下一个extent读取到buffer pool中,
由参数innodb_read_ahead_threshold来控制
比如该参数的值为30,那么当该extent中有30个pages 被 sequentially的读取,则会触发innodb linear预读,将下一个extent读到内存中。
eq_range_index_dive_limit
MySQL中In谓词是否用索引的阈值,MySQL 5.7 默认值是200,5.6默认值是10
简单地理解,index dives就是MySQL在对where id in (***,***,……)这种语句生成执行计划的时候,通过扫描索引页的方式来估算符合条件的数据行数,这种方式潜在的问题就是,如果In里面的值很多,以至于符合条件的数据页面很多,那么仅在执行计划评估阶段,就需要扫描大量的数据页面,可能会造成一定的性能损耗,如果换一种评估方式,也就是基于统计信息做评估,就可以避免潜在的扫描大量的索引页的情况(但是基于统计信息的预估也不是完美的,最大的问题是不够精准)。index dives的参数为eq_range_index_dive_limit,默认为200。
为什么建议自增列做主键
https://imysql.com/2014/09/14/mysql-faq-why-innodb-table-using-autoinc-int-as-pk.shtml
binlog_row_image
FULL:记录每一行的变更;
MINIMAL:只记录影响后的行,无法无通过flashback或binlog2SQL等快速闪回。
NOBLOB:就像full格式一样。但对于BLOB或TEXT格式的列,如果他不是唯一识别列(唯一索引列、主键列),或者没有修改,那就不记录。
innodb_online_alter_log_max_size
MySQL DDL 的 INPLACE 算法虽然支持在 DDL 过程中间的读写,但是对写入的数据量有上限,不能超过 innodb_online_alter_log_max_size(默认为 128M)
未完待续。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号